 Kebetulan bahwa bahasa utama untuk bekerja dengan mikrokontroler adalah C. Banyak proyek besar ditulis di atasnya. Tetapi hidup tidak berhenti. Alat pengembangan modern telah lama dapat menggunakan C ++ ketika mengembangkan perangkat lunak untuk sistem embedded. Namun, pendekatan ini masih jarang. Belum lama ini, saya mencoba menggunakan C ++ ketika mengerjakan proyek lain. Saya akan berbicara tentang pengalaman ini dalam artikel ini.
Kebetulan bahwa bahasa utama untuk bekerja dengan mikrokontroler adalah C. Banyak proyek besar ditulis di atasnya. Tetapi hidup tidak berhenti. Alat pengembangan modern telah lama dapat menggunakan C ++ ketika mengembangkan perangkat lunak untuk sistem embedded. Namun, pendekatan ini masih jarang. Belum lama ini, saya mencoba menggunakan C ++ ketika mengerjakan proyek lain. Saya akan berbicara tentang pengalaman ini dalam artikel ini.Entri
Sebagian besar pekerjaan saya dengan mikrokontroler terhubung dengan C. Pertama, itu adalah persyaratan pelanggan, dan kemudian menjadi kebiasaan. Pada saat yang sama, ketika datang ke aplikasi Windows, C ++ digunakan di sana terlebih dahulu, dan kemudian C # secara umum.Tidak ada pertanyaan tentang C atau C ++ untuk waktu yang lama. Bahkan rilis versi berikutnya dari Keil's MDK dengan dukungan C ++ untuk ARM tidak terlalu mengganggu saya. Jika Anda melihat proyek demo Keil, semuanya ditulis di sana dalam C. Pada saat yang sama, C ++ dipindahkan ke folder terpisah bersama dengan proyek Blinky. CMSIS dan LPCOpen juga ditulis dalam C. Dan jika "semua orang" menggunakan C, maka ada beberapa alasan.Tetapi banyak yang telah berubah. Net Micro Framework. Jika ada yang tidak tahu, maka ini adalah implementasi .Net yang memungkinkan Anda untuk menulis aplikasi untuk mikrokontroler di C # di Visual Studio. Anda dapat mempelajari lebih lanjut tentang dia diartikel - artikel ini .Jadi, .Net Micro Framework ditulis menggunakan C ++. Terkesan oleh ini, saya memutuskan untuk mencoba menulis proyek lain di C ++. Saya harus segera mengatakan bahwa saya tidak menemukan argumen yang pasti mendukung C ++, tetapi ada beberapa poin yang menarik dan berguna dalam pendekatan ini.Apa perbedaan antara proyek C dan C ++?
Salah satu perbedaan utama antara C dan C ++ adalah yang kedua adalah bahasa berorientasi objek. Enkapsulasi terkenal, polimorfisme, dan pewarisan adalah hal biasa di sini. C adalah bahasa prosedural. Hanya ada fungsi dan prosedur, dan untuk pengelompokan logis dari kode, modul digunakan (sepasang .h + .c). Tetapi jika Anda melihat dekat pada bagaimana C digunakan dalam mikrokontroler, Anda dapat melihat pendekatan berorientasi objek yang biasa.Mari kita lihat kode untuk bekerja dengan LED dari contoh Keil untuk MCB1000 ( Keil_v5 \ ARM \ Board \ Keil \ MCB1000 \ MCB11C14 \ CAN_Demo ):LED.h:#ifndef __LED_H
#define __LED_H
#define LED_NUM 8
extern void LED_init(void);
extern void LED_on (uint8_t led);
extern void LED_off (uint8_t led);
extern void LED_out (uint8_t led);
#endif
LED.c:#include "LPC11xx.h"
#include "LED.h"
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
void LED_init (void) {
LPC_SYSCON->SYSAHBCLKCTRL |= (1UL << 6);
LPC_GPIO2->DIR |= (led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
LPC_GPIO2->DATA &= ~(led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
}
void LED_on (uint8_t num) {
LPC_GPIO2->DATA |= led_mask[num];
}
void LED_off (uint8_t num) {
LPC_GPIO2->DATA &= ~led_mask[num];
}
void LED_out(uint8_t value) {
int i;
for (i = 0; i < LED_NUM; i++) {
if (value & (1<<i)) {
LED_on (i);
} else {
LED_off(i);
}
}
}
Jika Anda melihat lebih dekat, Anda bisa memberikan analogi dengan OOP. LED adalah objek yang memiliki satu konstanta publik, konstruktor, 3 metode publik, dan satu bidang pribadi:class LED
{
private:
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
public:
unsigned char LED_NUM=8;
public:
LED();
void on (uint8_t led);
void off (uint8_t led);
void out (uint8_t led);
}
Terlepas dari kenyataan bahwa kode tersebut ditulis dalam C, ia menggunakan paradigma pemrograman objek. File .C adalah objek yang memungkinkan Anda untuk merangkum dalam mekanisme implementasi metode publik yang dijelaskan dalam file .h. Tetapi tidak ada warisan di sini, dan karena itu juga polimorfisme.Sebagian besar kode dalam proyek yang saya temui ditulis dengan gaya yang sama. Dan jika pendekatan OOP digunakan, lalu mengapa tidak menggunakan bahasa yang sepenuhnya mendukungnya? Pada saat yang sama, ketika beralih ke C ++, pada umumnya, hanya sintaks yang akan berubah, tetapi bukan prinsip-prinsip pengembangan.Pertimbangkan contoh lain. Misalkan kita memiliki perangkat yang menggunakan sensor suhu yang terhubung melalui I2C. Tetapi revisi baru dari perangkat keluar dan sensor yang sama sekarang terhubung ke SPI. Apa yang harus dilakukan Penting untuk mendukung revisi pertama dan kedua perangkat, yang berarti bahwa kode harus secara fleksibel memperhitungkan perubahan ini. Di C, Anda dapat menggunakan definisi #define untuk menghindari penulisan dua file yang hampir identik. Sebagai contoh#ifdef REV1
#include “i2c.h”
#endif
#ifdef REV2
#include “spi.h”
#endif
void TEMPERATURE_init()
{
#ifdef REV1
I2C_int()
#endif
#ifdef REV2
SPI_int()
#endif
}
dan sebagainya.Di C ++, Anda bisa menyelesaikan masalah ini sedikit lebih elegan. Buat antarmukaclass ITemperature
{
public:
virtual unsigned char GetValue() = 0;
}
dan membuat 2 implementasiclass Temperature_I2C: public ITemperature
{
public:
virtual unsigned char GetValue();
}
class Temperature_SPI: public ITemperature
{
public:
virtual unsigned char GetValue();
}
Dan kemudian gunakan implementasi ini atau itu tergantung pada revisi:class TemperatureGetter
{
private:
ITemperature* _temperature;
pubic:
Init(ITemperature* temperature)
{
_temperature = temperature;
}
private:
void GetTemperature()
{
_temperature->GetValue();
}
#ifdef REV1
Temperature_I2C temperature;
#endif
#ifdef REV2
Temperature_SPI temperature;
#endif
TemperatureGetter tGetter;
void main()
{
tGetter.Init(&temperature);
}
Tampaknya perbedaannya tidak terlalu besar antara kode C dan C ++. Opsi berorientasi objek terlihat lebih rumit. Tetapi itu memungkinkan Anda untuk membuat keputusan yang lebih fleksibel.Saat menggunakan C, dua solusi utama dapat dibedakan:- Gunakan #define seperti yang ditunjukkan di atas. Opsi ini tidak terlalu bagus karena "mengikis" tanggung jawab modul. Ternyata dia bertanggung jawab atas beberapa revisi proyek. Ketika ada banyak file seperti itu, menjadi sangat sulit untuk memeliharanya.
- 2 , C++. “” , . , #ifdef. , , . , . , , .
Penggunaan polimorfisme memberikan hasil yang lebih indah. Di satu sisi, setiap kelas memecahkan masalah atom yang jelas, di sisi lain, kode tersebut tidak berserakan dan mudah dibaca."Percabangan" kode pada revisi masih harus dilakukan dalam kasus pertama dan kedua, tetapi menggunakan polimorfisme membuatnya lebih mudah untuk mentransfer tempat percabangan antara lapisan program, sementara tidak mengacaukan kode dengan #ifdef yang tidak perlu.Menggunakan polimorfisme membuatnya mudah untuk membuat keputusan yang lebih menarik.Katakanlah revisi baru dirilis, di mana kedua sensor suhu dipasang.Kode yang sama dengan perubahan minimal memungkinkan Anda untuk memilih implementasi SPI dan I2C secara real time, cukup menggunakan metode Init (& suhu).Contohnya sangat disederhanakan, tetapi dalam proyek nyata saya menggunakan pendekatan yang sama untuk mengimplementasikan protokol yang sama di atas dua antarmuka transfer data fisik yang berbeda. Ini membuatnya mudah untuk membuat pilihan antarmuka dalam pengaturan perangkat.Namun, dengan semua hal di atas, perbedaan antara menggunakan C dan C ++ tetap tidak terlalu besar. Keuntungan dari C ++ terkait dengan OOP tidak begitu jelas dan berasal dari kategori "amatir". Tetapi penggunaan C ++ di mikrokontroler memiliki masalah yang cukup serius.Apa bahaya menggunakan C ++?
Perbedaan penting kedua antara C dan C ++ adalah penggunaan memori. Bahasa C sebagian besar statis. Semua fungsi dan prosedur memiliki alamat tetap, dan bekerja dengan banyak dilakukan hanya jika perlu. C ++ adalah bahasa yang lebih dinamis. Biasanya penggunaannya menyiratkan pekerjaan aktif dengan alokasi dan membebaskan memori. Inilah yang C ++ berbahaya. Mikrokontroler memiliki sumber daya yang sangat sedikit, jadi kontrol terhadapnya penting. Penggunaan RAM yang tidak terkendali penuh dengan kerusakan pada data yang disimpan di sana dan "mukjizat" seperti itu dalam pekerjaan program yang sedikit tidak akan terlihat oleh siapa pun. Banyak pengembang mengalami masalah seperti itu.Jika Anda memperhatikan contoh-contoh di atas, dapat dicatat bahwa kelas tidak memiliki konstruktor dan destruktor. Ini karena mereka tidak pernah dibuat secara dinamis.Saat menggunakan memori dinamis (dan saat menggunakan yang baru), fungsi malloc selalu dipanggil, yang mengalokasikan jumlah byte yang diperlukan dari heap. Bahkan jika Anda memikirkannya (meskipun sangat sulit) dan mengontrol penggunaan memori, Anda mungkin menghadapi masalah fragmentasi.Sekelompok dapat direpresentasikan sebagai sebuah array. Misalnya, pilih 20 byte untuknya: Setiap kali memori dialokasikan, seluruh memori dipindai (dari kiri ke kanan atau dari kanan ke kiri - ini tidak begitu penting) untuk keberadaan sejumlah byte yang tidak dihuni. Selain itu, byte-byte ini semuanya harus berada di dekatnya:
Setiap kali memori dialokasikan, seluruh memori dipindai (dari kiri ke kanan atau dari kanan ke kiri - ini tidak begitu penting) untuk keberadaan sejumlah byte yang tidak dihuni. Selain itu, byte-byte ini semuanya harus berada di dekatnya: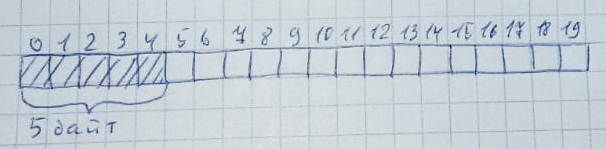 Ketika memori tidak lagi diperlukan, ia kembali ke keadaan semula:Ini dapat dengan mudah terjadi ketika ada cukup byte gratis, tetapi tidak diatur dalam satu baris. Biarkan 10 zona 2 byte masing-masing dialokasikan:
Ketika memori tidak lagi diperlukan, ia kembali ke keadaan semula:Ini dapat dengan mudah terjadi ketika ada cukup byte gratis, tetapi tidak diatur dalam satu baris. Biarkan 10 zona 2 byte masing-masing dialokasikan: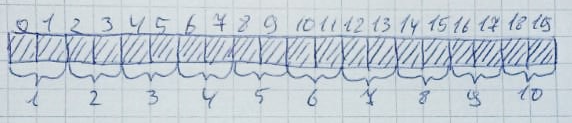 Kemudian 2,4,6,8,10 zona akan dibebaskan:
Kemudian 2,4,6,8,10 zona akan dibebaskan: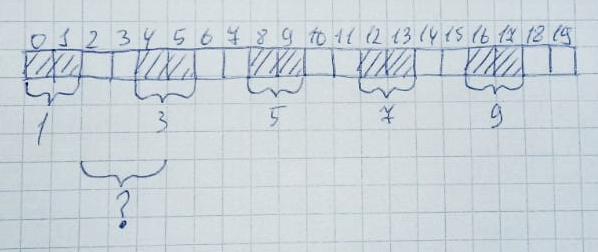 Secara formal, setengah dari seluruh tumpukan (10 byte) tetap gratis. Namun, untuk mengalokasikan area memori berukuran 3 byte masih tidak berfungsi, karena array tidak memiliki 3 sel bebas berturut-turut. Ini disebut fragmentasi memori.Dan untuk menghadapi ini pada sistem tanpa virtualisasi memori cukup sulit. Terutama di proyek-proyek besar.Situasi ini dapat dengan mudah ditiru. Saya melakukan ini di Keil mVision pada mikrokontroler LPC11C24.Atur ukuran heap ke 256 byte:
Secara formal, setengah dari seluruh tumpukan (10 byte) tetap gratis. Namun, untuk mengalokasikan area memori berukuran 3 byte masih tidak berfungsi, karena array tidak memiliki 3 sel bebas berturut-turut. Ini disebut fragmentasi memori.Dan untuk menghadapi ini pada sistem tanpa virtualisasi memori cukup sulit. Terutama di proyek-proyek besar.Situasi ini dapat dengan mudah ditiru. Saya melakukan ini di Keil mVision pada mikrokontroler LPC11C24.Atur ukuran heap ke 256 byte: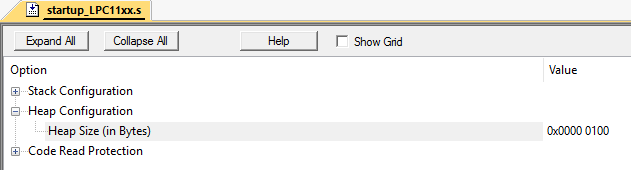 Misalkan kita memiliki 2 kelas:
Misalkan kita memiliki 2 kelas:#include <stdint.h>
class foo
{
private:
int32_t _pr1;
int32_t _pr2;
int32_t _pr3;
int32_t _pr4;
int32_t _pb1;
int32_t _pb2;
int32_t _pb3;
int32_t _pb4;
int32_t _pc1;
int32_t _pc2;
int32_t _pc3;
int32_t _pc4;
public:
foo()
{
_pr1 = 100;
_pr2 = 200;
_pr3 = 300;
_pr4 = 400;
_pb1 = 100;
_pb2 = 200;
_pb3 = 300;
_pb4 = 400;
_pc1 = 100;
_pc2 = 200;
_pc3 = 300;
_pc4 = 400;
}
~foo(){};
int32_t F1(int32_t a)
{
return _pr1*a;
};
int32_t F2(int32_t a)
{
return _pr1/a;
};
int32_t F3(int32_t a)
{
return _pr1+a;
};
int32_t F4(int32_t a)
{
return _pr1-a;
};
};
class bar
{
private:
int32_t _pr1;
int8_t _pr2;
public:
bar()
{
_pr1 = 100;
_pr2 = 10;
}
~bar() {};
int32_t F1(int32_t a)
{
return _pr2/a;
}
int16_t F2(int32_t a)
{
return _pr2*a;
}
};
Seperti yang Anda lihat, kelas bar akan memakan lebih banyak memori daripada foo.14 instance dari kelas bar ditempatkan di heap dan instance kelas foo tidak lagi cocok:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
f = new foo();
}
Jika Anda hanya membuat 7 instance bar, maka foo juga akan dibuat secara normal:int main(void)
{
foo *f;
bar *b[14];
b[1] = new bar();
b[3] = new bar();
b[5] = new bar();
b[7] = new bar();
b[9] = new bar();
b[11] = new bar();
b[13] = new bar();
f = new foo();
}
Namun, jika Anda pertama kali membuat 14 instance bar, maka hapus 0,2,4,6,8,10 dan 12 instance, maka foo tidak akan dapat mengalokasikan memori karena fragmentasi tumpukan:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
delete b[0];
delete b[2];
delete b[4];
delete b[6];
delete b[8];
delete b[10];
delete b[12];
f = new foo();
}
Ternyata Anda tidak dapat menggunakan C ++ sepenuhnya, dan ini adalah minus yang signifikan. Dari sudut pandang arsitektur, C ++, meskipun lebih unggul dari C, tidak signifikan. Akibatnya, transisi ke C ++ tidak membawa manfaat yang signifikan (walaupun tidak ada poin negatif yang besar juga). Jadi, karena perbedaan kecil, pilihan bahasa akan tetap menjadi preferensi pribadi pengembang.Tetapi untuk diri saya sendiri, saya menemukan satu poin positif yang signifikan dalam menggunakan C ++. Faktanya adalah bahwa dengan pendekatan C ++ yang benar, kode untuk mikrokontroler dapat dengan mudah ditutupi dengan unit test di Visual Studio.Nilai tambah besar C ++ adalah kemampuan untuk menggunakan Visual Studio.
Bagi saya pribadi, topik pengujian kode untuk mikrokontroler selalu sangat kompleks. Tentu saja, kode itu diperiksa dalam setiap cara yang mungkin, tetapi pembuatan sistem pengujian otomatis penuh selalu membutuhkan biaya besar, karena itu diperlukan untuk memasang dudukan perangkat keras dan menulis firmware khusus untuk itu. Terutama ketika datang ke sistem IoT terdistribusi yang terdiri dari ratusan perangkat.Ketika saya mulai menulis proyek dalam C ++, saya langsung ingin mencoba memasukkan kode dalam Visual Studio dan menggunakan Keil mVision hanya untuk debugging. Pertama, di Visual Studio, editor kode yang sangat kuat dan nyaman, dan kedua, di Keil mVision sama sekali tidak nyaman integrasi dengan sistem kontrol versi, dan di Visual Studio semuanya bekerja secara otomatis. Ketiga, saya memiliki harapan bahwa saya dapat mengatur setidaknya sebagian dari kode dengan unit test, yang juga didukung dengan baik di Visual Studio. Dan keempat, ini adalah tampilan Resharper C ++ - ekstensi Visual Studio untuk bekerja dengan kode C ++, berkat itu Anda dapat menghindari banyak kesalahan potensial sebelumnya dan memantau gaya kode.Membuat proyek di Visual Studio dan menghubungkannya ke sistem kontrol versi tidak menimbulkan masalah. Tapi saya harus mengotak-atik unit test.Kelas-kelas yang disarikan dari perangkat keras (misalnya, parser protokol) mudah untuk diuji. Tetapi saya menginginkan lebih banyak! Dalam proyek perangkat saya, saya menggunakan file header Keil. Misalnya, untuk LPC11C24 itu adalah LPC11xx.h. File-file ini menggambarkan semua register yang diperlukan sesuai dengan standar CMSIS. Mendefinisikan register spesifik secara langsung dilakukan melalui #define:#define LPC_I2C_BASE (LPC_APB0_BASE + 0x00000)
#define LPC_I2C ((LPC_I2C_TypeDef *) LPC_I2C_BASE )
Ternyata jika Anda benar menimpa register dan membuat beberapa bertopik, maka kode yang menggunakan peripheral sangat baik dapat dikompilasi ke dalam VisualStudio. Tidak hanya itu, jika Anda membuat kelas statis dan menentukan bidangnya sebagai alamat register, Anda akan mendapatkan emulator mikrokontroler lengkap yang memungkinkan Anda untuk sepenuhnya menguji bahkan bekerja dengan periferal:#include <LPC11xx.h>
class LPC11C24Emulator
{
public:
static class Registers
{
public:
static LPC_ADC_TypeDef ADC;
public:
static void Init()
{
memset(&ADC, 0x00, sizeof(LPC_ADC_TypeDef));
}
};
}
#undef LPC_ADC
#define LPC_ADC ((LPC_ADC_TypeDef *) &LPC11C24Emulator::Registers::ADC)
Dan kemudian lakukan ini:#if defined ( _M_IX86 )
#include "..\Emulator\LPC11C24Emulator.h"
#else
#include <LPC11xx.h>
#endif
Dengan cara ini, Anda dapat mengkompilasi dan menguji semua kode proyek untuk mikrokontroler di VisualStudio dengan perubahan minimal.Dalam proses pengembangan proyek di C ++, saya menulis lebih dari 300 tes yang mencakup aspek perangkat keras murni dan kode yang disarikan dari perangkat keras. Selain itu, sekitar 20 kesalahan serius ditemukan sebelumnya, yang, karena ukuran proyek, tidak akan mudah dideteksi tanpa pengujian otomatis.Kesimpulan
Untuk menggunakan atau tidak menggunakan C ++ ketika bekerja dengan mikrokontroler adalah pertanyaan yang agak rumit. Saya menunjukkan di atas bahwa, di satu sisi, keunggulan arsitektural dari OOP penuh tidak begitu besar, dan ketidakmampuan untuk sepenuhnya bekerja dengan sekelompok adalah masalah yang agak besar. Mengingat aspek-aspek ini, tidak ada perbedaan besar antara C dan C ++ untuk bekerja dengan mikrokontroler, pilihan di antara mereka mungkin dapat dibenarkan oleh preferensi pribadi pengembang.Namun, saya berhasil menemukan poin positif besar dalam menggunakan C ++ dalam bekerja dengan Visaul Studio. Ini memungkinkan Anda untuk secara signifikan meningkatkan keandalan pengembangan karena kerja penuh dengan sistem kontrol versi, penggunaan tes unit penuh (termasuk tes untuk bekerja dengan periferal) dan keuntungan lain dari Visual Studio.Saya berharap pengalaman saya akan bermanfaat dan membantu seseorang untuk meningkatkan efektivitas pekerjaan mereka.Pembaruan :Dalam komentar pada versi bahasa Inggris dari artikel ini memberikan tautan yang bermanfaat pada topik ini: