Saya mulai menulis teks ini sejak lama, jadi itu tidak direncanakan secara politis relevan. Tetapi ternyata pada hari-hari inilah media muncul sebuah panduan informasi yang berkaitan dengan bahasa-bahasa kecil (minoritas) Rusia. Ada kemungkinan bahwa penelitian, yang saya tulis di bawah ini, akan mengklarifikasi sesuatu kepada seseorang dalam pengertian ini.
Berapa banyak bahasa di Rusia?
Ini tidak mudah untuk diwujudkan, tetapi di Rusia mereka berbicara sejumlah bahasa yang mengesankan. Selain itu, di Rusia mereka berbicara bahasa-bahasa seperti itu yang tidak didistribusikan di tempat lain. Katakanlah, jutaan Ukraina dan Uzbek tinggal di Rusia, tetapi pada saat yang sama ada negara berdaulat Ukraina dan Uzbekistan, di mana bahasa yang sesuai adalah resmi. Tetapi di Rusia mereka berbicara Bashkir, Tuvan, Udmurt dan banyak (memang banyak) bahasa lain yang tidak memiliki status negara mereka di tempat lain.
Status negara itu penting. Di era globalisasi, untuk bertahan hidup, bahasa membutuhkan dukungan yang secara positif memengaruhi media cetak, media, seni, dan pada akhirnya keinginan dan kemampuan orang untuk berbicara dalam bahasa asli mereka.
Dan bagaimana bahasa-bahasa ini beradaptasi dengan realitas digital baru? Benarkah mereka hanya berbicara di desa pegunungan terpencil? Atau apakah mereka masih merupakan cara penuh untuk berkomunikasi online? Beberapa tahun yang lalu, saya dan kolega saya memutuskan untuk mencari tahu.
Pada awalnya, ini adalah studi dalam kerangka Pusat Studi Internet dan Masyarakat NES yang sekarang sudah tidak berfungsi (sekarang telah berhasil diubah menjadi Klub Internet dan Pecinta Masyarakat ), kemudian kami mengorganisir proyek penelitian di magistrasi Sekolah Linguistik Sekolah Tinggi Ekonomi , dan, secara umum, berhasil. Semua hasil disajikan di situs web khusus, Bahasa Rusia , tetapi saya akan memberi tahu Anda tentang yang paling menarik, tentang apa yang kami lakukan dan bagaimana (serta apa yang terjadi).
Pertama-tama, perlu menetapkan berapa banyak bahasa secara umum di Rusia, dan bahasa apa itu. Ahli bahasa tidak memiliki daftar yang diterima secara umum: tidak diketahui tentang beberapa bahasa apakah setidaknya satu penutur lain masih hidup, tentang beberapa tidak ada kesepakatan apakah ini bahasa, atau sebenarnya itu adalah dialek dari bahasa lain. Dan tidak ada kriteria yang jelas untuk membedakan satu dari yang lain. Ada sebuah lelucon: "bahasa adalah dialek dengan tentara dan angkatan laut", tetapi dengan semua kecakapan dari pernyataan ini oleh Weinreich, ada cukup contoh tandingan: Brasil memiliki tentara dan angkatan laut, tetapi tidak memiliki bahasa sendiri (orang Brasil menggunakan bahasa Portugis, bahasa bekas kota metropolis mereka), apalagi, Orang Amerika, pemilik pasukan paling kuat di dunia, hanya menggunakan dialek dan bukan bahasa mereka sendiri. Islandia tidak memiliki pasukan atau armada (hanya kapal penjaga pantai), tetapi tidak ada yang melanggar keanehan bahasa mereka (meskipun tidak ada yang berpendapat bahwa ia adalah kerabat Norwegia modern).
Singkatnya, tugas itu tidak mudah. Yang paling sulit adalah bahasa-bahasa Dagestan. Ada begitu banyak bahasa (bahasa nyata, bukan dialek! Operator mereka tidak saling memahami) sehingga Anda dapat mengetahuinya hanya setelah berkonsultasi dengan spesialis.
Kami juga memutuskan untuk memindahkan bahasa judul negara bagian lain di luar daftar kami. Memang, jika seluruh negara di luar Rusia berbicara beberapa bahasa, maka kemungkinan besar sumber daya negara juga digunakan untuk mendukung bahasa tersebut. Dimungkinkan untuk mempertimbangkan bahasa seperti itu sebagai bahasa Rusia, tetapi akan salah untuk mengevaluasi kehadirannya di Internet dibandingkan dengan bahasa lain yang tidak didorong dari luar negeri: Ingush dan Kazakh akan berada dalam kategori bobot yang sangat berbeda. Jadi, Ossetia ternyata berlebihan dalam penelitian kami: terlepas dari kenyataan bahwa di Rusia ada seluruh wilayah tituler tempat Ossetia digunakan, ada juga negara terpisah yang diakui oleh Rusia, Ossetia Selatan, yang bahasa ini resmi. Sebenarnya, di Ossetia Selatan dan Utara mereka berbicara dialek yang berbeda, Besi dan Digor. Tetapi secara otomatis, komputer, untuk membedakannya sangat sulit. Jadi lebih baik menganggap mereka sebagai satu bahasa yang bukan milik kelas bahasa Rusia.
Insiden lain terkait dengan Yiddish. Di Rusia, secara nominal, ada juga wilayah di mana penutur bahasa Yiddish harus hidup - Daerah Otonomi Yahudi. Pada saat yang sama, para ahli kami menjelaskan kepada kami bahwa hampir tidak ada penutur bahasa Yiddish di EAO, dan semua teks di Internet dalam bahasa ini ditulis hampir secara eksklusif di Israel dan Amerika Serikat. Jadi untuk menganalisis representasi Yiddish di Internet sebagai bahasa Rusia itu bodoh. Ini selain fakta bahwa kita akan menghadapi sakit kepala yang terkait dengan berbagai pilihan ejaan. Berikut ini beberapa tautan yang relevan tentang ini: [ 1 ], [ 2 ], [ 3 ].
Jadi, kami memutuskan bahasa. Ada 96 dari mereka.
Daftar lengkap bahasaAbaza
Avar
agul
Adyghe
Aleutian
alutor
amuzgi-shirinsky
andes
Archinsky
ahwah
Bagvalinsky
Bashkir
bezhtinsky
botlikh
Buryat
Vepsian
Verkhneurkunsky
Vodsky
gapshiminsky
ginuhsky
godoberinsky
gunung mari
Gunzib
Izhora
Ingush
Itelmen
Kabardino-Sirkasia
Kadar (mungkin dialek Darginsky)
kaitag
Kalmyk
karatinsky
Karachay-Balkar
Karelian
Ket
Kola Sami
Komi-Zyryansky
Komi-Permyak
Koryak
Kubachi-Ashtinsky
kumyk
Laksky
Lezgi
Nenets Hutan
padang rumput mari timur
Mansi
megeb
moksha-mordovian
muirinsky
Nanai
Nganasan
negidalsky
nivkhsky
Nogai
Orok
rutulsky
sanji itarin
Altai Utara
Yukagir Utara (tundra, vadul)
Severodarginsky (termasuk sastra Darginsky)
Selkup
Soyot-Tsatansky
Tabasaran
tanty-sirkhinsky (mungkin bahasa yang sama dengan Verkhneurkunsky)
Tatar
tat (terancam punah)
tindin
tofalar
tubalar
Tuvinian
tundra nenets
Udine
Udmurt
Udege
Ulchi
usisha-tsudahar
Khakass
Khanty
Khvarshinsky
Tsakhur
cesian
gipsi
chamalinsky
Chechnya
chiraghi
Chuvash
Chukchi
Chulymsky
Shor
Evenki
Bahkan
enetsky
Erzya Mordovian
eskimo
Altai Selatan
Yukagir Selatan (Kolyma, Odul)
Yakut
Bagaimana sekarang mencari mereka di web? Anda dapat mengempiskan seluruh Internet dan mencoba menemukan teks yang diperlukan dalam koleksi yang dihasilkan ... Tapi tunggu, Anda benar-benar tidak dapat mengempiskan seluruh Internet. Artinya, adalah mungkin jika Anda adalah perusahaan IT besar dengan armada server yang sesuai dan tim pengembangan. Dan jika Anda memiliki tim universitas kecil yang Anda inginkan, maka tidak ada yang perlu dipikirkan. Di sisi lain, Anda tidak perlu mengunduh apa pun pada tahap ini, karena mesin telusur telah melewati seluruh jaringan. Anda hanya perlu meminta mesin pencari pertanyaan yang tepat. Benar, mesin pencari tidak suka klik otomatis. Tetapi jika Anda benar-benar bertanya, maka Anda dapat menggunakan, misalnya, Yandex.XML, yang memiliki batasan pada jumlah permintaan, tetapi tetap saja ini tidak sama dengan bekerja dengan hasil pencarian dengan tangan Anda.
Kata-kata penanda
Tetapi apa yang harus ditanyakan? Kata-kata dibutuhkan - ini jelas. Indeks pencarian dibentuk dari kata-kata, jadi Anda harus memilih kata-kata untuk setiap bahasa yang Anda cari yang akan ditemukan dalam bahasa tertentu dan tidak akan cocok dengan komposisi huruf dengan kata apa pun dalam bahasa lain. Dalam arti tertentu, pencarian untuk bahasa Rusia harus lebih sederhana, karena hampir semua bahasa dalam daftar kami memiliki skrip Cyrillic, dan ini adalah kasus yang relatif jarang untuk bahasa dunia, sehingga kemungkinan dua kata yang bertepatan dari bahasa yang berbeda berkurang dengan tajam: akan mungkin untuk membingungkan hanya kata-kata dari bahasa dari ruang pasca-Soviet, dan kata-kata dari beberapa bahasa Oseania tidak akan membuat kebisingan.
Tapi dari mana mendapatkan kata-katanya? Jika kita kembali ke ahli bahasa, mereka akan memberi tahu Anda bahwa ada publikasi lama dan memang layak - Gilyarevsky R. S., Grivnin V. S. Penentu bahasa-bahasa di dunia dengan bahasa tertulis (M., 1961 untuk edisi kedua). Setiap bahasa yang dijelaskan (sekitar 200) memiliki satu halaman, di mana satu templat berisi nama bahasa, dua teks pendek pada mereka, alfabet, fitur utama dan informasi tentang jumlah operator dan afiliasi genetik.
Tampaknya buku untuk tujuan kita sama sekali tidak berguna, tetapi pada halaman 259 ada bagian tambahan, "Kombinasi Khas dan Kata-Kata Layanan dari Beberapa Bahasa". Tampaknya inilah yang Anda butuhkan, tetapi sayangnya, kata-kata yang dikutip di sana sangat pendek dan dalam komposisi huruf bertepatan dengan kata-kata dari bahasa Rusia. Misalnya, untuk Balkar itu adalah kata "bla", yang ketika mencari akan menghasilkan jumlah sampah yang sangat besar yang tidak sesuai sama sekali dengan bahasa Balkar (tidak hanya bla bla, tetapi juga " kendaraan udara tak berawak "), dan untuk gunung Mari - "don" ( pencarian akan lebih buruk). Yah, sama saja, kata-kata di bagian ini agak jarang. Dan dengan kombinasi huruf di Yandex Anda tidak akan melihat.
Jadi ahli bahasa akan mengusulkan untuk melakukannya. Ilmuwan komputer tentu punya solusi berbeda. Mengapa tidak menggunakan Wikipedia (lagipula, ada Wikipedia dalam bahasa orang-orang Rusia), buat buku frekuensi darinya, lintas kamus, temukan token unik dengan cara ini, dan gunakan untuk permintaan pencarian? Sayangnya, ini tidak akan berhasil. Pertama, Wikipedia bukan untuk semua bahasa Rusia. Hanya ada 22 bagian Wikipedia "asli", bukan dari inkubator. Inkubator menambahkan 41 lebih. Tapi biasanya itu maksimum beberapa lusin teks yang sangat singkat, yaitu, mereka tidak akan menghasilkan hasil yang signifikan secara statistik. Berikut adalah inkubator dengan Tabasaran Wikipedia (5 artikel). Berikut ini adalah inkubator Nogai (23 artikel). Apalagi dalam beberapa tidak ada teks sama sekali, tetapi artikel di sana tentang Bashkirs . Dan sebagainya.
Tetapi Wikipedia (non-inkubasi) nyata tidak dapat berfungsi sebagai sumber yang baik. Karena mereka ... tidak ditulis oleh orang-orang! Wikipedia terbesar dalam bahasa orang-orang Rusia menderita dari apa yang oleh orang-orang Wikipedia disebut " arachnophilia ." yaitu, pengisian otomatis bagian dengan artikel yang dihasilkan oleh template di mana beberapa data numerik dari database terbuka atau registri dimasukkan. Katakanlah, Wikipedia Bashkir dan Tatar untuk persentase yang sangat kecil dari "manusia", ada puluhan ribu artikel otomatis tentang sungai dan danau. Coba klik tautan " artikel acak " di Wikipedia Bashkir, berapa kali dari 10 yang Anda dapatkan di "artikel non-air" (Anda dapat mencari "sungai" dengan kata kunci "yylkha")? Sekarang situasinya sudah agak membaik, masih ada artikel tentang negara dan permukiman, tetapi lima tahun lalu ada topik “air” di 8 kasus dari 10. Saya mengklik sekarang, ternyata 7: 3 mendukung sungai. Bagaimana dengan kamu?
Semuanya akan baik-baik saja, tetapi kata-kata frekuensi dalam teks semacam itu sama sekali bukan kata-kata frekuensi dalam bahasa tersebut. Seperti apa kamus frekuensi "normal" berdasarkan teks yang berasal dari alam? Pasangan pertama dari puluhan posisi ditempati oleh kata-kata resmi yang berbeda, yang berkali-kali lebih umum dalam pidato daripada yang signifikan. Berikut ini adalah kamus frekuensi untuk bahasa Rusia . Kata benda pertama (tahun) muncul di sana pada akhir sepuluh ketiga. Dan sebelum itu, semuanya sepenuhnya - konjungsi, preposisi, kata ganti dan partikel. Dan di sini adalah kamus frekuensi Tatar Wikipedia untuk 2013:
| Tidak. | Bentuk kata | Terjemahan / Arti | Kejadian |
|---|
| 1 | Elga | sungai | 132567 |
| 2 | kolam renang | kolam renang | 75706 |
| 3 | sous | air | 54689 |
| 4 | buencha | oleh | 48838 |
| 5 | Rusia | Rusia | 48722 |
| 6 | urnashkan | terletak | 38043 |
| 7 | Km | kilometer | 36962 |
| 8 | Һәm | dan | 27231 |
| 9 | keche | kecil | 27203 |
| 10 | d .lәt | negara | 26888 |
Hanya ada dua kata resmi, di mana hanya satu - “ m “dan” - yang sangat sering ditemukan dalam teks asli. Selebihnya, tentu saja, dimasukkan dalam daftar hanya karena spesifik dari sampel asli.
Hanya ada satu jalan keluar bagi kami: untuk mengumpulkan kata-kata untuk mendefinisikan permintaan pencarian secara manual untuk setiap bahasa. Ini adalah pekerjaan ahli, Anda perlu mencari di kamus dan tata bahasa, kemudian mengarahkan kata-kata kandidat ke dalam pencarian dan melihat hasilnya dan mengevaluasi berapa banyak sampah yang keluar. Selain itu, setiap kata harus memenuhi dua kriteria wajib. Pertama, itu harus frekuensi untuk bahasa Anda. Oleh karena itu, Tatar Һәm “dan” akan cocok. Memang, kata ini ada di sebagian besar teks dalam bahasa Tatar, dan permintaan yang berisi kata ini akan memungkinkan kami untuk menerima dan karenanya menangkap sebagian besar situs yang memiliki teks dalam bahasa Tatar. Kedua, kata seperti itu harus unik, yaitu, hanya digunakan dalam bahasa ini, tetapi tidak dalam bahasa lain. Dari sudut pandang ini, Um , sayang, "terbang", karena kata yang persis sama di Bashkir.
Ada satu lagi nuansa. Dalam alfabet bahasa nasional ada banyak karakter "khusus", yaitu, huruf yang tidak ada dalam alfabet bahasa Rusia, menggunakan karakter ini (seperti kata ahli bahasa, "grapheme"), suara khusus (seperti kata ahli bahasa, "fonem") dari bahasa-bahasa ini direkam. Sebagai contoh, kata Komi-Zyryan tashtöm mengandung simbol seperti itu, jauh dari yang paling eksotis dari yang bisa (contoh lain dapat dilihat dalam daftar kata "air" Tatar di atas).
Faktanya adalah karena semua kemewahan grafis ini tidak ada pada keyboard Rusia standar, di mana semua orang pada dasarnya mengetik, sehingga pengguna sebenarnya tidak benar-benar memasukkan huruf-huruf ini, menggantinya dengan yang lain yang sama dalam ejaan atau suara. Kata tashtöm diterjemahkan sebagai tashtem atau tashtom. Di Bashkir, huruf "ә" dikirim sebagai "e" atau "a", dan huruf "ҙ" sebagai "z". Di sini, di KDPV, hanya kata "menan" yang seharusnya ditulis "menen." Mengikuti ahli bahasa A. A. Zaliznyak, kami menyebut rezim pengejaan seperti itu "sistem penulisan sehari-hari." Tentang proses yang sama (hanya tanpa keyboard dan perangkat lunak lain) Zaliznyak dijelaskan untuk dialek Novgorod Lama yang direkam pada huruf kulit kayu birch.
Apa artinya ini dalam praktik? Idealnya, tidak hanya kata-kata penanda diperlukan yang unik untuk bahasa ini dan frekuensi dalam bahasa ini. Kata-kata seperti itu juga diperlukan agar tidak mengandung "karakter khusus" ini. Karena pada kenyataannya, karakter seperti itu tidak ditulis oleh semua, dan jika Anda mengirim permintaan ke mesin pencari dengan kata dalam jadwal "benar", maka kelengkapan jawabannya akan berubah menjadi begitu-begitu: kita tidak akan menemukan sejumlah besar teks yang ditulis dalam sistem rumah.
Selain itu, ada simbol yang lebih licik, misalnya, "Aku": "tongkat Yakovlev" (dalam bahasa Kaukasia yang berbeda itu berarti busur laring atau apa yang disebut "kasar" suara). Seringkali dalam sistem rumah tangga diganti dengan unit, tetapi kebetulan mereka juga menulis simbol "|", sebuah bar vertikal, yang digunakan sebagai operator pencarian "atau" (mencari halaman yang mengandung kata-kata yang terkait dengan operator ini.).
Singkatnya, itu tidak mudah. Tetapi kami membuat daftar kata penanda seperti itu untuk sebagian besar bahasa yang kami minati. Dan ini adalah satu-satunya hal yang tidak kami posting secara publik, karena kata-kata seperti itu masih dapat berguna untuk mencari teks, dan daftar ini sangat mudah dirusak, misalnya, jika seseorang ingin menggunakannya untuk menghasilkan spam pencarian.
Cari
Jadi, kami memiliki istilah pencarian, kami mengirimkannya pada gilirannya ke Yandex.XML dan kami mendapatkan hasilnya. Di sini juga tidak begitu sederhana. Pertama, Yandex.XML membatasi selera kita hingga 10.000 permintaan per hari. Tidak terlalu kecil? Ya, tetapi ia memberikan tautan halaman demi halaman (10 per halaman) dan transisi ke halaman berikutnya dianggap sebagai permintaan terpisah ...
Selain itu, kami masih mendapatkan sampah di output. Bahkan untuk spidol "baik". Apa yang kita miliki Cermin dan ganda. Terutama banyak yang dibutuhkan Wikipedia. Dan mengapa kita harus mempertimbangkan Wikipedia jika tujuan kita adalah mengumpulkan semua teks dalam bahasa tertentu? Lagipula, Wikipedia dapat diunduh dengan satu klik! Apa lagi Artikel ilmiah linguistik. Beberapa ahli bahasa menulis artikel dalam bahasa Rusia dan memberikan contoh kalimat dalam beberapa rutulian, dan kalimat ini berisi kata penanda kami. Ini juga tidak baik, karena sebelum kita sebenarnya adalah teks dalam bahasa Rusia. Atau bisa juga berupa kamus. Akan ada kata yang kami cari, tetapi tidak ada teks. Yang mengejutkan bagi kami adalah situs musik. Mereka berisi mp3 dari banyak lagu-lagu rakyat atau hak cipta dalam bahasa kecil. Tidak ada teks di sana, tetapi ada frasa pendek yang cocok untuk permintaan - nama-nama karya musik. Untuk beberapa bahasa, situs ini sangat banyak sehingga menyumbat seluruh output. Kami memutuskan bahwa karena kami mencari teks, ini juga bukan klien kami.
Sesuatu harus dipotong. Filter pertama dapat dimasukkan pada tahap menghubungi mesin pencari. Jika kami memiliki beberapa penanda untuk bahasa tersebut, kemudian setelah menangkap beberapa domain di bagian bawah, kami dapat menanyakan mesin pencari apakah ada kata lain dari daftar kami di situs yang sama. Jika demikian, maka kemungkinan besar kita sampai ke situs yang kita butuhkan. Jika satu penanda ada di sana, tetapi sisanya tidak terwakili, maka kita sangat mungkin memegang boneka di tangan kita. Misalnya, ada kata Khakass yang indah "sinus" ("lagi"). Memenuhi semua kriteria untuk kata penanda yang tercantum di atas. Tapi ini masalahnya. Ketika mereka menulis dalam bahasa Rusia, kadang-kadang mereka membuat kesalahan dan mengetik "sinus" alih-alih "sinus" (hidung). Filter kami akan membantu untuk memahami apakah kesalahan ketik ada dalam teks Rusia, atau memang teks Khakass. Masalahnya adalah ini adalah permintaan tambahan, yang jumlahnya sangat sedikit.
Tidak semuanya jelas dengan daftar situs di mana teks-teks yang kita butuhkan ditemukan. Jika kita berencana untuk tidak hanya menemukan situs-situs ini, tetapi juga untuk memompa mereka untuk membentuk corpus, maka kita perlu mengetahui kedalaman pemompaan yang harus dilakukan. Kami membagi semua domain yang ditemukan ke dalam tiga kategori (semua ini juga dapat ditemukan dengan menanyakan pertanyaan Yandex yang benar).
, ( — ) .
, ( ) .
, . Youtube ( - «» ) stihi.ru ( , , ).
, , VK.com. , , , , ( ), , , -, . , , . .
VK.com . : - , - , vk.com. 2016 , .
. . , . Scrapy , . VK API .
. , . , , . , , , , - . ( — , ngram) . - , , , . , . .
, - . , , , . — ( , ), — . . . - «» . , , , . , , .
, , , .
Hasil
, . . ?
, . , , , . «» . .
- . ? , , - ?
, ( ) .
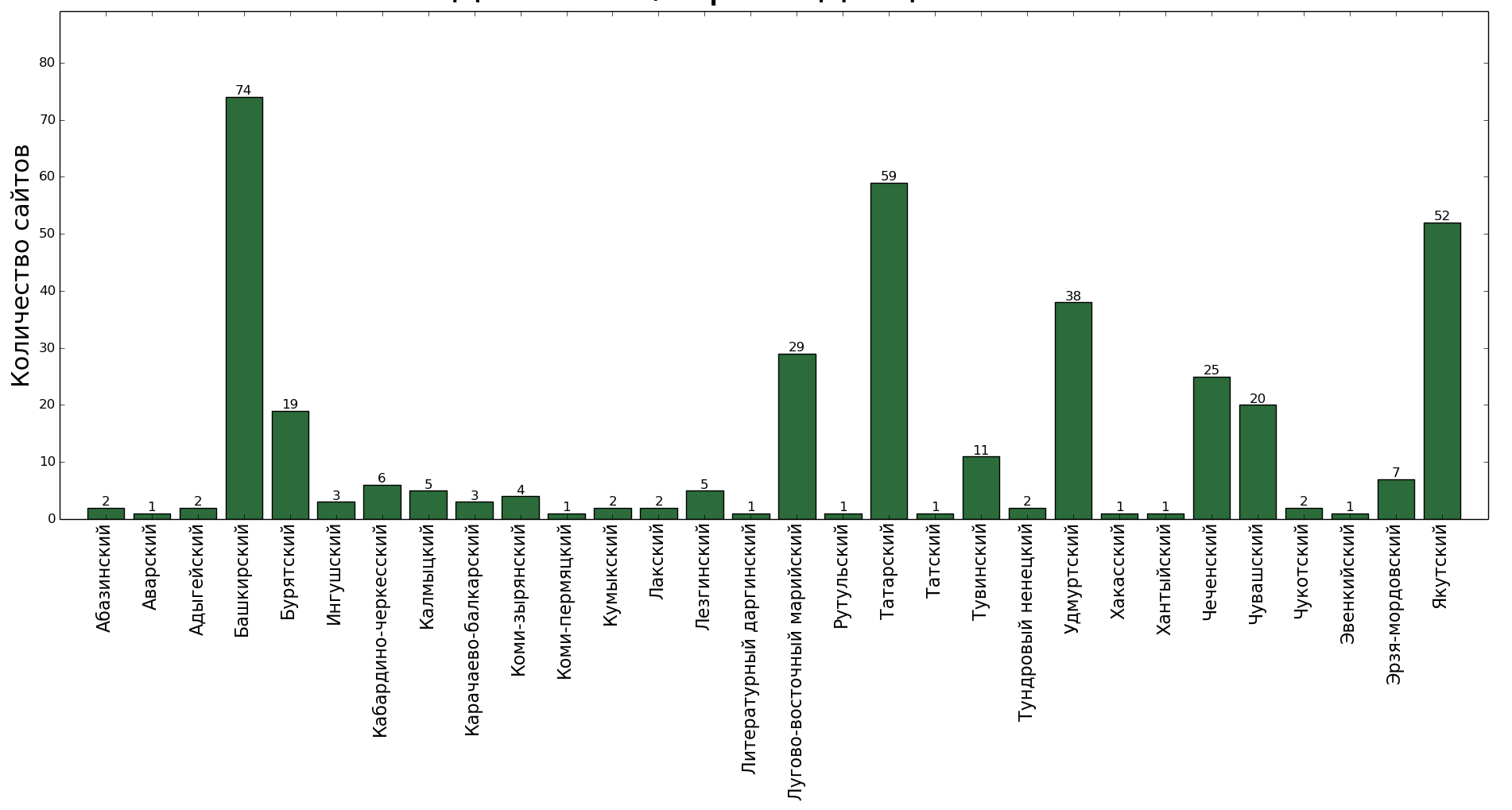
? — ?
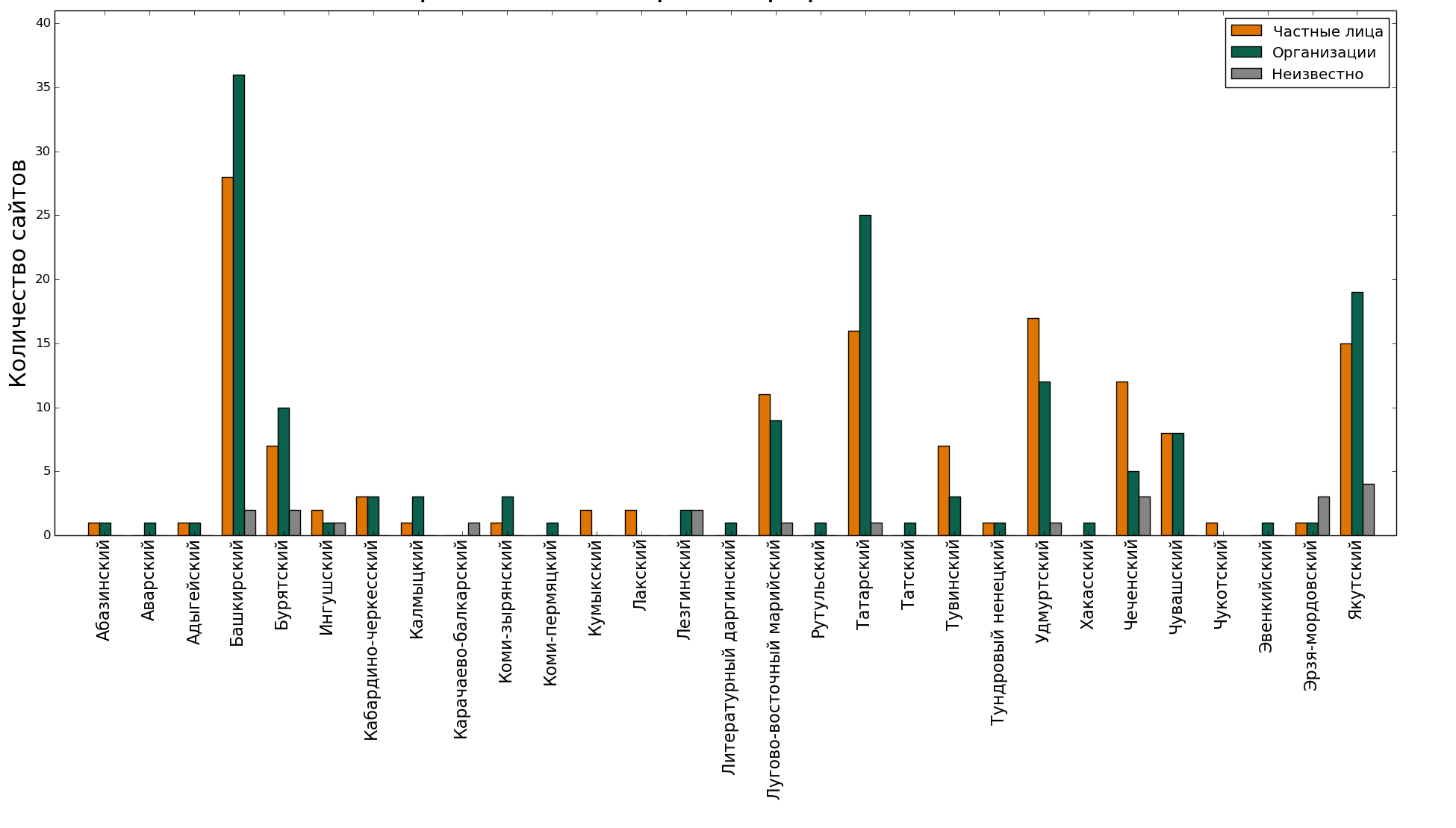
, - , .
?
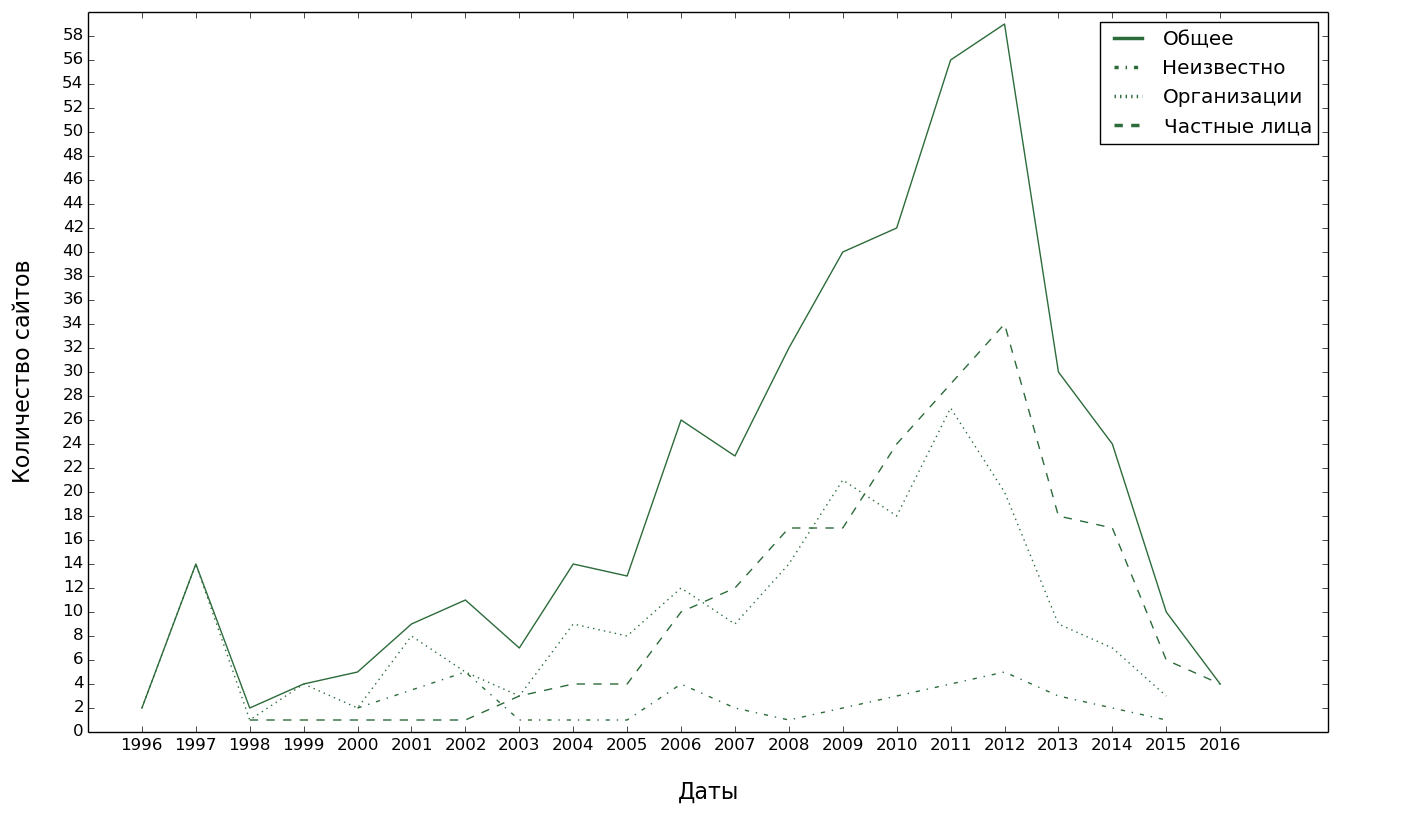
, , 2012 . Mengapa , . , vk.com.
. : , ( , ). ( , , , - , ). ? ?
, - ( 0.7), - . , , , . , , , . , , . , , .
, . ? , , , , .
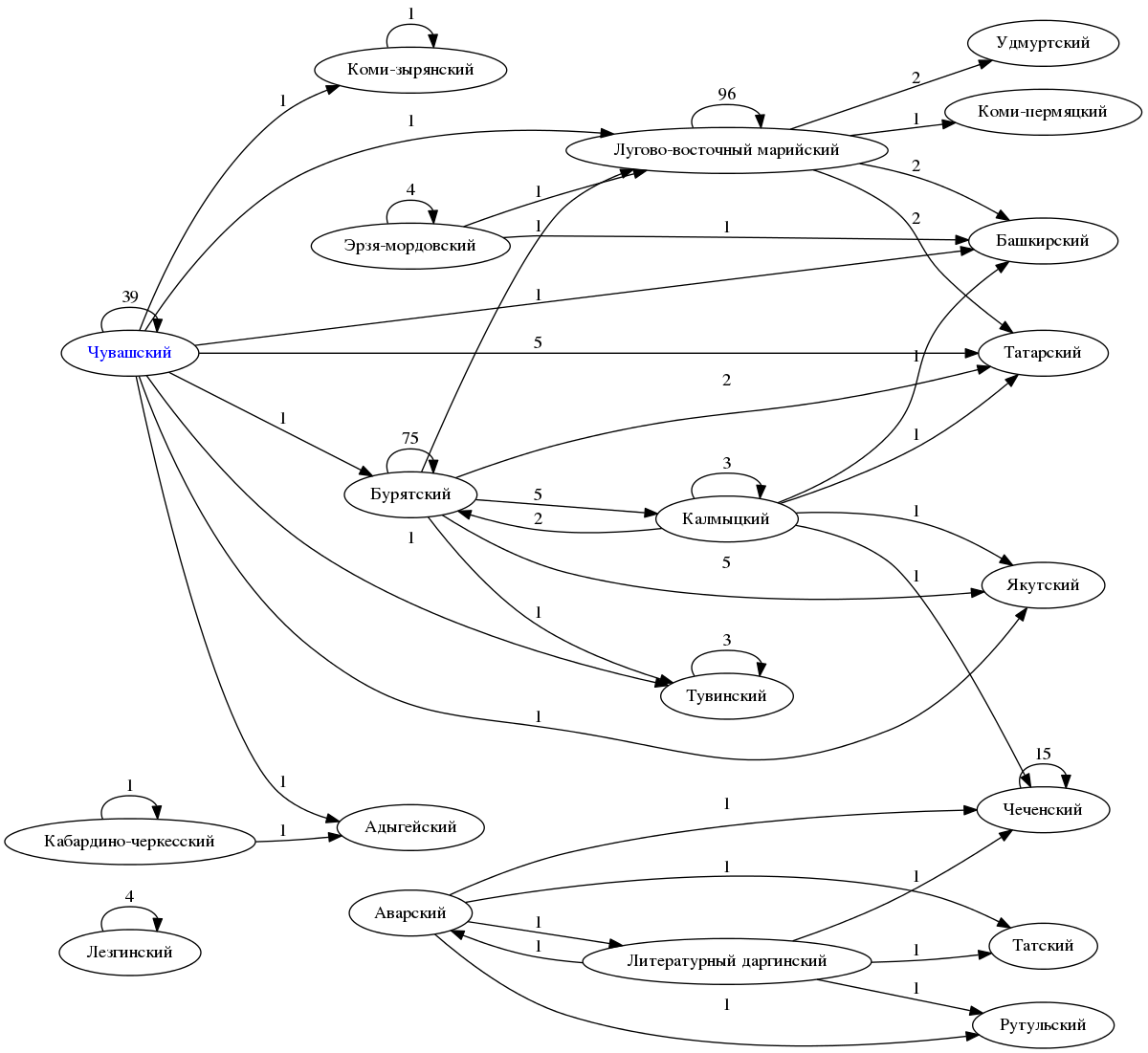
- "", , , . , : , , , . , , , .
, . , , , , , .
, -, ?
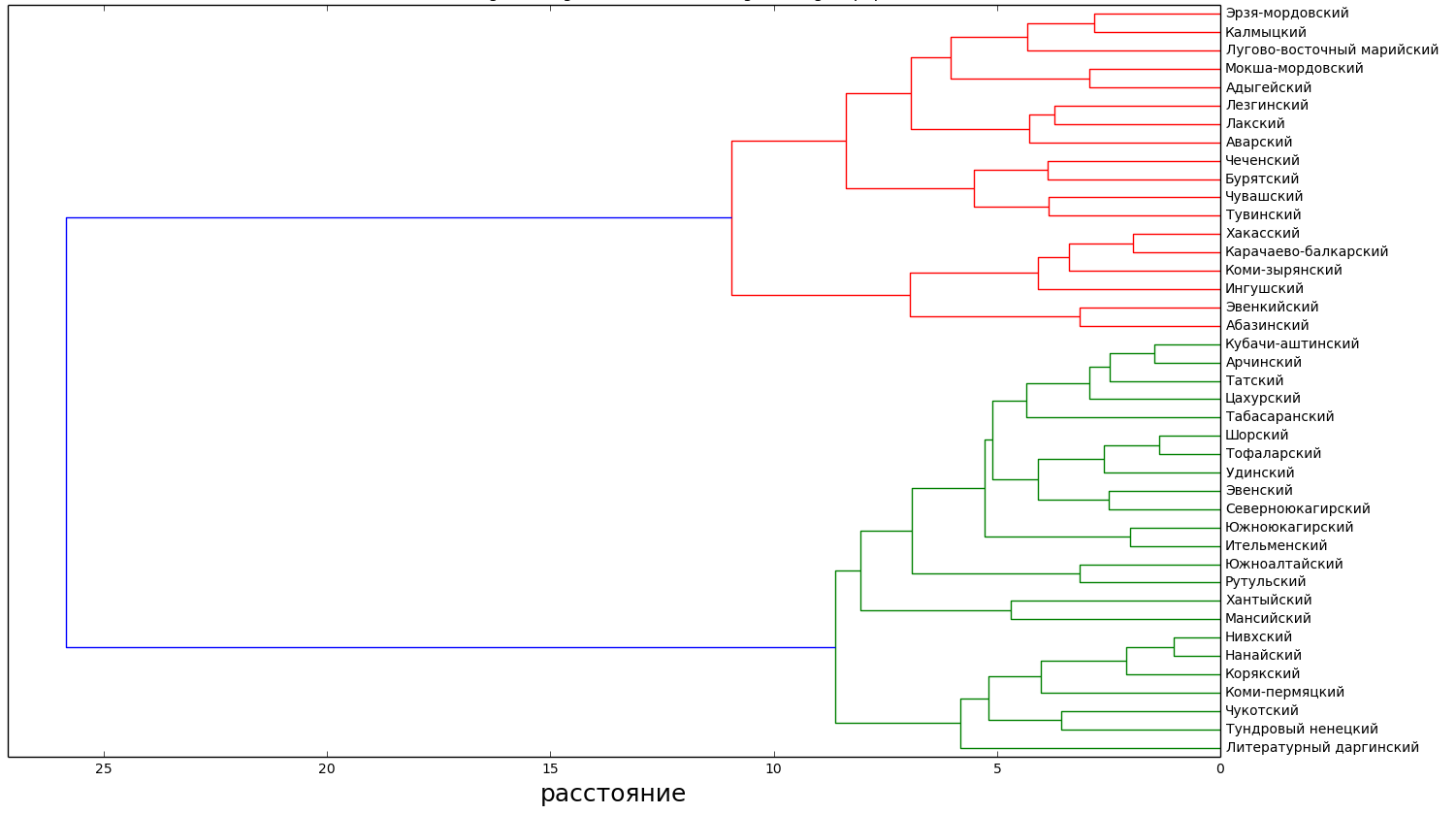
, , : - , , - , , .
Jejaring sosial
, vk.com. - , - , : , . . .
:
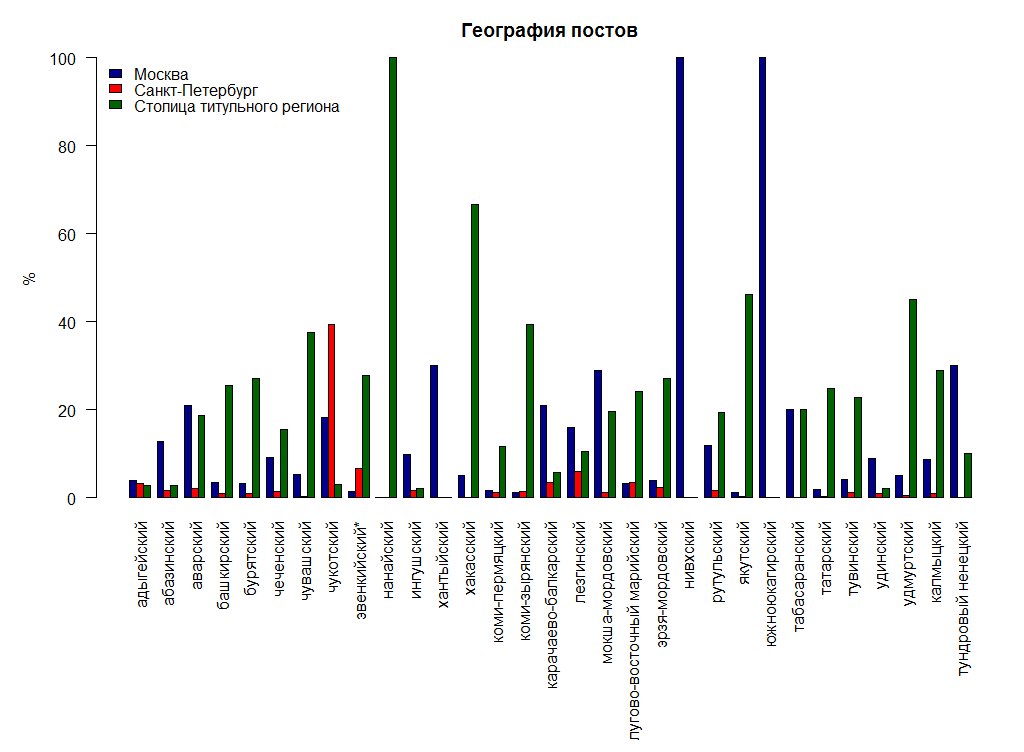
, , , , — . , — . , , . . , .
- ?
, «» :
?
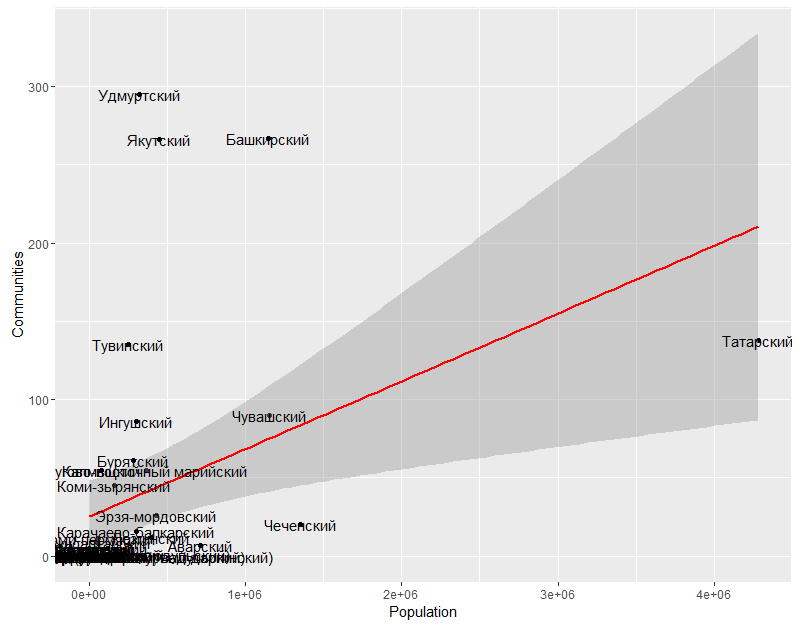
- . , , . , , . , 90- 2000-.
Jadi, kami belajar bahwa ada bahasa kecil Rusia di Internet. Mereka hidup di situs dan di jejaring sosial, dan sejak 2012, terutama di jejaring sosial. Baik di sana maupun di sana mereka dipaksa untuk bertahan dalam persaingan sengit dengan bahasa Rusia "bergengsi". Vitalitas bahasa di Internet tidak banyak bergantung pada seberapa banyak ia berbicara bahasa itu “dalam kehidupan”. Yang paling penting adalah apakah telah mengembangkan komunitas jaringan aktif di sekitar bahasa ini, yang beroperasi di situs Internet bergengsi (Wikipedia, Vkontakte). Jika itu terjadi, maka itu terjadi "di tanah" di wilayah tempat penutur asli bahasa ini tinggal.
Tetapi apakah bahasa kecil akan bertahan dalam situasi globalisasi, kita masih harus belajar selama hidup kita.
Semua kode proyek ada di repositori . Semua koleksi teks dan daftar domain dan komunitas tersedia untuk diunduh .
Dan saya tidak bisa merekomendasikan komunitas di vk.com dengan meme lucu dalam bahasa kecil dengan kucing .