
Saat ini, grafik adalah salah satu cara yang paling dapat diterima untuk menggambarkan model yang dibuat dalam sistem pembelajaran mesin. Grafik komputasi ini terdiri dari simpul neuron yang dihubungkan oleh tepi sinaps yang menggambarkan hubungan antar simpul.
Tidak seperti prosesor grafis skalar pusat atau vektor, IPU - jenis prosesor baru yang dirancang untuk pembelajaran mesin, memungkinkan Anda membuat grafik seperti itu. Komputer yang dirancang untuk manajemen grafik adalah mesin yang ideal untuk model grafik komputasi yang dibuat sebagai bagian dari pembelajaran mesin.
Salah satu cara termudah untuk menggambarkan cara kerja kecerdasan mesin adalah memvisualisasikannya. Tim pengembang Graphcore telah membuat koleksi gambar-gambar ini yang ditampilkan di IPU. Dasarnya adalah perangkat lunak Poplar, yang memvisualisasikan karya kecerdasan buatan. Para peneliti dari perusahaan ini juga menemukan mengapa jaringan yang dalam membutuhkan begitu banyak memori, dan solusi apa yang ada.
Poplar menyertakan kompiler grafis yang dibuat dari awal untuk menerjemahkan operasi standar yang digunakan sebagai bagian dari pembelajaran mesin ke dalam kode aplikasi yang sangat dioptimalkan untuk IPU. Ini memungkinkan Anda untuk mengumpulkan grafik-grafik ini bersama-sama dengan prinsip yang sama dengan POPNN dirakit. Perpustakaan berisi satu set berbagai jenis simpul untuk primitif umum.
Grafik adalah paradigma yang menjadi dasar semua perangkat lunak. Di Poplar, grafik memungkinkan Anda untuk menentukan proses perhitungan, di mana simpul melakukan operasi dan tepi menggambarkan hubungan di antara mereka. Misalnya, jika Anda ingin menambahkan dua angka bersama-sama, Anda dapat menentukan titik dengan dua input (angka yang ingin Anda tambahkan), beberapa perhitungan (fungsi menambahkan dua angka) dan output (hasil).
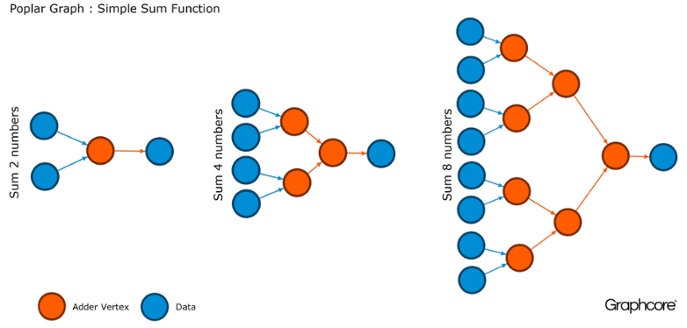
Biasanya, operasi vertex jauh lebih rumit daripada dalam contoh yang dijelaskan di atas. Seringkali mereka didefinisikan oleh program kecil yang disebut codelets (nama kode). Abstraksi grafis menarik karena tidak membuat asumsi tentang struktur komputasi dan memecah komputasi menjadi komponen yang dapat digunakan prosesor IPU untuk bekerja.
Poplar menggunakan abstraksi sederhana ini untuk membuat grafik yang sangat besar yang direpresentasikan sebagai gambar. Pembuatan grafik secara terprogram berarti bahwa kita dapat menyesuaikannya dengan perhitungan spesifik yang diperlukan untuk memastikan penggunaan sumber daya IPU yang paling efisien.
Kompiler menerjemahkan operasi standar yang digunakan dalam sistem pembelajaran mesin ke dalam kode aplikasi yang sangat dioptimalkan untuk IPU. Kompiler grafik membuat gambar perantara dari grafik komputasi yang digunakan pada satu atau lebih perangkat IPU. Compiler dapat menampilkan grafik komputasi ini, sehingga aplikasi yang ditulis pada tingkat struktur jaringan saraf menampilkan gambar dari grafik komputasi yang berjalan pada IPU.
 Grafik pembelajaran siklus penuh AlexNet maju dan mundur
Grafik pembelajaran siklus penuh AlexNet maju dan mundurKompiler grafis Poplar mengubah deskripsi
AlexNet menjadi grafik komputasi 18,7 juta simpul dan 115,8 juta tepi. Pengelompokan yang terlihat jelas adalah hasil dari koneksi yang kuat antara proses di setiap lapisan jaringan dengan koneksi yang lebih mudah antar level.
Contoh lain adalah jaringan sederhana dengan konektivitas penuh, dilatih di
MNIST - dataset sederhana untuk visi komputer, semacam "Halo, dunia" dalam pembelajaran mesin. Jaringan sederhana untuk mengeksplorasi dataset ini membantu untuk memahami grafik yang dikendalikan oleh aplikasi Poplar. Dengan mengintegrasikan pustaka grafik dengan lingkungan seperti TensorFlow, perusahaan menyediakan salah satu cara termudah untuk menggunakan IPU dalam aplikasi pembelajaran mesin.
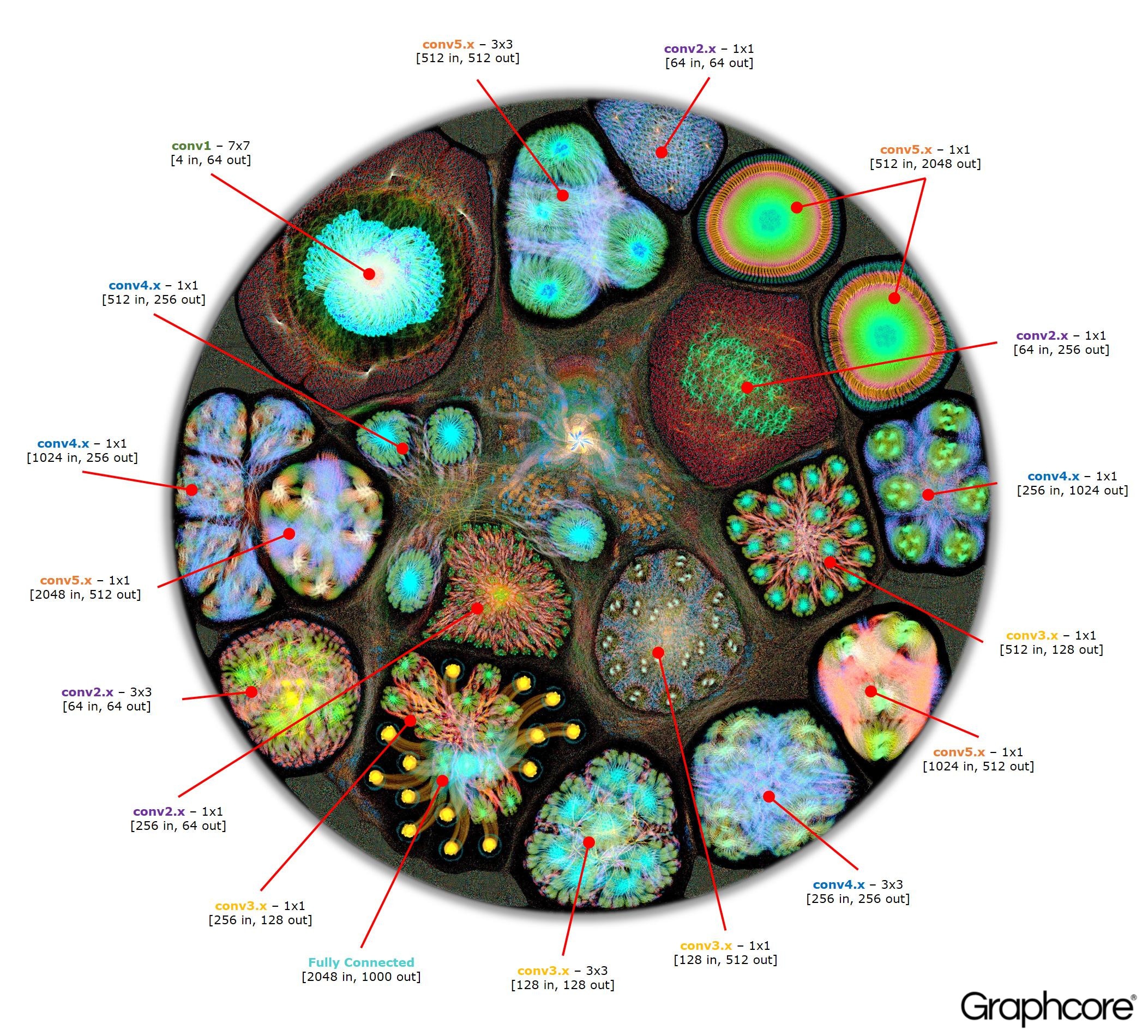
Setelah grafik dibangun menggunakan kompiler, itu perlu dieksekusi. Ini dimungkinkan menggunakan Graph Engine. Menggunakan ResNet-50 sebagai contoh, operasinya diperagakan.
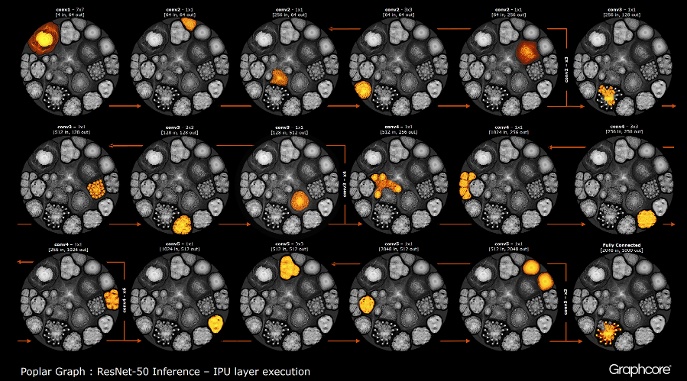 Hitung ResNet-50
Hitung ResNet-50Arsitektur ResNet-50 memungkinkan Anda membuat jaringan yang dalam dari pengulangan partisi. Prosesor hanya perlu menentukan partisi ini sekali dan memanggilnya kembali. Sebagai contoh, klaster level conv4 dijalankan enam kali, tetapi hanya sekali diterapkan pada grafik. Gambar juga menunjukkan berbagai bentuk lapisan konvolusional, karena masing-masing memiliki grafik yang dibangun sesuai dengan bentuk alami perhitungan.
Mesin membuat dan mengontrol pelaksanaan model pembelajaran mesin menggunakan grafik yang dibuat oleh kompiler. Setelah digunakan, Graph Engine memonitor dan merespons IPU atau perangkat yang digunakan oleh aplikasi.
Gambar ResNet-50 menunjukkan keseluruhan model. Pada tingkat ini, sulit untuk membedakan antara masing-masing simpul, jadi Anda harus melihat gambar yang diperbesar. Berikut ini adalah beberapa contoh bagian dalam lapisan jaringan saraf.


Mengapa jaringan yang dalam membutuhkan begitu banyak memori?
Sejumlah besar memori yang ditempati adalah salah satu masalah terbesar dari jaringan saraf yang dalam. Para peneliti sedang mencoba untuk berurusan dengan bandwidth terbatas perangkat DRAM, yang harus digunakan oleh sistem modern untuk menyimpan sejumlah besar bobot dan aktivasi dalam jaringan saraf yang dalam.
Arsitektur dikembangkan menggunakan chip prosesor yang dirancang untuk pemrosesan sekuensial dan optimalisasi DRAM untuk memori kepadatan tinggi. Antarmuka antara kedua perangkat adalah hambatan yang memperkenalkan batasan bandwidth dan menambah biaya konsumsi energi yang signifikan.
Meskipun kita masih belum memiliki gambaran lengkap tentang otak manusia dan cara kerjanya, secara umum jelas bahwa tidak ada fasilitas penyimpanan terpisah yang besar untuk memori. Dipercayai bahwa fungsi memori jangka panjang dan jangka pendek di otak manusia tertanam dalam struktur neuron + sinapsis. Bahkan organisme sederhana seperti
cacing dengan struktur saraf otak, yang terdiri dari lebih dari 300 neuron,
memiliki beberapa tingkat fungsi memori.
Membangun memori dalam prosesor konvensional adalah salah satu cara untuk mengatasi kemacetan memori dengan membuka bandwidth besar dengan konsumsi daya yang jauh lebih sedikit. Namun demikian, memori pada sebuah chip adalah hal yang mahal yang tidak dirancang untuk jumlah memori yang sangat besar, yang terhubung ke prosesor pusat dan grafis yang saat ini digunakan untuk persiapan dan penyebaran jaringan saraf yang dalam.
Oleh karena itu, penting untuk melihat bagaimana memori digunakan saat ini di unit pemrosesan terpusat dan sistem pembelajaran mendalam pada akselerator grafis, dan tanyakan pada diri sendiri: mengapa mereka membutuhkan perangkat penyimpanan memori yang begitu besar ketika otak manusia bekerja dengan baik tanpa mereka?
Jaringan saraf memerlukan memori untuk menyimpan data input, parameter bobot dan fungsi aktivasi, karena input didistribusikan melalui jaringan. Dalam pelatihan, aktivasi pada input harus dipertahankan hingga dapat digunakan untuk menghitung kesalahan gradien pada output.
Sebagai contoh, jaringan ResNet 50-lapis memiliki sekitar 26 juta parameter bobot dan menghitung 16 juta aktivasi ke depan. Jika Anda menggunakan angka floating-point 32-bit untuk menyimpan setiap bobot dan aktivasi, maka ini membutuhkan ruang sekitar 168 MB. Menggunakan nilai akurasi yang lebih rendah untuk menyimpan skala dan aktivasi ini, kami dapat membagi dua atau bahkan empat kali lipat persyaratan penyimpanan ini.
Masalah memori serius muncul dari kenyataan bahwa GPU bergantung pada data yang direpresentasikan sebagai vektor padat. Oleh karena itu, mereka dapat menggunakan aliran instruksi tunggal (SIMD) untuk mencapai komputasi kepadatan tinggi. Prosesor sentral menggunakan blok vektor serupa untuk komputasi kinerja tinggi.
Dalam GPU, sinapsinya memiliki lebar 1024 bit, sehingga mereka menggunakan data floating point 32-bit, sehingga mereka sering memecahnya menjadi batch mini paralel dari 32 sampel untuk membuat vektor data 1024-bit. Pendekatan untuk mengatur paralelisme vektor ini meningkatkan jumlah aktivasi sebanyak 32 kali dan kebutuhan penyimpanan lokal dengan kapasitas lebih dari 2 GB.
GPU dan mesin lain yang dirancang untuk aljabar matriks juga dikenakan beban memori dari bobot atau aktivasi jaringan saraf. GPU tidak dapat secara efisien melakukan konvolusi kecil yang digunakan dalam jaringan saraf yang dalam. Oleh karena itu, transformasi yang disebut "downgrade" digunakan untuk mengubah konvolusi ini menjadi multiplikasi matriks-matriks (GEMM), yang dapat ditangani oleh akselerator grafis secara efektif.
Memori tambahan juga diperlukan untuk menyimpan data input, nilai waktu, dan instruksi program. Mengukur penggunaan memori saat melatih ResNet-50 pada GPU berkinerja tinggi telah menunjukkan bahwa membutuhkan lebih dari 7,5 GB DRAM lokal.
Mungkin seseorang akan memutuskan bahwa akurasi yang lebih rendah dapat mengurangi jumlah memori yang dibutuhkan, tetapi bukan itu masalahnya. Ketika Anda mengubah nilai data ke setengah akurasi untuk bobot dan aktivasi, Anda mengisi hanya setengah lebar vektor SIMD, menghabiskan setengah dari sumber daya komputasi yang tersedia. Untuk mengimbangi ini, ketika Anda beralih dari akurasi penuh ke akurasi setengah pada GPU, maka Anda harus menggandakan ukuran mini-batch untuk menyebabkan paralelisme data yang cukup untuk menggunakan semua perhitungan yang tersedia. Dengan demikian, transisi ke skala akurasi yang lebih rendah dan aktivasi pada GPU masih membutuhkan lebih dari 7.5GB memori dinamis dengan akses gratis.
Dengan begitu banyak data yang akan disimpan, tidak mungkin memasukkan semua ini ke dalam GPU. Pada setiap lapisan jaringan saraf convolutional, perlu untuk menyimpan keadaan DRAM eksternal, memuat lapisan jaringan berikutnya dan kemudian memuat data ke dalam sistem. Akibatnya, antarmuka memori eksternal, yang sudah dibatasi oleh bandwidth memori, menderita beban tambahan untuk terus-menerus memuat ulang keseimbangan, serta menyimpan dan mengambil fungsi aktivasi. Ini secara signifikan memperlambat waktu pelatihan dan secara signifikan meningkatkan konsumsi energi.
Ada beberapa solusi untuk masalah ini. Pertama, operasi seperti fungsi aktivasi dapat dilakukan "di tempat", memungkinkan Anda untuk menimpa input langsung ke output. Dengan demikian, memori yang ada dapat digunakan kembali. Kedua, peluang untuk menggunakan kembali memori dapat diperoleh dengan menganalisis ketergantungan data antara operasi pada jaringan dan distribusi memori yang sama untuk operasi yang tidak menggunakannya pada saat ini.
Pendekatan kedua sangat efektif ketika seluruh jaringan saraf dapat dianalisis pada tahap kompilasi untuk membuat memori yang dialokasikan tetap, karena biaya manajemen memori berkurang menjadi hampir nol. Ternyata kombinasi dari metode-metode ini mengurangi penggunaan memori jaringan saraf dua hingga tiga kali lipat.
Pendekatan signifikan ketiga baru-baru ini ditemukan oleh tim Baidu Deep Speech. Mereka menerapkan berbagai metode menghemat memori untuk mendapatkan pengurangan 16 kali lipat dalam konsumsi memori dengan fungsi aktivasi, yang memungkinkan mereka untuk melatih jaringan dengan 100 lapisan. Sebelumnya, dengan jumlah memori yang sama, mereka bisa melatih jaringan dengan sembilan lapisan.
Menggabungkan sumber daya memori dan pemrosesan dalam satu perangkat memiliki potensi signifikan untuk meningkatkan produktivitas dan efisiensi jaringan saraf convolutional, serta bentuk pembelajaran mesin lainnya. Anda dapat membuat kompromi antara memori dan sumber daya komputasi untuk menyeimbangkan kemampuan dan kinerja sistem.
Jaringan saraf dan model pengetahuan dalam metode pembelajaran mesin lainnya dapat dianggap sebagai grafik matematika. Dalam grafik ini, sejumlah besar paralelisme terkonsentrasi. Prosesor paralel yang dirancang untuk menggunakan konkurensi dalam grafik tidak bergantung pada mini-batch dan dapat secara signifikan mengurangi jumlah penyimpanan lokal yang diperlukan.
Hasil penelitian modern telah menunjukkan bahwa semua metode ini dapat secara signifikan meningkatkan kinerja jaringan saraf. Grafik modern dan unit pemrosesan pusat memiliki memori internal yang sangat terbatas, hanya beberapa megabyte total. Arsitektur prosesor baru yang dirancang khusus untuk pembelajaran mesin memberikan keseimbangan antara memori dan komputasi on-chip, memberikan peningkatan kinerja dan efisiensi yang signifikan dibandingkan dengan unit pemrosesan sentral modern dan akselerator grafis.