Langkah lain dalam pembelajaran mandiri mesin
 Tentu saja, ada banyak model belajar mandiri dalam Ilmu Data, tetapi apakah mereka benar-benar? Sebenarnya, tidak: sekarang dalam pembelajaran mesin ada situasi di mana faktor manusia memainkan peran yang menentukan dalam membangun model yang efektif.Ilmu Data sekarang menjadi semacam perpaduan ilmu pengetahuan dan intuisi, karena tidak ada pengetahuan formal tentang cara memprediksi prediktor dengan benar, model mana yang dapat dipilih dari puluhan yang sudah ada, dan cara mengkonfigurasi banyak parameter dalam model ini. Semua ini sulit untuk diformalkan, dan karena itu muncul situasi paradoks - pembelajaran mesin membutuhkan faktor manusia .Ini adalah orang yang perlu membangun rantai pembelajaran, dan menyesuaikan parameter yang dapat dengan mudah mengubah model terbaik menjadi sama sekali tidak berguna. Konstruksi rantai ini, yang mengubah data awal menjadi model prediktif, dapat memakan waktu beberapa minggu, tergantung pada kompleksitas tugas, dan seringkali dilakukan hanya dengan coba-coba.Ini adalah kelemahan yang serius, dan karenanya muncul ide: bisakah pembelajaran mesin - mendidik diri sendiri dengan cara yang sama seperti yang dilakukan seseorang? Sistem seperti itu telah dibuat, dan mengejutkan bahwa berita ini belum sampai ke habrasociety!
Tentu saja, ada banyak model belajar mandiri dalam Ilmu Data, tetapi apakah mereka benar-benar? Sebenarnya, tidak: sekarang dalam pembelajaran mesin ada situasi di mana faktor manusia memainkan peran yang menentukan dalam membangun model yang efektif.Ilmu Data sekarang menjadi semacam perpaduan ilmu pengetahuan dan intuisi, karena tidak ada pengetahuan formal tentang cara memprediksi prediktor dengan benar, model mana yang dapat dipilih dari puluhan yang sudah ada, dan cara mengkonfigurasi banyak parameter dalam model ini. Semua ini sulit untuk diformalkan, dan karena itu muncul situasi paradoks - pembelajaran mesin membutuhkan faktor manusia .Ini adalah orang yang perlu membangun rantai pembelajaran, dan menyesuaikan parameter yang dapat dengan mudah mengubah model terbaik menjadi sama sekali tidak berguna. Konstruksi rantai ini, yang mengubah data awal menjadi model prediktif, dapat memakan waktu beberapa minggu, tergantung pada kompleksitas tugas, dan seringkali dilakukan hanya dengan coba-coba.Ini adalah kelemahan yang serius, dan karenanya muncul ide: bisakah pembelajaran mesin - mendidik diri sendiri dengan cara yang sama seperti yang dilakukan seseorang? Sistem seperti itu telah dibuat, dan mengejutkan bahwa berita ini belum sampai ke habrasociety!TROT (Alat Optimalisasi Pipa Berbasis Pohon)
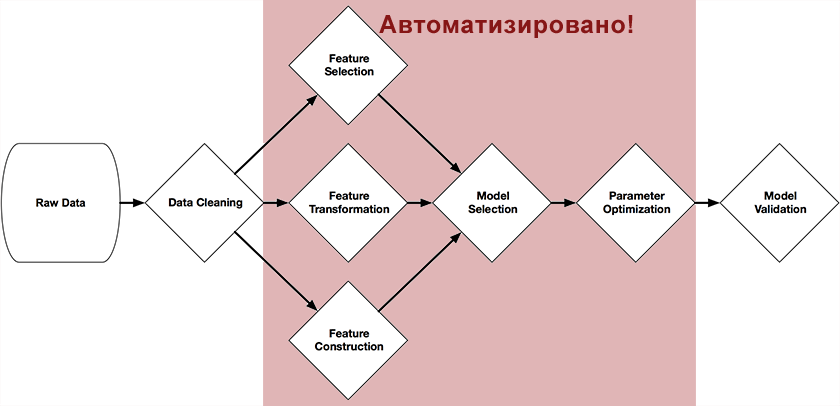
Randy Olson, seorang mahasiswa pascasarjana di Computational Genetics Lab (University of Pennsylvania), mengembangkan Alat Optimalisasi Pipeline Berbasis Pohon sebagai bagian dari proyek kelulusannya .Sistem ini diposisikan sebagai asisten Ilmu Data. Ini mengotomatiskan bagian paling membosankan dari pembelajaran mesin, mempelajari dan memilih di antara ribuan rantai bangunan yang mungkin tepat yang paling cocok untuk memproses data Anda.Sistem ini ditulis dalam Python menggunakan perpustakaan scikit-learn, dan melalui algoritma genetika secara mandiri membangun rangkaian lengkap persiapan dan konstruksi model. Gambar di awal artikel ini menyajikan bagian-bagian rantai yang dapat diotomatisasi dengan bantuannya: preprocessing dan pemilihan prediktor, pemilihan model, optimalisasi parameternya.Idenya cukup sederhana - suatu algoritma genetika .Ini adalah algoritma untuk menemukan rantai yang kita butuhkan dengan seleksi acak, menggunakan mekanisme yang mirip dengan seleksi alam di alam. Mereka ditulis dengan cukup detail tentang mereka di Wikipedia , di Habr , atau di buku "Sistem belajar mandiri"(Saya sarankan bagi mereka yang tertarik dengan topik ini, ada jaringan dalam bentuk elektronik).Sebagai fungsi seleksi (fungsi Kebugaran), akurasi prediksi dalam sampel uji digunakan, karena objek populasi adalah metode scikit dan parameternya.Hasil
Penulis menyajikan contoh sederhana tentang bagaimana menggunakan TPOT untuk menyelesaikan masalah referensi untuk klasifikasi digit tulisan tangan dari set MNISTfrom tpot import TPOT
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75)
tpot = TPOT(generations=5, verbosity=2)
tpot.fit(X_train, y_train)
print( tpot.score(X_train, y_train, X_test, y_test) )
tpot.export('tpot_exported_pipeline.py')
Ketika Anda menjalankan kode, setelah beberapa menit, TPOT bisa mendapatkan rantai pembuatan model, yang akurasinya mencapai 98%. Ini akan terjadi ketika TPOT menemukan bahwa pengelompokan Acak Hutan bekerja dengan sempurna pada data MNIST.Benar, karena proses ini probabilistik, disarankan untuk mengatur parameter random_state untuk hasil yang berulang - misalnya, selama 5 generasi saya hanya menemukan rantai dengan SVC dan KNeighborsClassifier.Menguji sistem pada masalah klasik lain, iris Fisher , memberikan akurasi 97% selama 10 generasi.Masa depan
Trot adalah proyek sumber terbuka yang muncul sebulan yang lalu (yang umumnya merupakan usia anak untuk sistem semacam itu) dan sekarang sedang aktif berkembang. Di situs web proyek, penulis mendorong komunitas Data Scientists untuk bergabung dengan pengembangan sistem yang kodenya tersedia di github (https://github.com/rhiever/tpot)Tentu saja, sekarang sistem ini sangat jauh dari ideal, tetapi gagasan sistem ini terlihat sangat logis - otomatisasi penuh seluruh proses pembelajaran mesin. Dan jika idenya berkembang, maka mungkin sistem akan segera muncul di mana seseorang hanya perlu mengunduh data dan mendapatkan hasilnya. Dan kemudian pertanyaan lain akan muncul: Apakah seseorang diperlukan untuk membangun model belajar mandiri?