AI menghasilkan suara realistis dalam rekaman
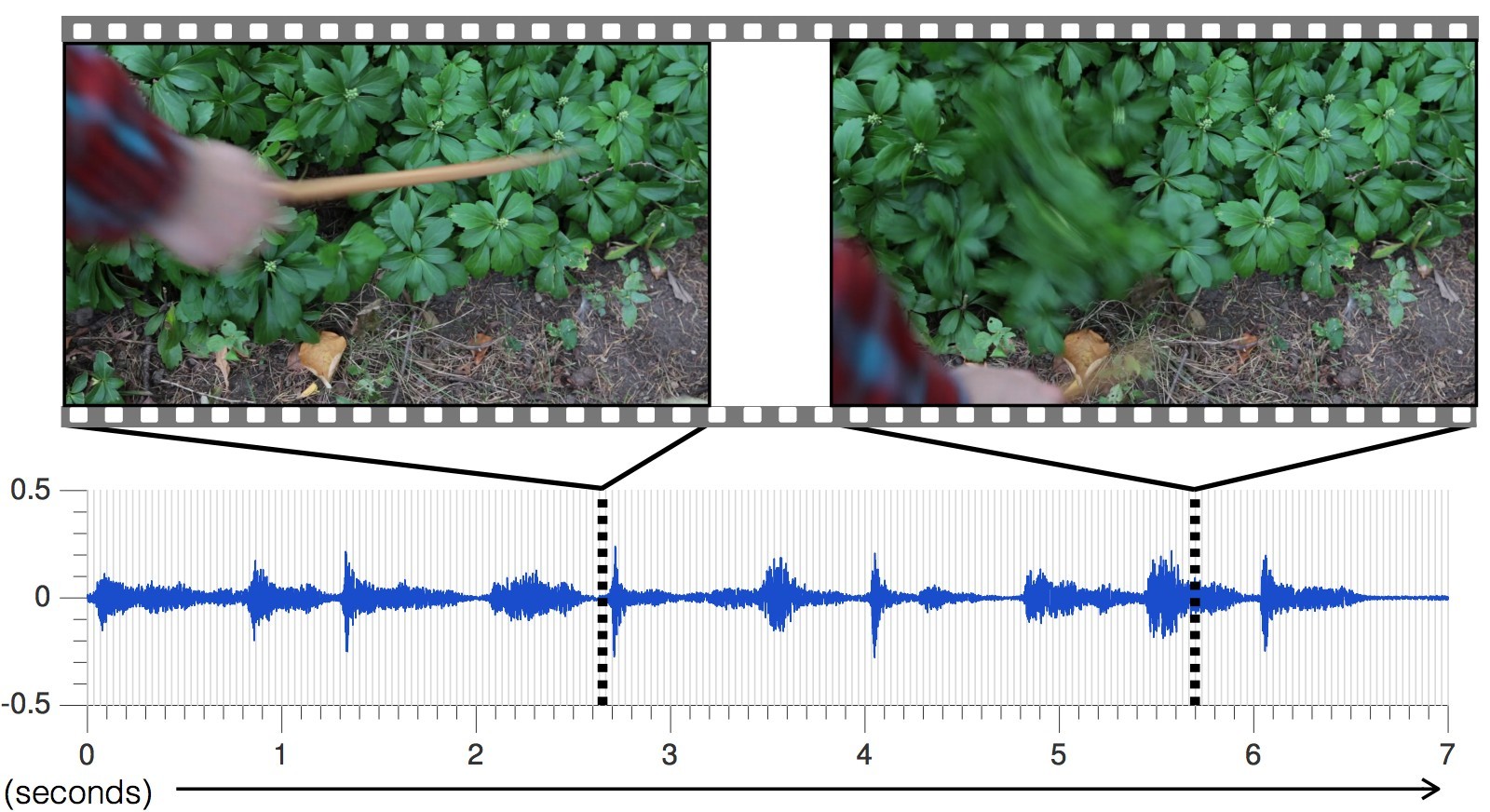 Karyawan di Laboratorium Ilmu Komputer dan Laboratorium Inteligensi Buatan (CSAIL) Institut Teknologi Massachusetts dan unit Penelitian Google merancang jaringan saraf yang belajar membunyikan urutan video yang sewenang-wenang , menghasilkan suara yang realistis, dan memprediksi sifat-sifat objek. Program ini menganalisis video, mengenali objek, pergerakannya dan jenis kontaknya - guncangan, geser, gesekan, dan sebagainya. Berdasarkan informasi ini, menghasilkan suara yang menurut seseorang dalam 40% kasus lebih realistis daripada yang asli.Para ilmuwan menyarankan bahwa perkembangan ini akan banyak digunakan di bioskop dan di televisi untuk menghasilkan efek suara dari urutan video tanpa suara. Selain itu, dapat bermanfaat bagi robot pelatihan untuk lebih memahami sifat-sifat dunia.Suara ambient banyak berbicara tentang sifat-sifat benda di sekitarnya, sehingga dalam proses belajar mandiri, robot masa depan dapat bertindak seperti anak-anak - menyentuh benda, mencobanya dengan sentuhan, menyodokkan tongkat di dalamnya, mencoba bergerak, mengangkat. Dalam hal ini, robot menerima umpan balik, mengenali sifat-sifat objek - beratnya, elastisitas dan sebagainya.Suara yang dibuat oleh suatu objek dalam kontak juga membawa informasi penting tentang sifat-sifat objek. "Ketika Anda menggeser jari Anda di segelas anggur, suara yang Anda buat sesuai dengan jumlah cairan yang dituangkan ke gelas," jelas mahasiswa pascasarjana Andrew Owens , penulis utama makalah ilmiah yang diterbitkan, yang belum siap untuk jurnal ilmiah, tetapi hanya diterbitkantersedia untuk umum di arXiv.org. Presentasi karya ilmiah akan berlangsung di konferensi tahunan tentang visi mesin dan pengenalan pola (CVPR) di Las Vegas bulan ini.Para ilmuwan telah memilih 977 video di mana orang melakukan tindakan dengan benda-benda di sekitarnya, yang terdiri dari berbagai bahan: gores, pukul dengan tongkat, dll. Secara total, video berisi 46.577 tindakan. Siswa CSAIL secara manual menandai semua tindakan, yang menunjukkan jenis bahan, tempat kontak, jenis tindakan (guncangan / goresan / lainnya) dan jenis reaksi dari bahan atau objek (deformasi, bentuk statis, gerakan keras, dll.). Video dengan suara digunakan untuk melatih jaringan saraf, dan tag yang ditempatkan secara manual hanya digunakan untuk menganalisis hasil pelatihan jaringan saraf, tetapi tidak untuk melatih.
Karyawan di Laboratorium Ilmu Komputer dan Laboratorium Inteligensi Buatan (CSAIL) Institut Teknologi Massachusetts dan unit Penelitian Google merancang jaringan saraf yang belajar membunyikan urutan video yang sewenang-wenang , menghasilkan suara yang realistis, dan memprediksi sifat-sifat objek. Program ini menganalisis video, mengenali objek, pergerakannya dan jenis kontaknya - guncangan, geser, gesekan, dan sebagainya. Berdasarkan informasi ini, menghasilkan suara yang menurut seseorang dalam 40% kasus lebih realistis daripada yang asli.Para ilmuwan menyarankan bahwa perkembangan ini akan banyak digunakan di bioskop dan di televisi untuk menghasilkan efek suara dari urutan video tanpa suara. Selain itu, dapat bermanfaat bagi robot pelatihan untuk lebih memahami sifat-sifat dunia.Suara ambient banyak berbicara tentang sifat-sifat benda di sekitarnya, sehingga dalam proses belajar mandiri, robot masa depan dapat bertindak seperti anak-anak - menyentuh benda, mencobanya dengan sentuhan, menyodokkan tongkat di dalamnya, mencoba bergerak, mengangkat. Dalam hal ini, robot menerima umpan balik, mengenali sifat-sifat objek - beratnya, elastisitas dan sebagainya.Suara yang dibuat oleh suatu objek dalam kontak juga membawa informasi penting tentang sifat-sifat objek. "Ketika Anda menggeser jari Anda di segelas anggur, suara yang Anda buat sesuai dengan jumlah cairan yang dituangkan ke gelas," jelas mahasiswa pascasarjana Andrew Owens , penulis utama makalah ilmiah yang diterbitkan, yang belum siap untuk jurnal ilmiah, tetapi hanya diterbitkantersedia untuk umum di arXiv.org. Presentasi karya ilmiah akan berlangsung di konferensi tahunan tentang visi mesin dan pengenalan pola (CVPR) di Las Vegas bulan ini.Para ilmuwan telah memilih 977 video di mana orang melakukan tindakan dengan benda-benda di sekitarnya, yang terdiri dari berbagai bahan: gores, pukul dengan tongkat, dll. Secara total, video berisi 46.577 tindakan. Siswa CSAIL secara manual menandai semua tindakan, yang menunjukkan jenis bahan, tempat kontak, jenis tindakan (guncangan / goresan / lainnya) dan jenis reaksi dari bahan atau objek (deformasi, bentuk statis, gerakan keras, dll.). Video dengan suara digunakan untuk melatih jaringan saraf, dan tag yang ditempatkan secara manual hanya digunakan untuk menganalisis hasil pelatihan jaringan saraf, tetapi tidak untuk melatih. Jaringan saraf menganalisis karakteristik suara yang sesuai dengan setiap jenis interaksi dengan objek - volume, nada dan karakteristik lainnya. Selama pelatihan, sistem mempelajari video bingkai demi bingkai, menganalisis suara dalam bingkai ini dan menemukan kecocokan dengan suara yang paling mirip dalam database yang sudah terakumulasi. Yang paling penting adalah mengajarkan jaringan saraf untuk meregangkan suara menjadi bingkai.
Jaringan saraf menganalisis karakteristik suara yang sesuai dengan setiap jenis interaksi dengan objek - volume, nada dan karakteristik lainnya. Selama pelatihan, sistem mempelajari video bingkai demi bingkai, menganalisis suara dalam bingkai ini dan menemukan kecocokan dengan suara yang paling mirip dalam database yang sudah terakumulasi. Yang paling penting adalah mengajarkan jaringan saraf untuk meregangkan suara menjadi bingkai.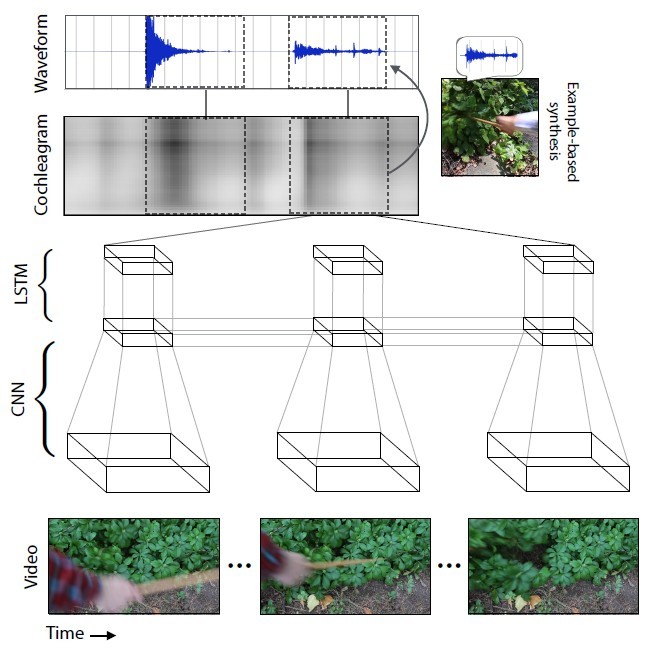 Dengan setiap video baru, keakuratan prediksi suara meningkat.Suara yang dihasilkan oleh jaringan saraf untuk adegan yang berbeda, dibandingkan dengan yang asli.
Dengan setiap video baru, keakuratan prediksi suara meningkat.Suara yang dihasilkan oleh jaringan saraf untuk adegan yang berbeda, dibandingkan dengan yang asli. Akibatnya, jaringan saraf belajar untuk secara akurat memprediksi suara yang paling beragam dengan semua nuansa: dari mengetuk batu ke ivy gemerisik."Pendekatan saat ini dari para peneliti di bidang kecerdasan buatan hanya berfokus pada satu dari lima indera: spesialis visi mesin mempelajari gambar visual, spesialis pengenalan suara mempelajari suara, dan sebagainya," kata Abhinav Gupta, associate professor robotika di Carnegie University - Mellon. "Studi ini adalah langkah ke arah yang benar yang meniru proses pembelajaran dengan cara yang sama yang dilakukan orang, yaitu mengintegrasikan suara dan visi."Untuk menguji keefektifan AI, para ilmuwan melakukan studi online di Amazon Mechanical Turk, para partisipan diminta untuk membandingkan dua opsi untuk suara video tertentu dan menentukan suara mana yang nyata dan mana yang tidak.Sebagai hasil dari percobaan, AI berhasil menipu orang di 40% kasus . Namun, menurut beberapa komentator di forum , tidak begitu sulit untuk menipu seseorang, karena sebagian besar pengetahuan tentang gambaran suara dunia diperoleh oleh orang-orang modern dari film layar lebar dan permainan komputer. Rentang suara untuk film dan game terdiri dari spesialis yang menggunakan koleksi sampel standar. Artinya, kita terus-menerus mendengar tentang hal yang sama.Dalam percobaan online, dalam dua dari lima kasus, orang berpikir bahwa suara yang dihasilkan oleh program lebih realistis daripada suara nyata dari video. Ini adalah hasil yang lebih baik daripada metode lain untuk mensintesis suara yang realistis.
Akibatnya, jaringan saraf belajar untuk secara akurat memprediksi suara yang paling beragam dengan semua nuansa: dari mengetuk batu ke ivy gemerisik."Pendekatan saat ini dari para peneliti di bidang kecerdasan buatan hanya berfokus pada satu dari lima indera: spesialis visi mesin mempelajari gambar visual, spesialis pengenalan suara mempelajari suara, dan sebagainya," kata Abhinav Gupta, associate professor robotika di Carnegie University - Mellon. "Studi ini adalah langkah ke arah yang benar yang meniru proses pembelajaran dengan cara yang sama yang dilakukan orang, yaitu mengintegrasikan suara dan visi."Untuk menguji keefektifan AI, para ilmuwan melakukan studi online di Amazon Mechanical Turk, para partisipan diminta untuk membandingkan dua opsi untuk suara video tertentu dan menentukan suara mana yang nyata dan mana yang tidak.Sebagai hasil dari percobaan, AI berhasil menipu orang di 40% kasus . Namun, menurut beberapa komentator di forum , tidak begitu sulit untuk menipu seseorang, karena sebagian besar pengetahuan tentang gambaran suara dunia diperoleh oleh orang-orang modern dari film layar lebar dan permainan komputer. Rentang suara untuk film dan game terdiri dari spesialis yang menggunakan koleksi sampel standar. Artinya, kita terus-menerus mendengar tentang hal yang sama.Dalam percobaan online, dalam dua dari lima kasus, orang berpikir bahwa suara yang dihasilkan oleh program lebih realistis daripada suara nyata dari video. Ini adalah hasil yang lebih baik daripada metode lain untuk mensintesis suara yang realistis. Paling sering, AI menipu peserta dalam percobaan dengan suara bahan seperti daun dan kotoran, karena suara ini lebih kompleks dan tidak "bersih" seperti yang dibuat, misalnya, dengan kayu atau logam.Kembali ke pelatihan jaringan saraf, sebagai produk sampingan dari penelitian, ditemukan bahwa algoritma dapat membedakan antara bahan lunak dan keras dengan akurasi 67%, hanya dengan memprediksi suara mereka. Dengan kata lain, robot dapat melihat jalan aspal dan rumput di depannya - dan menyimpulkan bahwa aspal itu keras dan rumputnya lunak. Robot akan mengetahui hal ini dengan suara yang diprediksi, bahkan tanpa menginjak aspal dan rumput. Kemudian dia bisa melangkah ke mana pun dia mau - dan menguji perasaannya dengan memeriksa dengan database dan, jika perlu, membuat koreksi di perpustakaan sampel suara. Dengan cara ini, di masa depan, robot akan mempelajari dan menguasai dunia di sekitar mereka.Namun, para peneliti masih memiliki banyak pekerjaan yang harus dilakukan untuk meningkatkan teknologi. Jaringan saraf sekarang sering disalahartikan sebagai pergerakan objek yang cepat, tanpa jatuh ke momen kontak yang tepat. Selain itu, AI hanya dapat menghasilkan suara berdasarkan kontak langsung yang direkam pada video, dan ada begitu banyak suara di sekitar kita yang tidak didasarkan pada kontak visual: kebisingan pohon, dengungan kipas di komputer. “Apa yang akan sangat keren adalah dengan mensimulasikan suara yang tidak terlalu terkait dengan rekaman,” kata Andrew Owens.
Paling sering, AI menipu peserta dalam percobaan dengan suara bahan seperti daun dan kotoran, karena suara ini lebih kompleks dan tidak "bersih" seperti yang dibuat, misalnya, dengan kayu atau logam.Kembali ke pelatihan jaringan saraf, sebagai produk sampingan dari penelitian, ditemukan bahwa algoritma dapat membedakan antara bahan lunak dan keras dengan akurasi 67%, hanya dengan memprediksi suara mereka. Dengan kata lain, robot dapat melihat jalan aspal dan rumput di depannya - dan menyimpulkan bahwa aspal itu keras dan rumputnya lunak. Robot akan mengetahui hal ini dengan suara yang diprediksi, bahkan tanpa menginjak aspal dan rumput. Kemudian dia bisa melangkah ke mana pun dia mau - dan menguji perasaannya dengan memeriksa dengan database dan, jika perlu, membuat koreksi di perpustakaan sampel suara. Dengan cara ini, di masa depan, robot akan mempelajari dan menguasai dunia di sekitar mereka.Namun, para peneliti masih memiliki banyak pekerjaan yang harus dilakukan untuk meningkatkan teknologi. Jaringan saraf sekarang sering disalahartikan sebagai pergerakan objek yang cepat, tanpa jatuh ke momen kontak yang tepat. Selain itu, AI hanya dapat menghasilkan suara berdasarkan kontak langsung yang direkam pada video, dan ada begitu banyak suara di sekitar kita yang tidak didasarkan pada kontak visual: kebisingan pohon, dengungan kipas di komputer. “Apa yang akan sangat keren adalah dengan mensimulasikan suara yang tidak terlalu terkait dengan rekaman,” kata Andrew Owens.Source: https://habr.com/ru/post/id395243/
All Articles