Hilangnya hari kesebelas bulan itu dan tanggal lainnya
 Pada bulan November 2012, Randal Monroe menerbitkan komik xkcd dengan kalender di mana ukuran angka setiap bulan sebanding dengan seberapa sering angka ini disebutkan dalam buku dengan namanya sendiri (misalnya, "14 Oktober") di database Google Ngrams sejak 2000. Sebagian besar tanggal utama adalah agak jelas: Juli 4 , Desember 25 , hari pertama setiap bulan, hari terakhir hampir setiap bulan, dan 11 September , meninggalkan semua orang di belakang. Tidak begitu banyak hari terlihat jauh lebih kecil daripada yang lain. Misalnya, 29 Februari- titik kecil. Tetapi jika Anda melihat lebih dekat, Anda dapat melihat bahwa hari ke 11 setiap bulannya relatif kecil. Sebuah catatan pergi ke komik: "Dalam semua bulan kecuali September, tanggal 11 disebutkan jauh lebih jarang daripada sisa tanggal. Itu sampai 11 September [2001], dan saya tidak tahu mengapa demikian. " Saya mencari-cari dalam data, dan saya pikir saya tahu mengapa.Pada awalnya saya memastikan bahwa tanggal 11 berbeda dari yang lain. Sebulan bisa sampai 31 hari, dan beberapa dari hari-hari ini pasti akan menjadi yang terkecil dari semuanya. Mungkin angka ke-11 di kalender itu bukan yang terkecil, hanya mata kita yang melekat padanya. Jadi saya membandingkan data nyata, dan tidak hanya mempelajari komik. Basis data Ngrams mengembalikan jumlah total frasa yang disebutkan selama setahun, dinormalisasi dengan jumlah buku yang diterbitkan tahun itu.Saya memilih jumlah setiap hari dalam setahun (1 Januari, 2 Januari) dan merencanakan medianper bulan untuk setiap hari dalam sebulan (1 Januari, 1 Februari, dll.) untuk setiap tahun. Ini menunjukkan seberapa sering hari ke-11 dan 30 lainnya disebutkan pada tahun yang dipilih. Median memungkinkan Anda memuluskan semburan dari hari-hari seperti 4 Juli. Median akan terlihat tidak biasa hanya jika nomor seri sangat berbeda dalam setidaknya 6 dari 12 bulan.Saya membuat median untuk setiap nomor seri dari 2000 hingga 2008. Di bawah ini adalah histogram untuk 31 median. Angka pertama menonjol dari semua, dan 15 hampir tidak terlihat di antara yang tersisa. Tetapi hasil dari hari ke-11 adalah yang paling sedikit dengan jumlah yang agak besar (dengan nilai-P <0,05), yang pada pandangan pertama sulit untuk dijelaskan.
Pada bulan November 2012, Randal Monroe menerbitkan komik xkcd dengan kalender di mana ukuran angka setiap bulan sebanding dengan seberapa sering angka ini disebutkan dalam buku dengan namanya sendiri (misalnya, "14 Oktober") di database Google Ngrams sejak 2000. Sebagian besar tanggal utama adalah agak jelas: Juli 4 , Desember 25 , hari pertama setiap bulan, hari terakhir hampir setiap bulan, dan 11 September , meninggalkan semua orang di belakang. Tidak begitu banyak hari terlihat jauh lebih kecil daripada yang lain. Misalnya, 29 Februari- titik kecil. Tetapi jika Anda melihat lebih dekat, Anda dapat melihat bahwa hari ke 11 setiap bulannya relatif kecil. Sebuah catatan pergi ke komik: "Dalam semua bulan kecuali September, tanggal 11 disebutkan jauh lebih jarang daripada sisa tanggal. Itu sampai 11 September [2001], dan saya tidak tahu mengapa demikian. " Saya mencari-cari dalam data, dan saya pikir saya tahu mengapa.Pada awalnya saya memastikan bahwa tanggal 11 berbeda dari yang lain. Sebulan bisa sampai 31 hari, dan beberapa dari hari-hari ini pasti akan menjadi yang terkecil dari semuanya. Mungkin angka ke-11 di kalender itu bukan yang terkecil, hanya mata kita yang melekat padanya. Jadi saya membandingkan data nyata, dan tidak hanya mempelajari komik. Basis data Ngrams mengembalikan jumlah total frasa yang disebutkan selama setahun, dinormalisasi dengan jumlah buku yang diterbitkan tahun itu.Saya memilih jumlah setiap hari dalam setahun (1 Januari, 2 Januari) dan merencanakan medianper bulan untuk setiap hari dalam sebulan (1 Januari, 1 Februari, dll.) untuk setiap tahun. Ini menunjukkan seberapa sering hari ke-11 dan 30 lainnya disebutkan pada tahun yang dipilih. Median memungkinkan Anda memuluskan semburan dari hari-hari seperti 4 Juli. Median akan terlihat tidak biasa hanya jika nomor seri sangat berbeda dalam setidaknya 6 dari 12 bulan.Saya membuat median untuk setiap nomor seri dari 2000 hingga 2008. Di bawah ini adalah histogram untuk 31 median. Angka pertama menonjol dari semua, dan 15 hampir tidak terlihat di antara yang tersisa. Tetapi hasil dari hari ke-11 adalah yang paling sedikit dengan jumlah yang agak besar (dengan nilai-P <0,05), yang pada pandangan pertama sulit untuk dijelaskan. Dan kekurangan ini sudah ada sejak lama. Grafik berikut menunjukkan semua nomor seri untuk masing-masing tahun dari 1800-2008. Data dihaluskan selama 11 tahun untuk menghilangkan noise. Bahkan di awal, tanggal 11 jauh lebih rendah daripada kelompok utama. Kelemahannya sedikit bertahan selama beberapa dekade, dan kemudian pada tahun 1860an, yang ke-11 tiba-tiba menyimpang dari posisinya sebagai yang terakhir di seri tengah. Kesenjangan antara nomor seri 11 dan biasa meningkat tajam, dan sebagai hasilnya, nilai frekuensi referensi menjadi sekitar setengah lebih rendah, yang berlanjut pada paruh pertama abad ke-20. Di babak kedua, jarak berkurang, tetapi tidak hilang sampai akhir.
Dan kekurangan ini sudah ada sejak lama. Grafik berikut menunjukkan semua nomor seri untuk masing-masing tahun dari 1800-2008. Data dihaluskan selama 11 tahun untuk menghilangkan noise. Bahkan di awal, tanggal 11 jauh lebih rendah daripada kelompok utama. Kelemahannya sedikit bertahan selama beberapa dekade, dan kemudian pada tahun 1860an, yang ke-11 tiba-tiba menyimpang dari posisinya sebagai yang terakhir di seri tengah. Kesenjangan antara nomor seri 11 dan biasa meningkat tajam, dan sebagai hasilnya, nilai frekuensi referensi menjadi sekitar setengah lebih rendah, yang berlanjut pada paruh pertama abad ke-20. Di babak kedua, jarak berkurang, tetapi tidak hilang sampai akhir. Pembaca yang penuh perhatian akan melihat keanehan lain. Ada 4 baris lagi yang lebih rendah dari yang seharusnya. Dari atas ke bawah, ini adalah nomor 2, 3, 22 dan 23. Dari 1800 hingga 1890 mereka bahkan lebih rendah dari tanggal 11. Namun sejak 1900, kesenjangan mereka semakin menyempit, sementara kesenjangan sejak tanggal 11 mulai melebar, dan sepenuhnya menghilang pada 1930-an. Ini juga topik yang agak menarik, yang akan kita bahas nanti.
Pembaca yang penuh perhatian akan melihat keanehan lain. Ada 4 baris lagi yang lebih rendah dari yang seharusnya. Dari atas ke bawah, ini adalah nomor 2, 3, 22 dan 23. Dari 1800 hingga 1890 mereka bahkan lebih rendah dari tanggal 11. Namun sejak 1900, kesenjangan mereka semakin menyempit, sementara kesenjangan sejak tanggal 11 mulai melebar, dan sepenuhnya menghilang pada 1930-an. Ini juga topik yang agak menarik, yang akan kita bahas nanti.Keingintahuan Tipografi
Memulai penelitian, saya berharap menemukan tabu rahasia tentang peristiwa tanggal 11 atau penyimpangan tipografis dari aturan pers. Sayangnya, alasannya ternyata jauh lebih sederhana: angka 1 sangat mirip dengan huruf besar I (i) atau huruf kecil l (L) di sebagian besar font yang digunakan untuk mencetak buku. Dan juga 11 dapat dikacaukan dengan n. Algoritma dari Google salah, mengenali 11 pada halaman, dan menafsirkan nomor seri sebagai semacam kata.Kita dapat langsung mencari frasa yang tidak berarti seperti ll Maret atau Juli II atau Mei II. 11 dapat dikacaukan dengan sembilan kombinasi I, l dan i. Lima di antaranya memang ditemukan dalam database, setidaknya selama satu bulan: II-nd, Il-nd, ii-nd, li-nd, dan ll-nd. Juga, ada opsi dengan hanya satu karakter yang salah, 1lth, 1ith dan l1th. Saya menyebut kesalahan ini xxth. Buku Googlemembuat kueri ke database yang lebih baru dari Ngram, tetapi contoh kesalahan seperti itu masih dapat ditemukan. Sebagai contoh , Google mengakui hal-hal berikut sebagai Januari II: Seperti Februari ll :
Seperti Februari ll : Tetapi Maret li :
Tetapi Maret li :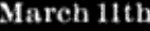 Ada banyak contoh seperti itu dalam database. Anda dapat menemukan nomor seri yang ditafsirkan secara keliru lainnya, tetapi yang ke-11 jauh lebih umum daripada yang lain.Saya menambahkan 2 Januari, 11 Januari, dll., Ke dalam perhitungan saya, dan melakukan hal yang sama untuk bulan-bulan lainnya. Grafik berikut menunjukkan bahwa tanggal 11 mendapat dorongan besar dari penambahan ini. Sampai tahun 1860-an, perbedaan antara kelompok ke-11 dan kelompok utama menghilang. Setelah 1860-an, sepertiga atau seperempat dari perbedaan ini menghilang.
Ada banyak contoh seperti itu dalam database. Anda dapat menemukan nomor seri yang ditafsirkan secara keliru lainnya, tetapi yang ke-11 jauh lebih umum daripada yang lain.Saya menambahkan 2 Januari, 11 Januari, dll., Ke dalam perhitungan saya, dan melakukan hal yang sama untuk bulan-bulan lainnya. Grafik berikut menunjukkan bahwa tanggal 11 mendapat dorongan besar dari penambahan ini. Sampai tahun 1860-an, perbedaan antara kelompok ke-11 dan kelompok utama menghilang. Setelah 1860-an, sepertiga atau seperempat dari perbedaan ini menghilang.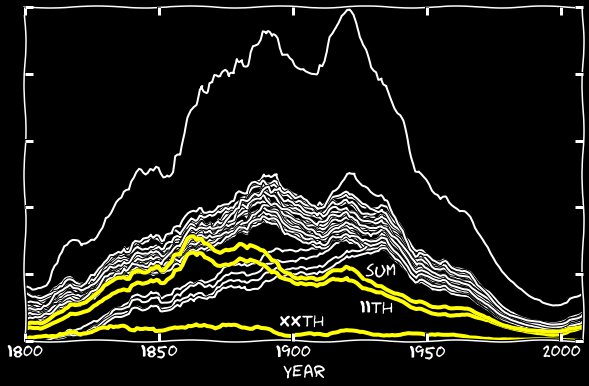 Dan kemana perginya sisa tanggal 11? Sejak tahun 1860-an, algoritme Google mulai membuat kesalahan aneh - alih-alih yang ke-11, algoritma ini mengakui kesalahan yang ke-n. Berikut adalah contoh halaman yang diisi dengan angka Januari:
Dan kemana perginya sisa tanggal 11? Sejak tahun 1860-an, algoritme Google mulai membuat kesalahan aneh - alih-alih yang ke-11, algoritma ini mengakui kesalahan yang ke-n. Berikut adalah contoh halaman yang diisi dengan angka Januari: Dalam beberapa tahun, jumlah pengakuan yang salah melebihi jumlah yang benar. Saya menambahkan hari ke-9 Januari hingga 11 Januari, dan melakukan hal yang sama dengan bulan-bulan lainnya. Grafik berikut menunjukkan angka ke-11 dan jumlah mereka dengan angka 11. Sampai tahun 1860-an, kontribusi mereka dapat diabaikan, tetapi kemudian kesalahan ini mulai bertanggung jawab atas hampir semua yang ke-11 yang hilang.
Dalam beberapa tahun, jumlah pengakuan yang salah melebihi jumlah yang benar. Saya menambahkan hari ke-9 Januari hingga 11 Januari, dan melakukan hal yang sama dengan bulan-bulan lainnya. Grafik berikut menunjukkan angka ke-11 dan jumlah mereka dengan angka 11. Sampai tahun 1860-an, kontribusi mereka dapat diabaikan, tetapi kemudian kesalahan ini mulai bertanggung jawab atas hampir semua yang ke-11 yang hilang.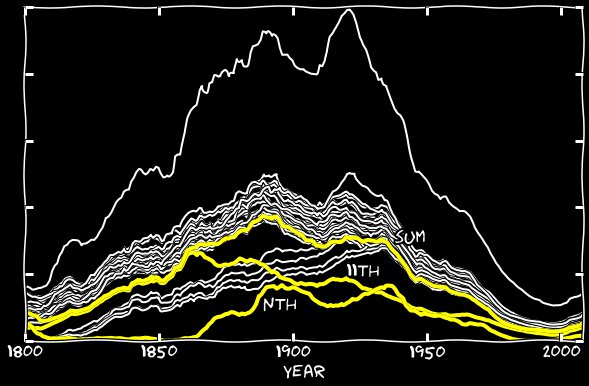 Jadwal gabunganDengan menambahkan kesalahan xxth dan n-th ke grafik ke-11, saya menutup celah di sepanjang grafik, dan ke-11 mulai terlihat sama dengan semua tanggal lainnya. Ternyata pengakuan yang salah dari tanggal 11 dalam bentuk tanggal ke-11, ke-11, dan seterusnya, bertanggung jawab atas sejumlah kecil dari 11 angka di antara hari-hari lainnya dalam sebulan.
Jadwal gabunganDengan menambahkan kesalahan xxth dan n-th ke grafik ke-11, saya menutup celah di sepanjang grafik, dan ke-11 mulai terlihat sama dengan semua tanggal lainnya. Ternyata pengakuan yang salah dari tanggal 11 dalam bentuk tanggal ke-11, ke-11, dan seterusnya, bertanggung jawab atas sejumlah kecil dari 11 angka di antara hari-hari lainnya dalam sebulan.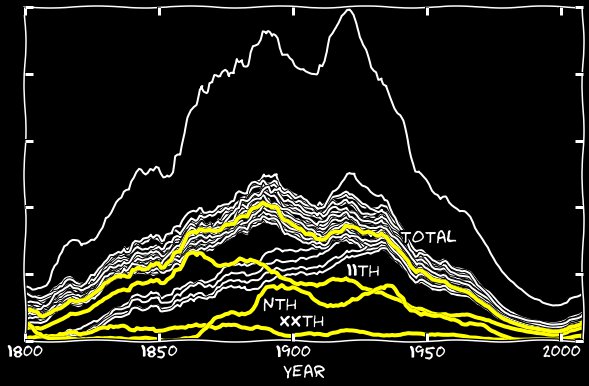
Mesin cetak
Meskipun jelas mengapa ke-11 lebih sering dikenali secara salah daripada yang lain, mengapa jumlah kesalahannya tidak merata? Apa yang terjadi pada tahun 1860-an, karena itu tingkat kesalahannya melonjak sangat banyak? Saya menduga ini karena penemuan pada tahun 1860-an dari perangkat seperti mesin tik. Mesin tik paling awal tidak memiliki kunci terpisah untuk nomor 1 . Diusulkan untuk menggunakan huruf l (L) dalam huruf kecil sebagai gantinya. Dan ketika algoritma mengenali tanggal 11 Oktober, itu sebenarnya lebih tepat daripada yang kita duga. Buku Google tidak memiliki banyak dokumen yang diketik, tetapi perangkat populer ini memiliki dampak besar pada pengembangan font. 1 dan l tidak berbeda pada mesin tik yang semakin umum, dan bahkan font tipografi mulai memenuhi harapan kesamaan ini. Bandingkan karakter-karakter ini dalam font1850 : Perbedaan antara l tanpa serif di atas dan 1 dengan serif jelas terlihat. Bandingkan mereka dalam font 1920 :
Perbedaan antara l tanpa serif di atas dan 1 dengan serif jelas terlihat. Bandingkan mereka dalam font 1920 : Karakter identik kecuali untuk kerning. Dan hari ini, sebagian besar font menggambarkan 1 dan l sebagai karakter tinggi dengan dua serif di bagian bawah dan satu mengarah ke kiri, di atas. Hanya sudut takik 1 yang sedikit lebih besar dari pada l. Kualitas cetak buku sejak 1970 telah membantu mengurangi jumlah pengakuan yang salah, tetapi belum sepenuhnya hilang, sehingga masalah yang tersisa muncul pada komik dari xkcd.Pertanyaan popularitas kesalahan tetap terbuka, di mana 11 digantikan oleh yang ke-n. Ini adalah kesalahan yang agak aneh. Yang ke-9 sering ditemukan dalam publikasi matematika dan ilmiah, dan ini dapat mempengaruhi popularitasnya. Pada sebagian besar font, bagian atas n sangat tipis, dan mungkin tidak terlihat dalam teks tempat algoritma dilatih. Tetapi ada perbedaan besar dalam pertumbuhan 1 dan n, terutama di era mesin tik, di mana banyak kesalahan terjadi. Tetapi frasa ke-Januari adalah omong kosong, jadi peluang pengakuan seperti itu seharusnya dikurangi. Mungkin beberapa teks modern mengandung kesalahan, dan teks ke-11 ditandai sebagai teks ke-n, yang berfungsi sebagai sumber kesalahan? Satu-satunya cara untuk mengetahuinya adalah dengan membuka kode sumber algoritma dari Google, yang mengenali teks. Kami akan menyerahkan latihan ini kepada pembaca.
Karakter identik kecuali untuk kerning. Dan hari ini, sebagian besar font menggambarkan 1 dan l sebagai karakter tinggi dengan dua serif di bagian bawah dan satu mengarah ke kiri, di atas. Hanya sudut takik 1 yang sedikit lebih besar dari pada l. Kualitas cetak buku sejak 1970 telah membantu mengurangi jumlah pengakuan yang salah, tetapi belum sepenuhnya hilang, sehingga masalah yang tersisa muncul pada komik dari xkcd.Pertanyaan popularitas kesalahan tetap terbuka, di mana 11 digantikan oleh yang ke-n. Ini adalah kesalahan yang agak aneh. Yang ke-9 sering ditemukan dalam publikasi matematika dan ilmiah, dan ini dapat mempengaruhi popularitasnya. Pada sebagian besar font, bagian atas n sangat tipis, dan mungkin tidak terlihat dalam teks tempat algoritma dilatih. Tetapi ada perbedaan besar dalam pertumbuhan 1 dan n, terutama di era mesin tik, di mana banyak kesalahan terjadi. Tetapi frasa ke-Januari adalah omong kosong, jadi peluang pengakuan seperti itu seharusnya dikurangi. Mungkin beberapa teks modern mengandung kesalahan, dan teks ke-11 ditandai sebagai teks ke-n, yang berfungsi sebagai sumber kesalahan? Satu-satunya cara untuk mengetahuinya adalah dengan membuka kode sumber algoritma dari Google, yang mengenali teks. Kami akan menyerahkan latihan ini kepada pembaca.Kehilangan 2, 3, 22 dan 23
Kami menemukan angka ke-11, tetapi selama mempelajari perilaku mereka, saya menemukan misteri lain - angka 2, 3, 22, dan 23 yang sangat rendah, tetapi hanya sampai tahun 1930-an, setelah membawa nomor mereka disamakan.Pada grafik di bawah ini adalah semua angka, dan ternyata pada tahun 1800 tanggal yang ditunjukkan tidak digunakan sama sekali. Referensi pertama untuk tanggal kami muncul pada tahun 1810-an, jumlah mereka tumbuh pada tingkat yang sama dengan tanggal lainnya, tetapi pada saat yang sama mempertahankan jarak dengan mereka - jumlah mereka sekitar setengah kecil. Tiba-tiba, pada tahun 1890-an, jurang menyempit, dan ini terjadi sampai tahun 1930-an, ketika mereka akhirnya bergabung ke dalam kelompok utama.
Gaya pra-revolusioner
Jadi, apakah angka 2 dan 3 di abad ke-19 tidak bahagia? Apakah algoritma Google hampir tidak mengenali dua dan tiga dalam font lama? Tidak, ternyata sebelumnya daripada catatan bahasa Inggris saat ini "2, 3, 22," 23 adalah kebiasaan untuk menulis "2d, 3d, 22d, 23d". Saya membangun rata-rata untuk 2 Januari, 2 Februari dan bulan-bulan lainnya, dan saya melakukan hal yang sama dengan tanggal yang tersisa. Grafik di bawah ini menunjukkan frekuensi kemunculan tanggal-tanggal ini dalam gaya rekaman lama - mereka mulai dengan frekuensi tanggal lainnya, tetapi kemudian secara bertahap menghilang pada 1890-an, dan sepenuhnya larut pada 1930-an.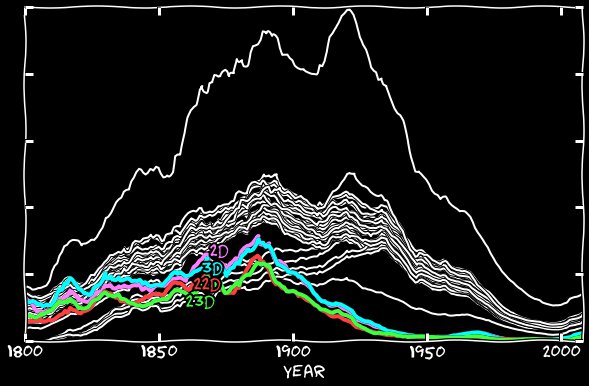 Kadang-kadang Anda dapat menemukan penggunaan modern dari bentuk lama rekaman, jika digunakan dalam judul dengan sejarah panjang, seperti 3d Marine Division. Tetapi sisa penggunaan catatan semacam itu terutama disebabkan oleh adanya cetak ulang buku-buku lama dan publikasi buku harian lama.
Kadang-kadang Anda dapat menemukan penggunaan modern dari bentuk lama rekaman, jika digunakan dalam judul dengan sejarah panjang, seperti 3d Marine Division. Tetapi sisa penggunaan catatan semacam itu terutama disebabkan oleh adanya cetak ulang buku-buku lama dan publikasi buku harian lama.Jadwal gabungan
Jika kita menambahkan gaya lama ke yang baru, kita mendapatkan grafik berikut. Oleh karena itu tanggal yang dihitung dengan benar hampir tidak berbeda dari yang lainnya.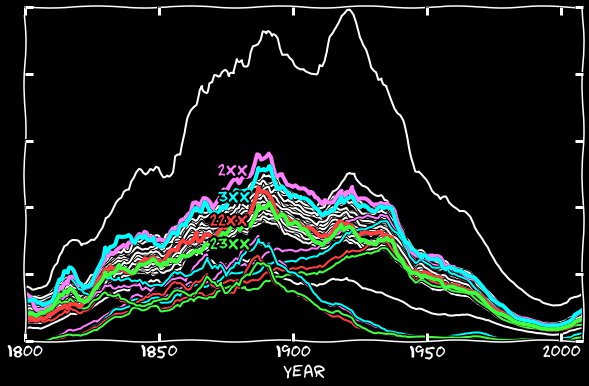 Mengapa sekarang ternyata referensi ke 2 dan 3 angka kadang-kadang melebihi yang lain dalam frekuensi, tetap tidak bisa dipahami oleh saya. Saya pikir karena terlalu sering menyebutkan tanggal 1 bulan itu, tanggal 2 dan 3 juga harus disebutkan sedikit lebih sering. Tetapi jika Anda melihat kemunculan 2 Januari atau 2 Januari di Google Books, Anda dapat menemukan beberapa bagian seperti itu:
Mengapa sekarang ternyata referensi ke 2 dan 3 angka kadang-kadang melebihi yang lain dalam frekuensi, tetap tidak bisa dipahami oleh saya. Saya pikir karena terlalu sering menyebutkan tanggal 1 bulan itu, tanggal 2 dan 3 juga harus disebutkan sedikit lebih sering. Tetapi jika Anda melihat kemunculan 2 Januari atau 2 Januari di Google Books, Anda dapat menemukan beberapa bagian seperti itu: Rupanya, Google Books mengabaikan koma. Jadi, walaupun tanggal dalam bulan dari tanggal 1 hingga 4 tidak ada yang istimewa, contoh-contoh seperti ini dapat memengaruhi statistik.
Rupanya, Google Books mengabaikan koma. Jadi, walaupun tanggal dalam bulan dari tanggal 1 hingga 4 tidak ada yang istimewa, contoh-contoh seperti ini dapat memengaruhi statistik.Alasan
Mengapa penulis menggunakan singkatan satu huruf seperti itu sebelumnya? Mungkin karena bahasa Latin, di mana huruf o berfungsi sebagai indikator nomor seri. Bahasa asmara seperti Spanyol, Italia, dan Portugis masih menggunakan o atau a. Kami masih akan menggunakan d jika bukan untuk 1, 4, dll, yang konsonan terakhir tidak dinyatakan dalam bahasa Inggris dengan satu huruf. Ternyata mengikuti bahasa Inggris melebihi keinginan untuk meniru bahasa Latin.Source: https://habr.com/ru/post/id397869/
All Articles