 Digital ganda politisi dan aktor terkenal berada di bawah kendali penuh "dalang". Ilustrasi: University of Washington, 2015
Digital ganda politisi dan aktor terkenal berada di bawah kendali penuh "dalang". Ilustrasi: University of Washington, 2015Program grafik 3D, ditambah dengan jaringan saraf, telah mencapai kualitas sedemikian rupa sehingga video palsu hampir tidak dapat dibedakan dari yang asli. Segera tidak akan mungkin untuk mengatakan dengan pasti bahwa orang di layar TV adalah seorang politisi sejati, bukan simulasi komputer.
Pada bulan Desember 2015, para ilmuwan dari University of Washington memperkenalkan
teknologi "digital double" : penciptaan model "langsung" dari ratusan foto dengan satu karakter. Arsip foto besar telah dikompilasi untuk selebriti dan politisi di Internet. Program ini menciptakan sebuah model, dan yang satu itu seperti boneka di atas tali - ia dapat dikontrol sesuka Anda, memberikan ekspresi wajah yang berbeda, menyampaikan pidato dengan bibir Anda.
Sekarang, pada malam konferensi grafis komputer
SIGGRAPH 2017 , kelompok peneliti yang sama telah menerbitkan
karya ilmiah baru dengan versi canggih “rekan digital”.
Sekarang ketika mengajar program, tidak hanya foto yang digunakan, tetapi juga video, sehingga pelatihan menjadi jauh lebih efektif. Untuk menunjukkan teknologi, para ilmuwan telah memilih karakter terkenal - mantan Presiden AS Barack Obama. Ini adalah pilihan yang baik, karena Internet memiliki banyak materi HD-video. Jutaan bingkai video tersedia untuk melatih jaringan saraf.
Jaringan saraf telah mempelajari secara rinci fitur ekspresi wajah Obama: gerakan bibir pada setiap suara, penampilan keriput di dekat mata, perubahan bentuk alis dan kemiringan kepala. Ekspresi wajah karakter eksperimental dikaitkan dengan suara yang dia ucapkan: jaringan saraf memproses tidak hanya bingkai video, tetapi juga trek audio untuk mereka.
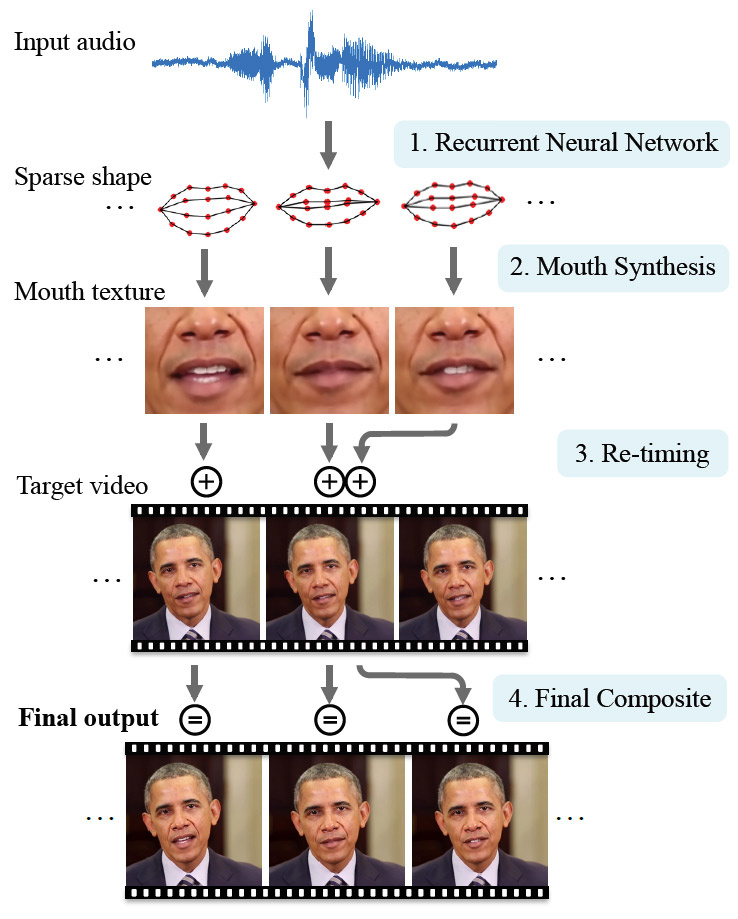
Dengan demikian, AI yang lemah belajar untuk menyinkronkan ekspresi wajah dan gerakan bibir dengan ucapan sewenang-wenang yang diberikan peneliti pada input jaringan saraf.
Penggoda untuk karya ilmiah membandingkan rekaman video nyata dari pidato Obama dan hasilnya disintesis oleh jaringan saraf.
Perlu dicatat bahwa hasil yang disintesis sangat berbeda dari yang asli, tetapi masih terlihat sangat realistis.
Para peneliti menekankan bahwa sebelumnya, untuk mendapatkan "digital double," orang dipaksa untuk berulang kali mengulangi frasa yang sama di depan kamera untuk merekam semua kombinasi morfem dan ekspresi wajah. Sekarang Anda dapat melakukan ini pada video yang tersedia untuk umum. Benar, tidak setiap orang di Internet memiliki materi video yang cukup untuk memalsukan kepribadiannya, tetapi seiring waktu, pengguna sendiri menyelesaikan masalah ini dengan mengunggah gigabyte foto dan video mereka ke jejaring sosial.
Dari sudut pandang praktis, teknologi ini juga dapat digunakan. Sebagai contoh, Ira Kemelmacher-Shlizerman, salah satu penulis pendamping dari karya ilmiah,
mengatakan bahwa dia akan meningkatkan kualitas konferensi video dengan mensintesiskan frame yang hilang jika mereka keluar dari aliran video. Jika suara berjalan tanpa gangguan, dan video tertinggal, sintesis seperti itu akan melengkapi gambar atau meningkatkan resolusinya. Tentu saja, teknologi dapat menemukan aplikasi dalam permainan komputer dan realitas virtual jika pemain berkomunikasi dengan karakter virtual. Sekarang ucapan karakter virtual akan menjadi lebih realistis, dan itu bisa menjadi salinan digital dari beberapa orang sungguhan. Misalnya, Anda dapat "menghidupkan kembali" beberapa tokoh sejarah dari masa lalu hanya dengan rekaman audio. Tentu saja, pemalsuan untuk tujuan politik akan difasilitasi. Jika sekarang mereka
dicetak dalam "Photoshop" dan dibuang ke jejaring sosial , maka di masa depan video palsu akan ditampilkan di TV.
Para penulis mengakui bahwa teknologi sejauh ini tidak sempurna. Misalnya, jika Obama memalingkan wajahnya sedikit dari kamera, maka bagian mulutnya dapat terpisah dari wajahnya dan tumpang tindih dengan latar belakang. Tetapi ini adalah kesalahan kecil yang dapat diperbaiki dengan pelatihan tambahan dari jaringan saraf.
Kelemahan lain dari model yang dibuat adalah tidak memodelkan emosi. Ekspresi wajah benar-benar netral dan hampir selalu sama. Jadi, dalam beberapa kasus, digital double kehilangan realismenya: ekspresi wajahnya tampak terlalu serius untuk kata-kata sembrono yang diucapkannya. Atau sebaliknya - terlalu sembrono untuk pidato yang sangat serius. Namun, insiden seperti itu terjadi dengan politisi sejati di kehidupan nyata.

Teknologi yang diciptakan pada prinsipnya mirip dengan bekerja pada
program untuk menciptakan digital ganda Face2Face , di mana ekspresi wajah dan ucapan satu orang ditransfer ke wajah orang lain. Dalam karya ilmiah mereka, penulis dari Washington membandingkan hasil jaringan saraf mereka dengan Face2Face. Mereka menjelaskan bahwa dalam kasus Face2Face, aliran video selalu diperlukan untuk disimulasikan, dan model mereka hanya berfungsi dengan rekaman suara.