
Pada awal abad ke-20, Wilhelm von Austin, seorang pelatih kuda dan matematikawan Jerman, mengumumkan kepada dunia bahwa ia telah mengajar seekor kuda untuk menghitung. Selama bertahun-tahun, von Austin berkeliling Jerman dengan menunjukkan fenomena ini. Dia meminta kudanya, dijuluki
Hans Pintar (
trotter Orlov trah), untuk menghitung hasil persamaan sederhana. Hans menjawab, menjejakkan kakinya. Dua tambah dua? Empat hit.
Tetapi para ilmuwan tidak percaya bahwa Hans sepandai yang diklaim von Austin. Psikolog
Karl Stumpf melakukan penyelidikan menyeluruh, yang dijuluki "Komite Hans." Dia menemukan bahwa Smart Hans tidak menyelesaikan persamaan, tetapi merespons sinyal visual. Hans mengetuk kukunya sampai dia mendapatkan jawaban yang benar, setelah itu pelatihnya dan kerumunan yang antusias berteriak. Dan kemudian dia berhenti. Ketika dia tidak melihat reaksi ini, dia terus mengetuk.
Ilmu komputer dapat belajar banyak dari Hans. Kecepatan percepatan pembangunan di bidang ini menunjukkan bahwa sebagian besar AI yang kami buat telah cukup terlatih untuk memberikan jawaban yang benar, tetapi tidak benar-benar memahami informasi tersebut. Dan mudah untuk dibodohi.
Algoritma pembelajaran mesin dengan cepat berubah menjadi gembala yang melihat semua manusia. Perangkat lunak ini menghubungkan kita ke Internet, memonitor spam dan konten berbahaya dalam surat kami, dan akan segera mengendarai mobil kami. Tipu daya mereka menggeser fondasi tektonik Internet, dan mengancam keamanan kita di masa depan.
Kelompok riset kecil - dari Pennsylvania State University, dari Google, dari militer AS - sedang mengembangkan rencana untuk melindungi terhadap serangan potensial terhadap AI. Teori yang dikemukakan dalam penelitian ini mengatakan bahwa seorang penyerang dapat mengubah apa yang "dilihat" oleh robomobile. Atau aktifkan pengenalan suara di telepon dan paksa untuk masuk ke situs web berbahaya menggunakan suara yang hanya akan berisik bagi seseorang. Atau biarkan virus bocor melalui firewall jaringan.
 Di sebelah kiri adalah gambar bangunan, di sebelah kanan adalah gambar yang dimodifikasi, yang berhubungan dengan jaringan saraf dalam dengan burung unta. Di tengah, semua perubahan yang diterapkan pada gambar utama ditampilkan.
Di sebelah kiri adalah gambar bangunan, di sebelah kanan adalah gambar yang dimodifikasi, yang berhubungan dengan jaringan saraf dalam dengan burung unta. Di tengah, semua perubahan yang diterapkan pada gambar utama ditampilkan.Alih-alih mengendalikan kontrol robomobile, metode ini menunjukkan padanya sesuatu seperti halusinasi - gambar yang sebenarnya tidak ada.
Serangan seperti itu menggunakan gambar dengan trik [contoh permusuhan - tidak ada istilah Rusia yang mapan, kata demi kata ternyata seperti "contoh dengan kontras" atau "contoh yang bersaing" - sekitar terjemahan.]: gambar, suara, teks yang terlihat normal bagi orang-orang tetapi dirasakan oleh mesin yang sama sekali berbeda. Perubahan kecil yang dibuat oleh penyerang dapat menyebabkan jaringan saraf yang dalam menarik kesimpulan yang salah tentang apa yang ditunjukkannya.
"Setiap sistem yang menggunakan pembelajaran mesin untuk membuat keputusan penting keamanan berpotensi rentan terhadap serangan jenis ini," kata Alex Kanchelyan, seorang peneliti di University of Berkeley yang mempelajari serangan pembelajaran mesin menggunakan gambar palsu.
Mengetahui nuansa ini pada tahap awal pengembangan AI memberi peneliti alat untuk memahami bagaimana memperbaiki kekurangan ini. Beberapa sudah mengambil ini, dan mereka mengatakan bahwa algoritma mereka menjadi lebih dan lebih efisien karena ini.
Sebagian besar aliran utama penelitian AI didasarkan pada jaringan saraf yang dalam, yang pada gilirannya didasarkan pada bidang pembelajaran mesin yang lebih luas. Teknologi Kementerian Perindustrian menggunakan kalkulus diferensial dan integral dan statistik untuk membuat perangkat lunak yang digunakan oleh sebagian besar dari kita, seperti filter spam dalam surat atau mencari di internet. Selama 20 tahun terakhir, para peneliti telah mulai menerapkan teknik-teknik ini pada ide baru, jaringan saraf - struktur perangkat lunak yang meniru fungsi otak. Idenya adalah untuk mendesentralisasikan perhitungan di ribuan persamaan kecil ("neuron") yang menerima data, memproses dan mengirimkannya lebih lanjut, ke lapisan berikutnya dari ribuan persamaan kecil.
Algoritma AI ini dilatih dengan cara yang sama seperti dalam kasus MO, yang, pada gilirannya, menyalin proses pembelajaran seseorang. Mereka ditunjukkan contoh hal yang berbeda dan tag terkait mereka. Perlihatkan komputer (atau anak) gambar kucing, katakan bahwa kucing itu terlihat seperti ini, dan algoritme akan belajar mengenali kucing. Tetapi untuk ini, komputer harus melihat ribuan dan jutaan gambar kucing dan kucing.
Para peneliti telah menemukan bahwa sistem ini dapat diserang dengan data menipu yang dipilih secara khusus, yang mereka sebut "contoh permusuhan".
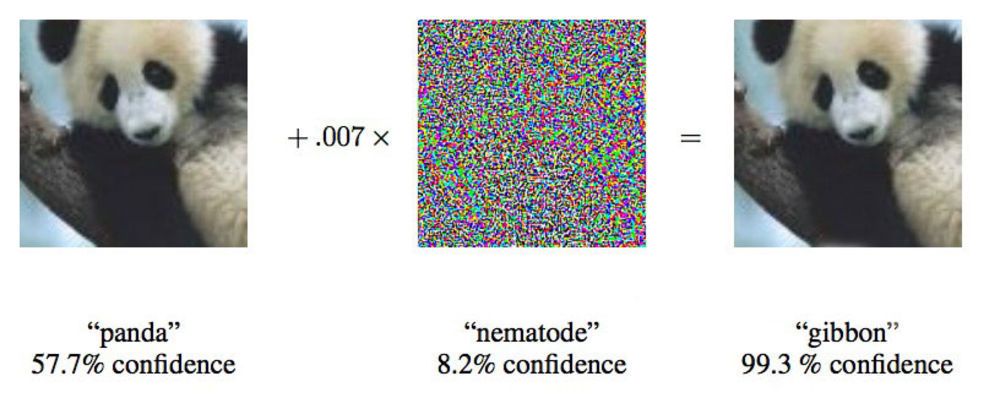 Dalam sebuah makalah dari 2015, para peneliti dari Google menunjukkan bahwa jaringan saraf yang dalam dapat dipaksa untuk menghubungkan gambar panda ini dengan owa.
Dalam sebuah makalah dari 2015, para peneliti dari Google menunjukkan bahwa jaringan saraf yang dalam dapat dipaksa untuk menghubungkan gambar panda ini dengan owa."Kami menunjukkan kepada Anda foto yang dengan jelas menunjukkan bus sekolah, dan membuat Anda berpikir itu adalah burung unta," kata Ian Goodfellow, seorang peneliti Google yang secara aktif bekerja pada serangan semacam itu pada jaringan saraf.
Mengubah gambar yang disediakan untuk jaringan saraf dengan hanya 4%, para peneliti dapat menipu mereka untuk membuat kesalahan dengan klasifikasi pada 97% kasus. Bahkan jika mereka tidak tahu persis bagaimana jaringan syaraf memproses gambar, mereka bisa menipu dalam 85% kasus.
Varian terakhir dari penipuan tanpa data pada arsitektur jaringan disebut “serangan kotak hitam”. Ini adalah kasus pertama yang didokumentasikan dari serangan fungsional semacam ini pada jaringan saraf yang dalam, dan pentingnya adalah bahwa kira-kira dalam skenario ini serangan di dunia nyata dapat terjadi.
Dalam studi tersebut, para peneliti dari Pennsylvania State University, Google, dan US Navy Research Laboratory menyerang jaringan saraf yang mengklasifikasikan gambar yang didukung oleh proyek MetaMind dan berfungsi sebagai alat online untuk pengembang. Tim membangun dan melatih jaringan yang diserang, tetapi algoritma serangan mereka bekerja terlepas dari arsitektur. Dengan algoritma seperti itu, mereka mampu menipu jaringan saraf kotak hitam dengan akurasi 84,24%.
 Baris teratas foto dan karakter - pengenalan karakter yang benar.
Baris teratas foto dan karakter - pengenalan karakter yang benar.
Baris bawah - jaringan dipaksa untuk mengenali tanda-tanda yang sepenuhnya salah.Memberi makan data yang tidak akurat ke mesin bukanlah ide baru, tetapi Doug Tygar, seorang profesor di University of Berkeley, yang telah mempelajari pembelajaran mesin selama 10 tahun berbeda, mengatakan teknologi serangan ini telah berkembang dari MO sederhana ke jaringan saraf yang dalam dan kompleks. Peretas jahat telah menggunakan teknik ini pada filter spam selama bertahun-tahun.
Penelitian Tiger berasal dari
karyanya 2006 tentang serangan semacam ini di jaringan dengan Kementerian Pertahanan, yang ia
kembangkan pada 2011 dengan bantuan peneliti dari UC Berkeley dan Microsoft Research. Tim Google, yang pertama menggunakan jaringan saraf dalam, menerbitkan
karya pertamanya pada 2014, dua tahun setelah menemukan kemungkinan serangan semacam itu. Mereka ingin memastikan bahwa ini bukan semacam anomali, tetapi kemungkinan nyata. Pada 2015, mereka menerbitkan
karya lain di mana mereka menggambarkan cara untuk melindungi jaringan dan meningkatkan efisiensi mereka, dan Ian Goodfellow sejak itu telah memberikan saran pada karya ilmiah lain di bidang ini, termasuk
serangan kotak hitam .
Para peneliti menyebut gagasan yang lebih umum tentang informasi yang tidak dapat dipercaya sebagai "data Bizantium," dan berkat kemajuan penelitian, mereka telah belajar mendalam. Istilah ini berasal dari "
tugas para jenderal Bizantium yang terkenal, " sebuah eksperimen pemikiran di bidang ilmu komputer, di mana sekelompok jenderal harus mengoordinasikan tindakan mereka dengan bantuan kurir, tanpa memiliki keyakinan bahwa salah satu dari mereka adalah pengkhianat. Mereka tidak dapat mempercayai informasi yang diterima dari rekan mereka.
“Algoritma ini dirancang untuk menangani noise acak, tetapi bukan data Bizantium,” kata Taigar. Untuk memahami bagaimana serangan seperti itu bekerja, Goodfello menyarankan untuk membayangkan jaringan saraf dalam bentuk diagram dispersi.
Setiap titik dalam diagram mewakili satu piksel gambar yang diproses oleh jaringan saraf. Biasanya, jaringan mencoba menggambar garis melalui data yang paling cocok dengan set semua titik. Dalam praktiknya, ini sedikit lebih rumit, karena piksel yang berbeda memiliki nilai yang berbeda untuk jaringan. Pada kenyataannya, ini adalah grafik multidimensi yang kompleks yang diproses oleh komputer.
Tetapi dalam analogi sederhana kami tentang sebaran, bentuk garis yang ditarik melalui data menentukan apa yang dilihat jaringan yang dilihatnya. Untuk serangan yang berhasil pada sistem seperti itu, peneliti perlu mengubah hanya sebagian kecil dari poin-poin ini, dan membuat jaringan membuat keputusan yang sebenarnya tidak ada. Dalam contoh bus yang terlihat seperti burung unta, foto bus sekolah dihiasi dengan piksel yang diatur sesuai dengan pola yang terkait dengan karakteristik unik foto burung unta yang akrab dengan jaringan. Ini adalah kontur yang tidak terlihat oleh mata, tetapi ketika algoritma
memproses dan menyederhanakan data , titik data ekstrim untuk burung unta tampaknya merupakan pilihan klasifikasi yang sesuai. Dalam versi kotak hitam, para peneliti menguji bekerja dengan input data yang berbeda untuk menentukan bagaimana algoritma melihat objek tertentu.
Dengan memberikan input palsu classifier objek dan mempelajari keputusan yang dibuat oleh mesin, para peneliti dapat mengembalikan algoritma untuk menipu sistem pengenalan gambar. Secara potensial, sistem seperti itu dalam robomobiles dalam hal ini dapat melihat tanda “beri jalan” alih-alih tanda berhenti. Ketika mereka mengerti bagaimana jaringan bekerja, mereka dapat membuat mesin melihat apa pun.
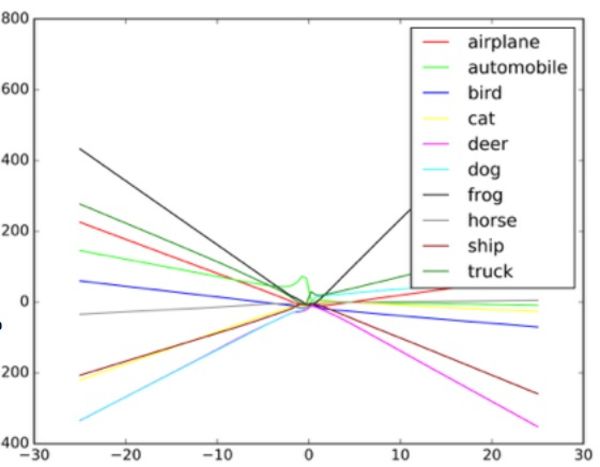 Contoh bagaimana penggolong gambar menggambar garis yang berbeda tergantung pada objek yang berbeda dalam gambar. Contoh palsu dapat dianggap sebagai nilai ekstrem pada grafik.
Contoh bagaimana penggolong gambar menggambar garis yang berbeda tergantung pada objek yang berbeda dalam gambar. Contoh palsu dapat dianggap sebagai nilai ekstrem pada grafik.Para peneliti mengatakan bahwa serangan semacam itu dapat dimasukkan langsung ke dalam sistem pemrosesan gambar, melewati kamera, atau manipulasi ini dapat dilakukan dengan tanda nyata.
Tetapi spesialis keselamatan di Universitas Columbia, Alison Bishop, mengatakan bahwa perkiraan seperti itu tidak realistis, dan tergantung pada sistem yang digunakan dalam robomobile. Jika penyerang sudah memiliki akses ke aliran data dari kamera, mereka sudah dapat memberikan input apa pun.
"Jika mereka bisa sampai ke pintu masuk kamera, kesulitan seperti itu tidak diperlukan," katanya. "Kamu bisa menunjukkan padanya tanda berhenti."
Metode serangan lain, selain melewati kamera - misalnya, menggambar tanda visual pada tanda nyata, bagi Bishop tampaknya tidak mungkin. Dia ragu bahwa kamera beresolusi rendah yang digunakan pada robomobiles umumnya akan dapat membedakan antara perubahan kecil pada tanda.
 Gambar murni di sebelah kiri diklasifikasikan sebagai bus sekolah. Diperbaiki di sebelah kanan - seperti burung unta. Di tengah gambar berubah.
Gambar murni di sebelah kiri diklasifikasikan sebagai bus sekolah. Diperbaiki di sebelah kanan - seperti burung unta. Di tengah gambar berubah.Dua kelompok, satu di Universitas Berkeley dan yang lainnya di Universitas Georgetown, telah berhasil mengembangkan algoritma yang dapat mengeluarkan perintah bicara kepada asisten digital seperti Siri dan Google Now, yang terdengar seperti suara yang tidak terdengar. Untuk seseorang, perintah seperti itu akan tampak seperti suara acak, tetapi pada saat yang sama mereka dapat memberikan perintah ke perangkat seperti Alexa, tidak diramalkan oleh pemiliknya.
Nicholas Carlini, salah satu peneliti dalam serangan audio Bizantium, mengatakan bahwa dalam pengujian mereka mereka dapat mengaktifkan program pengenalan audio open source, Siri dan Google Now, dengan akurasi lebih dari 90%.
Suara itu seperti semacam negosiasi alien fiksi ilmiah. Ini adalah campuran white noise dan suara manusia, tetapi sama sekali tidak seperti perintah suara.
Menurut Carlini, dalam serangan seperti itu, siapa pun yang mendengar suara telepon (perlu merencanakan serangan pada iOS dan Android secara terpisah) dapat dipaksa untuk masuk ke halaman web yang juga memutar suara, yang akan menginfeksi ponsel yang berlokasi di dekatnya. Atau halaman ini dapat dengan tenang mengunduh program malware. Mungkin juga suara-suara seperti itu akan hilang di radio, dan mereka akan disembunyikan dalam white noise atau paralel dengan informasi audio lainnya.
Serangan semacam itu dapat terjadi karena mesin dilatih untuk memastikan bahwa hampir semua data berisi data penting, dan juga satu hal lebih umum daripada yang lain, seperti dijelaskan oleh Goodfello.
Untuk menipu jaringan, memaksanya untuk percaya bahwa ia melihat objek yang sama, lebih mudah, karena ia percaya bahwa ia harus melihat objek seperti itu lebih sering. Oleh karena itu, Goodfellow dan kelompok lain dari Universitas Wyoming dapat memperoleh jaringan untuk mengklasifikasikan gambar yang tidak ada sama sekali - mengidentifikasi objek dalam derau putih, yang dibuat secara acak piksel hitam dan putih.
Dalam penelitian Goodfellow, white noise acak yang melewati jaringan diklasifikasikan olehnya sebagai kuda. Secara kebetulan, ini membawa kita kembali ke kisah Pintar Hans, seekor kuda yang tidak terlalu berbakat secara matematis.
Goodfellow mengatakan bahwa jaringan saraf, seperti Smart Hans, tidak benar-benar mempelajari ide, tetapi hanya belajar untuk mencari tahu ketika mereka menemukan ide yang tepat. Perbedaannya kecil tapi penting. Kurangnya pengetahuan mendasar memfasilitasi upaya jahat untuk menciptakan kembali tampilan menemukan hasil algoritma "benar", yang ternyata ternyata salah. Untuk memahami apa itu sesuatu, sebuah mesin juga harus mengerti apa itu bukan.
Goodfello, setelah melatih jaringan menyortir gambar baik pada gambar alami dan gambar yang diproses (palsu), menemukan bahwa ia tidak hanya dapat mengurangi efektivitas serangan tersebut sebesar 90%, tetapi juga membuat jaringan lebih baik dalam mengatasi tugas awal.
"Dengan memungkinkan untuk menjelaskan gambar palsu yang benar-benar tidak biasa, Anda bisa mendapatkan penjelasan yang lebih dapat diandalkan dari konsep yang mendasarinya," kata Goodfellow.
Dua kelompok peneliti audio menggunakan pendekatan yang mirip dengan tim Google, melindungi jaringan saraf mereka dari serangan mereka sendiri dengan berlatih berlebihan. Mereka juga mencapai kesuksesan yang sama, mengurangi efisiensi serangan mereka hingga lebih dari 90%.
Tidak mengherankan bahwa bidang penelitian ini menarik perhatian militer AS. Laboratorium Penelitian Angkatan Darat bahkan mensponsori dua karya terbaru tentang hal ini, termasuk serangan kotak hitam. Dan meskipun agensi mendanai penelitian, ini tidak berarti bahwa teknologi akan digunakan dalam perang. Menurut perwakilan departemen, hingga 10 tahun dapat beralih dari penelitian ke teknologi yang cocok untuk digunakan oleh seorang prajurit.
Ananthram Swami, seorang peneliti di US Army Laboratory, telah terlibat dalam beberapa karya terbaru tentang penipuan AI. Tentara tertarik pada masalah mendeteksi dan menghentikan data penipuan di dunia kita, di mana tidak semua sumber informasi dapat diperiksa dengan cermat. Swami menunjuk ke sekumpulan data yang diperoleh dari sensor publik yang berlokasi di universitas dan bekerja di proyek sumber terbuka.
“Kami tidak selalu mengontrol semua data. Sangat mudah bagi musuh kita untuk menipu kita, ”kata Swami. "Dalam beberapa kasus, konsekuensi dari penipuan semacam itu bisa sembrono, dalam beberapa kasus sebaliknya."
Dia juga mengatakan bahwa tentara tertarik pada robot otonom, tank, dan kendaraan lain, sehingga tujuan penelitian tersebut jelas. Dengan mempelajari masalah-masalah ini, tentara akan dapat memenangkan permulaan dalam mengembangkan sistem yang tidak rentan terhadap serangan semacam ini.
Tetapi setiap kelompok yang menggunakan jaringan saraf harus memiliki kekhawatiran tentang potensi serangan dengan spoofing AI. Pembelajaran mesin dan AI sedang dalam masa pertumbuhan, dan kelemahan keamanan dapat memiliki konsekuensi yang mengerikan saat ini. Banyak perusahaan mempercayai informasi yang sangat sensitif terhadap sistem AI yang belum lulus ujian waktu. Jaringan saraf kita masih terlalu muda bagi kita untuk mengetahui semua yang kita butuhkan tentang mereka.
Kekeliruan serupa membuat
bot Twitter Microsoft, Tay , dengan cepat menjadi rasis dengan kecenderungan genosida. Aliran data berbahaya dan fungsi "repeat after me" menyebabkan fakta bahwa Tay sangat menyimpang dari jalur yang dituju. Bot itu diakali oleh input di bawah standar, dan ini berfungsi sebagai contoh nyaman dari implementasi pembelajaran mesin yang buruk.
Kanchelyan mengatakan dia tidak percaya bahwa kemungkinan serangan seperti itu telah habis setelah penelitian yang berhasil oleh tim Google.
"Di bidang keamanan komputer, penyerang selalu di depan kita," kata Kanchelyan. "Akan agak berbahaya untuk mengklaim bahwa kita telah menyelesaikan semua masalah dengan penipuan jaringan saraf melalui pelatihan berulang mereka."