
Empat tahun lalu, Google menyadari potensi nyata menggunakan jaringan saraf dalam aplikasinya. Kemudian dia mulai memperkenalkan mereka di mana-mana - dalam terjemahan teks, pencarian suara dengan pengenalan suara, dll. Tetapi segera menjadi jelas bahwa penggunaan jaringan saraf meningkatkan beban di server Google. Secara kasar, jika semua orang melakukan pencarian suara di Android (atau teks yang ditentukan dengan pengenalan suara) hanya tiga menit sehari, maka Google harus menggandakan jumlah pusat data (!) Hanya agar jaringan saraf akan memproses jumlah lalu lintas suara yang sedemikian besar.
Sesuatu harus dilakukan - dan Google menemukan solusinya. Pada 2015, ia mengembangkan arsitektur perangkat kerasnya sendiri untuk pembelajaran mesin (Tensor Processing Unit, TPU), yang mencapai 70 kali lebih cepat dari GPU dan CPU tradisional dalam hal kinerja dan hingga 196 kali lebih banyak dalam hal jumlah perhitungan per watt. GPU / CPU tradisional merujuk ke prosesor tujuan umum Xeon E5 v3 (Haswell) dan GPU Nvidia Tesla K80.
Arsitektur TPU pertama kali dijelaskan minggu ini dalam sebuah
makalah ilmiah (pdf) yang akan dipresentasikan pada Simposium Internasional ke-44 tentang Arsitektur Komputer (ISCA), 26 Juni 2017 di Toronto. Seorang penulis terkemuka lebih dari 70 penulis karya ilmiah ini,
seorang insinyur luar biasa Norman Jouppi, yang dikenal sebagai salah satu pencipta prosesor MIPS, dalam
sebuah wawancara dengan
The Next Platform menjelaskan dengan kata-katanya sendiri fitur-fitur arsitektur TPU yang unik, yang sebenarnya adalah ASIC khusus, yaitu ASIC. sirkuit terpadu untuk keperluan khusus.
Tidak seperti FPGA konvensional atau ASIC yang sangat terspesialisasi, modul TPU diprogram dengan cara yang sama seperti GPU atau CPU, itu bukan peralatan rentang sempit untuk jaringan saraf tunggal. Norman Yuppy mengatakan bahwa TPU mendukung instruksi CISC untuk berbagai jenis jaringan saraf: jaringan saraf konvolusional, model LSTM, dan model besar yang terhubung penuh. Agar tetap terprogram, hanya menggunakan matriks sebagai primitif, dan bukan vektor atau skalar primitif.
Google menekankan bahwa sementara pengembang lain mengoptimalkan microchip mereka untuk jaringan saraf convolutional, jaringan saraf tersebut hanya menyediakan 5% dari beban di pusat data Google. Mayoritas aplikasi Google menggunakan
multilayer Rumelhart perceptrons , sehingga sangat penting untuk membuat arsitektur yang lebih universal yang tidak "dipertajam" hanya untuk jaringan saraf convolutional.
 Salah satu elemen dari arsitektur adalah mesin aliran data sistolik, array 256 × 256, yang menerima aktivasi (bobot) dari neuron di sebelah kiri, dan kemudian semuanya bergeser langkah demi langkah, dikalikan dengan bobot dalam sel. Ternyata matriks sistolik melakukan 65.536 perhitungan per siklus. Arsitektur ini sangat ideal untuk jaringan saraf.
Salah satu elemen dari arsitektur adalah mesin aliran data sistolik, array 256 × 256, yang menerima aktivasi (bobot) dari neuron di sebelah kiri, dan kemudian semuanya bergeser langkah demi langkah, dikalikan dengan bobot dalam sel. Ternyata matriks sistolik melakukan 65.536 perhitungan per siklus. Arsitektur ini sangat ideal untuk jaringan saraf.Menurut Yuppy, arsitektur TPU lebih seperti coprocessor FPU daripada GPU biasa, meskipun banyak matriks untuk perkalian tidak menyimpan program apa pun dalam diri mereka, mereka hanya menjalankan instruksi yang diterima dari tuan rumah.
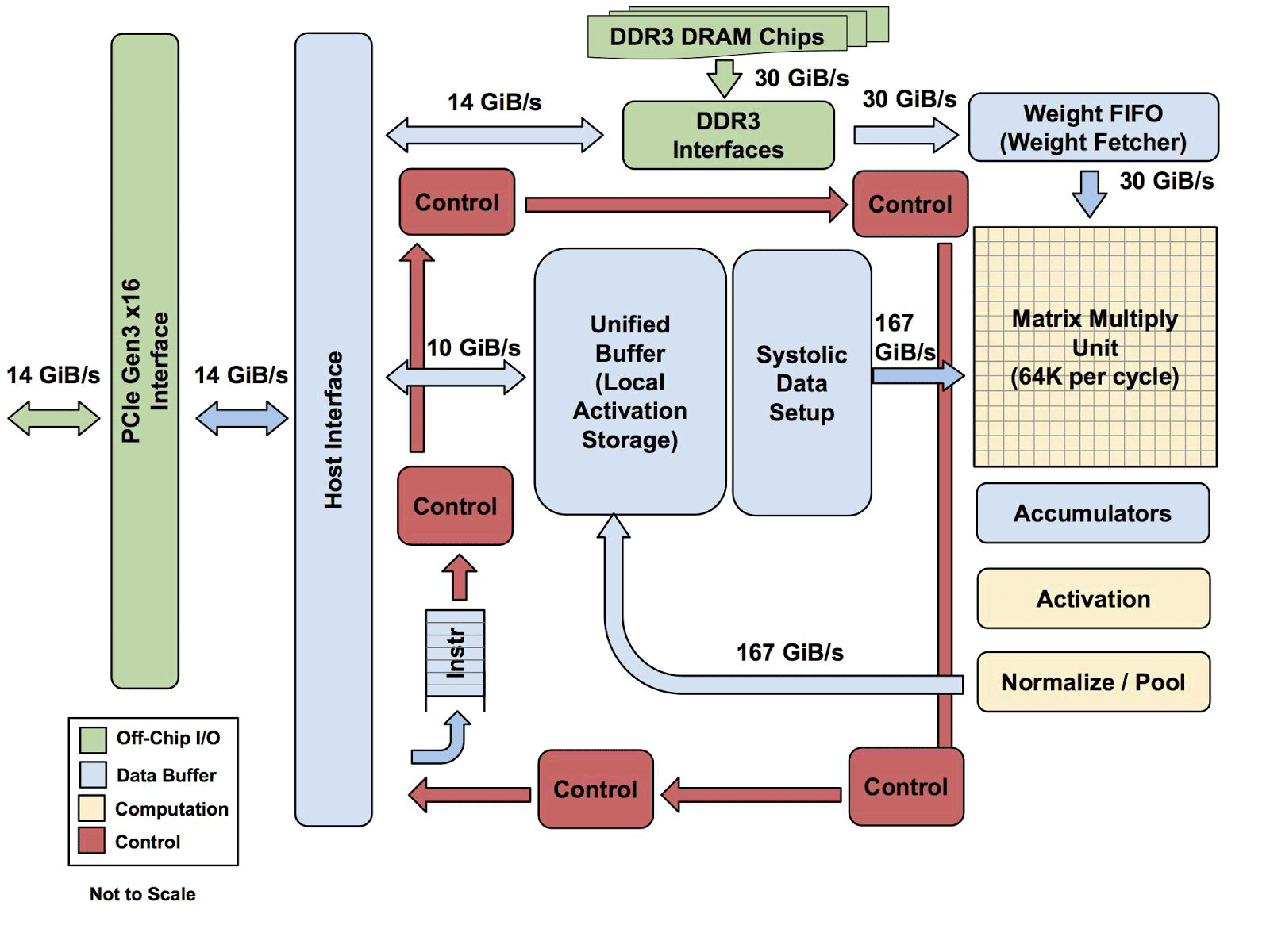 Semua arsitektur TPU dengan pengecualian memori DDR3. Instruksi dikirim dari host (kiri) ke antrian. Kemudian, logika kontrol, tergantung pada instruksinya, dapat menjalankan masing-masingnya berulang kali
Semua arsitektur TPU dengan pengecualian memori DDR3. Instruksi dikirim dari host (kiri) ke antrian. Kemudian, logika kontrol, tergantung pada instruksinya, dapat menjalankan masing-masingnya berulang kaliBelum diketahui seberapa scalable arsitektur ini. Yuppy mengatakan bahwa dalam sistem dengan host semacam ini akan selalu ada semacam bottleneck.
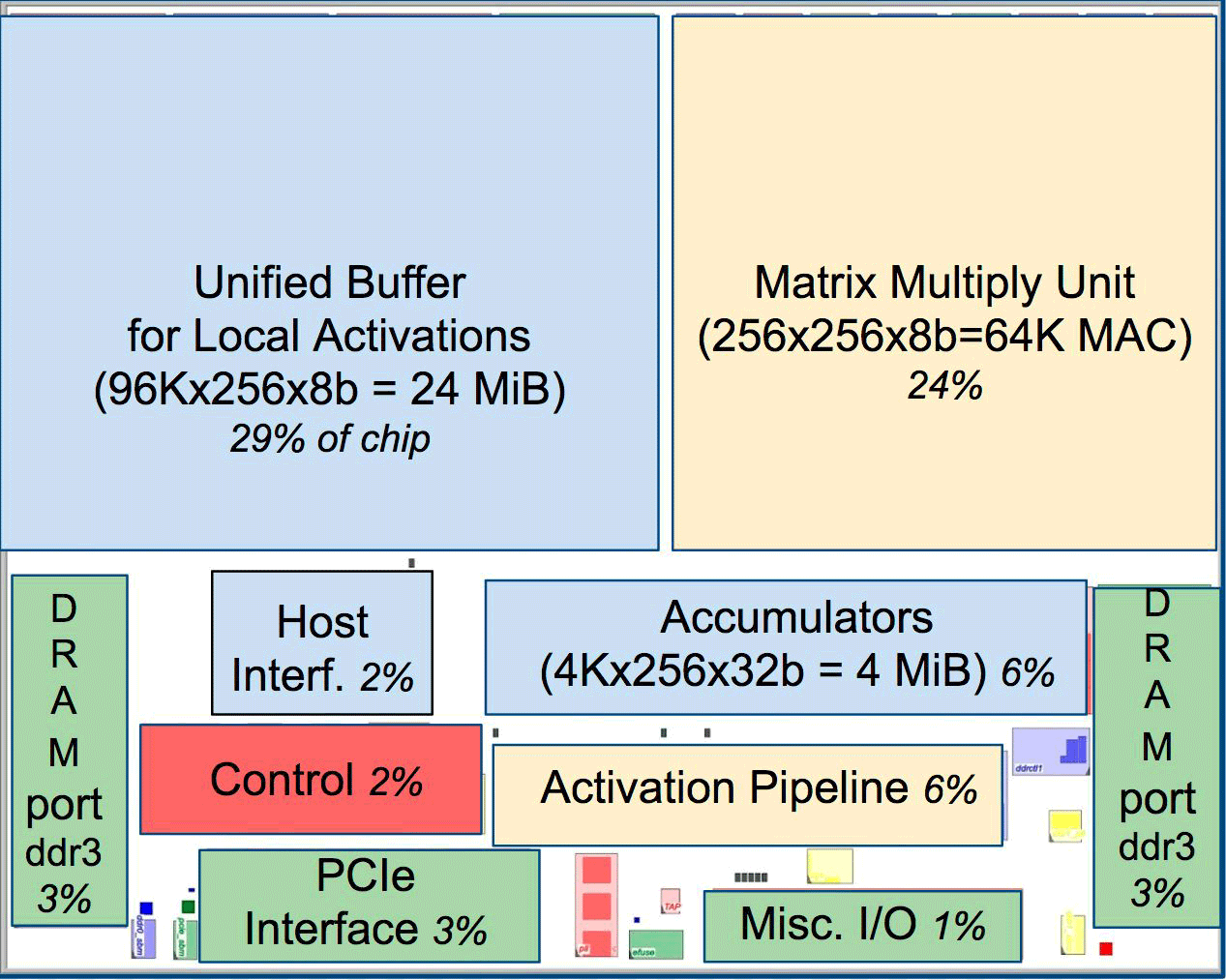
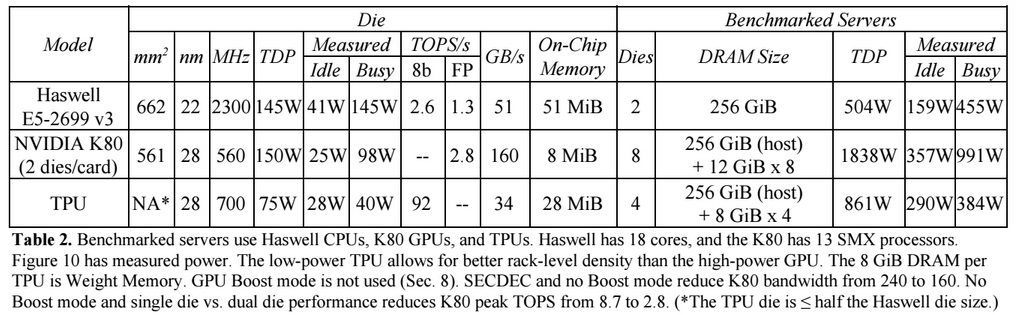
Dibandingkan dengan CPU dan GPU konvensional, arsitektur mesin Google mengungguli mereka sepuluh kali lipat. Misalnya, prosesor Haswell Xeon E5-2699 v3 dengan 18 core pada frekuensi clock 2,3 GHz dengan floating point 64-bit melakukan 1,3 tera-operasi per detik (TOPS) dan menunjukkan kecepatan transfer data 51 GB / s. Dalam hal ini, chip itu sendiri mengkonsumsi 145 watt, dan seluruh sistem di atasnya dengan 256 GB memori - 455 watt.
Sebagai perbandingan, TPU pada operasi 8-bit dengan 256 GB memori eksternal dan 32 GB memorinya sendiri menunjukkan kecepatan transfer 34 GB / s memori, tetapi kartu melakukan 92 TOPS, yaitu sekitar 71 kali lebih banyak daripada prosesor Haswell. Konsumsi daya server pada TPU adalah 384 watt.
Grafik berikut membandingkan kinerja relatif per watt server dengan GPU (kolom biru), server di TPU (merah) relatif ke server di CPU. Ini juga membandingkan kinerja relatif per watt server dengan TPU relatif ke server pada GPU (oranye) dan versi peningkatan TPU relatif ke server pada CPU (hijau) dan server pada GPU (ungu).

Perlu dicatat bahwa Google membuat perbandingan dalam pengujian aplikasi pada TensorFlow dengan versi relatif lama dari Haswell Xeon, sedangkan dalam versi yang lebih baru dari Broadwell Xeon E5 v4 jumlah instruksi per siklus meningkat 5% karena peningkatan arsitektur, dan dalam versi Skylake Xeon E5 v5 , yang diharapkan pada musim panas, jumlah instruksi per siklus dapat meningkat 9-10%. Dan dengan peningkatan jumlah core dari 18 menjadi 28 di Skylake, kinerja keseluruhan prosesor Intel dalam pengujian Google dapat meningkat sebesar 80%. Namun demikian, akan ada perbedaan kinerja yang sangat besar dengan TPU. Dalam versi pengujian dengan floating point 32-bit, perbedaan antara TPU dan CPU dikurangi menjadi sekitar 3,5 kali. Tetapi sebagian besar model sempurna terkuantisasi menjadi 8 bit.
Google telah memikirkan cara menggunakan GPU, FPGA, dan ASIC di pusat data sejak 2006, tetapi tidak menemukannya sampai saat ini, ketika memperkenalkan pembelajaran mesin untuk sejumlah tugas praktis, dan beban pada jaringan saraf ini mulai tumbuh dengan miliaran permintaan dari pengguna. Sekarang perusahaan tidak punya pilihan selain pindah dari CPU tradisional.
Perusahaan tidak berencana untuk menjual prosesornya kepada siapa pun, tetapi berharap bahwa karya ilmiah dengan ASIC 2015 akan memungkinkan orang lain untuk meningkatkan arsitektur dan membuat versi ASIC yang lebih baik yang "akan meningkatkan standar lebih tinggi." Google sendiri mungkin sudah bekerja pada ASIC versi baru.