Rumor mesin. Jaringan saraf SoundNet dilatih untuk mengenali objek dengan suara
 Kiri: upaya untuk mengenali pemandangan dan objek hanya dengan suara. Kanan: sumber suara nyata.Baru-baru ini, jaringan saraf telah membuat banyak kemajuan dalam pengenalan objek dan adegan dalam video. Pencapaian semacam itu dimungkinkan dengan melatih kumpulan data besar dengan objek bertanda (misalnya, lihat “Mempelajari fitur mendalam untuk pengenalan pemandangan menggunakan basis data tempat” . NIPS, 2014). Dengan melihat foto atau video, komputer hampir dapat secara akurat menentukan adegan dengan memilih satu deskripsi yang sesuai dari 401 adeganmisalnya, dapur berantakan, dapur penuh gaya, kamar tidur remaja, dll. Tetapi di bidang pemahaman suara jaringan saraf belum menunjukkan kemajuan seperti itu. Spesialis dari Laboratorium Teknologi Informasi dan Inteligensi Buatan Massachusetts Institute (CSAIL) memperbaiki kekurangan ini dengan mengembangkan sistem pembelajaran mesin SoundNet .Faktanya, dapat menemukan sebuah adegan dengan suara sama pentingnya dengan mencari sebuah adegan dengan video. Pada akhirnya, gambar dari kamera sering kali buram atau tidak memberikan informasi yang cukup. Tetapi jika mikrofon bekerja, robot sudah dapat mengetahui di mana itu.Dari sudut pandang sains, pelatihan jaringan saraf SoundNet adalah tugas yang cukup dangkal. Karyawan CSAIL menggunakan metode sinkronisasi alami antara penglihatan mesin dan pendengaran mesin, mengajar jaringan saraf untuk secara otomatis mengekstraksi representasi suara suatu objek dari materi video yang tidak teralokasi. Untuk pelatihan, kami menggunakan sekitar 2 juta video Flickr (26 TB data), serta database suara beranotasi - 50 kategori dan sekitar 2000 sampel.
Kiri: upaya untuk mengenali pemandangan dan objek hanya dengan suara. Kanan: sumber suara nyata.Baru-baru ini, jaringan saraf telah membuat banyak kemajuan dalam pengenalan objek dan adegan dalam video. Pencapaian semacam itu dimungkinkan dengan melatih kumpulan data besar dengan objek bertanda (misalnya, lihat “Mempelajari fitur mendalam untuk pengenalan pemandangan menggunakan basis data tempat” . NIPS, 2014). Dengan melihat foto atau video, komputer hampir dapat secara akurat menentukan adegan dengan memilih satu deskripsi yang sesuai dari 401 adeganmisalnya, dapur berantakan, dapur penuh gaya, kamar tidur remaja, dll. Tetapi di bidang pemahaman suara jaringan saraf belum menunjukkan kemajuan seperti itu. Spesialis dari Laboratorium Teknologi Informasi dan Inteligensi Buatan Massachusetts Institute (CSAIL) memperbaiki kekurangan ini dengan mengembangkan sistem pembelajaran mesin SoundNet .Faktanya, dapat menemukan sebuah adegan dengan suara sama pentingnya dengan mencari sebuah adegan dengan video. Pada akhirnya, gambar dari kamera sering kali buram atau tidak memberikan informasi yang cukup. Tetapi jika mikrofon bekerja, robot sudah dapat mengetahui di mana itu.Dari sudut pandang sains, pelatihan jaringan saraf SoundNet adalah tugas yang cukup dangkal. Karyawan CSAIL menggunakan metode sinkronisasi alami antara penglihatan mesin dan pendengaran mesin, mengajar jaringan saraf untuk secara otomatis mengekstraksi representasi suara suatu objek dari materi video yang tidak teralokasi. Untuk pelatihan, kami menggunakan sekitar 2 juta video Flickr (26 TB data), serta database suara beranotasi - 50 kategori dan sekitar 2000 sampel.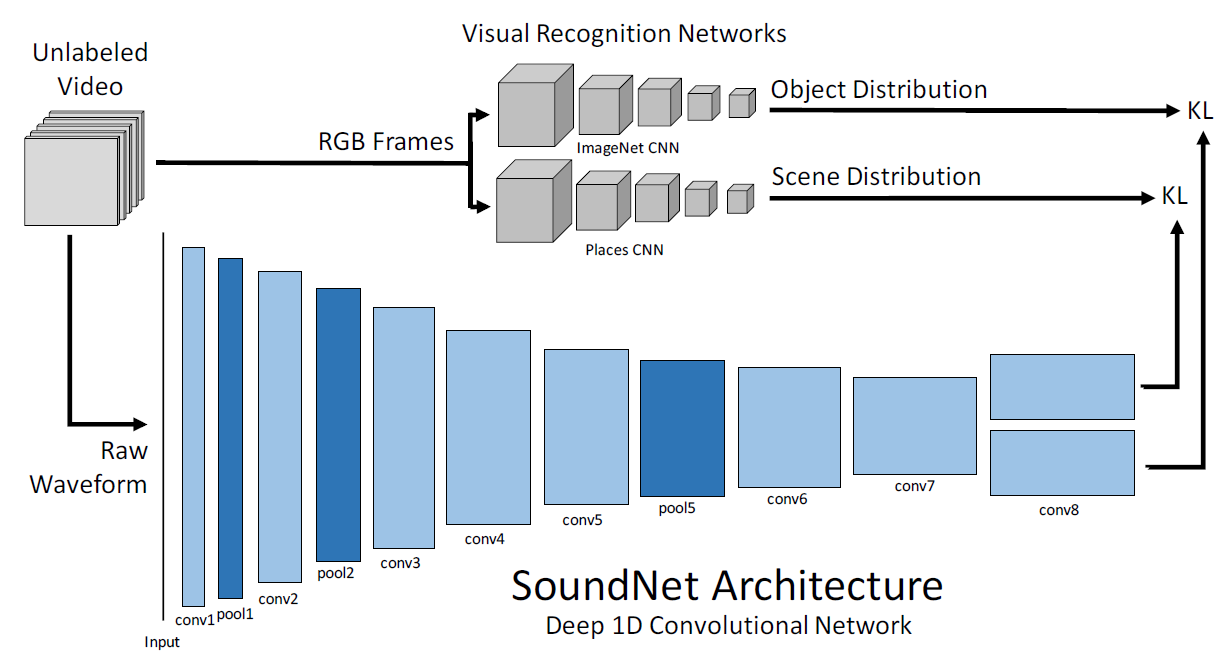 Arsitektur Jaringan Saraf SoundNetMeskipun pelatihan jaringan saraf berlangsung di bawah pengamatan visual, sistem memberikan hasil yang sangat baik dalam mode yang berdiri sendiri sesuai dengan klasifikasi setidaknya tiga adegan akustik standar, yang menurutnya para pengembang memeriksanya. Selain itu, tes jaringan saraf menunjukkan bahwa ia secara mandiri belajar mengenali karakteristik suara dari beberapa adegan, dan pengembang tidak memberikan sampel untuk mengenali objek-objek ini secara khusus. Berdasarkan pada dasar materi video yang tidak terisi, jaringan saraf itu sendiri belajar adegan mana yang sesuai dengan suara kerumunan gembira (ini adalah stadion) dan twitter burung (ini adalah halaman atau taman). Bersamaan dengan adegan itu, jaringan saraf mengenali objek tertentu, yang merupakan sumber suara.Video menunjukkan beberapa contoh mengenali objek dengan suara. Pada awalnya, suara terdengar dan hasil pengenalan ditampilkan, dan gambar itu sendiri kabur - sehingga Anda dapat mencoba memeriksa diri Anda sendiri. Apakah Anda dapat memahami tempat tindakan dan keberadaan benda-benda tertentu hanya dengan suara seakurat jaringan saraf. Misalnya, apa yang paling mungkin artinya dari lagu "Happy Birthday To You!", Yang dinyanyikan oleh beberapa orang secara bersamaan? Jawaban yang benar: benda itu membakar lilin , pemandangannya adalah restoran, kafe, bar ."Visi mesin telah mulai bekerja dengan sangat baik sehingga kami dapat mentransfer teknologi ini ke area lain," kata Carl Vondrick, seorang mahasiswa di Institut Teknologi Massachusetts di bidang Teknik Listrik dan Ilmu Komputer, salah satu penulis karya ilmiah. - Kami menggunakan hubungan alami antara penglihatan komputer dan suara. Itu mungkin untuk mencapai skala besar karena banyaknya materi video yang tidak berlabel, sehingga jaringan saraf telah belajar untuk memahami suara. "Pengujian SoundNet dilakukan pada dua database standar rekaman suara, dan itu menunjukkan akurasi 13-15% lebih tinggi dari pengenalan objek daripada yang terbaik dari program tersebut. Pada kumpulan data dengan 10 kategori suara yang berbeda, SoundNet mengklasifikasikan suara dengan akurasi 92%, dan pada kumpulan data dengan 50 kategori itu menunjukkan akurasi 74%. Sebagai perbandingan, pada dataset yang sama, orang menunjukkan akurasi pengenalan, rata-rata, 96% dan 81%.
Arsitektur Jaringan Saraf SoundNetMeskipun pelatihan jaringan saraf berlangsung di bawah pengamatan visual, sistem memberikan hasil yang sangat baik dalam mode yang berdiri sendiri sesuai dengan klasifikasi setidaknya tiga adegan akustik standar, yang menurutnya para pengembang memeriksanya. Selain itu, tes jaringan saraf menunjukkan bahwa ia secara mandiri belajar mengenali karakteristik suara dari beberapa adegan, dan pengembang tidak memberikan sampel untuk mengenali objek-objek ini secara khusus. Berdasarkan pada dasar materi video yang tidak terisi, jaringan saraf itu sendiri belajar adegan mana yang sesuai dengan suara kerumunan gembira (ini adalah stadion) dan twitter burung (ini adalah halaman atau taman). Bersamaan dengan adegan itu, jaringan saraf mengenali objek tertentu, yang merupakan sumber suara.Video menunjukkan beberapa contoh mengenali objek dengan suara. Pada awalnya, suara terdengar dan hasil pengenalan ditampilkan, dan gambar itu sendiri kabur - sehingga Anda dapat mencoba memeriksa diri Anda sendiri. Apakah Anda dapat memahami tempat tindakan dan keberadaan benda-benda tertentu hanya dengan suara seakurat jaringan saraf. Misalnya, apa yang paling mungkin artinya dari lagu "Happy Birthday To You!", Yang dinyanyikan oleh beberapa orang secara bersamaan? Jawaban yang benar: benda itu membakar lilin , pemandangannya adalah restoran, kafe, bar ."Visi mesin telah mulai bekerja dengan sangat baik sehingga kami dapat mentransfer teknologi ini ke area lain," kata Carl Vondrick, seorang mahasiswa di Institut Teknologi Massachusetts di bidang Teknik Listrik dan Ilmu Komputer, salah satu penulis karya ilmiah. - Kami menggunakan hubungan alami antara penglihatan komputer dan suara. Itu mungkin untuk mencapai skala besar karena banyaknya materi video yang tidak berlabel, sehingga jaringan saraf telah belajar untuk memahami suara. "Pengujian SoundNet dilakukan pada dua database standar rekaman suara, dan itu menunjukkan akurasi 13-15% lebih tinggi dari pengenalan objek daripada yang terbaik dari program tersebut. Pada kumpulan data dengan 10 kategori suara yang berbeda, SoundNet mengklasifikasikan suara dengan akurasi 92%, dan pada kumpulan data dengan 50 kategori itu menunjukkan akurasi 74%. Sebagai perbandingan, pada dataset yang sama, orang menunjukkan akurasi pengenalan, rata-rata, 96% dan 81%.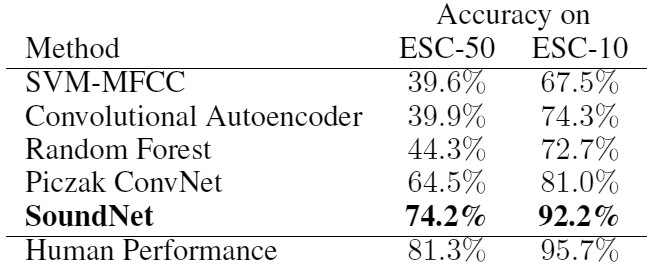 Bahkan orang terkadang tidak dapat menentukan dengan tepat apa yang mereka dengar. Coba lakukan eksperimen sendiri. Biarkan kolega memulai video sewenang-wenang dari YouTube - dan Anda mencoba untuk tidak melihat monitor untuk mengatakan apa yang terjadi, dari mana suara berasal dan apa yang ditampilkan di layar. Jauh dari biasanya Anda bisa menebak. Jadi tugas untuk kecerdasan buatan sebenarnya tidak mudah, tetapi SoundNet berhasil mengatasinya dengan cukup baik.Di masa depan, program komputer semacam itu mungkin menemukan aplikasi praktis. Misalnya, ponsel Anda akan secara otomatis mengenali bahwa Anda telah memasuki tempat umum - bioskop atau teater, dan secara otomatis membisukan volume dering. Jika film dimulai dan penonton menjadi tenang, telepon akan secara otomatis mematikan suara dan menghidupkan sinyal getar.Orientasi dengan terrain oleh suara akan membantu dalam mengendalikan program untuk robot otonom dan mesin lainnya.Dalam sistem keamanan dan rumah pintar, sistem dapat secara khusus merespons suara tertentu dengan cara tertentu. Misalnya, bunyi jendela yang pecah. Di "kota pintar" di masa depan, pengenalan jalan akan membantu memahami penyebabnya dan menangani polusi suara.Artikel ilmiah ini diterbitkan pada 27 Oktober 2016 di domain publik di arXiv.org (arXiv: 1610.09001, pdf ).
Bahkan orang terkadang tidak dapat menentukan dengan tepat apa yang mereka dengar. Coba lakukan eksperimen sendiri. Biarkan kolega memulai video sewenang-wenang dari YouTube - dan Anda mencoba untuk tidak melihat monitor untuk mengatakan apa yang terjadi, dari mana suara berasal dan apa yang ditampilkan di layar. Jauh dari biasanya Anda bisa menebak. Jadi tugas untuk kecerdasan buatan sebenarnya tidak mudah, tetapi SoundNet berhasil mengatasinya dengan cukup baik.Di masa depan, program komputer semacam itu mungkin menemukan aplikasi praktis. Misalnya, ponsel Anda akan secara otomatis mengenali bahwa Anda telah memasuki tempat umum - bioskop atau teater, dan secara otomatis membisukan volume dering. Jika film dimulai dan penonton menjadi tenang, telepon akan secara otomatis mematikan suara dan menghidupkan sinyal getar.Orientasi dengan terrain oleh suara akan membantu dalam mengendalikan program untuk robot otonom dan mesin lainnya.Dalam sistem keamanan dan rumah pintar, sistem dapat secara khusus merespons suara tertentu dengan cara tertentu. Misalnya, bunyi jendela yang pecah. Di "kota pintar" di masa depan, pengenalan jalan akan membantu memahami penyebabnya dan menangani polusi suara.Artikel ilmiah ini diterbitkan pada 27 Oktober 2016 di domain publik di arXiv.org (arXiv: 1610.09001, pdf ).Source: https://habr.com/ru/post/id399659/
All Articles