Apa itu privasi diferensial
Teknik canggih tanggapan acak pertama kali digunakan oleh Google untuk mengumpulkan statistik Chrome. Apakah Apple akan mengikutinya?
Tentang penulis. Matthew Green: cryptographer, profesor di Johns Hopkins University, penulis blog sistem cryptographicDiterbitkan 14 Juni 2016 Kemarin, pada presentasi WWDC, Apple memperkenalkan sejumlah fitur baru untuk keamanan dan perlindungan data rahasia, termasuk yang menarik perhatian khusus ... dan kebingungan. Yakni, Apple mengumumkan penggunaan teknik baru yang disebut "Privasi Diferensial," disingkat DP, untuk meningkatkan perlindungan privasi saat mengumpulkan data rahasia pengguna.Bagi kebanyakan orang, ini menimbulkan pertanyaan bodoh: "apa ... ???", karena hanya sedikit yang pernah mendengar tentang privasi diferensial, dan bahkan lebih mengerti apa artinya. Sayangnya, Apple tidak jernih dalam hal bahan rahasia yang dijalankan platform mereka, jadi kami hanya bisa berharap bahwa di masa depan akan memutuskan untuk menerbitkan lebih banyak informasi. Segala sesuatu yang kita ketahui saat ini terkandung dalam manual untuk Apple iOS 10 Preview.“Dimulai dengan iOS 10, Apple menggunakan teknologi privasi diferensial untuk membantu mengidentifikasi pola perilaku pengguna untuk sejumlah besar pengguna tanpa membahayakan privasi setiap pengguna. Untuk menyembunyikan identitas seseorang, privasi diferensial menambahkan kebisingan matematika ke sampel kecil templat perilaku pengguna individu untuk pengguna tertentu. Karena semakin banyak orang menunjukkan pola yang sama, pola umum mulai muncul yang dapat menginformasikan kami dan meningkatkan pengalaman pengguna secara keseluruhan. Di iOS 10, teknologi ini akan membantu meningkatkan QuickType dan tip emoji, tips Spotlight, dan Petunjuk Pencarian dalam Catatan. "Singkatnya, sepertinya Apple ingin mengumpulkan lebih banyak data dari ponsel Anda.Pada dasarnya, mereka melakukan ini untuk meningkatkan layanan mereka, dan tidak mengumpulkan informasi tentang kebiasaan dan karakteristik masing-masing pengguna. Untuk menjamin hal ini, Apple bermaksud menggunakan teknik statistik canggih untuk memastikan bahwa basis agregat - hasil menghitung fungsi statistik setelah memproses semua informasi Anda - tidak memberikan peserta secara individu. Pada prinsipnya, kedengarannya cukup bagus. Tapi tentu saja, iblis selalu bersembunyi di detailnya.Meskipun kami tidak memiliki detail ini, tampaknya sekarang adalah waktu untuk setidaknya berbicara tentang apa itu privasi diferensial, bagaimana itu dapat diimplementasikan dan apa artinya bagi Apple - dan untuk iPhone Anda.
Kemarin, pada presentasi WWDC, Apple memperkenalkan sejumlah fitur baru untuk keamanan dan perlindungan data rahasia, termasuk yang menarik perhatian khusus ... dan kebingungan. Yakni, Apple mengumumkan penggunaan teknik baru yang disebut "Privasi Diferensial," disingkat DP, untuk meningkatkan perlindungan privasi saat mengumpulkan data rahasia pengguna.Bagi kebanyakan orang, ini menimbulkan pertanyaan bodoh: "apa ... ???", karena hanya sedikit yang pernah mendengar tentang privasi diferensial, dan bahkan lebih mengerti apa artinya. Sayangnya, Apple tidak jernih dalam hal bahan rahasia yang dijalankan platform mereka, jadi kami hanya bisa berharap bahwa di masa depan akan memutuskan untuk menerbitkan lebih banyak informasi. Segala sesuatu yang kita ketahui saat ini terkandung dalam manual untuk Apple iOS 10 Preview.“Dimulai dengan iOS 10, Apple menggunakan teknologi privasi diferensial untuk membantu mengidentifikasi pola perilaku pengguna untuk sejumlah besar pengguna tanpa membahayakan privasi setiap pengguna. Untuk menyembunyikan identitas seseorang, privasi diferensial menambahkan kebisingan matematika ke sampel kecil templat perilaku pengguna individu untuk pengguna tertentu. Karena semakin banyak orang menunjukkan pola yang sama, pola umum mulai muncul yang dapat menginformasikan kami dan meningkatkan pengalaman pengguna secara keseluruhan. Di iOS 10, teknologi ini akan membantu meningkatkan QuickType dan tip emoji, tips Spotlight, dan Petunjuk Pencarian dalam Catatan. "Singkatnya, sepertinya Apple ingin mengumpulkan lebih banyak data dari ponsel Anda.Pada dasarnya, mereka melakukan ini untuk meningkatkan layanan mereka, dan tidak mengumpulkan informasi tentang kebiasaan dan karakteristik masing-masing pengguna. Untuk menjamin hal ini, Apple bermaksud menggunakan teknik statistik canggih untuk memastikan bahwa basis agregat - hasil menghitung fungsi statistik setelah memproses semua informasi Anda - tidak memberikan peserta secara individu. Pada prinsipnya, kedengarannya cukup bagus. Tapi tentu saja, iblis selalu bersembunyi di detailnya.Meskipun kami tidak memiliki detail ini, tampaknya sekarang adalah waktu untuk setidaknya berbicara tentang apa itu privasi diferensial, bagaimana itu dapat diimplementasikan dan apa artinya bagi Apple - dan untuk iPhone Anda.Motivasi
Dalam beberapa tahun terakhir, "pengguna biasa" telah terbiasa dengan gagasan bahwa sejumlah besar informasi pribadi dikirim dari perangkatnya ke berbagai layanan yang ia gunakan. Jajak pendapat juga menunjukkan bahwa warga mulai merasa tidak nyaman karena alasan ini .Ketidaknyamanan ini masuk akal jika Anda memikirkan perusahaan-perusahaan yang menggunakan informasi pribadi kami untuk mendapatkan uang dari kami. Namun, terkadang ada alasan bagus untuk mengumpulkan informasi tentang tindakan pengguna. Misalnya, Microsoft baru-baru ini memperkenalkan alat yang dapat mendiagnosis kanker pankreas dengan menganalisis permintaan pencarian Anda di Bing. Google mendukung layanan Google Flu Trends yang terkenaluntuk memprediksi penyebaran penyakit menular dengan frekuensi permintaan pencarian di berbagai wilayah. Dan tentu saja, kita semua mendapat manfaat dari data crowdsourcing yang meningkatkan kualitas layanan yang kami gunakan, dari aplikasi peta hingga ulasan di restoran. Sayangnya, bahkan mengumpulkan data untuk tujuan yang baik bisa berbahaya. Misalnya, pada akhir 2000-an, Netflix mengumumkan kompetisi untuk mengembangkan algoritma rekomendasi film fitur terbaik . Untuk membantu peserta dalam kontes, mereka menerbitkan set data "anonim" dengan statistik pada pandangan oleh pengguna film, menghapus semua informasi pribadi dari sana. Sayangnya, "de-identifikasi" seperti itu tidak cukup. Dalam karya ilmiah terkenal Narayan dan Shmatikovmenunjukkan bahwa kumpulan data tersebut dapat digunakan untuk mendanonimisasi pengguna tertentu - dan bahkan untuk memprediksi pandangan politik mereka! - hanya jika Anda tahu sedikit informasi tambahan tentang pengguna ini.Hal-hal seperti itu seharusnya mengganggu kita. Bukan hanya karena perusahaan komersial biasa bertukar informasi yang dikumpulkan tentang pengguna (meskipun mereka lakukan), tetapi karena peretasan terjadi, dan karena bahkan statistik tentang database yang dikumpulkan dapat dengan entah bagaimana memperjelas rincian catatan individu tertentu yang digunakan untuk mengkompilasi sampel agregat. Privasi diferensial adalah seperangkat alat yang dirancang untuk mengatasi masalah ini.Apa itu privasi diferensial?
Privasi diferensial adalah definisi perlindungan data pengguna yang semula diusulkan oleh Cynthia Dwork pada 2006. Secara kasar, dapat dijelaskan secara singkat sebagai berikut:Bayangkan bahwa Anda memiliki dua database identik dalam semua hal lain, satu dengan informasi Anda di dalam dan yang lainnya tanpa itu. Privasi diferensial memastikan bahwa kueri statistik ke satu dan basis data kedua akan menghasilkan hasil spesifik dengan (hampir) probabilitas yang sama.Ini dapat direpresentasikan sebagai berikut: DP memungkinkan untuk memahami apakah data Anda memiliki pengaruh signifikan secara statistik pada hasil kueri. Jika tidak, maka mereka dapat dengan aman ditambahkan ke database, karena hampir tidak ada salahnya dari ini. Pertimbangkan contoh bodoh ini:Bayangkan bahwa Anda telah mengaktifkan pada iPhone Anda opsi untuk memberi tahu Apple bahwa Anda sering menggunakan emoji  di sesi obrolan iMessage Anda. Laporan ini terdiri dari satu bit informasi: 1 berarti Anda suka , dan 0 berarti Anda tidak. Apple dapat menerima laporan ini dan memasukkannya ke dalam basis data raksasa. Akibatnya, perusahaan ingin dapat mengetahui jumlah pengguna yang menyukai emoji tertentu.Tak perlu dikatakan bahwa proses sederhana untuk merangkum hasil dan menerbitkannya tidak memenuhi definisi DP, karena operasi aritmatika menjumlahkan nilai dalam database yang berisi informasi Anda berpotensi menghasilkan hasil yang berbeda daripada menjumlahkan nilai dari database di mana informasi Anda hilang. Karena itu, walaupun jumlah tersebut akan memberikan sedikit informasi tentang Anda, tetapi masih ada sedikit informasi pribadi yang bocor. Kesimpulan utama dari studi privasi diferensial adalah bahwa dalam banyak kasus prinsip DP dapat dicapai dengan menambahkan noise acakuntuk hasilnya. Misalnya, alih-alih hanya melaporkan hasil akhir, pelapor dapat mengimplementasikan distribusi Gaussian atau Laplace, sehingga hasilnya tidak akan seakurat - tetapi akan menutupi setiap nilai tertentu dalam database. (Untuk fitur keren lainnya ada banyak lainnya teknik ).Yang lebih bernilai lagi, perhitungan jumlah noise yang ditambahkan dapat dilakukan tanpa mengetahui isi dari database itu sendiri (atau bahkan ukurannya) . Artinya, perhitungan dengan noise dapat dilakukan atas dasar hanya pengetahuan tentang fungsi itu sendiri, yang dilakukan, dan tingkat kebocoran data yang dapat diterima.
di sesi obrolan iMessage Anda. Laporan ini terdiri dari satu bit informasi: 1 berarti Anda suka , dan 0 berarti Anda tidak. Apple dapat menerima laporan ini dan memasukkannya ke dalam basis data raksasa. Akibatnya, perusahaan ingin dapat mengetahui jumlah pengguna yang menyukai emoji tertentu.Tak perlu dikatakan bahwa proses sederhana untuk merangkum hasil dan menerbitkannya tidak memenuhi definisi DP, karena operasi aritmatika menjumlahkan nilai dalam database yang berisi informasi Anda berpotensi menghasilkan hasil yang berbeda daripada menjumlahkan nilai dari database di mana informasi Anda hilang. Karena itu, walaupun jumlah tersebut akan memberikan sedikit informasi tentang Anda, tetapi masih ada sedikit informasi pribadi yang bocor. Kesimpulan utama dari studi privasi diferensial adalah bahwa dalam banyak kasus prinsip DP dapat dicapai dengan menambahkan noise acakuntuk hasilnya. Misalnya, alih-alih hanya melaporkan hasil akhir, pelapor dapat mengimplementasikan distribusi Gaussian atau Laplace, sehingga hasilnya tidak akan seakurat - tetapi akan menutupi setiap nilai tertentu dalam database. (Untuk fitur keren lainnya ada banyak lainnya teknik ).Yang lebih bernilai lagi, perhitungan jumlah noise yang ditambahkan dapat dilakukan tanpa mengetahui isi dari database itu sendiri (atau bahkan ukurannya) . Artinya, perhitungan dengan noise dapat dilakukan atas dasar hanya pengetahuan tentang fungsi itu sendiri, yang dilakukan, dan tingkat kebocoran data yang dapat diterima.Pertukaran antara privasi dan akurasi
Sekarang sudah jelas bahwa menghitung jumlah penggemar di antara pengguna adalah contoh yang sangat buruk. Dalam kasus DP, penting bahwa pendekatan umum yang sama dapat diterapkan pada fungsi yang jauh lebih menarik, termasuk perhitungan statistik yang kompleks, seperti yang digunakan dalam sistem pembelajaran mesin. Itu dapat diterapkan bahkan jika banyak fungsi berbeda dihitung pada database yang sama.Tapi ada satu tangkapan. Faktanya adalah bahwa ukuran "kebocoran informasi" dari satu permintaan dapat diminimalkan dalam batas-batas kecil, tetapi itu tidak akan menjadi nol. Setiap kali Anda mengirim kueri ke database dengan beberapa fungsi, "kebocoran" total meningkat - dan tidak pernah dapat dikurangi. Seiring waktu, dengan meningkatnya jumlah permintaan, kebocoran mungkin mulai tumbuh.Ini adalah salah satu aspek DP yang paling sulit. Itu memanifestasikan dirinya dalam dua cara utama:- Semakin Anda berniat untuk "meminta" database, semakin banyak suara yang harus Anda tambahkan untuk meminimalkan kebocoran informasi . Ini berarti bahwa DP, pada kenyataannya, adalah kompromi mendasar antara akurasi dan perlindungan data pribadi, yang dapat menyebabkan masalah besar ketika melatih model pembelajaran mesin yang kompleks.
- , . , , , — , . . .
Jumlah total kebocoran yang diperbolehkan sering disebut sebagai "anggaran privasi," dan menentukan berapa banyak permintaan yang diizinkan untuk dibuat (dan seberapa akurat hasilnya akan). Pelajaran utama dari DP adalah bahwa iblis bersembunyi dalam anggaran. Atur terlalu tinggi dan data penting akan bocor. Setel terlalu rendah, dan hasil kueri bisa tidak berguna.Sekarang di beberapa aplikasi, seperti kebanyakan aplikasi di iPhone kami, akurasi yang tidak memadai tidak akan menjadi masalah tertentu. Kita terbiasa dengan fakta bahwa smartphone kita membuat kesalahan. Tetapi pada saat-saat ketika DP digunakan dalam aplikasi yang kompleks, seperti model pembelajaran mesin pelatihan, ini sangat penting.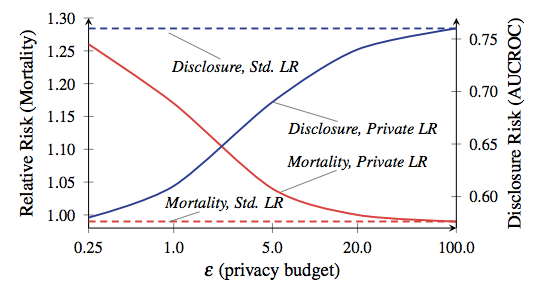 Rasio kematian dan pengungkapan, dari karya Frederickson et al. Dari 2014. Garis merah sesuai dengan mortalitas pasien.Untuk memberi Anda contoh yang benar-benar gila tentang betapa pentingnya kompromi antara privasi dan akurasi, lihat makalah ilmiah 2014 oleh Frederickson et al . Para penulis mulai dengan mengkorelasikan data dosis obatdaridatabase terbuka Warfarin dengan penanda genetik spesifik. Kemudian mereka menerapkan teknik pembelajaran mesin untuk mengembangkan model untuk menghitung dosis dari basis data - tetapi mereka menggunakan DP dengan berbagai opsi anggaran privasi selama pelatihan model. Kemudian mereka mengevaluasi tingkat kebocoran informasi dan keberhasilan menggunakan model untuk perawatan "pasien" virtual.Hasil penelitian menunjukkan bahwa akurasi model sangat tergantung pada anggaran privasi yang ditetapkan selama pelatihan. Jika anggaran ditetapkan terlalu tinggi, maka sejumlah besar informasi rahasia pasien bocor dari database - tetapi model yang dihasilkan membuat keputusan dosis yang aman seperti praktik klinis standar. Di sisi lain, ketika anggaran dikurangi ke tingkat yang berarti privasi yang dapat diterima, model yang dilatih tentang data bising cenderung membunuh "pasien" -nya.Sebelum Anda mulai panik, izinkan saya menjelaskan: iPhone Anda tidak akan membunuh Anda. Tidak ada yang mengatakan bahwa contoh ini bahkan mirip dengan apa yang akan dilakukan Apple pada smartphone. Kesimpulan dari penelitian ini hanya terletak pada kenyataan bahwa ada kompromi yang menarik antara efisiensi dan perlindungan privasi di setiap sistem berbasis DP - kompromi ini sangat tergantung pada keputusan khusus yang dibuat oleh pengembang sistem, parameter operasi yang dipilih, dll. Mari kita berharap bahwa Apple akan segera memberi tahu kami apa opsi ini.
Rasio kematian dan pengungkapan, dari karya Frederickson et al. Dari 2014. Garis merah sesuai dengan mortalitas pasien.Untuk memberi Anda contoh yang benar-benar gila tentang betapa pentingnya kompromi antara privasi dan akurasi, lihat makalah ilmiah 2014 oleh Frederickson et al . Para penulis mulai dengan mengkorelasikan data dosis obatdaridatabase terbuka Warfarin dengan penanda genetik spesifik. Kemudian mereka menerapkan teknik pembelajaran mesin untuk mengembangkan model untuk menghitung dosis dari basis data - tetapi mereka menggunakan DP dengan berbagai opsi anggaran privasi selama pelatihan model. Kemudian mereka mengevaluasi tingkat kebocoran informasi dan keberhasilan menggunakan model untuk perawatan "pasien" virtual.Hasil penelitian menunjukkan bahwa akurasi model sangat tergantung pada anggaran privasi yang ditetapkan selama pelatihan. Jika anggaran ditetapkan terlalu tinggi, maka sejumlah besar informasi rahasia pasien bocor dari database - tetapi model yang dihasilkan membuat keputusan dosis yang aman seperti praktik klinis standar. Di sisi lain, ketika anggaran dikurangi ke tingkat yang berarti privasi yang dapat diterima, model yang dilatih tentang data bising cenderung membunuh "pasien" -nya.Sebelum Anda mulai panik, izinkan saya menjelaskan: iPhone Anda tidak akan membunuh Anda. Tidak ada yang mengatakan bahwa contoh ini bahkan mirip dengan apa yang akan dilakukan Apple pada smartphone. Kesimpulan dari penelitian ini hanya terletak pada kenyataan bahwa ada kompromi yang menarik antara efisiensi dan perlindungan privasi di setiap sistem berbasis DP - kompromi ini sangat tergantung pada keputusan khusus yang dibuat oleh pengembang sistem, parameter operasi yang dipilih, dll. Mari kita berharap bahwa Apple akan segera memberi tahu kami apa opsi ini.Bagaimana pun, bagaimana cara mengumpulkan data?
Anda telah memperhatikan bahwa dalam semua contoh di atas, saya berasumsi bahwa kueri dilakukan oleh operator database tepercaya yang memiliki akses ke semua data dasar "mentah" asli. Saya memilih model ini karena ini adalah versi tradisional dari model yang digunakan di hampir semua literatur, dan bukan karena itu adalah ide yang bagus.Bahkan, akan ada alasan untuk khawatir jika Apple benar-benar mengimplementasikannyasistem Anda dengan cara yang serupa. Ini akan mengharuskan Apple untuk mengumpulkan semua informasi awal tentang tindakan pengguna dalam database terpusat besar-besaran, dan kemudian ("percayai kami!") Hitung statistik di atasnya dengan cara yang aman sambil melindungi privasi pengguna. Minimal, metode ini membuat informasi tersedia untuk memperoleh panggilan pengadilan, serta bagi peretas asing, manajer puncak Apple yang penasaran, dan sebagainya.Untungnya, ini bukan satu-satunya cara untuk menerapkan sistem privasi diferensial. Secara teoritis, statistik dapat dihitung dengan menggunakan teknik kriptografi mewah (seperti protokol komputasi rahasia atau enkripsi homomorfik sepenuhnya)) Sayangnya, teknik ini mungkin terlalu tidak efisien untuk digunakan pada skala yang dibutuhkan Apple.Pendekatan yang jauh lebih menjanjikan tampaknya tidak mengumpulkan data mentah sama sekali . Pendekatan ini adalah yang pertama di antara semua yang menggunakan Google untuk mengumpulkan statistik di browser Chrome . Sistem mereka, yang disebut RAPPOR, didasarkan pada teknik respons acak berusia 50 tahun . Respons acak berfungsi sebagai berikut:- ( : « Bing?»), , «», — . .
- ( , «»), «» .
Pada tingkat intuitif, respons acak melindungi privasi laporan pengguna individu, karena jawaban "ya" dapat berarti "Ya, saya menggunakan Bing", atau hanya menjadi hasil dari penurunan koin acak. Di tingkat formal, respons acak memang memberikan privasi berbeda , dengan jaminan khusus yang dapat disesuaikan dengan menyesuaikan karakteristik koin.RAPPOR menggunakan teknik yang relatif lama ini dan mengubahnya menjadi sesuatu yang jauh lebih kuat. Alih-alih hanya menjawab satu pertanyaan, sistem dapat menyusun laporan tentang vektor pertanyaan yang kompleks dan bahkan mengembalikan jawaban yang kompleks, seperti string - misalnya, apa beranda Anda di browser Anda. Yang terakhir ini dicapai sehingga string pertama kali dilewatiBloom filter - urutan bit yang dihasilkan menggunakan fungsi hash dengan cara yang sangat spesifik. Bit yang diterima kemudian dicampur dengan noise dan dijumlahkan, dan respon dikembalikan menggunakan proses decoding (agak rumit). Meskipun tidak ada bukti jelas bahwa Apple menggunakan sistem seperti RAPPOR, beberapa tips kecil menunjukkan hal ini. Sebagai contoh, Craig Federighi (dalam kehidupan dia persis seperti di foto) menggambarkan privasi yang dibedakan sebagai "menggunakan hashing, subsampling dan noise untuk mengaktifkan ... pelatihan crowdsourcing sambil menjaga data pengguna individu sepenuhnya pribadi". Ini adalah bukti yang agak lemah dari apa pun, mungkin, tetapi keberadaan "hashing" dalam kutipan ini setidaknya menunjukkan penggunaan filter dalam gaya RAPPOR.Kesulitan utama dengan sistem respons acak adalah mereka dapat memberikan data sensitif jika pengguna menjawab pertanyaan yang sama beberapa kali. RAPPOR mencoba menyelesaikan masalah ini dengan beberapa cara. Salah satunya adalah untuk menentukan bagian statis dari informasi dan dengan demikian menghitung "respon permanen" alih-alih mengacaknya kembali setiap kali. Tetapi dimungkinkan untuk membayangkan situasi di mana perlindungan seperti itu tidak berhasil. Sekali lagi, iblis sering menyembunyikan detailnya - Anda hanya perlu melihatnya. Saya yakin banyak makalah ilmiah yang menarik akan diterbitkan pula.
Meskipun tidak ada bukti jelas bahwa Apple menggunakan sistem seperti RAPPOR, beberapa tips kecil menunjukkan hal ini. Sebagai contoh, Craig Federighi (dalam kehidupan dia persis seperti di foto) menggambarkan privasi yang dibedakan sebagai "menggunakan hashing, subsampling dan noise untuk mengaktifkan ... pelatihan crowdsourcing sambil menjaga data pengguna individu sepenuhnya pribadi". Ini adalah bukti yang agak lemah dari apa pun, mungkin, tetapi keberadaan "hashing" dalam kutipan ini setidaknya menunjukkan penggunaan filter dalam gaya RAPPOR.Kesulitan utama dengan sistem respons acak adalah mereka dapat memberikan data sensitif jika pengguna menjawab pertanyaan yang sama beberapa kali. RAPPOR mencoba menyelesaikan masalah ini dengan beberapa cara. Salah satunya adalah untuk menentukan bagian statis dari informasi dan dengan demikian menghitung "respon permanen" alih-alih mengacaknya kembali setiap kali. Tetapi dimungkinkan untuk membayangkan situasi di mana perlindungan seperti itu tidak berhasil. Sekali lagi, iblis sering menyembunyikan detailnya - Anda hanya perlu melihatnya. Saya yakin banyak makalah ilmiah yang menarik akan diterbitkan pula.Jadi, apakah penggunaan DP oleh Apple baik atau buruk?
Sebagai seorang ilmuwan dan spesialis keamanan informasi, saya memiliki perasaan campur aduk tentang ini. Di satu sisi, sebagai seorang ilmuwan, saya memahami betapa menariknya mengamati implementasi perkembangan ilmiah maju dalam produk nyata. Dan Apple menyediakan platform yang sangat besar untuk eksperimen semacam itu.Di sisi lain, sebagai spesialis keamanan praktis, adalah tugas saya untuk tetap skeptis - perusahaan harus, pada pertanyaan sekecil apa pun, menampilkan kode yang penting untuk keamanan (seperti yang Google lakukan dengan RAPPOR ), atau setidaknya menyatakan secara eksplisit apa yang diterapkannya. Jika Apple berencana untuk mengumpulkan sejumlah besar data baru dari perangkat yang kita sangat tergantung, kita harus benar-benaryakin bahwa mereka melakukan segalanya dengan benar - dan tidak bertepuk tangan keras untuk penerapan ide-ide keren tersebut. (Saya sudah melakukan kesalahan seperti itu sekali, dan masih merasa bodoh karena ini).Tapi mungkin semua ini terlalu detail. Pada akhirnya, sepertinya Apple jujur mencoba melakukan sesuatu untuk melindungi informasi rahasia pengguna , dan dengan mempertimbangkan alternatif akun, ini bisa menjadi hal yang paling penting.Source: https://habr.com/ru/post/id395313/
All Articles