Terakhir kali [
Mengunduh data dari situs data terbuka, data.gov.ru ] Saya berhasil mempelajari cara mengunduh data dari portal data terbuka Rusia dengan beberapa masalah. Portal data terbuka harus menyediakan informasi yang paling relevan tentang data terbuka otoritas federal, otoritas regional, dan organisasi lain (kutipan dari data.gov.ru). Mari kita lihat data apa di portal, seberapa relevan mereka dan dalam bentuk apa mereka ditempatkan.
Diagram pie di bawah ini menunjukkan distribusi set data berdasarkan kategori.
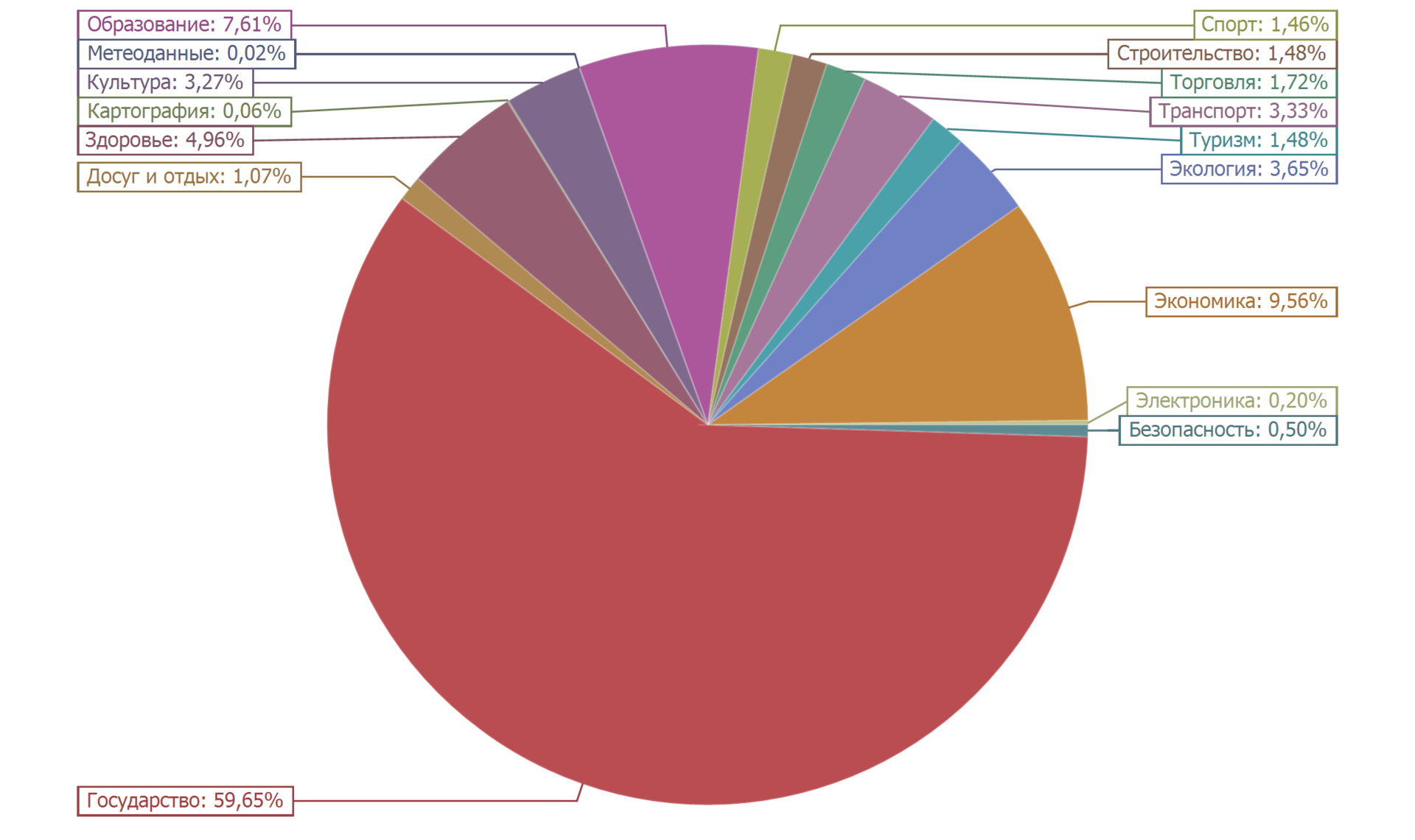
Lebih dari setengah dari set data (59,65%) termasuk kategori "Negara". Sekitar sepuluh persen (9,56%) termasuk dalam kategori "Ekonomi". Hampir sepuluh persen (7,61%) adalah jumlah set data dalam kategori Pendidikan. Sisanya kurang dari lima persen. Distribusi sangat alami.
Kami akan memperluas kenalan kami dengan data yang diposting di portal. Mari kita lihat statistik penempatan di portal data berdasarkan tanggal publikasi pertama dari kumpulan data.
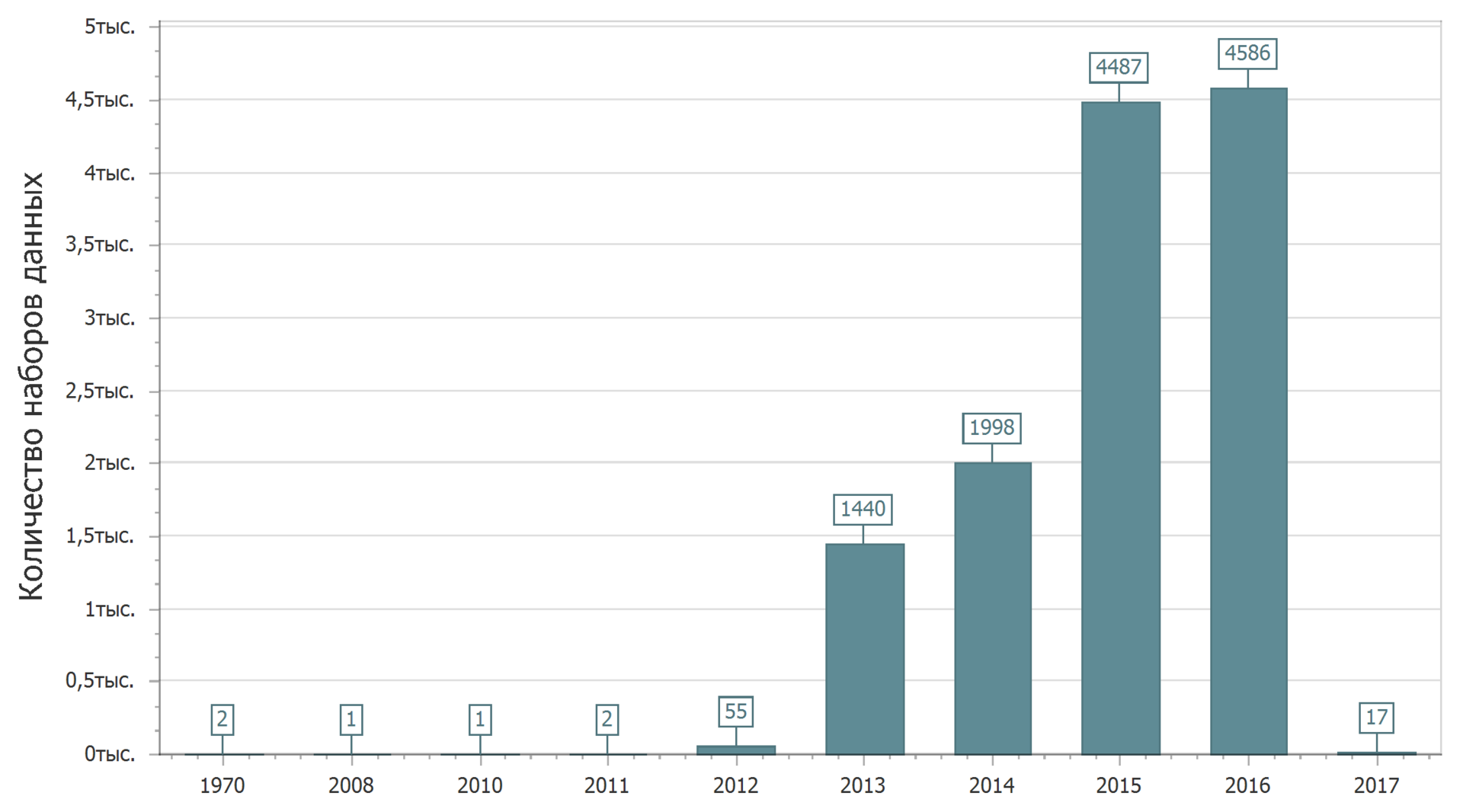
2017 baru saja dimulai, dan itu wajar bahwa jumlah data yang diposting pada 2017 akan meningkat. Ya, ketika saya menulis teks, set data baru diunggah ke portal.
Rupanya, seseorang berhasil kembali ke masa lalu, setelah berhasil menempatkan data pada tahun 1970 yang jauh.
Secara umum, gambarannya jelas: pertama, pertumbuhan tajam, lalu stabilitas. Meskipun mungkin terlalu dini untuk berbicara tentang stabilitas.
Gambaran yang menarik dapat dilihat jika kita mempertimbangkan distribusi set data berdasarkan tanggal relevansi (tanggal setelah versi set data saat ini harus diperbarui).
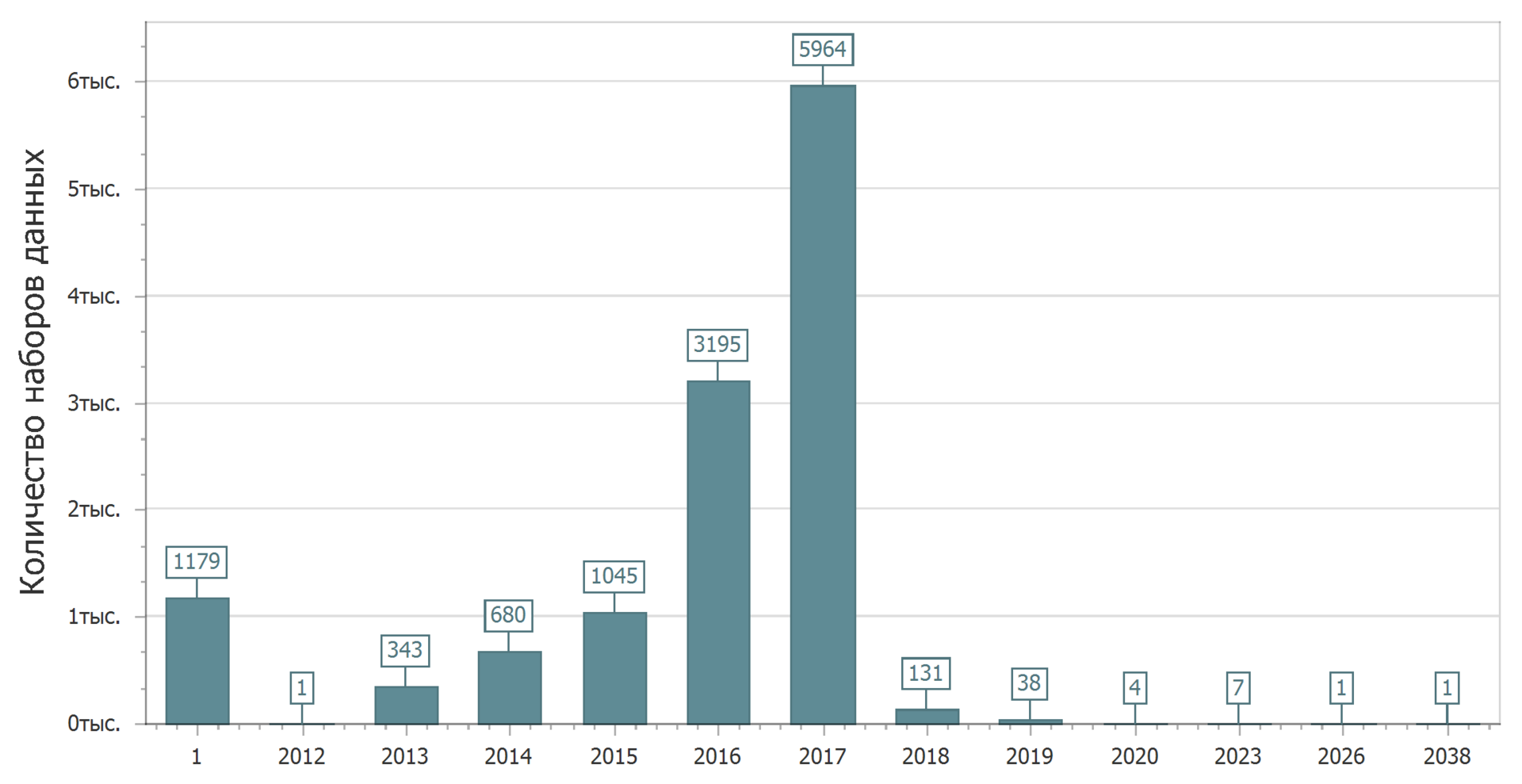
Segera bergegas 1 tahun. Jadi, saya menetapkan set data yang tidak memiliki tanggal terbaru. Berdasarkan penentuan tanggal relevansi, kita dapat menyimpulkan bahwa ini adalah kumpulan data yang tidak perlu diperbarui sama sekali. Secara alami, set data tersebut memiliki hak untuk ada. Selalu ada data arsip (historis) yang tidak mungkin berubah (yah, jika tidak ada kesalahan di dalamnya), dan ada data saat ini - saat ini yang terus berubah. Baik itu dan yang lain mungkin menarik. Lagi pula, kebetulan Anda perlu mencari tahu: bagaimana itu ada di masa lalu (di bawah tsar atau di bawah rezim Soviet)? Tapi, tentu saja, data aktual (langsung) yang terus diperbarui lebih menarik.
Bahkan jika Anda tidak mempertimbangkan grafik dengan sangat hati-hati, jelas bahwa beberapa data harus diperbarui dalam waktu yang agak lama. Kita dapat mengatakan bahwa mereka yang mempostingnya memiliki kepercayaan diri yang luar biasa terhadap masa depan. Lima, sepuluh, dua puluh (?) Tahun ke depan mereka tidak akan mengubah apa pun. Atau mungkin itu hanya kesalahan? Dan itu mungkin.
Tapi secara umum, gambarnya cukup bahagia - hampir setengah dari data berencana diperbarui tahun ini.
Dan sekarang kita akan mengkonfirmasi gambaran yang menyenangkan ini. Pertimbangkan distribusi set data pada tanggal perubahan terakhir.
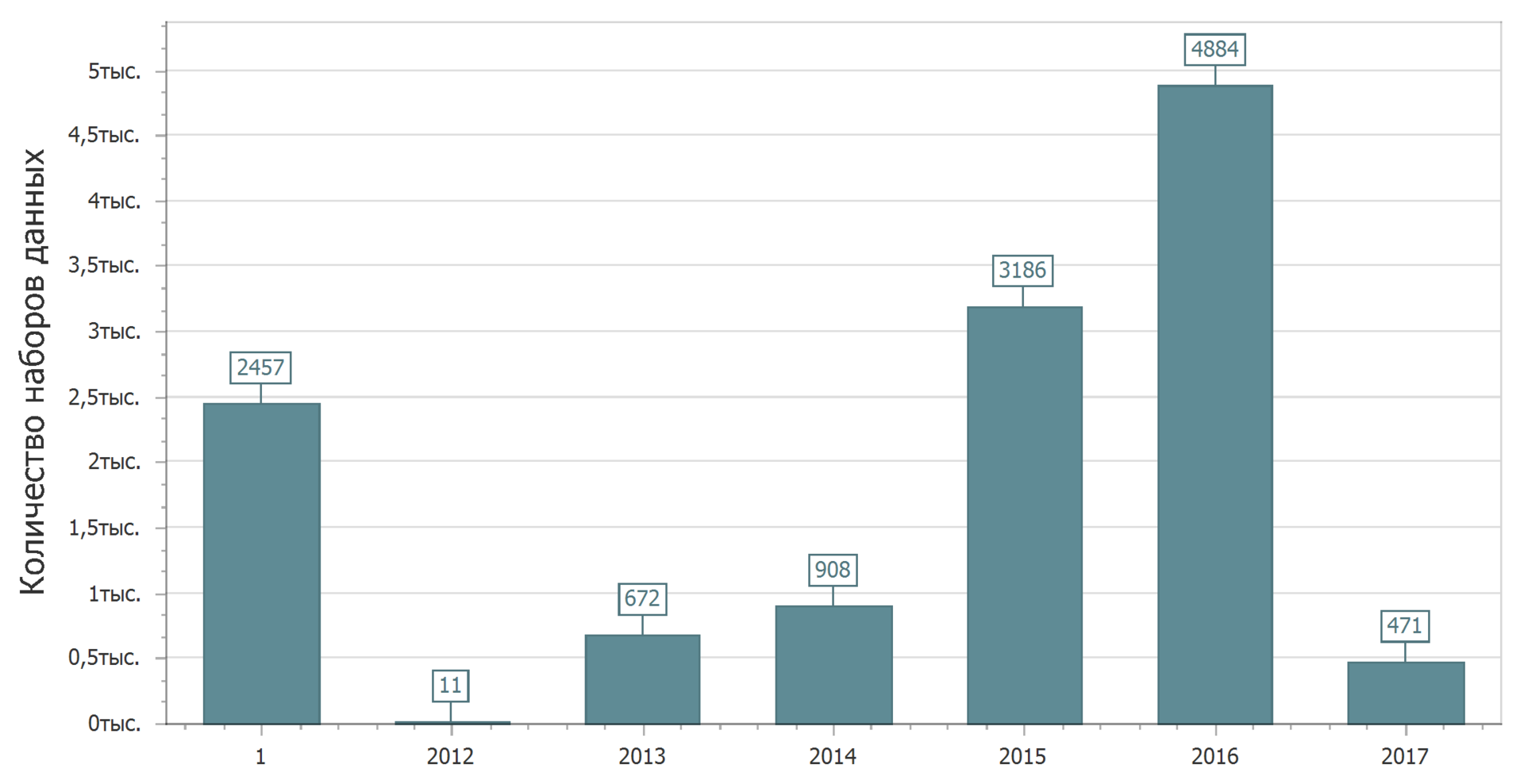
Ya Lagi 1 tahun. Kumpulan data ini belum dimodifikasi. Saya hanya ingin menangkap seseorang. Seperti, mereka berjanji untuk memperbarui, tetapi tidak melakukan perubahan. Atau mereka tidak berjanji untuk memperbarui dan memperbarui. Tetapi lain kali kita akan mencari pola (atau ketiadaan).
Gabungkan informasi tentang publikasi pertama dan pembaruan terakhir. Yaitu, jika ada pembaruan - ambil tanggal pembaruan, jika tidak ada pembaruan - ambil tanggal publikasi pertama. Hasilnya adalah tanggal perubahan data terakhir.

Kecantikan Tren ini terlihat jelas - lebih dari setengah data terakhir diubah atau dibuat pada 2016-2017. Mungkin Anda dapat menganggapnya relevan.
Perlu dicatat satu peringatan. Beberapa set data diulang: nama dan pemilik data yang sama ditemukan beberapa kali dalam registri.
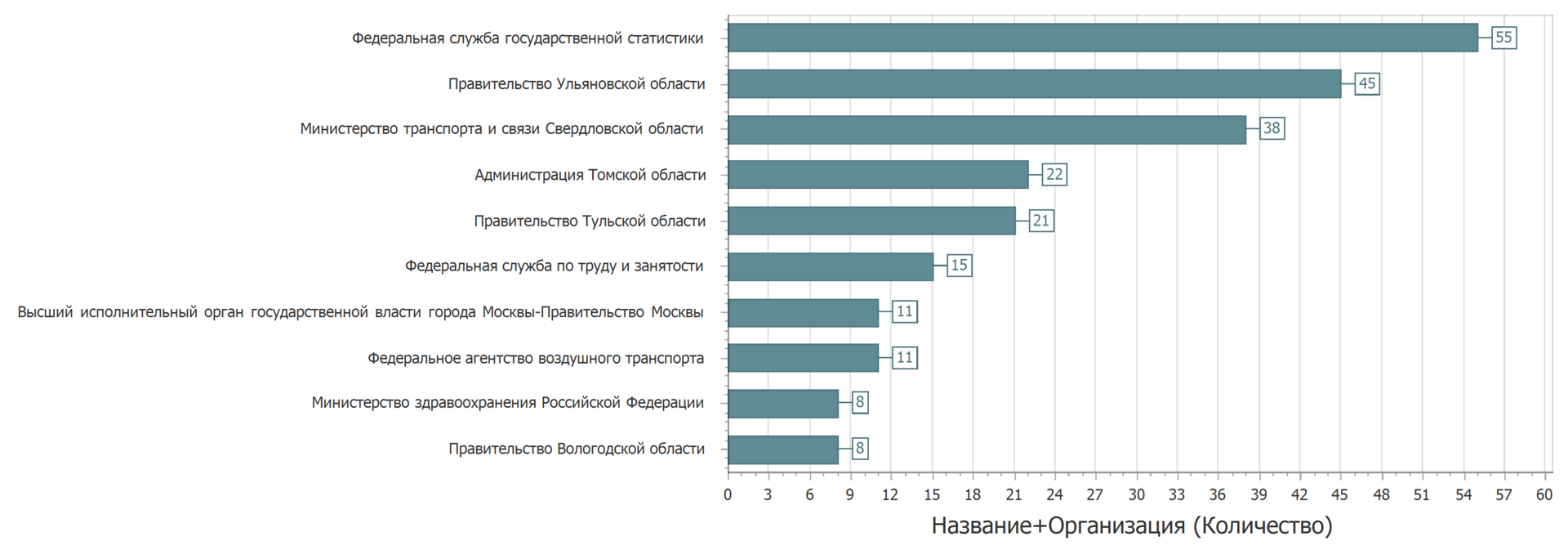
Alih-alih memperbarui, set data ditata kembali. Terkadang set diletakkan dalam kategori yang berbeda. Tetapi jika Anda melihat kumpulan data dengan nama, pemilik, dan kategori yang sama, maka gambarnya adalah sebagai berikut.
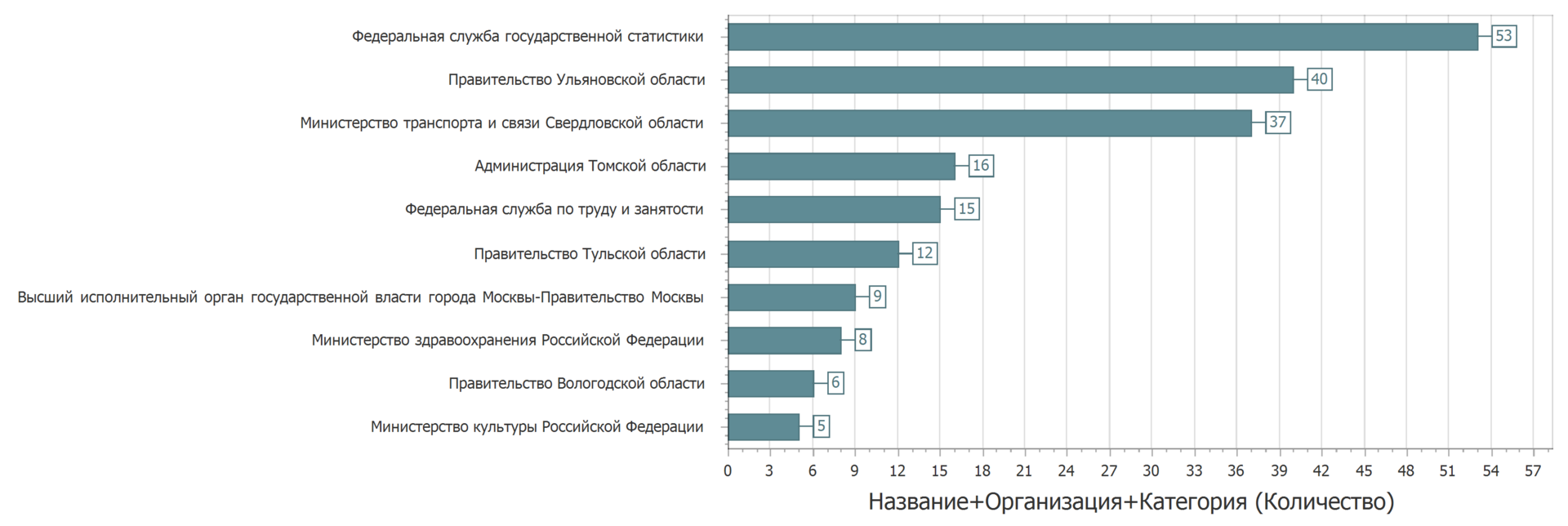
Setidaknya sangat mirip. Tapi hampir tidak kritis. Beberapa pemilik data, tampaknya, perlu menyebarkan data dengan cermat.
Pemeriksaan kecil tentang mengisi bidang teks dalam set data paspor.
| Lapangan | Ditetapkan oleh | Tidak diatur |
|---|
| Judul | 100% | 0% |
| Deskripsi | 80,84% | 19,16% |
| Kategori | 100% | 0% |
| Pemilik | 99,7% | 0,03% |
| Kata kunci | 99,48% | 0,52% |
| Orang yang bertanggung jawab | 96,43% | 3,57% |
| Nomor Telepon Orang yang Bertanggung Jawab | 96% | 4% |
| Email Orang yang Bertanggung Jawab | 92,68% | 7,32% |
| Format data | 97,79% | 2,21% |
| Tautan Panggil | 96,86% | 3,14% |
Nama dan kategori didefinisikan di mana-mana. Hampir seperlima dari kumpulan data tidak berisi deskripsi. Hampir di mana-mana pemiliknya dikenal dan beberapa kata kunci ditetapkan. Orang yang bertanggung jawab juga hadir hampir di mana-mana. Tidak jelas mengapa kita membutuhkan kumpulan data yang tidak dapat diunduh (sekitar 3%).
Sebagai hasilnya, kami membagi semua set data menjadi dua kategori: semua bidang ditentukan, setidaknya satu bidang tidak ditentukan.

Tiga puluh persen (30,3%) memiliki setidaknya satu bidang yang tidak ditentukan. Dalam format apa data diunggah?
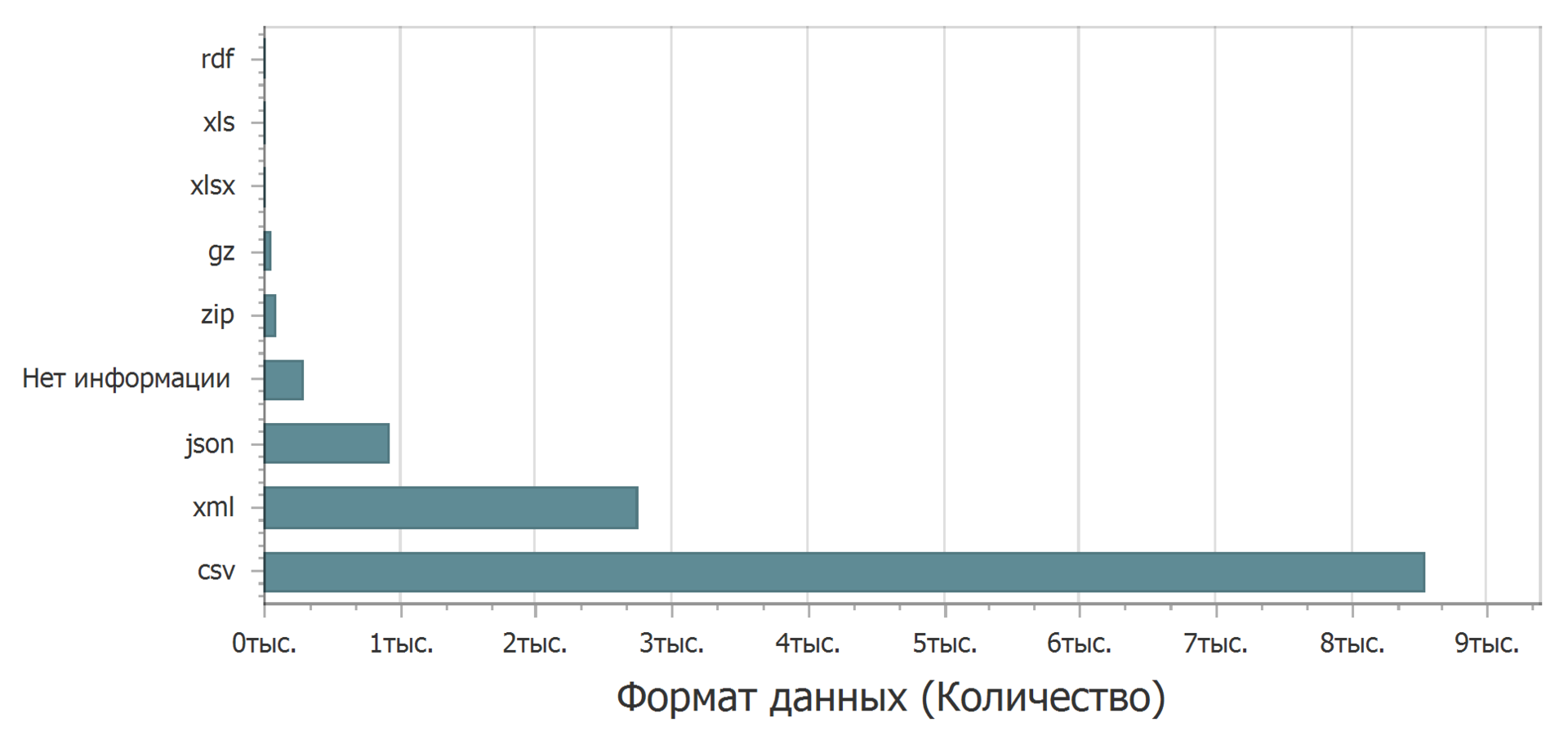
Sebagian besar dalam format teks terbatas polos (csv). Di tempat kedua adalah xml. Di json ketiga. Pemimpin yang jelas adalah format csv - Anda dapat membukanya di editor teks apa pun, mengimpornya hampir di mana saja untuk diproses, dan dengan sedikit upaya menempelkannya ke editor teks sebagai sebuah tabel. Format xml juga cukup mudah dilihat. Tetapi dengan format json mungkin ada masalah. Jika Anda fokus pada Excel, sebagai editor spreadsheet yang paling umum digunakan, maka json sudah menjadi masalah. Anda dapat google pada topik ini dan menemukan cara untuk mengunduh, tetapi tidak mengarahkan. Excel tidak memiliki alat bawaan untuk memuat json.
Tentu saja, masalahnya adalah tanpa rasa takut, tidak fatal, tetapi tidak menyenangkan. Tentunya, format ini akan menghentikan atau membingungkan seseorang.
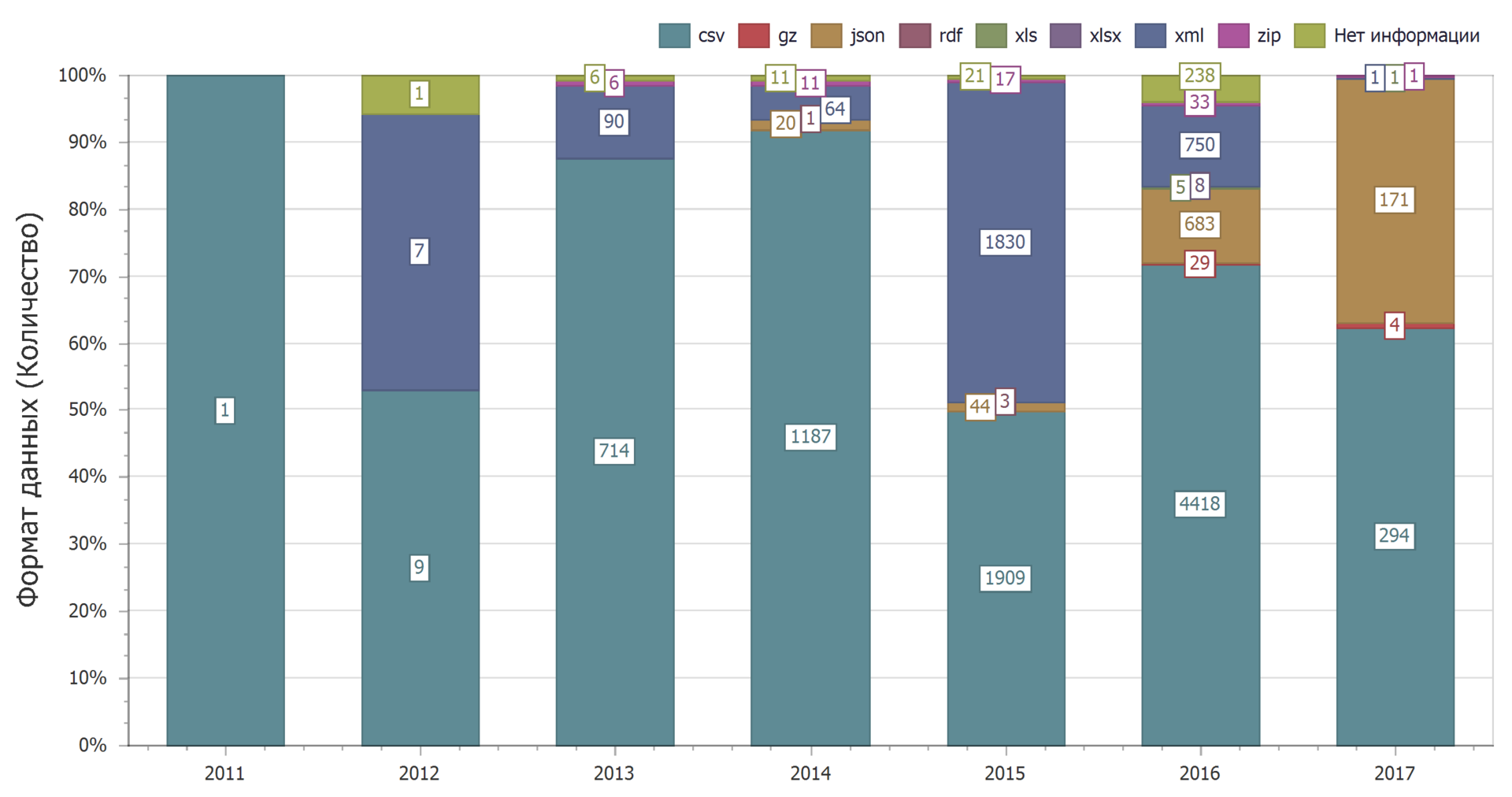
Distribusi berdasarkan tahun menunjukkan bahwa seiring berjalannya waktu, dominasi format csv tetap ada.

Penggunaan format json akan meningkat secara dramatis. Ini mengurangi penggunaan format xml.
Dan ini bisa dijelaskan. Format csv adalah yang paling sederhana, sehingga sering digunakan. Pada saat yang sama, layanan web sekarang semakin menggunakan format json dan semakin sedikit xml.
Kesimpulan
Lebih dari setengah data yang diposting di portal data terbuka Rusia termasuk dalam kategori “Negara”.
Lebih dari setengah data terakhir diubah atau dibuat pada 2016-2017.
Tiga puluh persen paspor dataset memiliki setidaknya satu bidang yang belum ditetapkan.
Format paling umum untuk menyimpan data terbuka: csv, xml, json. Pada saat yang sama, ada peningkatan jumlah set data dalam format json dan penurunan jumlah set data dalam format xml.
Apa selanjutnya
Setelah menganalisis kumpulan data, mari kita lihat seberapa sering mereka digunakan - dilihat, diunduh. Peringkat apa yang ditetapkan pengguna untuk set data? Kumpulan data apa yang menarik? Seberapa sering dataset diperbarui? Apa ukuran dataset? Dan adakah hubungan antara semua ini?