 Tangkapan layar tugas dan penerbitan jaringan saraf pix2code dalam bahasanya sendiri, yang kemudian diterjemahkan oleh kompiler menjadi kode untuk platform yang diinginkan (Android, iOS)
Tangkapan layar tugas dan penerbitan jaringan saraf pix2code dalam bahasanya sendiri, yang kemudian diterjemahkan oleh kompiler menjadi kode untuk platform yang diinginkan (Android, iOS)Program
pix2code baru (
artikel ilmiah ) dirancang untuk memfasilitasi pekerjaan programmer yang terlibat dalam bisnis yang membosankan dalam mengkode GUI klien.
Perancang biasanya membuat layout antarmuka, dan programmer harus menulis kode untuk mengimplementasikan desain ini. Pekerjaan semacam itu membutuhkan waktu berharga yang dapat dihabiskan pengembang untuk tugas-tugas yang lebih menarik dan kreatif, yaitu pada implementasi fungsi dan logika program yang sebenarnya, bukan GUI. Segera, pembuatan kode dapat ditransfer ke bahu program. Demonstrasi mainan tentang kemungkinan pembelajaran mesin di masa depan adalah proyek
pix2code , yang telah mencapai tempat pertama dalam
daftar repositori terpanas di GitHub , meskipun penulis bahkan belum memposting kode sumber dan set data untuk melatih jaringan saraf! Ketertarikan yang besar pada topik ini.
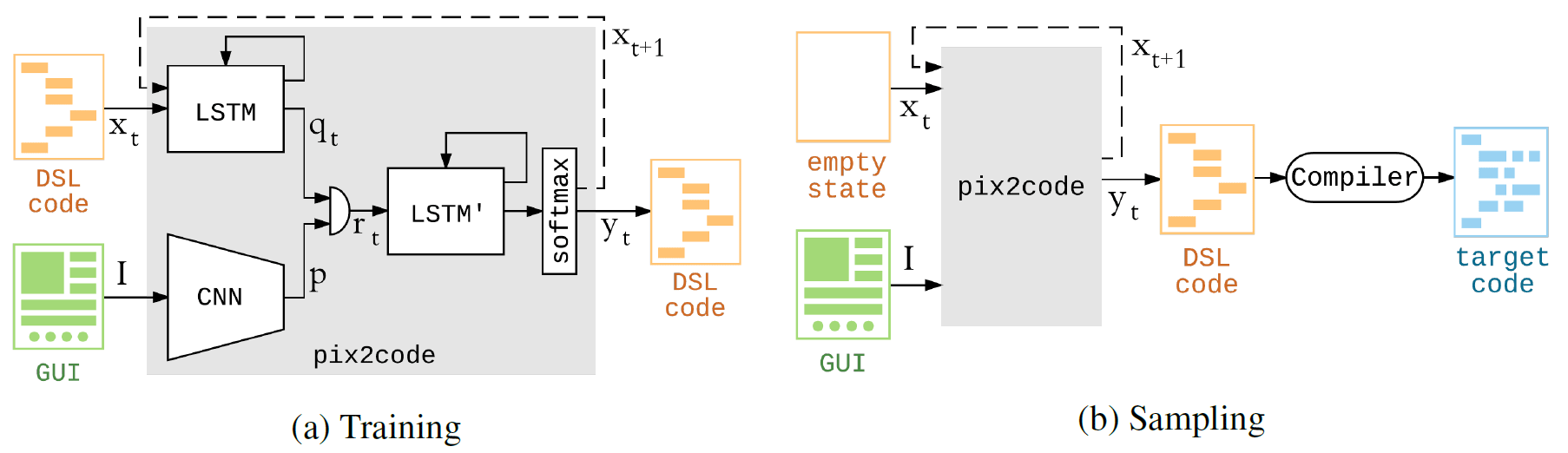
Pengkodean GUI itu membosankan. Lebih buruk lagi, ini adalah bahasa pemrograman yang berbeda pada platform yang berbeda. Artinya, Anda perlu menulis kode terpisah untuk Android, terpisah untuk iOS, jika program tersebut seharusnya bekerja secara native. Ini bahkan membutuhkan lebih banyak waktu dan membuat Anda melakukan tugas yang sama dan membosankan. Lebih tepatnya, itu sebelumnya. Program pix2code menghasilkan kode GUI untuk tiga platform utama - Andriod, iOS dan lintas-platform HTML / CSS - dengan akurasi 77% (akurasi ditentukan dalam bahasa built-in program - dengan membandingkan kode yang dihasilkan dengan kode target / yang diharapkan untuk setiap platform).
Penulis program Tony Beltramelli dari startup Denmark
UIzard Technologies menyebut ini demonstrasi konsep. Dia percaya bahwa ketika penskalaan, model akan meningkatkan akurasi pengkodean dan berpotensi dapat menyelamatkan orang dari keharusan menyandikan GUI secara manual.
Program pix2code dibangun di atas jaringan saraf convolutional dan berulang. Pelatihan pada GPU Nvidia Tesla K80 membutuhkan waktu kurang dari lima jam - selama waktu itu sistem dioptimalkan
parameter untuk satu set data. Jadi jika Anda ingin melatihnya untuk tiga platform, itu akan memakan waktu sekitar 15 jam.
Model ini dapat menghasilkan kode dengan hanya menerima nilai piksel dari satu tangkapan layar di input. Dengan kata lain, pipa khusus tidak diperlukan untuk jaringan saraf untuk mengekstraksi fitur dan data input preproses.
Pembuatan kode komputer dari tangkapan layar dapat dibandingkan dengan pembuatan deskripsi teks dari sebuah foto. Dengan demikian, arsitektur model pix2code terdiri dari tiga bagian: 1) modul visi komputer untuk mengenali gambar, objek yang disajikan di sana, lokasi, bentuk dan warna (tombol, keterangan, wadah elemen); 2) modul bahasa untuk memahami teks (dalam hal ini, bahasa pemrograman) dan menghasilkan contoh yang benar secara semantik dan semantik; 3) menggunakan dua model sebelumnya untuk menghasilkan deskripsi teks (kode) untuk objek yang dikenali (elemen GUI).
Penulis menarik perhatian pada fakta bahwa jaringan saraf dapat dilatih pada set data yang berbeda - dan kemudian akan mulai menghasilkan kode dalam bahasa lain untuk platform lain. Penulis sendiri tidak berencana untuk melakukan ini, karena ia menganggap kode pix2 sebagai mainan yang menunjukkan beberapa teknologi yang sedang dikerjakan oleh startup-nya. Namun, siapa pun dapat melakukan fork proyek dan membuat implementasi untuk bahasa / platform lain.
Dalam sebuah makalah ilmiah, Tony Beltramelli menulis bahwa ia akan menerbitkan kumpulan data untuk pelatihan jaringan saraf dalam domain publik dalam repositori di GitHub. Repositori telah dibuat. Di sana, di bagian FAQ, penulis mengklarifikasi bahwa ia akan memposting set data setelah publikasi (atau penolakan untuk mempublikasikan) artikelnya di
konferensi NIPS 2017 . Pemberitahuan dari penyelenggara konferensi harus datang pada awal September, sehingga set data akan muncul di repositori pada saat yang sama. Akan ada screenshot dari GUI, kode yang sesuai dalam bahasa program, dan output kompiler untuk tiga platform utama.
Mengenai kode sumber program, penulisnya tidak berjanji untuk menerbitkan, tetapi mengingat minat yang besar dalam pengembangannya, ia memutuskan untuk membukanya juga. Ini akan dilakukan bersamaan dengan publikasi set data.
Artikel ilmiah ini
diterbitkan pada 22 Mei 2017 di situs pracetak arXiv.org (arXiv: 1705.07962).