Apakah AlphaGo memiliki peluang dalam pertandingan melawan Lee Sedol: pendapat dan peringkat pemain profesional di th
Google go-pro 9 pertandingan dan Google AI akan berlangsung pada bulan Maret
 Tidak ada komputer yang mampu mengalahkan pemain profesional di Asian board game go. Masalahnya adalah tentang fitur permainan: ada terlalu banyak posisi, dan sulit untuk menggambarkan intuisi manusia secara algoritmik. Dunia memiliki pandangan serupa hingga 27 Januari. Beberapa hari yang lalu, Google menerbitkan data penelitian dari divisi DeepMind-nya . Ini berbicara tentang sistem AlphaGo, yang pada Oktober tahun lalu mampu mengalahkan pemain kedua profesional Dan Fan dalam 5 dari lima pertandingan.Namun demikian, pemain profesional dan kenalan dari go memiliki pertanyaan tentang kualitas permainan. Hui adalah juara tiga kali, tetapi ia adalah juara Eropa, di mana level permainannya tidak terlalu tinggi. Bukan hanya pilihan pemain untuk menunjukkan kekuatan AlphaGo yang menimbulkan pertanyaan, tetapi juga beberapa gerakan dalam permainan.
Tidak ada komputer yang mampu mengalahkan pemain profesional di Asian board game go. Masalahnya adalah tentang fitur permainan: ada terlalu banyak posisi, dan sulit untuk menggambarkan intuisi manusia secara algoritmik. Dunia memiliki pandangan serupa hingga 27 Januari. Beberapa hari yang lalu, Google menerbitkan data penelitian dari divisi DeepMind-nya . Ini berbicara tentang sistem AlphaGo, yang pada Oktober tahun lalu mampu mengalahkan pemain kedua profesional Dan Fan dalam 5 dari lima pertandingan.Namun demikian, pemain profesional dan kenalan dari go memiliki pertanyaan tentang kualitas permainan. Hui adalah juara tiga kali, tetapi ia adalah juara Eropa, di mana level permainannya tidak terlalu tinggi. Bukan hanya pilihan pemain untuk menunjukkan kekuatan AlphaGo yang menimbulkan pertanyaan, tetapi juga beberapa gerakan dalam permainan.Algoritma
Guo telah lama dianggap sebagai permainan untuk melatih di mana kecerdasan buatan sulit karena ruang pencarian yang sangat besar dan kompleksitas pilihan gerakan. Go termasuk dalam kelas permainan dengan informasi yang sempurna, yaitu, pemain mengetahui semua gerakan yang dilakukan pemain lain sebelumnya. hasil pertandingan solusi masalah pencarian melibatkan menghitung nilai optimal dari fungsi di pohon pencarian yang berisi tentang b d mungkin bergerak. Di sini b adalah jumlah gerakan yang benar di setiap posisi, dan d adalah panjang permainan. Untuk catur, nilai-nilai ini adalah b ≈ 35 dan d ≈ 80, dan pencarian lengkap tidak dimungkinkan. Oleh karena itu, posisi angka dievaluasi, dan kemudian penilaian diperhitungkan dalam pencarian. Pada tahun 1996, untuk pertama kalinya, komputer memenangkan catur melawan juara, dan sejak 2005, tidak ada juara yang mampu mengalahkan komputer.Untuk go b ≈ 250, d ≈ 150. Posisi batu yang mungkin pada papan standar lebih dari googol (10 100 ) kali lebih banyak daripada dalam catur. Jumlah posisi yang mungkin lebih besar daripada atom di alam semesta. Yang memperumit situasinya adalah sulit untuk memperkirakan nilai kondisi karena kompleksitas permainan. Dua pemain menempatkan batu dua warna pada papan ukuran tertentu, bidang standar adalah 19 × 19 garis. Aturannya bervariasi dalam rincian, tetapi tujuan utama permainan ini sederhana: Anda perlu memagari area yang lebih besar di papan dengan batu warna Anda daripada lawan Anda.Program-program yang ada dapat diputar di tingkat amatir. Mereka menggunakan pencarian di pohon Monte Carlo untuk mengevaluasi nilai setiap negara di pohon pencarian. Program-program juga mencakup kebijakan yang memprediksi pergerakan pemain yang kuat.Baru-baru ini, jaringan saraf convolutional yang mendalam telah mampu mencapai hasil yang baik dalam pengenalan wajah dan klasifikasi gambar. Di Google, AI bahkan belajar memainkan 49 game Atari sendiri . Dalam AlphaGo, jaringan saraf yang sama menafsirkan posisi batu di papan, yang membantu untuk mengevaluasi dan memilih gerakan. Di Google, peneliti mengambil pendekatan berikut: mereka menggunakan jaringan nilai dan jaringan kebijakan. Kemudian jaringan saraf yang dalam ini dilatih baik pada kelompok orang, maupun pada permainan melawan salinan mereka. Pencarian juga baru, menggabungkan metode Monte Carlo dengan jaringan politik dan nilai. Skema dan arsitektur pelatihan jaringan saraf.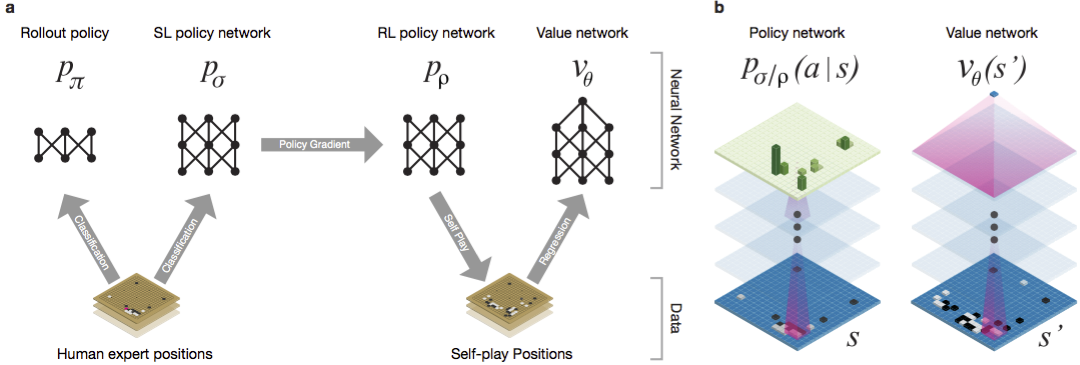 Jaringan saraf dilatih dalam beberapa tahap pembelajaran mesin. Pada awalnya, pelatihan terkontrol jaringan kebijakan dilakukan langsung menggunakan gerakan pemain manusia. Jaringan kebijakan lain telah diperkuat pembelajaran. Yang kedua dimainkan dengan yang pertama dan dioptimalkan sehingga kebijakan bergeser ke kemenangan, dan bukan hanya prediksi bergerak. Akhirnya, pelatihan dilakukan, diperkuat oleh jaringan nilai yang memprediksi pemenang game yang dimainkan oleh jaringan kebijakan. Hasil akhirnya adalah AlphaGo, kombinasi dari metode Monte Carlo dan jaringan politik dan nilai. Hasil prediksi yang benar dari langkah selanjutnya dicapai dalam 57% kasus. Sebelum ke AlphaGo, hasil terbaik adalah 44% .160 ribu game dengan 29,4 juta posisi dari server KGS digunakan sebagai input untuk pelatihan. Pesta para pemain dari keenam dan kesembilan diambil. Satu juta posisi dialokasikan untuk tes, dan pelatihan itu sendiri dilakukan untuk 28,4 juta posisi. Kekuatan dan akurasi kebijakan dan nilai-nilai jaringan.
Agar algoritme berfungsi, mereka membutuhkan beberapa urutan kekuatan komputasi yang lebih besar daripada dengan pencarian tradisional. AlphaGo adalah program multi-threaded asinkron yang melakukan simulasi pada inti prosesor pusat dan menjalankan jaringan kebijakan dan nilai pada chip video. Versi terakhir terlihat seperti aplikasi 40-threaded yang berjalan pada 48 prosesor (mungkin berarti kernel yang terpisah atau bahkan hyper-threading) dan 8 akselerator grafis. Versi terdistribusi dari AlphaGo juga dibuat, yang menggunakan beberapa mesin, 40 aliran pencarian, 1202 core dan 176 akselerator video.
Jaringan saraf dilatih dalam beberapa tahap pembelajaran mesin. Pada awalnya, pelatihan terkontrol jaringan kebijakan dilakukan langsung menggunakan gerakan pemain manusia. Jaringan kebijakan lain telah diperkuat pembelajaran. Yang kedua dimainkan dengan yang pertama dan dioptimalkan sehingga kebijakan bergeser ke kemenangan, dan bukan hanya prediksi bergerak. Akhirnya, pelatihan dilakukan, diperkuat oleh jaringan nilai yang memprediksi pemenang game yang dimainkan oleh jaringan kebijakan. Hasil akhirnya adalah AlphaGo, kombinasi dari metode Monte Carlo dan jaringan politik dan nilai. Hasil prediksi yang benar dari langkah selanjutnya dicapai dalam 57% kasus. Sebelum ke AlphaGo, hasil terbaik adalah 44% .160 ribu game dengan 29,4 juta posisi dari server KGS digunakan sebagai input untuk pelatihan. Pesta para pemain dari keenam dan kesembilan diambil. Satu juta posisi dialokasikan untuk tes, dan pelatihan itu sendiri dilakukan untuk 28,4 juta posisi. Kekuatan dan akurasi kebijakan dan nilai-nilai jaringan.
Agar algoritme berfungsi, mereka membutuhkan beberapa urutan kekuatan komputasi yang lebih besar daripada dengan pencarian tradisional. AlphaGo adalah program multi-threaded asinkron yang melakukan simulasi pada inti prosesor pusat dan menjalankan jaringan kebijakan dan nilai pada chip video. Versi terakhir terlihat seperti aplikasi 40-threaded yang berjalan pada 48 prosesor (mungkin berarti kernel yang terpisah atau bahkan hyper-threading) dan 8 akselerator grafis. Versi terdistribusi dari AlphaGo juga dibuat, yang menggunakan beberapa mesin, 40 aliran pencarian, 1202 core dan 176 akselerator video.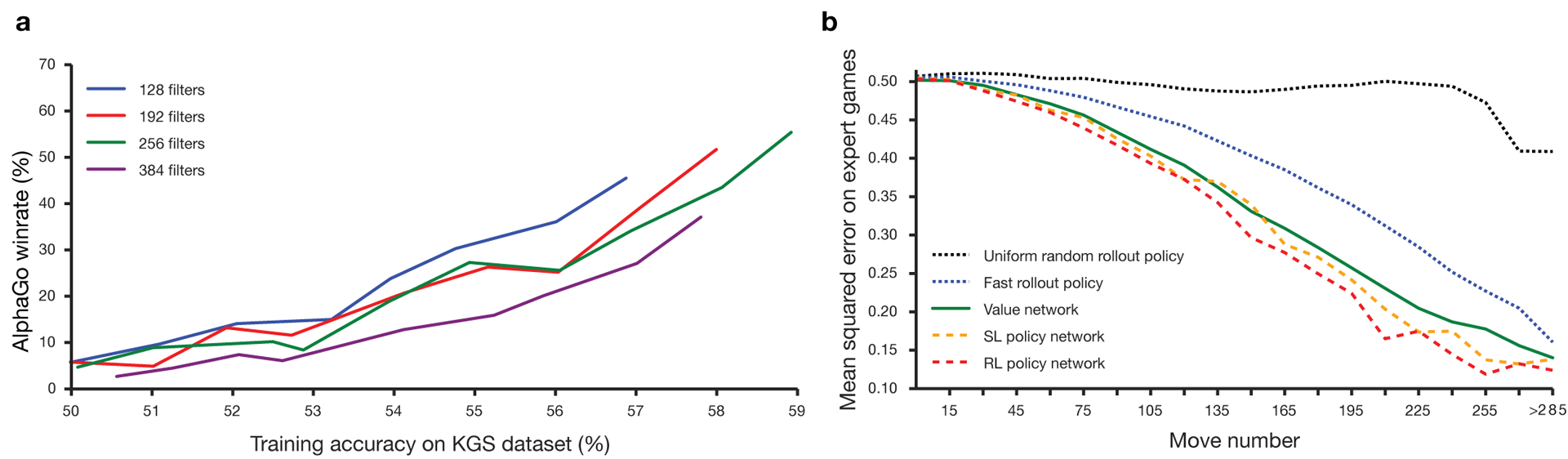 Laporan DeepMind lengkap dapat ditemukan di dokumen . Cari Monte Carlo di AlphaGo.
Untuk menilai kemampuan AlphaGo, pertandingan internal diadakan melawan versi lain dari program, serta produk sejenis lainnya. Termasuk perbandingan dilakukan dengan program komersial populer seperti Crazy Stone dan Zen, dan proyek open source terkuat Pachi dan Fuego. Semuanya didasarkan pada algoritma Monte Carlo berkinerja tinggi. Tetapi juga AlphaGo dibandingkan dengan non-Monte Carlo GnuGo. Program diberikan 5 detik per gerakan. Perbandingan dibuat dari AlphaGo yang berjalan pada satu mesin dan versi terdistribusi dari algoritma.
Laporan DeepMind lengkap dapat ditemukan di dokumen . Cari Monte Carlo di AlphaGo.
Untuk menilai kemampuan AlphaGo, pertandingan internal diadakan melawan versi lain dari program, serta produk sejenis lainnya. Termasuk perbandingan dilakukan dengan program komersial populer seperti Crazy Stone dan Zen, dan proyek open source terkuat Pachi dan Fuego. Semuanya didasarkan pada algoritma Monte Carlo berkinerja tinggi. Tetapi juga AlphaGo dibandingkan dengan non-Monte Carlo GnuGo. Program diberikan 5 detik per gerakan. Perbandingan dibuat dari AlphaGo yang berjalan pada satu mesin dan versi terdistribusi dari algoritma.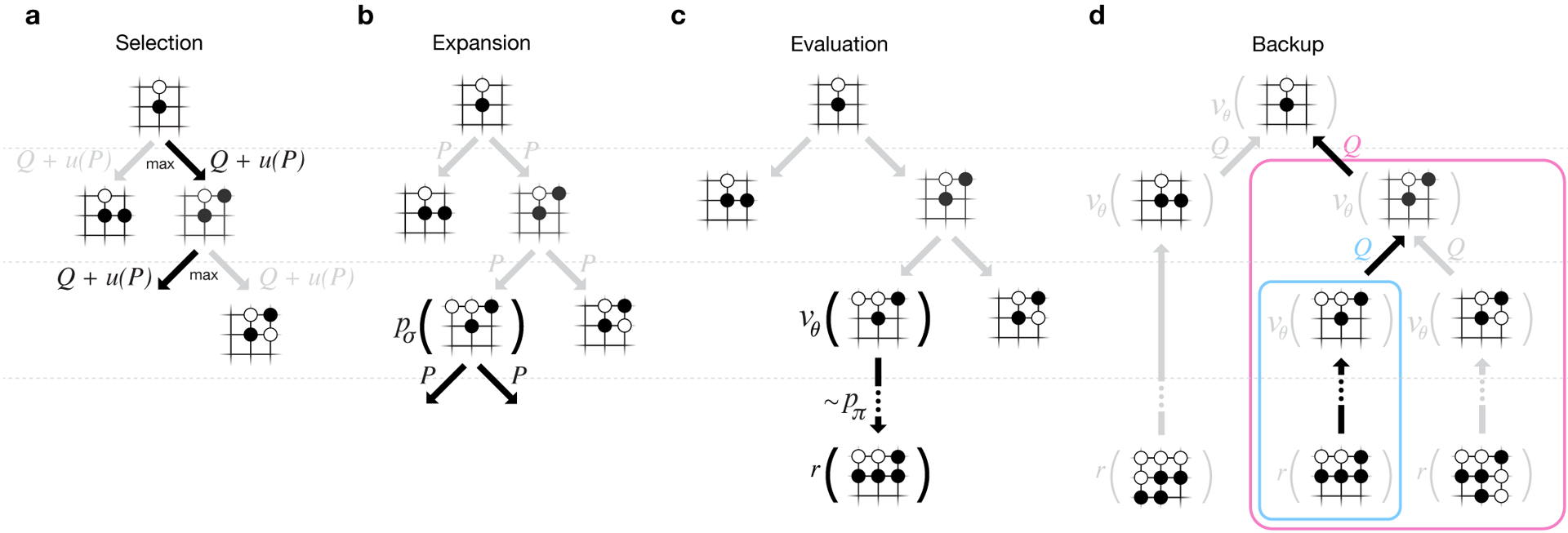 Menurut pengembang, hasilnya menunjukkan bahwa AlphaGo jauh lebih kuat daripada go-program sebelumnya. AlphaGo memenangkan 494 dari 495 game, yang merupakan 99,8% pertandingan melawan produk sejenis lainnya. Aturan Go memungkinkan handicap , handicap: hingga 9 batu hitam dapat diatur di lapangan sebelum bergerak putih. Tetapi bahkan dengan 4 batu handicap, mesin tunggal AlphaGo memenangkan 77%, 86% dan 99% dari waktu melawan Crazy Stone, Zen dan Pachi, masing-masing. Versi terdistribusi dari AlphaGo secara signifikan lebih kuat: di 77% game, ia mengalahkan versi mesin tunggal dan 100% game - semua program lain. AlphaGo vs program lain.
Menurut pengembang, hasilnya menunjukkan bahwa AlphaGo jauh lebih kuat daripada go-program sebelumnya. AlphaGo memenangkan 494 dari 495 game, yang merupakan 99,8% pertandingan melawan produk sejenis lainnya. Aturan Go memungkinkan handicap , handicap: hingga 9 batu hitam dapat diatur di lapangan sebelum bergerak putih. Tetapi bahkan dengan 4 batu handicap, mesin tunggal AlphaGo memenangkan 77%, 86% dan 99% dari waktu melawan Crazy Stone, Zen dan Pachi, masing-masing. Versi terdistribusi dari AlphaGo secara signifikan lebih kuat: di 77% game, ia mengalahkan versi mesin tunggal dan 100% game - semua program lain. AlphaGo vs program lain.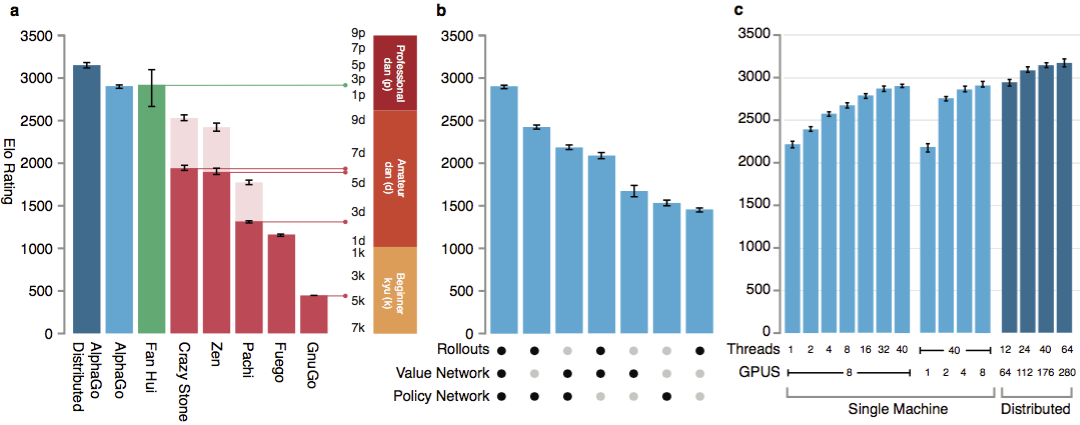 Akhirnya, produk yang dibuat dibandingkan dengan seseorang. Pemain profesional 2 dan berjuang melawan versi terdistribusi dari AlphaGo, Fan Hui, pemenang Kejuaraan Go Eropa pada 2013, 2014 dan 2015. Permainan diadakan dengan partisipasi seorang hakim dari British Federation of go dan editor jurnal Nature. 5 pertandingan digelar pada periode 5 hingga 9 Oktober 2015. Semuanya memenangkan algoritma pengembangan Google DeepMind. Ini adalah game-game yang mengarah pada pernyataan bahwa komputer adalah yang pertama yang bisa mengalahkan pemain profesional. Selain 5 partai resmi, 5 partai tidak resmi diadakan, yang tidak dihitung. Fan memenangkan dua dari mereka.Tersedia rekaman bergerak lima pertandingan , melihat di web widget , dan video di YouTube .
Akhirnya, produk yang dibuat dibandingkan dengan seseorang. Pemain profesional 2 dan berjuang melawan versi terdistribusi dari AlphaGo, Fan Hui, pemenang Kejuaraan Go Eropa pada 2013, 2014 dan 2015. Permainan diadakan dengan partisipasi seorang hakim dari British Federation of go dan editor jurnal Nature. 5 pertandingan digelar pada periode 5 hingga 9 Oktober 2015. Semuanya memenangkan algoritma pengembangan Google DeepMind. Ini adalah game-game yang mengarah pada pernyataan bahwa komputer adalah yang pertama yang bisa mengalahkan pemain profesional. Selain 5 partai resmi, 5 partai tidak resmi diadakan, yang tidak dihitung. Fan memenangkan dua dari mereka.Tersedia rekaman bergerak lima pertandingan , melihat di web widget , dan video di YouTube .Kritik dari pemain profesional
Pilihan pemain profesional dan permainan lemah sang juara dipertanyakan. Aturan yang dipilih juga tidak jelas: satu jam per game, bukan beberapa jam game serius. Namun, format itu dipilih oleh Hui sendiri. Pada bulan Maret, AlphaGo akan bermain melawan Lee Sedola. Bisakah algoritma mengalahkan profesional Korea dari Dan kesembilan, dianggap sebagai salah satu pemain terbaik di dunia? Yang dipertaruhkan adalah satu juta dolar. Jika seseorang menang, Li Sedol akan menerimanya, jika algoritma menang, dia akan pergi ke amal.Para peneliti mengatakan bahwa selama pertempuran Oktober dengan manusia, sistem AlphaGo dianggap posisi ribuan kali lebih sedikit daripada Deep Blue selama pertandingan bersejarah dengan Kasparov. Sebaliknya, program ini menggunakan jaringan kebijakan untuk pilihan yang lebih cerdas dan jaringan nilai untuk mengukur posisi dengan lebih akurat. Mungkin pendekatan ini lebih dekat dengan cara orang bermain, kata para peneliti. Selain itu, sistem penilaian Deep Blue diprogram secara manual, sementara jaringan saraf AlphaGo dilatih langsung dari game menggunakan algoritma universal pembelajaran terbimbing dan pembelajaran penguatan. Lee Sedoll akan mencoba tangannya melawan AlphaGo pada bulan Maret. Pemain profesional memiliki sudut pandang yang berbeda. Tampaknya bagi beberapa orang bahwa Google secara khusus memilih bukan pemain yang sangat kuat, seseorang yakin Sedol akan kehilangan Maret ini.Salah satu pemain profesional berbahasa Inggris terkuat yang ada, Kim Mengwang (kesembilan dan) percaya bahwa Fan Hui tidak bermain dengan kekuatan penuh. Pada menit ke-51 video, ia memberikan contoh nyata dari angsuran kedua. Fan mungkin memainkan keduanya dengan yang lebih lemah untuk menguji kekuatan komputer, kata Kim. Mengwan mengakui bahwa AlphaGo adalah program yang sangat kuat, tetapi tidak mungkin untuk mengalahkan Lee Sedol.Wasit pertandingan, Toby Manning, mengatakan kepada British Go Journal tentang pertandingan tersebut. Dia menganalisis semua lima pertandingan dan menyoroti beberapa poin. AlphaGo membuat kesalahan di game kedua, ketiga dan keempat, tetapi Fan tidak menggunakannya. Juara Eropa tiga kali menjawab dengan pertanyaannya sendiri. Artikel di majalah berakhir dengan penilaian positif umum oleh AlphaGo: program ini kuat, tetapi tidak jelas berapa banyak.Juga, ketika menyiapkan materi, saya menerima komentar dari para profesional Rusia dan pecinta pergi. Alexander Dinerstein (Kazan), ketiga dan (profesional), juara Eropa tujuh kali:
Pemain profesional memiliki sudut pandang yang berbeda. Tampaknya bagi beberapa orang bahwa Google secara khusus memilih bukan pemain yang sangat kuat, seseorang yakin Sedol akan kehilangan Maret ini.Salah satu pemain profesional berbahasa Inggris terkuat yang ada, Kim Mengwang (kesembilan dan) percaya bahwa Fan Hui tidak bermain dengan kekuatan penuh. Pada menit ke-51 video, ia memberikan contoh nyata dari angsuran kedua. Fan mungkin memainkan keduanya dengan yang lebih lemah untuk menguji kekuatan komputer, kata Kim. Mengwan mengakui bahwa AlphaGo adalah program yang sangat kuat, tetapi tidak mungkin untuk mengalahkan Lee Sedol.Wasit pertandingan, Toby Manning, mengatakan kepada British Go Journal tentang pertandingan tersebut. Dia menganalisis semua lima pertandingan dan menyoroti beberapa poin. AlphaGo membuat kesalahan di game kedua, ketiga dan keempat, tetapi Fan tidak menggunakannya. Juara Eropa tiga kali menjawab dengan pertanyaannya sendiri. Artikel di majalah berakhir dengan penilaian positif umum oleh AlphaGo: program ini kuat, tetapi tidak jelas berapa banyak.Juga, ketika menyiapkan materi, saya menerima komentar dari para profesional Rusia dan pecinta pergi. Alexander Dinerstein (Kazan), ketiga dan (profesional), juara Eropa tujuh kali:Deep Blue . , , , . Google . .
4-4 ( -, starpoint ). . : 3-3, 3-4, 5-3, , , , . , . .
, , . . – , . , - . . 20-30 , , , , . , . , . .
, - 2016 (EGC), dalam kerangka di mana turnamen program komputer selalu terjadi. Federasi Rusia Go mengundang semua program terkuat untuk berpartisipasi dalam turnamen. Jika mereka menerima undangan, maka mungkin di turnamen ini untuk pertama kalinya program Google dan Facebook akan bermain di antara mereka sendiri. Yang terakhir, tidak seperti pesaingnya, mengikuti jalur yang jujur. Bot DarkForest memainkan ribuan game di server KGS . Versi terkuat mendekati Dan keenam di server. Ini adalah level yang sangat bagus. Fan Hui dan pemain levelnya - ini adalah tentang Dan kedelapan di server (dari sembilan kemungkinan). Perbedaannya adalah tentang dua cacat batu. Dengan perbedaan seperti itu, suatu program terkadang dapat benar-benar mengalahkan seseorang. Jika dengan persyaratan yang sama, maka kira-kira dalam satu batch sepuluh.
Maxim Podolyak, (St. Petersburg), Wakil Presiden Federasi Rusia Go:, , , , , , , , . , Google : , . , . : , , , . , : , . Google . , . ? ?
Alexander Krainov (Moskow), pencinta permainan:Karena aktivitas profesional saya, saya tahu situasinya cukup baik "dari sisi lain".
Pada 2012, ada lompatan kuantum dalam pembelajaran mesin secara umum. Jumlah data untuk pelatihan, tingkat algoritma dan kekuatan untuk pelatihan telah mencapai tingkat yang membuat jaringan saraf tiruan (dikembangkan sebagai prinsip untuk waktu yang lama) mulai memberikan hasil yang fantastis.
Perbedaan mendasar antara pelatihan pada jaringan saraf adalah bahwa mereka tidak perlu diberi faktor input (dalam kasus go, jelaskan, misalnya, bentuk mana yang baik). Dalam batas itu, bahkan aturannya tidak bisa dijelaskan kepada mereka. Hal utama adalah memberikan sejumlah besar contoh positif (gerakan pihak yang menang) dan negatif (gerakan pihak yang kalah). Dan jaringan akan belajar sendiri.
, , . . : , , ( ) , .
, .
, , , . . . . , , .
Apa yang dikatakan Lee Sedol sendiri
Pemain go profesional bersaing bukan untuk gelar dunia, tetapi untuk gelar. Pengakuan dan status master ditentukan oleh jumlah judul yang bisa dia dapatkan selama tahun itu. Lee Sedol adalah salah satu dari lima pemain go terkuat di dunia, dan pada bulan Maret tahun ini ia harus bertarung dengan sistem AlphaGo.Sang juara Korea sendiri memperkirakan bahwa ia akan menang dengan skor 4-1 atau 5-0. Tetapi setelah 2-3 tahun, Google akan ingin membalas dendam, dan kemudian permainan dengan versi terbaru dari AlphaGo akan lebih menarik, kata Lee.
Tugas menciptakan algoritma seperti itu menimbulkan pertanyaan baru tentang apa itu pembelajaran dan pemikiran. Seperti yang diingatkan oleh M. Emelyanov, tingkat keterampilan (pin) ketiga dari atas menurut klasifikasi Cina kuno disebut “kejelasan lengkap”. Level permainan seperti itu menunjukkan bahwa keputusan dibuat secara intuitif, dengan sedikit atau tanpa pilihan. Salah satu penguasa terkuat abad ke-20, Guo Seigen, mengatakan bahwa bagi dia sepertinya dia akan menang melawan "go-god" dengan mengambil dua atau tiga batu handicap. Seigan percaya bahwa dia hampir mencapai batas memahami permainan. Bisakah jaringan saraf mencapai ini? Mungkin intuisi manusia adalah algoritma yang ditetapkan oleh alam?Penulis berterima kasih kepada Alexander Dinerstein dan go_secrets publik atas komentar dan bantuannya dalam publikasi ini.Source: https://habr.com/ru/post/id389825/
All Articles