Terjemahan mesin dengan bantuan jaringan saraf telah
jauh dari saat penelitian ilmiah pertama tentang topik ini sampai saat ketika Google mengumumkan
transfer lengkap layanan Google Translate ke pembelajaran yang mendalam .
Seperti yang Anda ketahui, dasar dari penerjemah saraf adalah mekanisme Bidirectional Recurrent Neural Networks, dibangun berdasarkan perhitungan matriks, yang memungkinkan Anda untuk membangun model probabilistik yang jauh lebih kompleks daripada penerjemah mesin statistik. Namun, selalu diyakini bahwa terjemahan saraf, seperti terjemahan statistik, membutuhkan teks bilingual paralel untuk pelatihan. Jaringan saraf sedang dilatih di gedung-gedung ini, mengambil terjemahan manusia sebagai referensi.
Ternyata sekarang, jaringan saraf mampu menguasai bahasa baru untuk terjemahan bahkan tanpa corpus paralel teks!
Dua karya mengenai hal ini diterbitkan di situs pracetak arXiv.org.
"Bayangkan bahwa Anda memberi seseorang banyak buku Tiongkok dan banyak buku Arab - tidak ada buku yang identik di antara mereka - dan orang ini sedang belajar menerjemahkan dari Cina ke Arab. Sepertinya tidak mungkin, kan? Tetapi kami menunjukkan bahwa komputer mampu melakukan ini, ”
kata Mikel Artetxe, seorang ilmuwan komputer di Universitas Negara Basque di San Sebastian (Spanyol).
Sebagian besar jaringan saraf terjemahan mesin diajarkan "dengan seorang guru", yang perannya justru merupakan kumpulan teks paralel yang diterjemahkan oleh manusia. Dalam proses pembelajaran, secara kasar, jaringan saraf membuat asumsi, memeriksa standar, dan membuat pengaturan yang diperlukan dalam sistemnya, kemudian belajar lebih lanjut. Masalahnya adalah bahwa untuk beberapa bahasa di dunia tidak ada banyak teks paralel, oleh karena itu mereka tidak tersedia untuk jaringan saraf terjemahan mesin tradisional.
Dua model baru menawarkan pendekatan baru: mengajar jaringan saraf terjemahan mesin
tanpa guru . Sistem itu sendiri sedang mencoba untuk membuat semacam kumpulan teks paralel, mengelompokkan kata-kata di sekitar satu sama lain. Faktanya adalah bahwa di sebagian besar bahasa di dunia ada makna yang sama, yang hanya sesuai dengan kata-kata yang berbeda. Jadi, semua makna ini dikelompokkan ke dalam kelompok yang identik, yaitu makna kata yang sama dikelompokkan di sekitar makna kata yang sama, hampir terlepas dari bahasanya (lihat artikel “
Jaringan Terjemahan Google Terjemahan Disusun Pangkalan Terpadu dari Makna Kata-kata Manusia ”) .
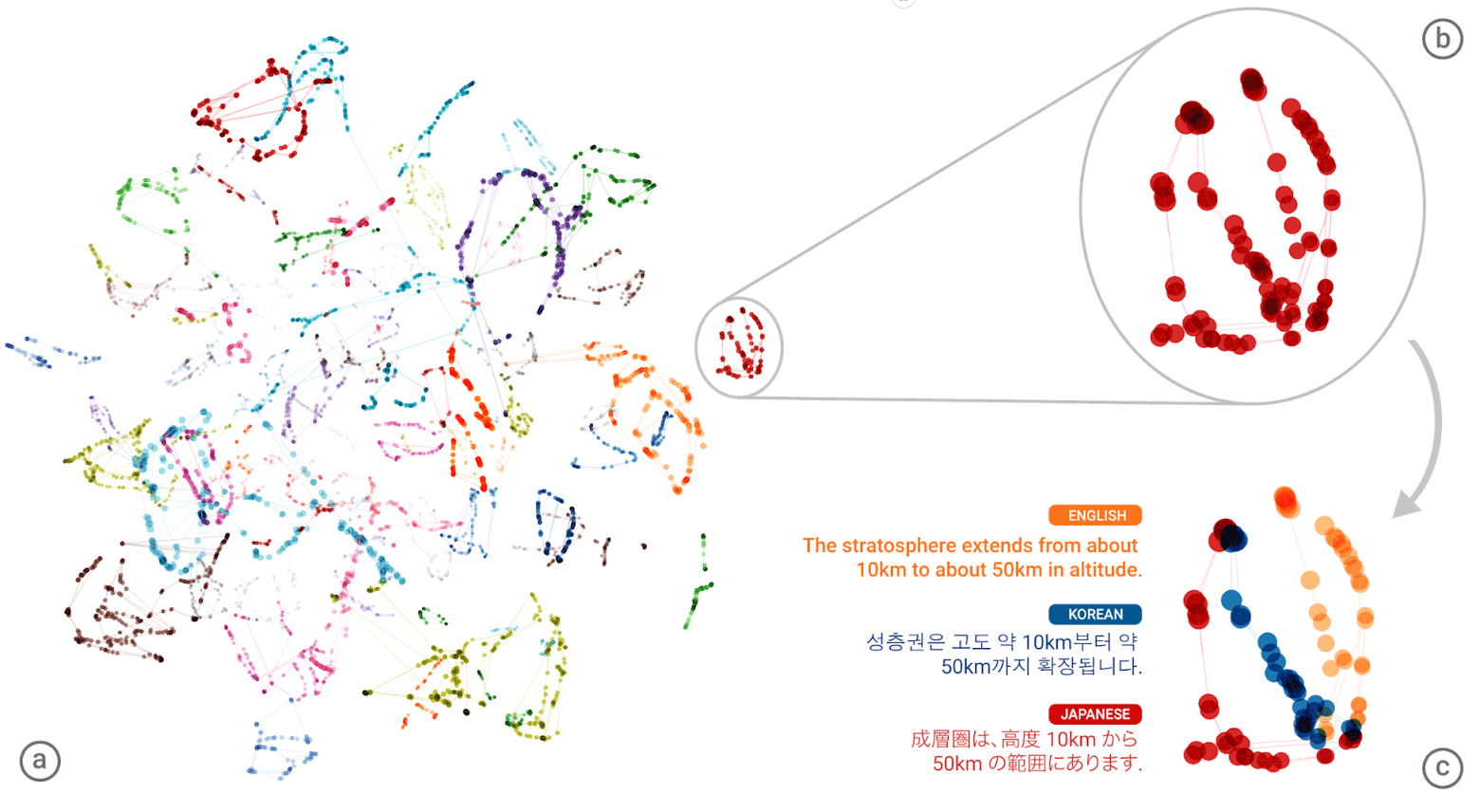 “Bahasa universal” dari jaringan saraf Google Neural Machine Translation (GNMT). Kumpulan makna setiap kata ditampilkan dalam warna berbeda pada ilustrasi kiri, dan makna kata yang diperoleh dari berbagai bahasa manusia: Inggris, Korea, dan Jepang
“Bahasa universal” dari jaringan saraf Google Neural Machine Translation (GNMT). Kumpulan makna setiap kata ditampilkan dalam warna berbeda pada ilustrasi kiri, dan makna kata yang diperoleh dari berbagai bahasa manusia: Inggris, Korea, dan JepangSetelah mengompilasi "atlas" raksasa untuk setiap bahasa, maka sistem mencoba untuk melapisi satu atlas tersebut pada yang lain - dan di sinilah Anda, Anda siap untuk memiliki semacam corpus teks paralel!
Anda dapat membandingkan pola dari dua arsitektur pembelajaran tanpa guru yang diusulkan.
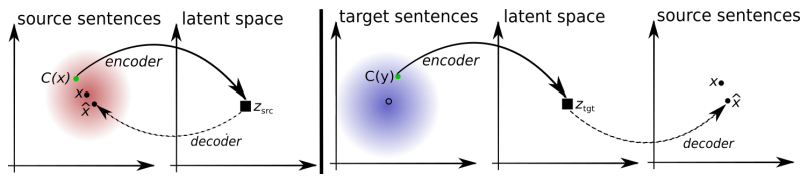
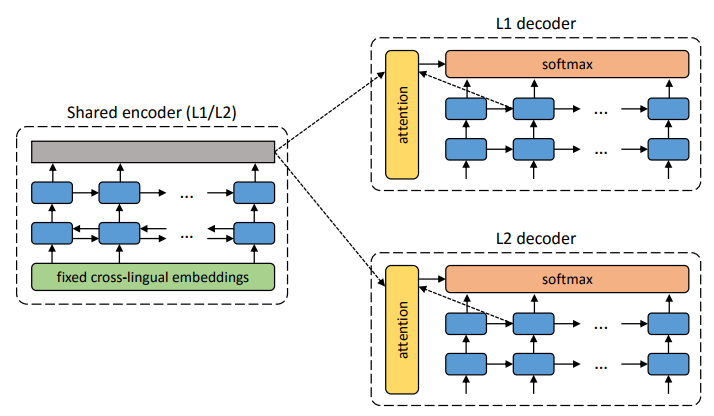 Arsitektur sistem yang diusulkan. Untuk setiap kalimat dalam bahasa L1, sistem mempelajari pergantian dua langkah: 1) denoising , yang mengoptimalkan kemungkinan penyandian versi berisik kalimat dengan encoder umum dan rekonstruksinya dengan decoder L1; 2) terjemahan balik, ketika kalimat diterjemahkan dalam mode keluaran (mis. Dikodekan oleh pengode umum dan diterjemahkan oleh pengurai L2), dan kemudian kemungkinan untuk menyandikan kalimat terjemahan ini dengan pengode umum dan pemulihan kalimat asli oleh pengurai L1 dioptimalkan. Ilustrasi: artikel ilmiah oleh Mikel Artetks et al.
Arsitektur sistem yang diusulkan. Untuk setiap kalimat dalam bahasa L1, sistem mempelajari pergantian dua langkah: 1) denoising , yang mengoptimalkan kemungkinan penyandian versi berisik kalimat dengan encoder umum dan rekonstruksinya dengan decoder L1; 2) terjemahan balik, ketika kalimat diterjemahkan dalam mode keluaran (mis. Dikodekan oleh pengode umum dan diterjemahkan oleh pengurai L2), dan kemudian kemungkinan untuk menyandikan kalimat terjemahan ini dengan pengode umum dan pemulihan kalimat asli oleh pengurai L1 dioptimalkan. Ilustrasi: artikel ilmiah oleh Mikel Artetks et al.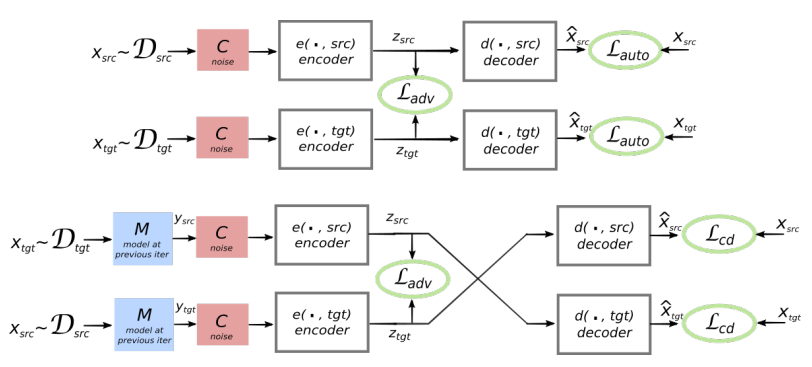 Arsitektur yang diusulkan dan tujuan pembelajaran sistem (dari karya ilmiah kedua). Arsitektur adalah model terjemahan kalimat, tempat encoder dan decoder bekerja dalam dua bahasa, tergantung pada pengidentifikasi bahasa input, yang menukar tabel pencarian. Above (auto-coding): model sedang mempelajari cara melakukan pengurangan noise di setiap domain. Bawah (terjemahan): seperti sebelumnya, ditambah kami kode dari bahasa lain, menggunakan sebagai input terjemahan yang dihasilkan oleh model dalam iterasi sebelumnya (kotak biru). Elips hijau menunjukkan istilah dalam fungsi kerugian. Ilustrasi: artikel ilmiah oleh Guillaume Lampl et al.
Arsitektur yang diusulkan dan tujuan pembelajaran sistem (dari karya ilmiah kedua). Arsitektur adalah model terjemahan kalimat, tempat encoder dan decoder bekerja dalam dua bahasa, tergantung pada pengidentifikasi bahasa input, yang menukar tabel pencarian. Above (auto-coding): model sedang mempelajari cara melakukan pengurangan noise di setiap domain. Bawah (terjemahan): seperti sebelumnya, ditambah kami kode dari bahasa lain, menggunakan sebagai input terjemahan yang dihasilkan oleh model dalam iterasi sebelumnya (kotak biru). Elips hijau menunjukkan istilah dalam fungsi kerugian. Ilustrasi: artikel ilmiah oleh Guillaume Lampl et al.Kedua makalah ilmiah menggunakan teknik yang sangat mirip dengan sedikit perbedaan. Namun dalam kedua kasus, terjemahan dilakukan melalui “bahasa” perantara atau, lebih baik, dimensi perantara atau ruang. Sejauh ini, jaringan saraf tanpa guru menunjukkan kualitas terjemahan yang tidak terlalu tinggi, tetapi penulis mengatakan bahwa mudah untuk meningkatkan jika Anda menggunakan sedikit bantuan dari seorang guru, hanya sekarang demi kemurnian eksperimen yang mereka tidak lakukan.
Perhatikan bahwa karya ilmiah kedua diterbitkan oleh para peneliti dari divisi AI Facebook.
Karya-karya disajikan untuk Konferensi Internasional tentang Representasi Pembelajaran 2018. Belum ada artikel yang dipublikasikan di media ilmiah.