Jaringan saraf membaca 46,8% dari kata-kata di bibir di televisi, sementara hanya 12,4% orang
 Kerangka dari empat program di mana program itu dipelajari, serta kata "siang", diucapkan oleh dua pembicara yang berbedaDua minggu lalu, mereka berbicara tentang jaringan saraf LipNet , yang menunjukkan kualitas rekaman 93,4% pengenalan ucapan manusia di bibir. Bahkan kemudian, banyak aplikasi yang seharusnya untuk sistem komputer seperti itu: generasi baru alat bantu dengar medis dengan pengenalan suara, sistem untuk perkuliahan bisu di tempat umum, identifikasi biometrik, sistem untuk transmisi rahasia informasi untuk spionase, pengenalan suara melalui video dari kamera pengintai, dll. Dan sekarang, para ahli dari Universitas Oxford bersama dengan karyawan Google DeepMind memberi tahu tentang perkembangan mereka sendiri di bidang ini.Jaringan saraf baru dilatih tentang teks sewenang-wenang dari orang yang bertindak di saluran televisi BBC. Menariknya, pelatihan dilakukan secara otomatis, tanpa terlebih dahulu membubuhi keterangan pidato secara manual. Sistem itu sendiri mengenali ucapan, membubuhi keterangan video, menemukan wajah dalam bingkai, dan kemudian belajar menentukan hubungan antara kata (suara) dan gerakan bibir.Sebagai hasilnya, sistem ini secara efektif mengenali teks yang berubah-ubah , dan bukan contoh dari paket kalimat GRID khusus, seperti yang dilakukan LipNet. Kasus GRID memiliki struktur dan kosakata yang sangat terbatas, oleh karena itu, hanya 33.000 kalimat yang mungkin. Dengan demikian, jumlah opsi dikurangi oleh urutan besarnya dan pengakuan disederhanakan.Kasus GRID khusus dibuat sebagai berikut:perintah (4) + warna (4) + preposisi (4) + huruf (25) + digit (10) + kata keterangan (4), dimana angka tersebut sesuai dengan jumlah varian kata untuk masing-masing dari enam kategori verbal.Tidak seperti LipNet, pengembangan DeepMind dan spesialis dari Universitas Oxford bekerja pada aliran pidato arbitrer pada kualitas gambar televisi. Ini jauh lebih seperti sistem nyata, siap untuk penggunaan praktis.AI melatih 5.000 jam video yang direkam dari enam acara televisi saluran televisi BBC Inggris dari Januari 2010 hingga Desember 2015: ini adalah rilis berita reguler (1584 jam), berita pagi (1997 jam), acara Newsnight (590 jam), World News (194) jam), Waktu Pertanyaan (323 jam) dan Dunia Hari Ini (272 jam). Secara total, video berisi 118.116 kalimat ucapan manusia yang berkelanjutan.Setelah itu, program diperiksa pada siaran yang ditayangkan antara Maret dan September 2016.
Kerangka dari empat program di mana program itu dipelajari, serta kata "siang", diucapkan oleh dua pembicara yang berbedaDua minggu lalu, mereka berbicara tentang jaringan saraf LipNet , yang menunjukkan kualitas rekaman 93,4% pengenalan ucapan manusia di bibir. Bahkan kemudian, banyak aplikasi yang seharusnya untuk sistem komputer seperti itu: generasi baru alat bantu dengar medis dengan pengenalan suara, sistem untuk perkuliahan bisu di tempat umum, identifikasi biometrik, sistem untuk transmisi rahasia informasi untuk spionase, pengenalan suara melalui video dari kamera pengintai, dll. Dan sekarang, para ahli dari Universitas Oxford bersama dengan karyawan Google DeepMind memberi tahu tentang perkembangan mereka sendiri di bidang ini.Jaringan saraf baru dilatih tentang teks sewenang-wenang dari orang yang bertindak di saluran televisi BBC. Menariknya, pelatihan dilakukan secara otomatis, tanpa terlebih dahulu membubuhi keterangan pidato secara manual. Sistem itu sendiri mengenali ucapan, membubuhi keterangan video, menemukan wajah dalam bingkai, dan kemudian belajar menentukan hubungan antara kata (suara) dan gerakan bibir.Sebagai hasilnya, sistem ini secara efektif mengenali teks yang berubah-ubah , dan bukan contoh dari paket kalimat GRID khusus, seperti yang dilakukan LipNet. Kasus GRID memiliki struktur dan kosakata yang sangat terbatas, oleh karena itu, hanya 33.000 kalimat yang mungkin. Dengan demikian, jumlah opsi dikurangi oleh urutan besarnya dan pengakuan disederhanakan.Kasus GRID khusus dibuat sebagai berikut:perintah (4) + warna (4) + preposisi (4) + huruf (25) + digit (10) + kata keterangan (4), dimana angka tersebut sesuai dengan jumlah varian kata untuk masing-masing dari enam kategori verbal.Tidak seperti LipNet, pengembangan DeepMind dan spesialis dari Universitas Oxford bekerja pada aliran pidato arbitrer pada kualitas gambar televisi. Ini jauh lebih seperti sistem nyata, siap untuk penggunaan praktis.AI melatih 5.000 jam video yang direkam dari enam acara televisi saluran televisi BBC Inggris dari Januari 2010 hingga Desember 2015: ini adalah rilis berita reguler (1584 jam), berita pagi (1997 jam), acara Newsnight (590 jam), World News (194) jam), Waktu Pertanyaan (323 jam) dan Dunia Hari Ini (272 jam). Secara total, video berisi 118.116 kalimat ucapan manusia yang berkelanjutan.Setelah itu, program diperiksa pada siaran yang ditayangkan antara Maret dan September 2016.Contoh membaca bibir dari layar televisi Program ini menunjukkan kualitas bacaan yang cukup tinggi. Dia dengan benar mengenali kalimat yang sangat kompleks dengan konstruksi tata bahasa yang tidak biasa dan penggunaan nama yang tepat. Contoh kalimat yang dikenal baik:- BANYAK ORANG LEBIH BANYAK YANG TERLIBAT DALAM SERANGAN
- CLOSE TO THE EUROPEAN COMMISSION’S MAIN BUILDING
- WEST WALES AND THE SOUTH WEST AS WELL AS WESTERN SCOTLAND
- WE KNOW THERE WILL BE HUNDREDS OF JOURNALISTS HERE AS WELL
- ACCORDING TO PROVISIONAL FIGURES FROM THE ELECTORAL COMMISSION
- THAT’S THE LOWEST FIGURE FOR EIGHT YEARS
- MANCHESTER FOOTBALL CORRESPONDENT FOR THE DAILY MIRROR
- LAYING THE GROUNDS FOR A POSSIBLE SECOND REFERENDUM
- ACCORDING TO THE LATEST FIGURES FROM THE OFFICE FOR NATIONAL STATISTICS
- IT COMES AFTER A DAMNING REPORT BY THE HEALTH WATCHDOG
AI secara signifikan melebihi efektivitas kerja seseorang, seorang ahli membaca bibir, yang mencoba mengenali 200 klip video acak dari arsip video verifikasi yang direkam.Profesional itu dapat membubuhi keterangan tanpa kesalahan tunggal hanya 12,4% dari kata-kata, sedangkan AI dengan benar mencatat 46,8%. Peneliti mencatat bahwa banyak kesalahan bisa disebut minor. Misalnya, "s" yang hilang di akhir kata. Jika kita mendekati analisis hasil dengan kurang ketat, maka dalam kenyataannya sistem mengakui lebih dari setengah kata-kata yang ada di udara.Dengan hasil ini, DeepMind secara signifikan lebih unggul daripada semua pembaca bibir lainnya, termasuk LipNet yang disebutkan sebelumnya, yang juga dikembangkan di Universitas Oxford. Namun, masih terlalu dini untuk berbicara tentang keunggulan tertinggi, karena LipNet tidak dilatih tentang kumpulan data sebesar itu.Menurut para ahli , DeepMind adalah langkah besar menuju pengembangan sistem membaca bibir sepenuhnya otomatis.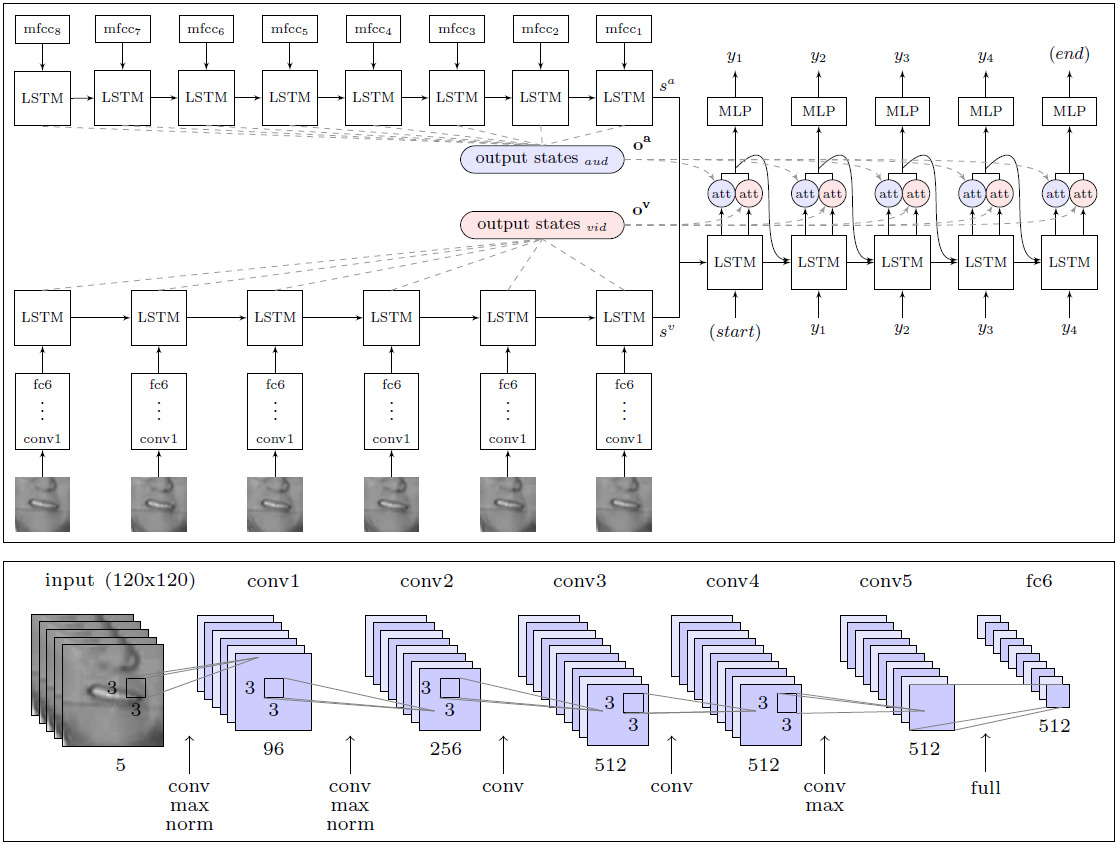 Arsitektur modul WLAS (Watch, Listen, Attend and Eja) dan jaringan saraf convolutional untuk membaca bibirKelebihan besar dari para peneliti terletak pada kenyataan bahwa mereka menyusun kumpulan data raksasa untuk pelatihan dan pengujian sistem dengan 17.500 kata unik. Lagipula, ini bukan hanya lima tahun perekaman berkelanjutan program televisi dalam bahasa Inggris yang baik, tetapi juga sinkronisasi yang jelas antara video dan suara (di TV sering ada sinkronisasi hingga 1 detik, bahkan di televisi bahasa Inggris profesional), serta pengembangan modul untuk pengenalan suara, yang ditumpangkan pada video dan digunakan dalam pengajaran sistem membaca bibir (modul WLAS, lihat diagram di atas).Dalam kasus rassynchronous terkecil, pelatihan sistem menjadi praktis tidak berguna, karena program tidak dapat menentukan korespondensi suara dan pergerakan bibir yang benar. Setelah pekerjaan persiapan menyeluruh, pelatihan program ini sepenuhnya otomatis - program ini memproses 5.000 video secara mandiri.Sebelumnya, set seperti itu tidak ada, oleh karena itu penulis LipNet yang sama terpaksa membatasi diri ke basis GRID. Untuk memuji pengembang DeepMind, mereka berjanji untuk menerbitkan set data dalam domain publik untuk melatih AI lain. Kolega dari tim pengembangan LipNet telah mengatakan mereka menantikannya.Karya ilmiah diterbitkan dalam domain publik di situs web arXiv (arXiv: 1611.05358v1).Jika sistem pembaca bibir komersial muncul di pasaran, maka kehidupan orang awam akan jauh lebih sederhana. Dapat diasumsikan bahwa sistem seperti itu akan segera dibangun ke televisi dan peralatan rumah tangga lainnya untuk meningkatkan kontrol suara dan pengenalan suara yang hampir bebas dari kesalahan.
Arsitektur modul WLAS (Watch, Listen, Attend and Eja) dan jaringan saraf convolutional untuk membaca bibirKelebihan besar dari para peneliti terletak pada kenyataan bahwa mereka menyusun kumpulan data raksasa untuk pelatihan dan pengujian sistem dengan 17.500 kata unik. Lagipula, ini bukan hanya lima tahun perekaman berkelanjutan program televisi dalam bahasa Inggris yang baik, tetapi juga sinkronisasi yang jelas antara video dan suara (di TV sering ada sinkronisasi hingga 1 detik, bahkan di televisi bahasa Inggris profesional), serta pengembangan modul untuk pengenalan suara, yang ditumpangkan pada video dan digunakan dalam pengajaran sistem membaca bibir (modul WLAS, lihat diagram di atas).Dalam kasus rassynchronous terkecil, pelatihan sistem menjadi praktis tidak berguna, karena program tidak dapat menentukan korespondensi suara dan pergerakan bibir yang benar. Setelah pekerjaan persiapan menyeluruh, pelatihan program ini sepenuhnya otomatis - program ini memproses 5.000 video secara mandiri.Sebelumnya, set seperti itu tidak ada, oleh karena itu penulis LipNet yang sama terpaksa membatasi diri ke basis GRID. Untuk memuji pengembang DeepMind, mereka berjanji untuk menerbitkan set data dalam domain publik untuk melatih AI lain. Kolega dari tim pengembangan LipNet telah mengatakan mereka menantikannya.Karya ilmiah diterbitkan dalam domain publik di situs web arXiv (arXiv: 1611.05358v1).Jika sistem pembaca bibir komersial muncul di pasaran, maka kehidupan orang awam akan jauh lebih sederhana. Dapat diasumsikan bahwa sistem seperti itu akan segera dibangun ke televisi dan peralatan rumah tangga lainnya untuk meningkatkan kontrol suara dan pengenalan suara yang hampir bebas dari kesalahan.Source: https://habr.com/ru/post/id399429/
All Articles