Chip pada kebanyakan komputer desktop modern memiliki empat core, tetapi pembuat chip telah mengumumkan rencana untuk meningkatkan ke enam core, dan prosesor 16-core jauh dari biasa untuk server berkinerja tinggi.
Semakin banyak core, semakin besar masalah alokasi memori antara semua core saat bekerja bersama. Dengan meningkatnya jumlah core, menjadi semakin menguntungkan untuk meminimalkan kehilangan waktu dalam mengelola core selama pemrosesan data - karena nilai tukar data tertinggal dari kecepatan prosesor dan pemrosesan data dalam memori. Anda dapat secara fisik beralih ke cache cepat orang lain, atau Anda dapat menggunakan lambat sendiri, tetapi menghemat waktu transfer data. Tugas ini rumit oleh kenyataan bahwa jumlah memori yang diminta oleh program tidak jelas sesuai dengan ukuran cache masing-masing jenis.
Hanya jumlah memori yang sangat terbatas yang dapat ditempatkan secara fisik sedekat mungkin dengan prosesor - cache prosesor level L1, yang jumlahnya sangat kecil. Daniel Sanchez, Po-An Tsai, dan Nathan Beckmann, peneliti di Laboratorium Ilmu Komputer dan Laboratorium Inteligensi Buatan Institut Teknologi Massachusetts,
mengajarkan komputer
cara mengonfigurasi berbagai jenis memori agar sesuai dengan hierarki program yang fleksibel ke dalam waktu nyata Sistem baru, yang disebut Jenga, menganalisis kebutuhan volumetrik dan frekuensi akses program ke memori dan mendistribusikan kembali kekuatan masing-masing dari 3 jenis cache prosesor dalam kombinasi yang memberikan peningkatan efisiensi dan penghematan energi.

Untuk mulai dengan, para peneliti menguji peningkatan kinerja dengan kombinasi memori statis dan dinamis dalam mengerjakan program-program untuk prosesor single-core dan mendapatkan hierarki utama - ketika kombinasi mana yang terbaik untuk digunakan. Dari 2 jenis memori atau dari satu. Dua parameter dievaluasi - keterlambatan sinyal (latensi) dan konsumsi energi selama pengoperasian setiap program. Sekitar 40% dari program mulai bekerja lebih buruk dengan kombinasi jenis memori, sisanya - lebih baik. Setelah memperbaiki program mana yang "suka" kinerja campuran, dan mana - ukuran memori, para peneliti membangun sistem Jenga mereka.
Mereka sebenarnya menguji 4 jenis program pada komputer virtual dengan 36 core. Menguji program:
- omnet - Objective Modular Network Testbed, C modeling library dan platform tools modelling jaringan (biru pada gambar)
- mcf - Kerangka Konten Meta (merah)
- astar - perangkat lunak untuk menampilkan realitas virtual (hijau)
- bzip2 - pengarsip (warna ungu)
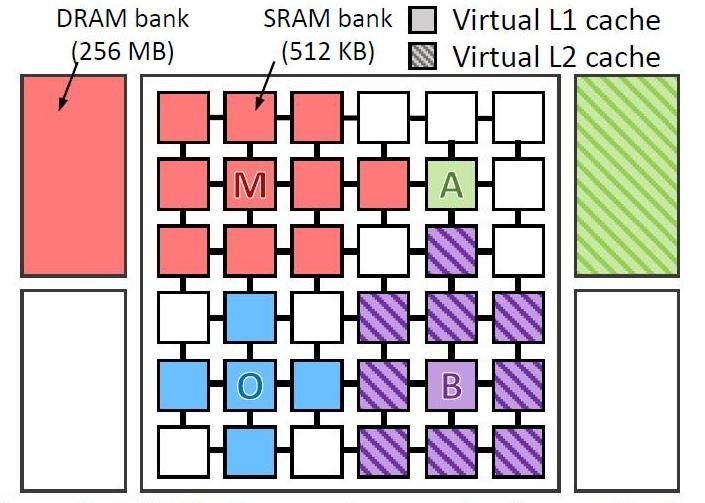
Gambar menunjukkan di mana dan bagaimana data masing-masing program diproses. Huruf-huruf menunjukkan di mana setiap aplikasi berjalan (satu per kuadran), warna menunjukkan di mana datanya berada, dan penetasan menunjukkan tingkat kedua dari hierarki virtual ketika itu ada.
Tingkat cacheCache CPU dibagi menjadi beberapa level. Untuk prosesor universal - hingga 3. Memori tercepat adalah cache level pertama - L1-cache, karena terletak pada chip yang sama dengan prosesor. Terdiri dari cache perintah dan cache data. Beberapa prosesor tanpa cache L1 tidak dapat berfungsi. Cache L1 berjalan pada frekuensi prosesor, dan dapat diakses setiap siklus clock. Seringkali dimungkinkan untuk melakukan beberapa operasi baca / tulis pada saat yang bersamaan. Volume biasanya kecil - tidak lebih dari 128 KB.
L1 cache berinteraksi dengan cache level kedua - L2. Ini tercepat kedua. Biasanya terletak di chip, seperti L1, atau di sekitar inti, misalnya, dalam kartrid prosesor. Pada prosesor yang lebih lama, sebuah chipset pada motherboard. Ukuran cache L2 adalah dari 128 KB hingga 12 MB. Dalam prosesor multi-core modern, cache tingkat kedua, yang terletak pada chip yang sama, adalah memori bersama - dengan ukuran cache total 8 MB, 2 MB per inti. Biasanya, latensi cache L2 yang terletak pada chip inti adalah antara 8 dan 20 siklus clock. Dalam tugas yang terkait dengan berbagai akses ke area memori yang terbatas, misalnya, DBMS, penggunaan penuhnya membuat produktivitas meningkat sepuluh kali lipat.
Cache L3 biasanya lebih besar, meskipun sedikit lebih lambat dari L2 (karena fakta bahwa bus antara L2 dan L3 lebih sempit daripada bus antara L1 dan L2). L3 biasanya terletak terpisah dari inti CPU, tetapi bisa besar - lebih dari 32 MB. L3 cache lebih lambat dari cache sebelumnya, tetapi masih lebih cepat dari RAM. Dalam sistem multiprosesor biasa digunakan. Penggunaan cache tingkat ketiga dibenarkan dalam berbagai tugas yang sangat sempit dan mungkin tidak hanya tidak meningkatkan produktivitas, tetapi sebaliknya dan menyebabkan penurunan umum dalam kinerja sistem.
Menonaktifkan cache level kedua dan ketiga paling berguna dalam masalah matematika ketika jumlah data kurang dari ukuran cache. Dalam hal ini, Anda dapat memuat semua data segera ke cache L1, dan kemudian memprosesnya.
Secara berkala, Jenga di tingkat OS mengkonfigurasi ulang hierarki virtual untuk meminimalkan pertukaran data, mengingat kendala sumber daya dan perilaku aplikasi. Setiap konfigurasi ulang terdiri dari empat langkah.
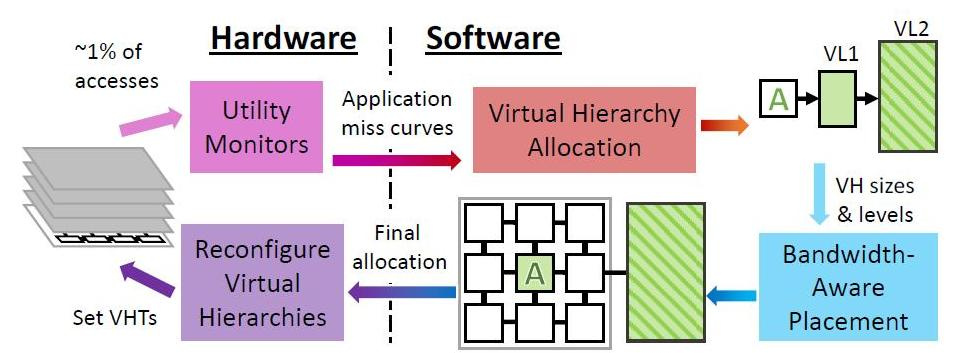
Jenga mendistribusikan data tidak hanya tergantung pada program mana yang dikirim - mereka yang suka memori berkecepatan tunggal besar atau yang suka kinerja cache campuran, tetapi juga tergantung pada kedekatan fisik sel-sel memori dengan data yang sedang diproses. Terlepas dari jenis cache apa yang dibutuhkan oleh program secara default atau hierarki. Yang utama adalah meminimalkan penundaan sinyal dan konsumsi energi. Bergantung pada berapa banyak jenis memori yang “disukai” program, Jenga memodelkan latensi setiap hierarki virtual dengan satu atau dua tingkat. Hirarki dua tingkat membentuk permukaan, hierarki satu tingkat membentuk kurva. Jenga kemudian merancang penundaan minimum dalam ukuran VL1, yang memberikan dua kurva. Akhirnya, Jenga menggunakan kurva ini untuk memilih hierarki terbaik (mis. Ukuran VL1).
Penggunaan Jenga memberi efek nyata. Chip virtual 36-core 30 persen lebih cepat dan menggunakan daya 85 persen lebih sedikit. Tentu saja, sementara Jenga hanyalah simulasi dari komputer yang berfungsi, itu akan memakan waktu sebelum Anda melihat contoh nyata dari cache ini dan bahkan sebelum produsen chip menerimanya jika mereka menyukai teknologi tersebut.
Konfigurasi mesin nuklir bersyarat 36
- Pengolah . 36 core, x86-64 ISA, 2,4 GHz, OOO seperti Silvermont: selebar 8B
ifetch; 2-level bpred dengan BHSR 512 × 10-bit + 1024 × 2-bit PHT, 2-way decode / issue / rename / commit, 32-entri IQ dan ROB, 10-entri LQ, 16-entri SQ; 371 pJ / instruksi, 163 mW / inti daya statis - Cache tingkat L1 . 32 KB, set-asosiatif 8 arah, membagi data dan cache instruksi,
3 siklus latensi; 15/33 pJ per hit / miss - Prefetcher Layanan Prefetch . Prefetcher aliran 16 entri dimodelkan setelah dan divalidasi terhadap
Nehalem - Cache tingkat L2 . 128 KB pribadi per-inti, 8-arah set-asosiatif, inklusif, latensi 6 siklus; 46/93 pJ per hit / miss
- Mode koheren (Koherensi) . Bank direktori latensi 16-arah, 6-siklus untuk Jenga; direktori L3 di-cache untuk orang lain
- Global NoC . 6 × 6 mesh, link dan link 128-bit, perutean XY, router perpipaan 2-siklus, tautan 1-siklus; 63/71 pJ per router / link flit traversal, 12 / 4mW router / link daya statis
- SRAM blok memori statis . 18 MB, satu bank 512 KB per kotak, zcache 52-arah 4 arah, latensi bank 9-siklus, partisi Vantage; 240/500 pJ per hit / miss, daya statis 28 mW / bank
- Memori dinamis multilayer Stacked DRAM . 1152MB, satu lemari besi 128MB per 4 ubin, Paduan dengan MAP-I DDR3-3200 (1600 MHz), bus 128-bit, 16 peringkat, 8 bank / peringkat, buffer baris 2 KB; 4.4 / 6.2 nJ per hit / miss, daya statis 88 mW / vault
- Memori utama . 4 DDR3-1600 saluran, bus 64-bit, 2 peringkat / saluran, 8 bank / peringkat, buffer baris 8 KB; 20 nJ / akses, daya statis 4W
- Pengaturan waktu DRAM . tCAS = 8, tRCD = 8, tRTP = 4, tRAS = 24, tRP = 8, tRRD = 4, tWTR = 4, tWR = 8, tFAW = 18 (semua timing dalam tCK; DRAM yang ditumpuk memiliki setengah tCK sebagai memori utama )