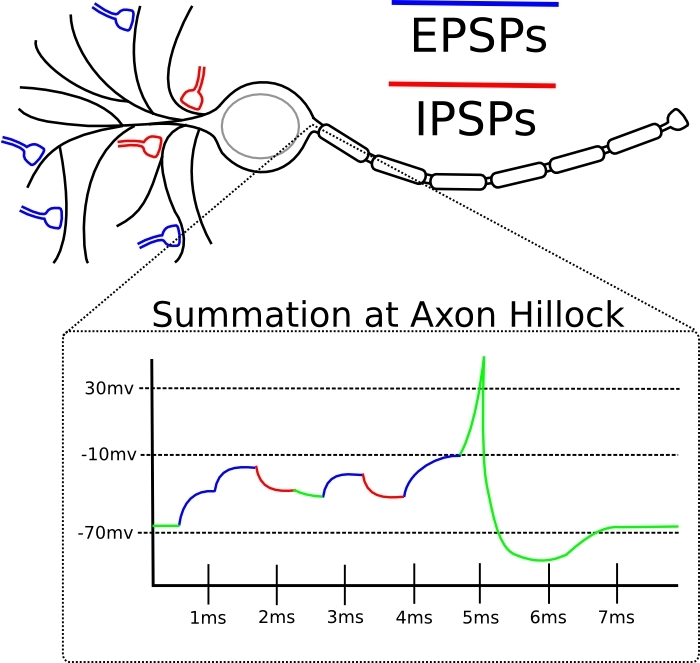
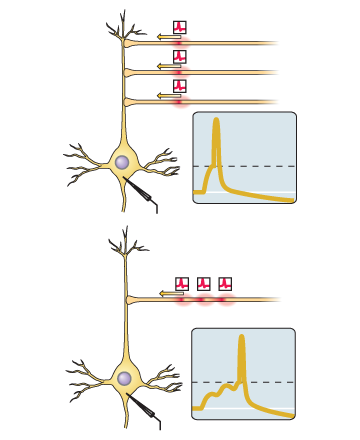
Jika lonjakan input untuk sinaps ini cenderung datang tepat sebelum neuron itu sendiri yang menghasilkan spike, maka sinaps tersebut diperkuat.Jika lonjakan input untuk sinaps ini cenderung datang segera setelah pembuatan lonjakan oleh neuron itu sendiri, maka sinaps tersebut melemah.
Source: https://habr.com/ru/post/id390385/More articles:15 лет первому контакту земного аппарата с астероидомJumlah pengguna situs dan aplikasi untuk kencan online berkembang pesatUbuntu Tablet: "semua yang Anda butuhkan dari PC ada di tablet"Apakah Anda terlalu banyak bekerja? Liburan tidak akan membantu14 Februari - Hari Lawrence: Hadiah untuk Orang yang Anda CintaiPemegang Hak menemukan cara baru untuk mengubah bajak laut menjadi pengguna yang membayarTeknologi FRAMKualitas komunikasi - aplikasi Android dari Kementerian KomunikasiCara membangkitkan game yang menarik dalam sejarah atau meja bundar WargamingУмный банковский троян позволяет снимать почти неограниченное количество денег в банкоматахAll Articles