"Photoshop" untuk ucapan manusia
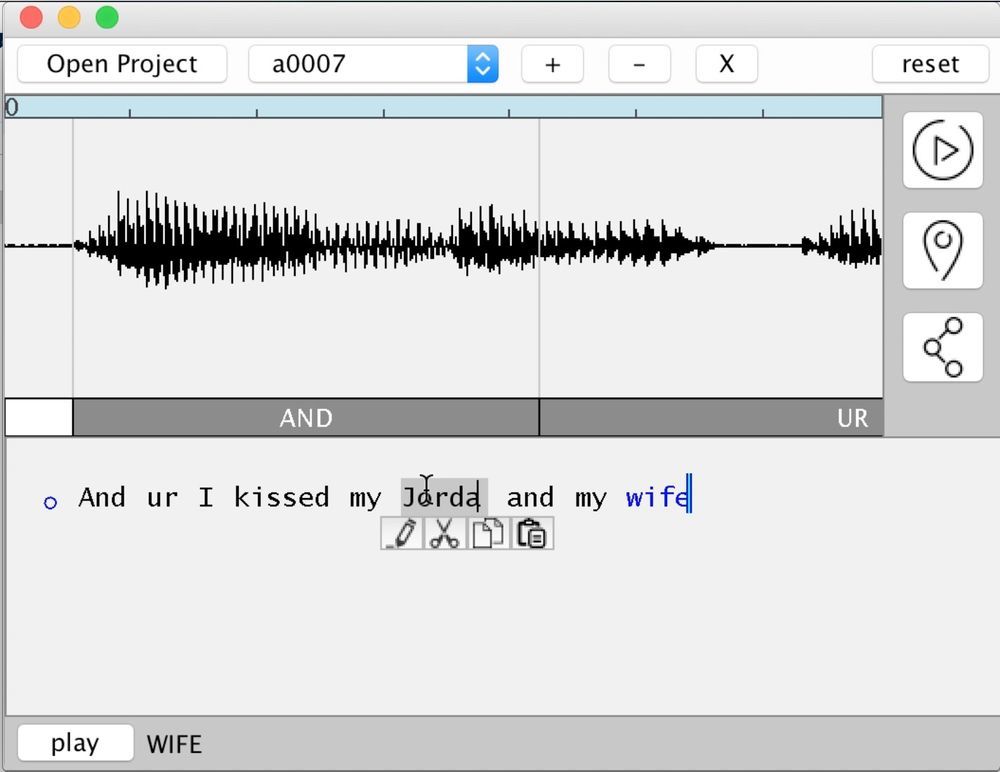 3 November 2016 di konferensi teknologi Adobe MAX, Adobe mempresentasikan perkembangan ilmiah dan teknis yang sangat menarik, yang di masa depan dapat berubah menjadi aplikasi perangkat lunak yang populer. Singkatnya, penemuan ini adalah program untuk mengedit semantik ucapan manusia. Dalam hal ini, tidak hanya metode standar sintesis dari fonem yang dikumpulkan (sintesis kompilasi) yang digunakan, tetapi juga metode tambahan yang meningkatkan realisme. Ini adalah pilihan cerdas trifon dan penggunaan karakteristik spesifik dari sampel suara.Akibatnya, pengguna menulis teks sewenang-wenang - dan program menyuarakannya dengan suara yang dilatih. Anda dapat dengan cepat menambahkan kata ke pidato atau memotong kata-kata yang tidak perlu.Dalam praktiknya, program yang disajikan sebagai bagian dari proyek VoCo berfungsi sebagai berikut. Pertama, basis fonem disusun untuk suara orang tertentu dalam bahasa tertentu. Untuk hasil yang realistis, program ini membutuhkan minimal 20 menit pidato manusia. Semakin banyak, semakin baik. Berdasarkan kumpulan fonem (trifon) yang terkumpul, program kemudian dapat mengumpulkan hampir semua kata baru dari batu bata.Fragmen presentasi VoCo di konferensi MAXDalam arti tertentu, VoCo berfungsi seperti karya kuas konteks di Photoshop. Dia juga mengambil fragmen dari berbagai tempat gambar - dan mengumpulkan gambar baru dari fragmen ini. Sepotong kayu dari foto hutan, sepotong rumput dari gambar lain dan seorang gadis dari foto ketiga - dan kami mendapatkan karya fotorealistik yang sama sekali baru dengan hutan, rumput, dan seorang gadis di latar depan. Jika pekerjaan dilakukan secara profesional, maka pemasangannya sangat sulit ditentukan. Jadi di masa Soviet , orang - orang yang tiba-tiba menjadi musuh rakyat terhapus dari sejarah . Ada seseorang di foto itu - dan sekarang ada kekosongan atau orang lain.Jadi teknologi VoCo memungkinkan Anda untuk melengkapi ucapan manusia dengan kata dan frasa yang sewenang-wenang.Pada konferensi MAX, salah satu pengembang, Zeyu Jin, memberikan presentasi. Dalam makalah ilmiah yang diterbitkan sebelumnya , ia terdaftar sebagai karyawan Universitas Princeton, bersama dengan rekannya Adam Finkelstein. Teknologi ini dikembangkan oleh Adobe Research bekerja sama dengan Princeton University.Seperti yang dikandung oleh Adobe, teknologi ini akan membantu pembuat konten untuk lebih mudah mengedit trek audio: dialog dan teks sulih suara untuk dengan cepat memperbaiki kesalahan atau membuat perubahan pada alur cerita.Adobe menekankan bahwa dalam hal ini lebih tepat untuk berbicara tentang "konversi suara" daripada sintesis suara klasik. Tujuan konversi suara adalah untuk mengubah suara asli sehingga bagi pendengar suara itu tampaknya adalah suara orang lain mengikuti model suara yang terakhir.Fondasi teknis konversi suara dijelaskan secara lebih rinci dalam makalah ilmiah di atas .dipersiapkan bersama dengan Universitas Princeton. Penulisnya menunjukkan bahwa teknik CUTE yang dikembangkan secara kualitatif lebih unggul daripada metode konversi suara lainnya. Metode konversi alternatif biasanya didasarkan pada analisis paralel dari frasa yang identik dari sumber dan target, diikuti oleh perhitungan vektor transformasi tertentu di setiap ruang alamat. Setelah itu, setiap bagian acak dari suara asli dapat ditransformasikan menggunakan vektor yang diperoleh. Tetapi metode ini menderita efek samping yang tidak menyenangkan - ucapan yang disintesis dengan cara ini tuli, tidak jelas.Peneliti Adobe mampu mengatasi kekurangan teknik lain menggunakan metode CUTE hybrid. Judul mengenkripsi empat komponen utama dari teknik ini: sintesis kompilasi (sintesis concatenative); pemilihan unit; pemilihan awal trifon, yaitu, unit tiga fonem (pra-pemilihan Triphone); Menggunakan properti sampel (fitur berbasis contoh).Sintesis kompilasi direduksi menjadi penulisan pesan dari kamus fonem yang direkam sebelumnya. Ini adalah metode utama bekerja dengan synthesizer wicara, yang dilengkapi dengan berbagai perangkat: dari pesawat militer ke perangkat domestik, dalam layanan bantuan operator seluler, dll.Seperti namanya, teknik hibrida yang dikembangkan menggabungkan beberapa metode sintesis wicara dan konversi suara.Karya ilmiah menyajikan hasil uji komparatif dengan metode konversi suara lainnya, di mana CUTE secara signifikan lebih unggul daripada pesaing. Pada saat yang sama, beberapa kekurangannya disebutkan: ia, seperti orang lain, menderita kekurangan jumlah fonem dalam database ketika mensintesiskan kata-kata baru, yang menghasilkan fonetis benar, tetapi hasilnya tidak terlalu realistis. Selain itu, itu tergantung pada operasi mesin pengenalan suara untuk segmentasi fonetik yang benar.Masih belum diketahui apakah Adobe akan mengimplementasikan pengembangan yang menjanjikan ini dalam bentuk produk komersial nyata. Tetapi sekarang kita dapat mengatakan bahwa program semacam itu akan menjadi sangat populer, asalkan sintesis suara dari fonem itu realistis. Misalnya, podcasters dapat menggunakannya untuk membuat podcast dari teks. Ini juga dapat digunakan untuk menyuarakan buku audio menggunakan suara orang yang sewenang-wenang (misalnya, gadis Anda sendiri). Teknologi semacam itu kemungkinan akan menemukan aplikasi di Hollywood untuk akting suara tanpa adanya aktor. Misalnya, jika kontrak diputuskan dengan dia atau dia meninggal di tengah syuting.
3 November 2016 di konferensi teknologi Adobe MAX, Adobe mempresentasikan perkembangan ilmiah dan teknis yang sangat menarik, yang di masa depan dapat berubah menjadi aplikasi perangkat lunak yang populer. Singkatnya, penemuan ini adalah program untuk mengedit semantik ucapan manusia. Dalam hal ini, tidak hanya metode standar sintesis dari fonem yang dikumpulkan (sintesis kompilasi) yang digunakan, tetapi juga metode tambahan yang meningkatkan realisme. Ini adalah pilihan cerdas trifon dan penggunaan karakteristik spesifik dari sampel suara.Akibatnya, pengguna menulis teks sewenang-wenang - dan program menyuarakannya dengan suara yang dilatih. Anda dapat dengan cepat menambahkan kata ke pidato atau memotong kata-kata yang tidak perlu.Dalam praktiknya, program yang disajikan sebagai bagian dari proyek VoCo berfungsi sebagai berikut. Pertama, basis fonem disusun untuk suara orang tertentu dalam bahasa tertentu. Untuk hasil yang realistis, program ini membutuhkan minimal 20 menit pidato manusia. Semakin banyak, semakin baik. Berdasarkan kumpulan fonem (trifon) yang terkumpul, program kemudian dapat mengumpulkan hampir semua kata baru dari batu bata.Fragmen presentasi VoCo di konferensi MAXDalam arti tertentu, VoCo berfungsi seperti karya kuas konteks di Photoshop. Dia juga mengambil fragmen dari berbagai tempat gambar - dan mengumpulkan gambar baru dari fragmen ini. Sepotong kayu dari foto hutan, sepotong rumput dari gambar lain dan seorang gadis dari foto ketiga - dan kami mendapatkan karya fotorealistik yang sama sekali baru dengan hutan, rumput, dan seorang gadis di latar depan. Jika pekerjaan dilakukan secara profesional, maka pemasangannya sangat sulit ditentukan. Jadi di masa Soviet , orang - orang yang tiba-tiba menjadi musuh rakyat terhapus dari sejarah . Ada seseorang di foto itu - dan sekarang ada kekosongan atau orang lain.Jadi teknologi VoCo memungkinkan Anda untuk melengkapi ucapan manusia dengan kata dan frasa yang sewenang-wenang.Pada konferensi MAX, salah satu pengembang, Zeyu Jin, memberikan presentasi. Dalam makalah ilmiah yang diterbitkan sebelumnya , ia terdaftar sebagai karyawan Universitas Princeton, bersama dengan rekannya Adam Finkelstein. Teknologi ini dikembangkan oleh Adobe Research bekerja sama dengan Princeton University.Seperti yang dikandung oleh Adobe, teknologi ini akan membantu pembuat konten untuk lebih mudah mengedit trek audio: dialog dan teks sulih suara untuk dengan cepat memperbaiki kesalahan atau membuat perubahan pada alur cerita.Adobe menekankan bahwa dalam hal ini lebih tepat untuk berbicara tentang "konversi suara" daripada sintesis suara klasik. Tujuan konversi suara adalah untuk mengubah suara asli sehingga bagi pendengar suara itu tampaknya adalah suara orang lain mengikuti model suara yang terakhir.Fondasi teknis konversi suara dijelaskan secara lebih rinci dalam makalah ilmiah di atas .dipersiapkan bersama dengan Universitas Princeton. Penulisnya menunjukkan bahwa teknik CUTE yang dikembangkan secara kualitatif lebih unggul daripada metode konversi suara lainnya. Metode konversi alternatif biasanya didasarkan pada analisis paralel dari frasa yang identik dari sumber dan target, diikuti oleh perhitungan vektor transformasi tertentu di setiap ruang alamat. Setelah itu, setiap bagian acak dari suara asli dapat ditransformasikan menggunakan vektor yang diperoleh. Tetapi metode ini menderita efek samping yang tidak menyenangkan - ucapan yang disintesis dengan cara ini tuli, tidak jelas.Peneliti Adobe mampu mengatasi kekurangan teknik lain menggunakan metode CUTE hybrid. Judul mengenkripsi empat komponen utama dari teknik ini: sintesis kompilasi (sintesis concatenative); pemilihan unit; pemilihan awal trifon, yaitu, unit tiga fonem (pra-pemilihan Triphone); Menggunakan properti sampel (fitur berbasis contoh).Sintesis kompilasi direduksi menjadi penulisan pesan dari kamus fonem yang direkam sebelumnya. Ini adalah metode utama bekerja dengan synthesizer wicara, yang dilengkapi dengan berbagai perangkat: dari pesawat militer ke perangkat domestik, dalam layanan bantuan operator seluler, dll.Seperti namanya, teknik hibrida yang dikembangkan menggabungkan beberapa metode sintesis wicara dan konversi suara.Karya ilmiah menyajikan hasil uji komparatif dengan metode konversi suara lainnya, di mana CUTE secara signifikan lebih unggul daripada pesaing. Pada saat yang sama, beberapa kekurangannya disebutkan: ia, seperti orang lain, menderita kekurangan jumlah fonem dalam database ketika mensintesiskan kata-kata baru, yang menghasilkan fonetis benar, tetapi hasilnya tidak terlalu realistis. Selain itu, itu tergantung pada operasi mesin pengenalan suara untuk segmentasi fonetik yang benar.Masih belum diketahui apakah Adobe akan mengimplementasikan pengembangan yang menjanjikan ini dalam bentuk produk komersial nyata. Tetapi sekarang kita dapat mengatakan bahwa program semacam itu akan menjadi sangat populer, asalkan sintesis suara dari fonem itu realistis. Misalnya, podcasters dapat menggunakannya untuk membuat podcast dari teks. Ini juga dapat digunakan untuk menyuarakan buku audio menggunakan suara orang yang sewenang-wenang (misalnya, gadis Anda sendiri). Teknologi semacam itu kemungkinan akan menemukan aplikasi di Hollywood untuk akting suara tanpa adanya aktor. Misalnya, jika kontrak diputuskan dengan dia atau dia meninggal di tengah syuting.Source: https://habr.com/ru/post/id398865/
All Articles