Google mendengar lebih baik, pencarian lebih mudah
Google mengumumkan bahwa mereka telah menyelesaikan sistem pencarian suara mereka untuk mencapai pengakuan yang lebih baik terhadap ucapan pengguna di tempat-tempat yang bising. Itu selalu menjadi salah satu sistem pengenalan suara terbaik, terutama nyaman saat mencari menggunakan smartphone. Sekarang fungsi pencarian suara menjadi lebih berkembang dari sebelumnya. Google Research Blog menguraikan perbaikan yang telah dibuat untuk sistem yang diperbarui.Sejak 2012, raksasa pencarian telah beralih dari menggunakan Metode Gaussian Mixes (MGS) tiga puluh tahun yang lalu dalam pengenalan ucapan. Sistem baru mulai menggunakan jaringan saraf dalam ( Deep Neural Networks ). STS dapat lebih mengenali suara apa yang dibuat pengguna pada titik waktu tertentu, yang sangat meningkatkan akurasi pengakuan.
Itu selalu menjadi salah satu sistem pengenalan suara terbaik, terutama nyaman saat mencari menggunakan smartphone. Sekarang fungsi pencarian suara menjadi lebih berkembang dari sebelumnya. Google Research Blog menguraikan perbaikan yang telah dibuat untuk sistem yang diperbarui.Sejak 2012, raksasa pencarian telah beralih dari menggunakan Metode Gaussian Mixes (MGS) tiga puluh tahun yang lalu dalam pengenalan ucapan. Sistem baru mulai menggunakan jaringan saraf dalam ( Deep Neural Networks ). STS dapat lebih mengenali suara apa yang dibuat pengguna pada titik waktu tertentu, yang sangat meningkatkan akurasi pengakuan.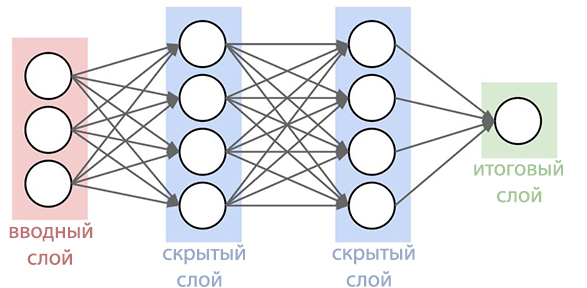 Sekarang, para ahli Google telah mengumumkan bahwa mereka telah berhasil menciptakan jaringan saraf model akustik yang lebih maju yang menggunakan klasifikasi temporal koneksionis dan algoritma pembelajaran diskriminatif . Model-model ini merupakan perpanjangan khusus dari jaringan saraf periodik yang lebih akurat, terutama di lingkungan yang bising, dan sangat cepat!Dalam pengenalan ucapan tradisional, bentuk suara yang diisi pengguna dibagi menjadi frame (segmen) berurutan 10 milidetik. Setiap frame menjalani analisis frekuensi dan vektor yang dihasilkan dengan karakteristik diteruskan melalui model akustik, seperti GNS, yang memberikan probabilitas untuk semua kecocokan suara. Hidden Markov Model (SMM) membantu mengungkap detail yang tidak diketahui berdasarkan yang sudah diperoleh, ini memungkinkan untuk memperkenalkan semacam penataan urutan distribusi probabilitas ini. Model ini selanjutnya dikombinasikan dengan sumber pengetahuan lain, seperti Model Pengucapan, yang menghubungkan urutan suara dengan kata-kata tertentu dari bahasa yang dipilih dan Model Bahasa, yang pada gilirannya mengungkapkan seberapa banyak kata merujuk pada bahasa yang dipilih.Pengenal kemudian merekonsiliasi semua informasi ini untuk menentukan kalimat yang dibuat pengguna. Jika pengguna mengatakan, misalnya, kata "museum" (mju: 'zɪəm adalah bentuk fonetis), maka akan sulit untuk menentukan kapan suara "j" berakhir dan suara "u" dimulai. Namun, sebenarnya, penentu tidak peduli ketika transisi ini terjadi. Satu-satunya hal yang mengganggunya adalah suara yang diucapkan.Model akustik yang lebih baik didasarkan pada Jaringan Syaraf Tiruan (PNIC). Dalam topologi PNS, ada loop umpan balik yang memungkinkan Anda untuk mensimulasikan ketergantungan waktu. Ketika pengguna mengucapkan / U / dalam contoh sebelumnya, peralatan artikulasi orang tersebut bergerak dengan lancar dari suara / J / ke suara / M / pertama-tama. Cobalah untuk mengucapkan kata "museum", bagi orang yang fasih berbahasa Inggris, itu tidak akan sulit dan kata itu akan diucapkan dengan mudah dalam satu napas, PNS mampu menangkap momen ini.
Sekarang, para ahli Google telah mengumumkan bahwa mereka telah berhasil menciptakan jaringan saraf model akustik yang lebih maju yang menggunakan klasifikasi temporal koneksionis dan algoritma pembelajaran diskriminatif . Model-model ini merupakan perpanjangan khusus dari jaringan saraf periodik yang lebih akurat, terutama di lingkungan yang bising, dan sangat cepat!Dalam pengenalan ucapan tradisional, bentuk suara yang diisi pengguna dibagi menjadi frame (segmen) berurutan 10 milidetik. Setiap frame menjalani analisis frekuensi dan vektor yang dihasilkan dengan karakteristik diteruskan melalui model akustik, seperti GNS, yang memberikan probabilitas untuk semua kecocokan suara. Hidden Markov Model (SMM) membantu mengungkap detail yang tidak diketahui berdasarkan yang sudah diperoleh, ini memungkinkan untuk memperkenalkan semacam penataan urutan distribusi probabilitas ini. Model ini selanjutnya dikombinasikan dengan sumber pengetahuan lain, seperti Model Pengucapan, yang menghubungkan urutan suara dengan kata-kata tertentu dari bahasa yang dipilih dan Model Bahasa, yang pada gilirannya mengungkapkan seberapa banyak kata merujuk pada bahasa yang dipilih.Pengenal kemudian merekonsiliasi semua informasi ini untuk menentukan kalimat yang dibuat pengguna. Jika pengguna mengatakan, misalnya, kata "museum" (mju: 'zɪəm adalah bentuk fonetis), maka akan sulit untuk menentukan kapan suara "j" berakhir dan suara "u" dimulai. Namun, sebenarnya, penentu tidak peduli ketika transisi ini terjadi. Satu-satunya hal yang mengganggunya adalah suara yang diucapkan.Model akustik yang lebih baik didasarkan pada Jaringan Syaraf Tiruan (PNIC). Dalam topologi PNS, ada loop umpan balik yang memungkinkan Anda untuk mensimulasikan ketergantungan waktu. Ketika pengguna mengucapkan / U / dalam contoh sebelumnya, peralatan artikulasi orang tersebut bergerak dengan lancar dari suara / J / ke suara / M / pertama-tama. Cobalah untuk mengucapkan kata "museum", bagi orang yang fasih berbahasa Inggris, itu tidak akan sulit dan kata itu akan diucapkan dengan mudah dalam satu napas, PNS mampu menangkap momen ini.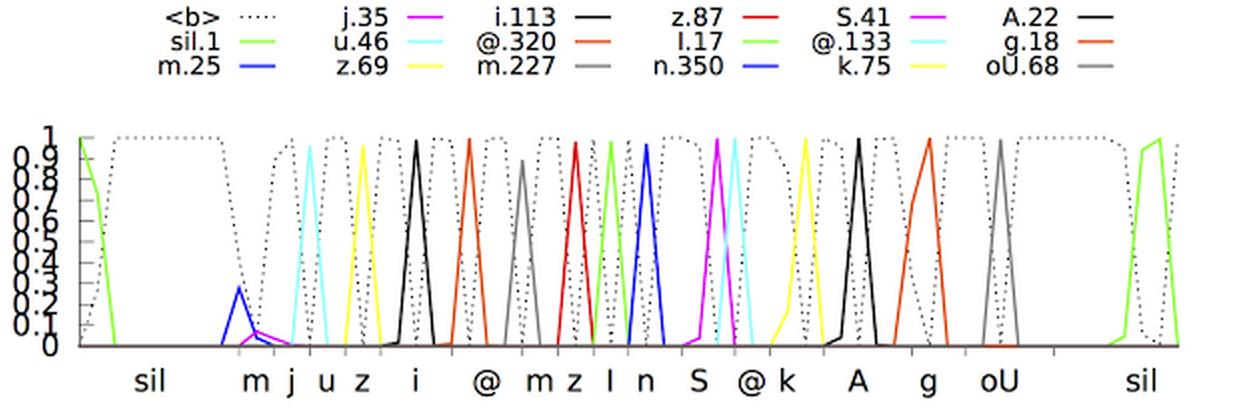 Jenis jaringan saraf periodik dalam sistem ini adalah memori jangka pendek, yang dengan bantuan sel memori dan mekanisme gating yang kompleks mengingat informasi lebih baik daripada PNS lainnya. Gating adalah metode mengalokasikan interval waktu tertentu untuk meningkatkan kemungkinan mendeteksi sinyal yang berguna dengan latar belakang gangguan. Adopsi model tersebut telah secara signifikan meningkatkan kualitas pengenalan suara.Langkah selanjutnya adalah mengajarkan model akustik untuk mengenali fonem (suara) dalam pidato yang disampaikan tanpa membuat prediksi untuk setiap frame. Model dengan Associative Time Classification menyiapkan grafik dengan urutan paku yang menampilkan urutan suara dalam sinyal yang diterima.Mereka dapat melakukan ini sampai urutan rusak.Faktanya, sistem pengenalan suara Google sekarang dapat memeriksa konteks di mana kata itu diucapkan, menjauh dari suara latar belakang.
Jenis jaringan saraf periodik dalam sistem ini adalah memori jangka pendek, yang dengan bantuan sel memori dan mekanisme gating yang kompleks mengingat informasi lebih baik daripada PNS lainnya. Gating adalah metode mengalokasikan interval waktu tertentu untuk meningkatkan kemungkinan mendeteksi sinyal yang berguna dengan latar belakang gangguan. Adopsi model tersebut telah secara signifikan meningkatkan kualitas pengenalan suara.Langkah selanjutnya adalah mengajarkan model akustik untuk mengenali fonem (suara) dalam pidato yang disampaikan tanpa membuat prediksi untuk setiap frame. Model dengan Associative Time Classification menyiapkan grafik dengan urutan paku yang menampilkan urutan suara dalam sinyal yang diterima.Mereka dapat melakukan ini sampai urutan rusak.Faktanya, sistem pengenalan suara Google sekarang dapat memeriksa konteks di mana kata itu diucapkan, menjauh dari suara latar belakang. Pertanyaan yang sama sekali berbeda: bagaimana membuat semuanya dapat diakses dan nyaman secara real time? Setelah sejumlah besar iterasi, programmer Google berhasil membuat model streaming tunggal yang memproses sinyal yang masuk dengan blok yang lebih besar daripada blok dalam model akustik standar, tetapi melakukan lebih sedikit perhitungan aktual. Mengurangi jumlah operasi komputasi secara signifikan mempercepat proses pengenalan. Juga, kebisingan buatan dan gema (pengurangan suara buatan) ditambahkan ke program pelatihan sistem untuk membuat sistem pengenalan lebih tahan terhadap kebisingan asing. Dalam video di bawah ini, Anda dapat menonton sistem mempelajari kalimatnya.Namun demikian, satu masalah lagi masih harus dipecahkan: sistem menghasilkan perkiraan lebih sedikit, tetapi pada saat yang sama mereka tertunda sekitar 300 milidetik. Dengan mengeluarkan hasilnya setelah proposal selesai, tingkat pengakuan meningkat, tetapi pada saat yang sama penundaan tambahan dibuat untuk pengguna, yang sama sekali tidak dapat diterima untuk spesialis Goolge. Untuk menyelesaikan masalah, sistem dilatih untuk menganalisis dan menghasilkan hasil untuk setiap frasa sebelum selesai. Ini membuat proses pengenalan lebih disinkronkan dengan tingkat pengucapan normal seseorang. Pengguna tidak lagi perlu menunggu sampai program menampilkan versi sendiri dari frasa yang diucapkan.Model akustik baru sudah digunakan untuk pencarian dan perintah suara di aplikasi Google(pada Android dan iOS) dan untuk dikte pada perangkat Android. Model-model baru mulai membutuhkan lebih sedikit sumber daya, menjadi lebih tahan terhadap kebisingan sekitar dan mampu menghasilkan hasil yang jauh lebih cepat daripada pendahulunya. Ini membuat pencarian suara lebih menyenangkan bagi pengguna.
Pertanyaan yang sama sekali berbeda: bagaimana membuat semuanya dapat diakses dan nyaman secara real time? Setelah sejumlah besar iterasi, programmer Google berhasil membuat model streaming tunggal yang memproses sinyal yang masuk dengan blok yang lebih besar daripada blok dalam model akustik standar, tetapi melakukan lebih sedikit perhitungan aktual. Mengurangi jumlah operasi komputasi secara signifikan mempercepat proses pengenalan. Juga, kebisingan buatan dan gema (pengurangan suara buatan) ditambahkan ke program pelatihan sistem untuk membuat sistem pengenalan lebih tahan terhadap kebisingan asing. Dalam video di bawah ini, Anda dapat menonton sistem mempelajari kalimatnya.Namun demikian, satu masalah lagi masih harus dipecahkan: sistem menghasilkan perkiraan lebih sedikit, tetapi pada saat yang sama mereka tertunda sekitar 300 milidetik. Dengan mengeluarkan hasilnya setelah proposal selesai, tingkat pengakuan meningkat, tetapi pada saat yang sama penundaan tambahan dibuat untuk pengguna, yang sama sekali tidak dapat diterima untuk spesialis Goolge. Untuk menyelesaikan masalah, sistem dilatih untuk menganalisis dan menghasilkan hasil untuk setiap frasa sebelum selesai. Ini membuat proses pengenalan lebih disinkronkan dengan tingkat pengucapan normal seseorang. Pengguna tidak lagi perlu menunggu sampai program menampilkan versi sendiri dari frasa yang diucapkan.Model akustik baru sudah digunakan untuk pencarian dan perintah suara di aplikasi Google(pada Android dan iOS) dan untuk dikte pada perangkat Android. Model-model baru mulai membutuhkan lebih sedikit sumber daya, menjadi lebih tahan terhadap kebisingan sekitar dan mampu menghasilkan hasil yang jauh lebih cepat daripada pendahulunya. Ini membuat pencarian suara lebih menyenangkan bagi pengguna. Source: https://habr.com/ru/post/id384747/
All Articles