IoT dan hackathon Azure Machine Learning: bagaimana kami melakukan proyek di luar kompetisi
 Belum lama berselang, hackathon Microsoft lainnya terjadi . Kali ini, ia didedikasikan untuk pembelajaran mesin . Namun, topiknya sangat relevan dan menjanjikan, bagi saya agak kabur. Pada awal hackathon, saya hanya memiliki gambaran umum tentang apa itu, mengapa itu diperlukan, dan saya melihat hasil model yang terlatih beberapa kali. Setelah mengetahui bahwa pengumuman itu menjanjikan banyak ahli untuk membantu pemula, saya memutuskan untuk menggabungkan bisnis dengan kesenangan dan mencoba menggunakan pembelajaran mesin ketika bekerja dengan beberapa jenis solusi IoT . Selanjutnya, saya akan memberi tahu Anda apa yang terjadi.Saya telah lama terlibat dalam sistem keamanan perimeter, berdasarkan analisis getaran pagar, sehingga setelah ide untuk bekerja dengan accelerometer. Idenya sederhana: untuk mengajarkan sistem untuk membedakan antara getaran beberapa telepon, berdasarkan data dari accelerometer. Eksperimen serupa telah berhasil dilakukan oleh rekan-rekan saya, jadi saya tidak ragu bahwa ini mungkin.Awalnya, saya ingin melakukan segalanya pada Raspberry Pi 2 dan Windows IoT . Sebuah papan khusus disiapkan (dalam foto di bawah) dengan akselerometer digital dan analog, tetapi saya tidak berhasil mencobanya dalam praktik, setelah memutuskan untuk melakukan segalanya dengan hackathon. Untuk jaga-jaga, saya juga menangkap sensor kami , yang juga memungkinkan Anda mempelajari data "mentah" tentang fluktuasi.
Belum lama berselang, hackathon Microsoft lainnya terjadi . Kali ini, ia didedikasikan untuk pembelajaran mesin . Namun, topiknya sangat relevan dan menjanjikan, bagi saya agak kabur. Pada awal hackathon, saya hanya memiliki gambaran umum tentang apa itu, mengapa itu diperlukan, dan saya melihat hasil model yang terlatih beberapa kali. Setelah mengetahui bahwa pengumuman itu menjanjikan banyak ahli untuk membantu pemula, saya memutuskan untuk menggabungkan bisnis dengan kesenangan dan mencoba menggunakan pembelajaran mesin ketika bekerja dengan beberapa jenis solusi IoT . Selanjutnya, saya akan memberi tahu Anda apa yang terjadi.Saya telah lama terlibat dalam sistem keamanan perimeter, berdasarkan analisis getaran pagar, sehingga setelah ide untuk bekerja dengan accelerometer. Idenya sederhana: untuk mengajarkan sistem untuk membedakan antara getaran beberapa telepon, berdasarkan data dari accelerometer. Eksperimen serupa telah berhasil dilakukan oleh rekan-rekan saya, jadi saya tidak ragu bahwa ini mungkin.Awalnya, saya ingin melakukan segalanya pada Raspberry Pi 2 dan Windows IoT . Sebuah papan khusus disiapkan (dalam foto di bawah) dengan akselerometer digital dan analog, tetapi saya tidak berhasil mencobanya dalam praktik, setelah memutuskan untuk melakukan segalanya dengan hackathon. Untuk jaga-jaga, saya juga menangkap sensor kami , yang juga memungkinkan Anda mempelajari data "mentah" tentang fluktuasi. Di hackathon, semua peserta diminta untuk dibagi menjadi beberapa tim dan menyelesaikan satu dari 3 masalah menggunakan data yang telah disiapkan sebelumnya. Tugas saya ternyata “keluar dari kompetisi”, tetapi tim berkumpul cukup cepat:
Di hackathon, semua peserta diminta untuk dibagi menjadi beberapa tim dan menyelesaikan satu dari 3 masalah menggunakan data yang telah disiapkan sebelumnya. Tugas saya ternyata “keluar dari kompetisi”, tetapi tim berkumpul cukup cepat: Tidak seorang pun dari kami memiliki pengalaman menggunakan pembelajaran Azure Machine, jadi ada banyak yang harus dilakukan! Terima kasih kepada kolega, di antaranya adalah psfinaki , atas upaya mereka!Diputuskan untuk membagi menjadi 3 arah:
Tidak seorang pun dari kami memiliki pengalaman menggunakan pembelajaran Azure Machine, jadi ada banyak yang harus dilakukan! Terima kasih kepada kolega, di antaranya adalah psfinaki , atas upaya mereka!Diputuskan untuk membagi menjadi 3 arah:- persiapan data untuk analisis
- unggah data ke cloud
- bekerja dengan Azure Machine Learning
Persiapan data adalah untuk mendapatkannya dari accelerometer, dan kemudian menyajikannya dalam bentuk yang tersedia untuk diunduh ke cloud. Upload ke cloud direncanakan melalui Event Hub . Nah, maka Anda harus memahami cara menggunakan data ini di Azure Machine Learning.Masalah dimulai pada ketiga poin. Butuh waktu lama untuk mengkonfigurasi Windows IoT di Raspberry. Dia tidak memberikan gambar di monitor. Itu mungkin untuk menyelesaikan ini hanya dengan memasukkan baris berikut di config.txt:
Butuh waktu lama untuk mengkonfigurasi Windows IoT di Raspberry. Dia tidak memberikan gambar di monitor. Itu mungkin untuk menyelesaikan ini hanya dengan memasukkan baris berikut di config.txt:hdmi_ignore_edid=0xa5000080hdmi_drive=2hdmi_group=2hdmi_mode=16Ini menyetel driver video ke format, resolusi, dan frekuensi yang diinginkan. Namun, waktu yang dihabiskan untuk pelajaran ini menjelaskan bahwa Anda mungkin tidak punya waktu untuk mengatur penerimaan data dari accelerometer. Oleh karena itu, diputuskan untuk menggunakan sensor yang telah saya ambil sebagai cadangan.Banyak aplikasi telah ditulis untuk sensor. Salah satunya ditampilkan pada layar grafik data "mentah":
Namun, waktu yang dihabiskan untuk pelajaran ini menjelaskan bahwa Anda mungkin tidak punya waktu untuk mengatur penerimaan data dari accelerometer. Oleh karena itu, diputuskan untuk menggunakan sensor yang telah saya ambil sebagai cadangan.Banyak aplikasi telah ditulis untuk sensor. Salah satunya ditampilkan pada layar grafik data "mentah":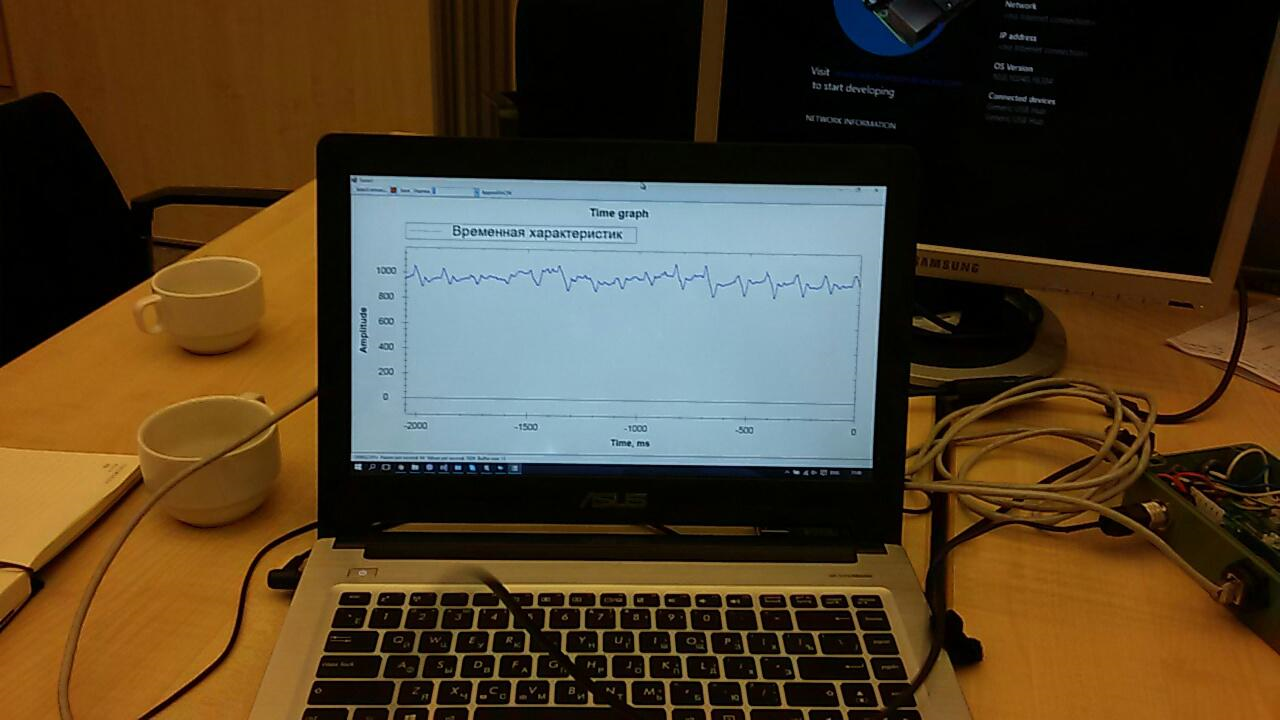 Perlu sedikit untuk menyelesaikannya untuk mempersiapkan data untuk dikirim ke cloud.Event Hub juga tidak langsung berfungsi. Untuk memulainya, kami mencoba mengirim ke sana hanya urutan acak. Tetapi data tidak mau muncul di laporan. Ada beberapa masalah, dan, ternyata, mereka semua "kekanak-kanakan": di suatu tempat mereka salah mengaturnya, di suatu tempat mereka menggunakan kunci yang salah, dan seterusnya. Bekerja ke arah ini sulit dan menghabiskan banyak energi:
Perlu sedikit untuk menyelesaikannya untuk mempersiapkan data untuk dikirim ke cloud.Event Hub juga tidak langsung berfungsi. Untuk memulainya, kami mencoba mengirim ke sana hanya urutan acak. Tetapi data tidak mau muncul di laporan. Ada beberapa masalah, dan, ternyata, mereka semua "kekanak-kanakan": di suatu tempat mereka salah mengaturnya, di suatu tempat mereka menggunakan kunci yang salah, dan seterusnya. Bekerja ke arah ini sulit dan menghabiskan banyak energi: Tetapi, pada malam hari pertama, kami dapat mengirim dan menerima data dari sensor dengan cepat ... Benar, ini tidak diperlukan dalam solusi akhir. Saya akan membicarakan alasannya nanti.Dengan Machine Learning, tidak ada yang jelas sama sekali. Awalnya kami bersama-sama mempelajari keindahanartikel dengan contoh menggunakan aplikasi seluler sebagai klien. Kemudian kami menemukan format data dan cara bekerja dengannya. Kemudian mereka memikirkan cara membuat urutan pelatihan.Azure Mashine Learning memiliki banyak algoritma untuk berbagai klasifikasi. Algoritma ini harus dilatih pada set data uji. Kemudian, mereka yang memberikan hasil terbaik dapat dipublikasikan sebagai layanan web dan terhubung dengan mereka dari aplikasi.Mempelajari suatu algoritma disebut "eksperimen." Semua tindakan dilakukan dalam editor visual:
Tetapi, pada malam hari pertama, kami dapat mengirim dan menerima data dari sensor dengan cepat ... Benar, ini tidak diperlukan dalam solusi akhir. Saya akan membicarakan alasannya nanti.Dengan Machine Learning, tidak ada yang jelas sama sekali. Awalnya kami bersama-sama mempelajari keindahanartikel dengan contoh menggunakan aplikasi seluler sebagai klien. Kemudian kami menemukan format data dan cara bekerja dengannya. Kemudian mereka memikirkan cara membuat urutan pelatihan.Azure Mashine Learning memiliki banyak algoritma untuk berbagai klasifikasi. Algoritma ini harus dilatih pada set data uji. Kemudian, mereka yang memberikan hasil terbaik dapat dipublikasikan sebagai layanan web dan terhubung dengan mereka dari aplikasi.Mempelajari suatu algoritma disebut "eksperimen." Semua tindakan dilakukan dalam editor visual: Menyeret dan menjatuhkan item dari daftar di sebelah kiri memungkinkan Anda untuk menerima data, memodifikasi dan mentransformasikannya, melatih model dan mengevaluasi pekerjaan mereka.Inilah yang menjadi eksperimen biasa:
Menyeret dan menjatuhkan item dari daftar di sebelah kiri memungkinkan Anda untuk menerima data, memodifikasi dan mentransformasikannya, melatih model dan mengevaluasi pekerjaan mereka.Inilah yang menjadi eksperimen biasa: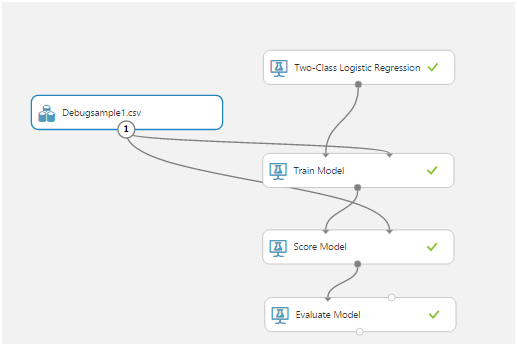 Model Kereta, Model Skor, dan Model Evaluasi ternyata yang paling penting.Yang pertama, menggunakan input data, melatih algoritma, yang kedua menguji algoritma yang terlatih pada set data, yang ketiga mengevaluasi hasil tes.Sumber data dalam kasus kami adalah file csv. Tapi apa yang harus terkandung di dalamnya?Elemen sensitif dari sensor kami disurvei 1024 kali per detik. Setiap survei adalah nilai dua byte yang sesuai dengan amplitudo osilasi saat ini. Selain itu, amplitudo diukur bukan dari nol, tetapi dari nomor referensi yang sesuai dengan sensor tetap.Setelah refleksi, kami memutuskan untuk menggunakan irisan sementara. Sebagai contoh, semua jajak pendapat sensor untuk 256 ms memberi kami satu baris di tabel csv. Data ini, dalam kolom tambahan, dapat ditandai dengan satu atau lain cara, tergantung pada apa yang terjadi dengan sensor. Misalnya, kami menggunakan 0 untuk mengindikasikan noise (mengguncang sensor dengan tangan Anda, mengetuk, dll.) Dan 1 untuk menunjukkan sinyal (ada telepon yang bergetar pada sensor).Inilah cara kami mencatat urutan pengujian:
Model Kereta, Model Skor, dan Model Evaluasi ternyata yang paling penting.Yang pertama, menggunakan input data, melatih algoritma, yang kedua menguji algoritma yang terlatih pada set data, yang ketiga mengevaluasi hasil tes.Sumber data dalam kasus kami adalah file csv. Tapi apa yang harus terkandung di dalamnya?Elemen sensitif dari sensor kami disurvei 1024 kali per detik. Setiap survei adalah nilai dua byte yang sesuai dengan amplitudo osilasi saat ini. Selain itu, amplitudo diukur bukan dari nol, tetapi dari nomor referensi yang sesuai dengan sensor tetap.Setelah refleksi, kami memutuskan untuk menggunakan irisan sementara. Sebagai contoh, semua jajak pendapat sensor untuk 256 ms memberi kami satu baris di tabel csv. Data ini, dalam kolom tambahan, dapat ditandai dengan satu atau lain cara, tergantung pada apa yang terjadi dengan sensor. Misalnya, kami menggunakan 0 untuk mengindikasikan noise (mengguncang sensor dengan tangan Anda, mengetuk, dll.) Dan 1 untuk menunjukkan sinyal (ada telepon yang bergetar pada sensor).Inilah cara kami mencatat urutan pengujian: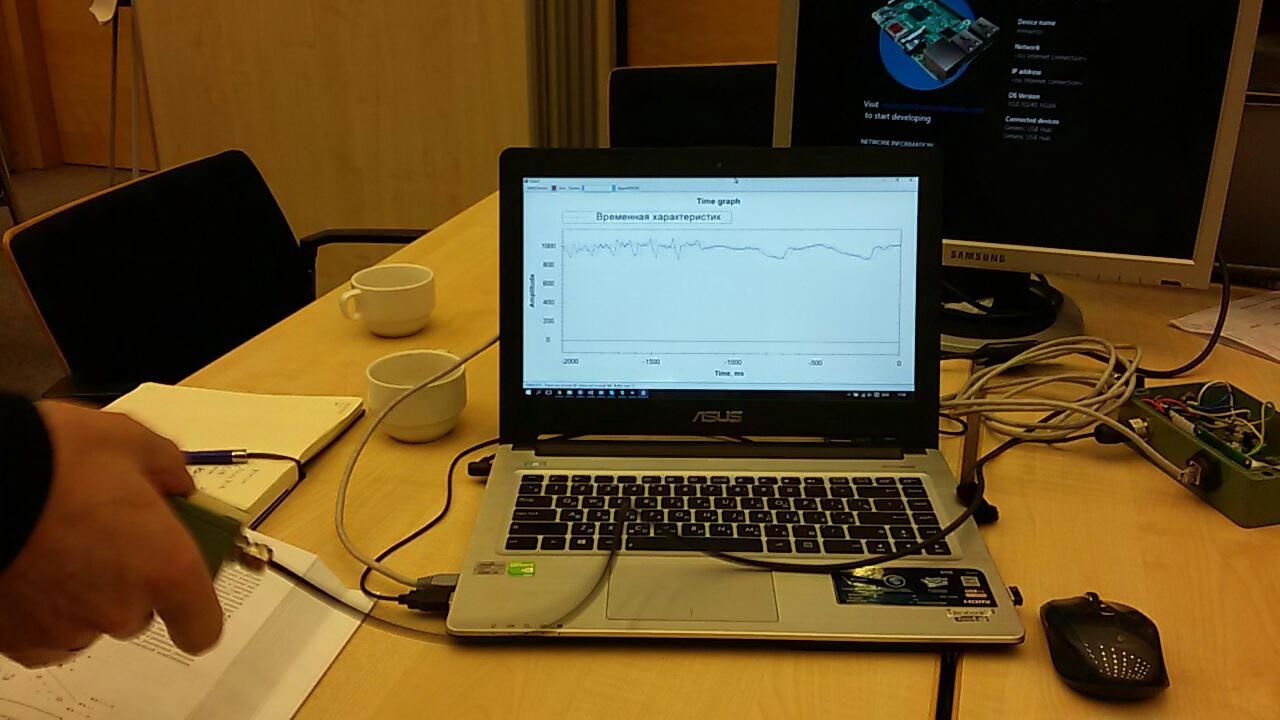 Setelah menerima data, dan menyadari apa yang harus dilakukan dengan mereka, kami mulai mempelajari model pertama:
Setelah menerima data, dan menyadari apa yang harus dilakukan dengan mereka, kami mulai mempelajari model pertama: Pancake pertama ternyata menjadi kental:
Pancake pertama ternyata menjadi kental: Pada saat itu, bahkan makna dari indikator-indikator ini tidak jelas. Kami diselamatkan oleh perwakilan dari tim pendukung, Yevgeny Grigorenko, berbicara tentang kurva ROC. Hal utama adalah bahwa jika grafik berada di bawah garis tengah di suatu tempat, maka model tersebut bekerja lebih buruk daripada jika itu memberikan hasil acak! Eugene terus membantu kami sebanyak mungkin, yang karenanya banyak terima kasih kepadanya!
Pada saat itu, bahkan makna dari indikator-indikator ini tidak jelas. Kami diselamatkan oleh perwakilan dari tim pendukung, Yevgeny Grigorenko, berbicara tentang kurva ROC. Hal utama adalah bahwa jika grafik berada di bawah garis tengah di suatu tempat, maka model tersebut bekerja lebih buruk daripada jika itu memberikan hasil acak! Eugene terus membantu kami sebanyak mungkin, yang karenanya banyak terima kasih kepadanya! Kemudian kami menulis ulang urutan pelatihan untuk waktu yang lama dan melihat hasilnya:
Kemudian kami menulis ulang urutan pelatihan untuk waktu yang lama dan melihat hasilnya: Ternyata bekerja dengan rekaman 2 detik (2048 jajak pendapat sensor) kurang optimal. Ini memungkinkan kami untuk membuat baris tabel csv lebih bermakna. Namun hasilnya masih jauh dari bagus.Ini berakhir pada hari pertama.Saya menghabiskan malam mempelajari materi. Artikel itu sangat membantutentang klasifikasi biner. Saya juga hati-hati membaca artikel dengan tips untuk hackathon ini. Secara umum, pada awal pekerjaan saya penuh dengan ide-ide baru.Kami menghabiskan seluruh paruh pertama hari kedua mempelajari berbagai model. Hasil dari pekerjaan ini adalah “lembaran”:
Ternyata bekerja dengan rekaman 2 detik (2048 jajak pendapat sensor) kurang optimal. Ini memungkinkan kami untuk membuat baris tabel csv lebih bermakna. Namun hasilnya masih jauh dari bagus.Ini berakhir pada hari pertama.Saya menghabiskan malam mempelajari materi. Artikel itu sangat membantutentang klasifikasi biner. Saya juga hati-hati membaca artikel dengan tips untuk hackathon ini. Secara umum, pada awal pekerjaan saya penuh dengan ide-ide baru.Kami menghabiskan seluruh paruh pertama hari kedua mempelajari berbagai model. Hasil dari pekerjaan ini adalah “lembaran”: Pada saat ini sudah jelas bahwa kami tidak punya waktu untuk membedakan antara dua cincin getaran, karena kualitas data pelatihan meninggalkan banyak yang diinginkan, dan tidak ada cukup waktu untuk merekam yang baru. Oleh karena itu, kami fokus pada pemisahan data menjadi "sinyal" dan "noise".Untuk pekerjaan, kami menggunakan 3 set data:
Pada saat ini sudah jelas bahwa kami tidak punya waktu untuk membedakan antara dua cincin getaran, karena kualitas data pelatihan meninggalkan banyak yang diinginkan, dan tidak ada cukup waktu untuk merekam yang baru. Oleh karena itu, kami fokus pada pemisahan data menjadi "sinyal" dan "noise".Untuk pekerjaan, kami menggunakan 3 set data:- Set pelatihan di mana ada sinyal (garis-garis file csv bertanda 1) dan derau (garis bertanda 0)
- Satu set yang hanya berisi derau (garis dari 0)
- Satu set yang hanya berisi sinyal (garis dari 1)
Model pertama kali dilatih, kemudian diuji dan dievaluasi pada masing-masing set data. Hasilnya menggembirakan: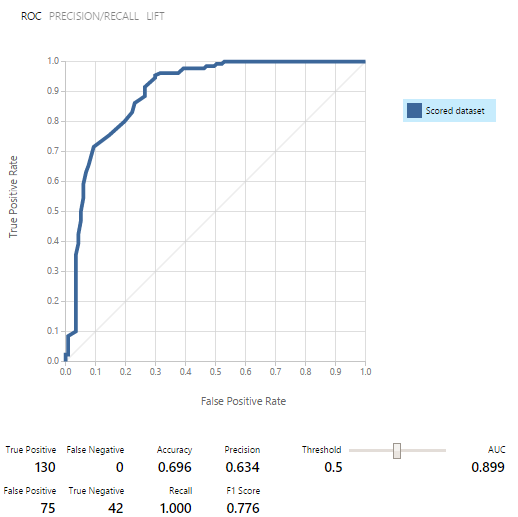 Sebagai hasilnya, dari sembilan model klasifikasi biner, kami memilih lima.Ternyata, menggunakan model sebagai layanan Web jauh lebih mudah daripada mengacaukannya ke hub Event. Oleh karena itu, kami memutuskan untuk menerbitkan semua 5 model dan bekerja dengannya melalui REQUEST / RESPONSE, yang disertai dengan contoh yang sangat baik.
Sebagai hasilnya, dari sembilan model klasifikasi biner, kami memilih lima.Ternyata, menggunakan model sebagai layanan Web jauh lebih mudah daripada mengacaukannya ke hub Event. Oleh karena itu, kami memutuskan untuk menerbitkan semua 5 model dan bekerja dengannya melalui REQUEST / RESPONSE, yang disertai dengan contoh yang sangat baik. Permintaan adalah array input 2048 nilai yang diambil dari sensor. Jawabannya terlihat seperti ini:
Permintaan adalah array input 2048 nilai yang diambil dari sensor. Jawabannya terlihat seperti ini: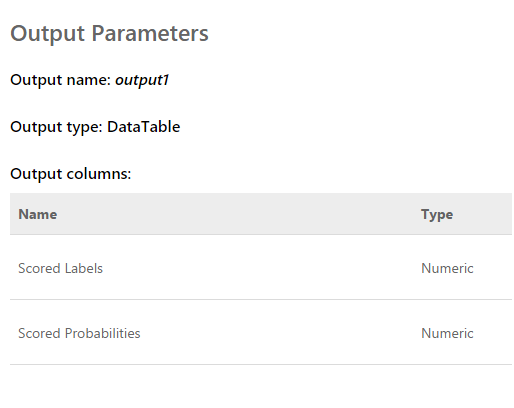 Label yang diberi nilai adalah 0 atau 1. Yaitu, hasil klasifikasi. Probabilitas Skor - angka desimal yang mencerminkan kebenaran penilaian. Seperti yang saya pahami, nilai pertama adalah pembulatan ke dua. Artinya, semakin dekat nilai kedua ke 0, skor 0 lebih mungkin, dan sebaliknya. Semakin dekat nilainya ke 1, skor 1 lebih mungkin.Setelah menyelesaikan program yang menampilkan grafik "data mentah" di layar, kami dapat secara bersamaan menerima data dari semua lima layanan web dari beberapa aliran. Selanjutnya, setelah mengamati perkiraan sedikit, kami mengecualikan satu, karena memberikan hasil yang benar-benar berbeda dari yang lain dan merusak keseluruhan gambar.Hasilnya adalah sebagai berikut:
Label yang diberi nilai adalah 0 atau 1. Yaitu, hasil klasifikasi. Probabilitas Skor - angka desimal yang mencerminkan kebenaran penilaian. Seperti yang saya pahami, nilai pertama adalah pembulatan ke dua. Artinya, semakin dekat nilai kedua ke 0, skor 0 lebih mungkin, dan sebaliknya. Semakin dekat nilainya ke 1, skor 1 lebih mungkin.Setelah menyelesaikan program yang menampilkan grafik "data mentah" di layar, kami dapat secara bersamaan menerima data dari semua lima layanan web dari beberapa aliran. Selanjutnya, setelah mengamati perkiraan sedikit, kami mengecualikan satu, karena memberikan hasil yang benar-benar berbeda dari yang lain dan merusak keseluruhan gambar.Hasilnya adalah sebagai berikut: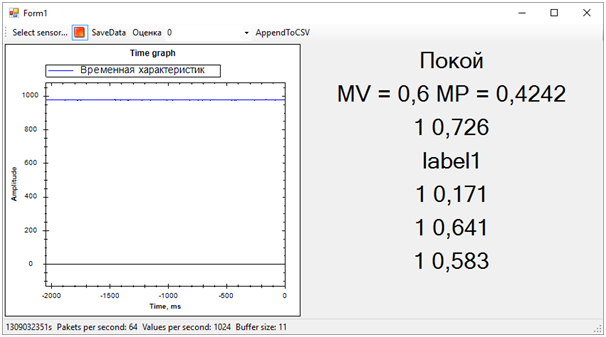
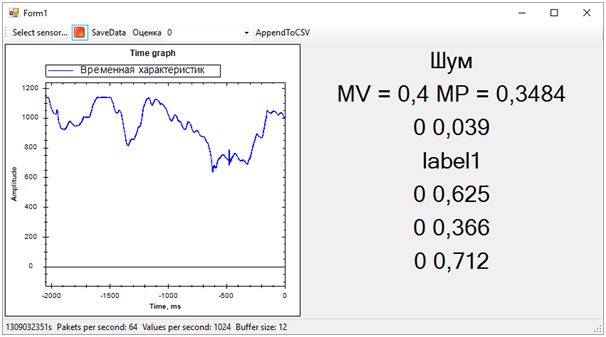
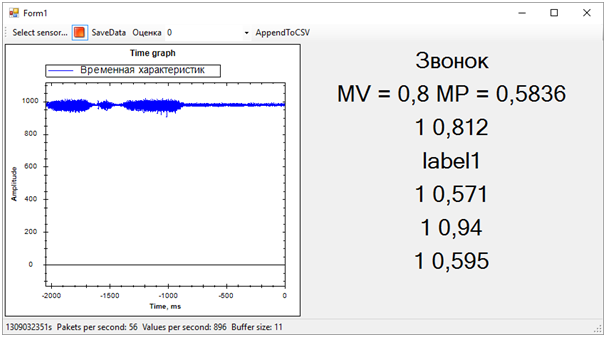 Kemudian semua masalah dari urutan pelatihan segera keluar. Meskipun kami mencoba memisahkan peringatan getaran dari yang lainnya (kebisingan dan istirahat), keadaan sisanya ternyata sangat dekat dengan panggilan, ini jauh dari selalu ditentukan. Perbedaan antara panggilan dan sisanya, kami ditentukan oleh jumlah rata-rata probabilitas untuk masing-masing model. Nilai yang lebih dekat ke 1 berarti panggilan, nilai sekitar 0,5 dengan skor 1 adalah kedamaian. Nah, jika skornya 0 - ini pasti berisik.Pada saat ini, hackathon berakhir. Kami bahkan tidak punya waktu untuk menunjukkan hasilnya kepada para ahli, karena mereka sibuk mengevaluasi entri.Tetapi semua ini tidak lagi penting. Yang paling penting, kami telah mencapai hasil yang benar-benar waras dan pada saat yang sama telah belajar banyak!Dalam dua hari kerja keras, kami menyelesaikan, meskipun sebagian, tugas. Terima kasih kepada kolega dari tim dan para ahli yang membantu kami!Sekarang kita dapat mencatat jalur pengembangan proyek kami. Kami menggunakan karakteristik waktu untuk memisahkan acara. Namun, jika kita pindah ke domain frekuensi, efisiensi algoritma harus lebih tinggi. Kebisingan, kedamaian dan bel memiliki karakteristik spektral yang sangat berbeda.Selain itu, orang yang berpengalaman menyarankan bahwa data harus dinormalisasi. Artinya, angka-angka dari urutan input harus berada dalam kisaran dari -1 hingga +1. Algoritma bekerja lebih efisien dengan data seperti itu.Yah dan masih, perlu untuk bekerja pada pembentukan urutan pelatihan untuk lebih jelas memisahkan sinyal dari kebisingan.Perbaikan ini harus secara signifikan meningkatkan akurasi penentuan keadaan, yang ingin saya periksa di masa depan.
Kemudian semua masalah dari urutan pelatihan segera keluar. Meskipun kami mencoba memisahkan peringatan getaran dari yang lainnya (kebisingan dan istirahat), keadaan sisanya ternyata sangat dekat dengan panggilan, ini jauh dari selalu ditentukan. Perbedaan antara panggilan dan sisanya, kami ditentukan oleh jumlah rata-rata probabilitas untuk masing-masing model. Nilai yang lebih dekat ke 1 berarti panggilan, nilai sekitar 0,5 dengan skor 1 adalah kedamaian. Nah, jika skornya 0 - ini pasti berisik.Pada saat ini, hackathon berakhir. Kami bahkan tidak punya waktu untuk menunjukkan hasilnya kepada para ahli, karena mereka sibuk mengevaluasi entri.Tetapi semua ini tidak lagi penting. Yang paling penting, kami telah mencapai hasil yang benar-benar waras dan pada saat yang sama telah belajar banyak!Dalam dua hari kerja keras, kami menyelesaikan, meskipun sebagian, tugas. Terima kasih kepada kolega dari tim dan para ahli yang membantu kami!Sekarang kita dapat mencatat jalur pengembangan proyek kami. Kami menggunakan karakteristik waktu untuk memisahkan acara. Namun, jika kita pindah ke domain frekuensi, efisiensi algoritma harus lebih tinggi. Kebisingan, kedamaian dan bel memiliki karakteristik spektral yang sangat berbeda.Selain itu, orang yang berpengalaman menyarankan bahwa data harus dinormalisasi. Artinya, angka-angka dari urutan input harus berada dalam kisaran dari -1 hingga +1. Algoritma bekerja lebih efisien dengan data seperti itu.Yah dan masih, perlu untuk bekerja pada pembentukan urutan pelatihan untuk lebih jelas memisahkan sinyal dari kebisingan.Perbaikan ini harus secara signifikan meningkatkan akurasi penentuan keadaan, yang ingin saya periksa di masa depan.Source: https://habr.com/ru/post/id387857/
All Articles