Jaringan saraf LipNet membaca bibir dengan akurasi 93,4%
 Komandan Dave Bowman dan co-pilot Frank Pool, yang tidak mempercayai komputer, memutuskan untuk melepaskannya dari kendali kapal. Untuk melakukan ini, mereka berunding di ruang kedap suara, tetapi HAL 9000 membaca percakapan mereka di bibir. Ditembak dari film "Space Odyssey of 2001"Membaca bibir memainkan peran penting dalam komunikasi. Lebih banyak eksperimen pada tahun 1976 menunjukkan bahwa orang "mendengar" fonem yang sama sekali berbeda jika Anda menerapkan bunyi yang salah pada gerakan bibir (lihat "Mendengar bibir dan melihat suara" , Nature 264, 746-748, 23 Desember 1976, doi: 10.1038 / 264746a0) .Dari sudut pandang praktis, membaca bibir adalah keterampilan yang penting dan bermanfaat. Anda dapat memahami lawan bicara tanpa mematikan musik di headphone, membaca percakapan semua orang di bidang pandang (misalnya, semua penumpang di ruang tunggu), mendengarkan orang melalui teropong atau teleskop. Lingkup keterampilan sangat luas. Seorang profesional yang telah menguasainya akan dengan mudah menemukan pekerjaan bergaji tinggi. Misalnya, di bidang keamanan atau intelijen kompetitif.Sistem pembacaan bibir otomatis juga memiliki banyak potensi praktis. Ini adalah alat bantu dengar medis generasi baru dengan pengenalan ucapan, sistem untuk perkuliahan sunyi di tempat-tempat umum, identifikasi biometrik, sistem untuk transmisi rahasia informasi untuk spionase, pengenalan ucapan melalui video dari kamera pengintai, dll. Pada akhirnya, komputer masa depan juga akan membaca bibir, seperti HAL 9000 .Karena itu, para ilmuwan telah berusaha selama bertahun-tahun untuk mengembangkan sistem pembacaan bibir otomatis, tetapi tidak banyak berhasil. Bahkan untuk bahasa Inggris yang relatif sederhana, di mana jumlah fonem jauh lebih kecil daripada di Rusia, akurasi pengenalannya rendah.Memahami ucapan berdasarkan ekspresi wajah manusia adalah tugas yang menakutkan. Orang yang telah menguasai keterampilan ini mencoba mengenali puluhan fonem konsonan, banyak di antaranya sangat mirip dalam penampilan. Sangat sulit bagi orang yang tidak terlatih untuk membedakan antara lima kategori fonem visual (yaitu, visema) bahasa Inggris. Dengan kata lain, untuk membedakan pengucapan beberapa konsonan dengan bibir hampir tidak mungkin. Tidak mengherankan bahwa orang melakukannya dengan sangat buruk dengan pembacaan bibir yang akurat. Bahkan yang terbaik dari orang dengan gangguan pendengaran menunjukkan keakuratan hanya 17 ± 12% dari 30 suku kata tunggal atau 21 ± 11% dari kata-kata polisilabik (selanjutnya hasil untuk bahasa Inggris).Pembacaan bibir otomatis adalah salah satu tugas penglihatan mesin, yang bermuara pada pemrosesan frame-by-frame dari urutan video. Tugas ini sangat rumit oleh rendahnya kualitas materi video paling praktis, yang tidak memungkinkan pembacaan yang akurat tentang karakteristik spasial temporal, yaitu karakteristik spatio-temporal seseorang selama percakapan. Wajah bergerak dan berbelok ke arah yang berbeda. Perkembangan terbaru dalam bidang penglihatan mesin sedang mencoba melacak pergerakan wajah dalam bingkai untuk menyelesaikan masalah ini. Meskipun sukses, sampai saat ini, mereka hanya mampu mengenali kata-kata individual, tetapi tidak kalimat.Terobosan signifikan dalam bidang ini dicapai oleh pengembang dari Universitas Oxford. LipNet yang mereka latihmenjadi yang pertama di dunia yang berhasil mengenali bibir di tingkat seluruh kalimat, memproses rekaman video. Peta arti
Komandan Dave Bowman dan co-pilot Frank Pool, yang tidak mempercayai komputer, memutuskan untuk melepaskannya dari kendali kapal. Untuk melakukan ini, mereka berunding di ruang kedap suara, tetapi HAL 9000 membaca percakapan mereka di bibir. Ditembak dari film "Space Odyssey of 2001"Membaca bibir memainkan peran penting dalam komunikasi. Lebih banyak eksperimen pada tahun 1976 menunjukkan bahwa orang "mendengar" fonem yang sama sekali berbeda jika Anda menerapkan bunyi yang salah pada gerakan bibir (lihat "Mendengar bibir dan melihat suara" , Nature 264, 746-748, 23 Desember 1976, doi: 10.1038 / 264746a0) .Dari sudut pandang praktis, membaca bibir adalah keterampilan yang penting dan bermanfaat. Anda dapat memahami lawan bicara tanpa mematikan musik di headphone, membaca percakapan semua orang di bidang pandang (misalnya, semua penumpang di ruang tunggu), mendengarkan orang melalui teropong atau teleskop. Lingkup keterampilan sangat luas. Seorang profesional yang telah menguasainya akan dengan mudah menemukan pekerjaan bergaji tinggi. Misalnya, di bidang keamanan atau intelijen kompetitif.Sistem pembacaan bibir otomatis juga memiliki banyak potensi praktis. Ini adalah alat bantu dengar medis generasi baru dengan pengenalan ucapan, sistem untuk perkuliahan sunyi di tempat-tempat umum, identifikasi biometrik, sistem untuk transmisi rahasia informasi untuk spionase, pengenalan ucapan melalui video dari kamera pengintai, dll. Pada akhirnya, komputer masa depan juga akan membaca bibir, seperti HAL 9000 .Karena itu, para ilmuwan telah berusaha selama bertahun-tahun untuk mengembangkan sistem pembacaan bibir otomatis, tetapi tidak banyak berhasil. Bahkan untuk bahasa Inggris yang relatif sederhana, di mana jumlah fonem jauh lebih kecil daripada di Rusia, akurasi pengenalannya rendah.Memahami ucapan berdasarkan ekspresi wajah manusia adalah tugas yang menakutkan. Orang yang telah menguasai keterampilan ini mencoba mengenali puluhan fonem konsonan, banyak di antaranya sangat mirip dalam penampilan. Sangat sulit bagi orang yang tidak terlatih untuk membedakan antara lima kategori fonem visual (yaitu, visema) bahasa Inggris. Dengan kata lain, untuk membedakan pengucapan beberapa konsonan dengan bibir hampir tidak mungkin. Tidak mengherankan bahwa orang melakukannya dengan sangat buruk dengan pembacaan bibir yang akurat. Bahkan yang terbaik dari orang dengan gangguan pendengaran menunjukkan keakuratan hanya 17 ± 12% dari 30 suku kata tunggal atau 21 ± 11% dari kata-kata polisilabik (selanjutnya hasil untuk bahasa Inggris).Pembacaan bibir otomatis adalah salah satu tugas penglihatan mesin, yang bermuara pada pemrosesan frame-by-frame dari urutan video. Tugas ini sangat rumit oleh rendahnya kualitas materi video paling praktis, yang tidak memungkinkan pembacaan yang akurat tentang karakteristik spasial temporal, yaitu karakteristik spatio-temporal seseorang selama percakapan. Wajah bergerak dan berbelok ke arah yang berbeda. Perkembangan terbaru dalam bidang penglihatan mesin sedang mencoba melacak pergerakan wajah dalam bingkai untuk menyelesaikan masalah ini. Meskipun sukses, sampai saat ini, mereka hanya mampu mengenali kata-kata individual, tetapi tidak kalimat.Terobosan signifikan dalam bidang ini dicapai oleh pengembang dari Universitas Oxford. LipNet yang mereka latihmenjadi yang pertama di dunia yang berhasil mengenali bibir di tingkat seluruh kalimat, memproses rekaman video. Peta arti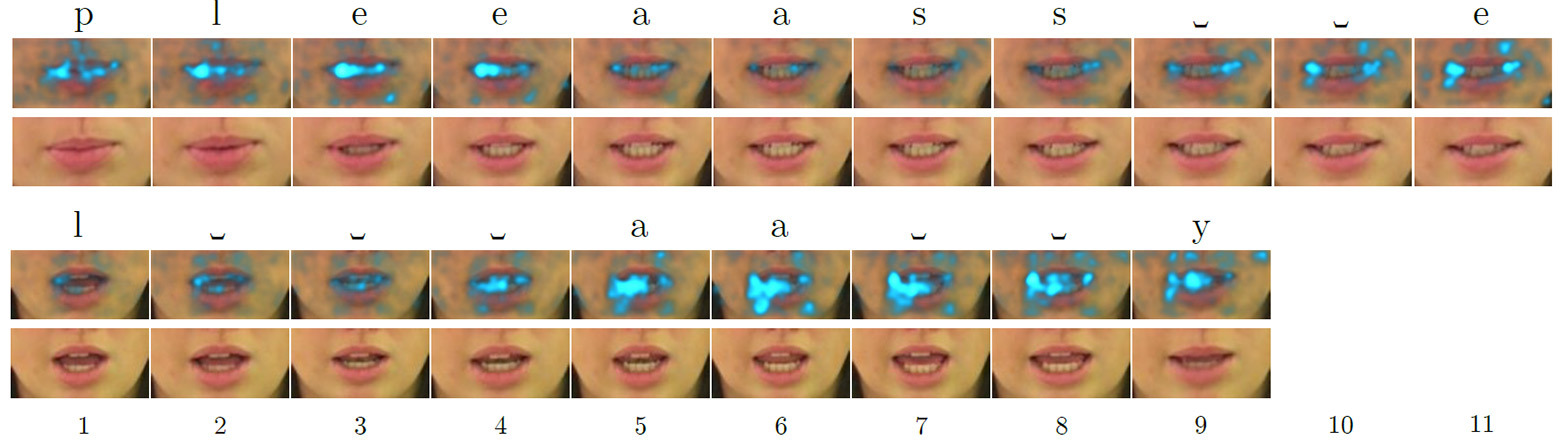 - penting bingkai demi bingkai untuk kata-kata bahasa Inggris "tolong" (di atas) dan "berbaring" (di bawah) ketika diproses oleh jaringan saraf yang membaca bibir, menyoroti fiturLipNet - jaringan saraf yang paling mencolok dari jenis LSTM (memori jangka pendek). Arsitekturnya ditunjukkan dalam ilustrasi. Jaringan saraf dilatih menggunakan metode Connectionist Temporal Classification (CTC), yang banyak digunakan dalam sistem pengenalan suara modern, karena menghilangkan kebutuhan untuk pelatihan pada set input data yang disinkronkan dengan hasil yang benar.
- penting bingkai demi bingkai untuk kata-kata bahasa Inggris "tolong" (di atas) dan "berbaring" (di bawah) ketika diproses oleh jaringan saraf yang membaca bibir, menyoroti fiturLipNet - jaringan saraf yang paling mencolok dari jenis LSTM (memori jangka pendek). Arsitekturnya ditunjukkan dalam ilustrasi. Jaringan saraf dilatih menggunakan metode Connectionist Temporal Classification (CTC), yang banyak digunakan dalam sistem pengenalan suara modern, karena menghilangkan kebutuhan untuk pelatihan pada set input data yang disinkronkan dengan hasil yang benar.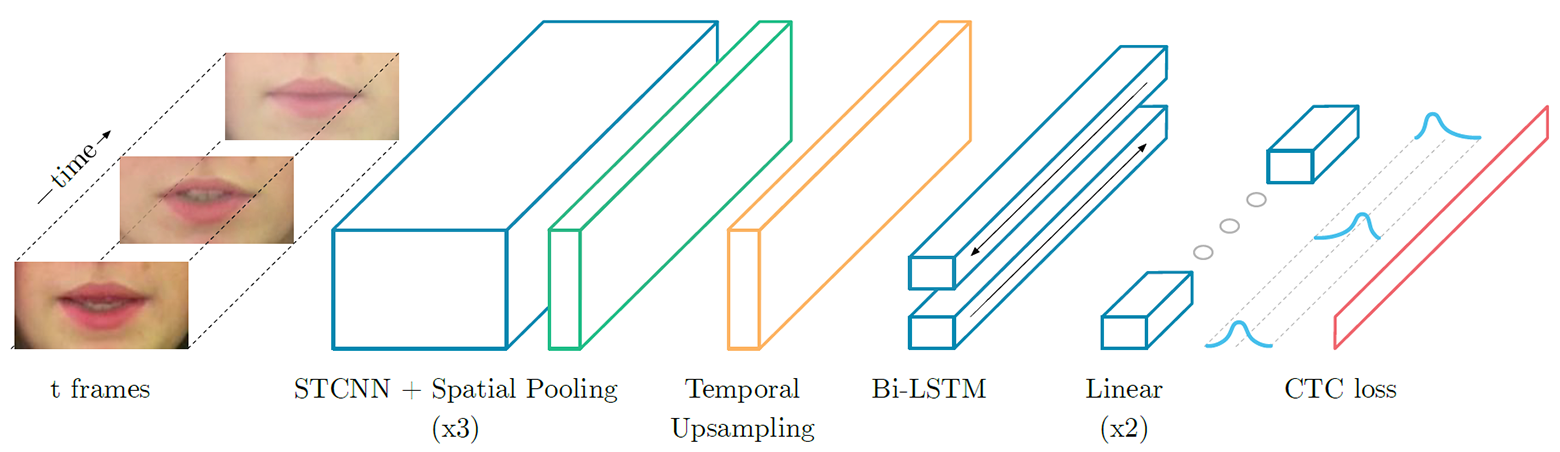 Arsitektur jaringan saraf LipNet. Pada input, urutan frame T disediakan, yang kemudian diproses oleh tiga lapisan jaringan saraf convolutional spatiotemporal (spatiotemporal) (STCNN), yang masing-masing disertai dengan lapisan sampling spasial. Untuk fitur yang diekstraksi, laju pengambilan sampel pada timeline (upsampling) ditingkatkan, dan kemudian diproses oleh LTSM ganda. Setiap langkah waktu pada output LTSM diproses oleh jaringan distribusi langsung dua-lapisan dan lapisan SoftMax terakhir.Pada paket penawaran GRID khusus, jaringan saraf menunjukkan akurasi pengenalan 93,4%. Ini tidak hanya melebihi ketepatan pengakuan pengembangan perangkat lunak lain (yang ditunjukkan dalam tabel di bawah), tetapi juga melebihi efisiensi membaca di bibir orang-orang yang terlatih khusus.
Arsitektur jaringan saraf LipNet. Pada input, urutan frame T disediakan, yang kemudian diproses oleh tiga lapisan jaringan saraf convolutional spatiotemporal (spatiotemporal) (STCNN), yang masing-masing disertai dengan lapisan sampling spasial. Untuk fitur yang diekstraksi, laju pengambilan sampel pada timeline (upsampling) ditingkatkan, dan kemudian diproses oleh LTSM ganda. Setiap langkah waktu pada output LTSM diproses oleh jaringan distribusi langsung dua-lapisan dan lapisan SoftMax terakhir.Pada paket penawaran GRID khusus, jaringan saraf menunjukkan akurasi pengenalan 93,4%. Ini tidak hanya melebihi ketepatan pengakuan pengembangan perangkat lunak lain (yang ditunjukkan dalam tabel di bawah), tetapi juga melebihi efisiensi membaca di bibir orang-orang yang terlatih khusus.| Metode | Dataset | Ukuran | Masalah | Akurasi |
|---|
| Fu et al. (2008) | AVICAR | 851 | | 37,9% |
| Zhao et al. (2009) | AVLetter | 78 | | 43,5% |
| Papandreou et al. (2009) | CUAVE | 1800 | | 83,0% |
| Chung & Zisserman (2016a) | OuluVS1 | 200 | | 91,4% |
| Chung & Zisserman (2016b) | OuluVS2 | 520 | | 94,1% |
| Chung & Zisserman (2016a) | BBC TV | >400000 | | 65,4% |
| Wand et al. (2016) | GRID | 9000 | | 79,6% |
| LipNet | GRID | 28853 | | 93,4% |
Casing GRID khusus disusun menurut templat berikut:perintah (4) + warna (4) + preposisi (4) + huruf (25) + digit (10) + kata keterangan (4), dimana angka tersebut sesuai dengan jumlah varian kata untuk masing-masing dari enam kategori verbal .Dengan kata lain, akurasi 93,4% masih merupakan hasil yang diperoleh dalam kondisi laboratorium rumah kaca. Tentu saja, dengan pengakuan ucapan manusia yang sewenang-wenang, hasilnya akan jauh lebih buruk. Belum lagi analisis data dari video nyata, di mana wajah seseorang tidak diambil dari dekat dalam pencahayaan yang sangat baik dan resolusi tinggi.Pengoperasian jaringan saraf LipNet ditunjukkan dalam video demo.Artikel ilmiah disiapkan untuk konferensi ICLR 2017 dan diterbitkan pada 4 November 2016 dalam domain publik.Source: https://habr.com/ru/post/id398901/
All Articles