Pada awal November 2017, Qualcomm Datacenter Technologies (QDT) menyelesaikan pekerjaan pada gagasan baru - prosesor berbasis teknologi 10-nm - Centriq 2400. Masa depan apa yang menanti industri sesuai dengan pencipta inovasi ini? Apa manfaat mendapatkan server dan mengapa Centriq 2400 begitu unik? Baca lebih lanjut tentang ini dan lebih banyak lagi.
Pada 8 November, konferensi pers QDT diadakan di San Jose (California), di mana dimulainya pengiriman prosesor baru diumumkan secara resmi. Anand Chandrasekher, Wakil Presiden Senior dan Chief Executive Officer, mengatakan:
Presentasi hari ini adalah pencapaian penting dan puncak dari lebih dari 4 tahun desain, pengembangan, dan dukungan sistem yang rajin ... Kami telah menciptakan prosesor server paling canggih di dunia, yang memberikan kinerja tinggi dikombinasikan dengan tingkat efisiensi energi yang tinggi, memungkinkan pelanggan kami untuk secara signifikan mengurangi biaya mereka.
Selain kebanggaan terang-terangan pada produk mereka, perwakilan perusahaan tidak malu menyatakan bahwa prosesor Centriq 2400 mereka secara signifikan lebih unggul daripada produk pesaing, misalnya Intel Xeon Platinum 8180. Menurut perhitungan mereka, untuk setiap dolar yang dikeluarkan (dan biaya prosesor adalah $ 1995), pengguna akan mendapatkan kinerja dalam 4 kali. Dan ketika dihitung ulang menjadi kinerja dengan 1 watt - sebesar 45% lebih. Pernyataan berani, bagaimanapun, banyak dari perwakilan dari berbagai perusahaan yang tertarik pada produk baru lebih dari senang mendengarnya.
Spesifikasi Teknis Qualcomm Centriq 2400
Arsitektur CPU:- hingga 48 core 64-bit dengan frekuensi puncak 2,6 GHz;
- Kompatibilitas Armv8
- Hanya AArch64;
- Armv8 FP / SIMD;
- Perpanjangan CRC dan Armv8 Crypto;
Cache CPU:- 64 Kb cache instruksi (instruksi) L1 dan 24 Kb cache siklus tunggal L0;
- Cache data 32 Kb L1;
- 512 KB dari total cache L2 untuk setiap 2 core;
- 60 MB cache L3 bersama;
- memfilter permintaan antarprocessor L2;
- QoS;
di mana, L (L1, L2, L3, L0) adalah levelnya, mis. L0 adalah level nol.Teknologi:- Teknologi FinFET 10nm Samsung;
Bandwidth memori:- 6 saluran untuk menghubungkan modul memori DDR4;
- hingga 2667 MT / s per koneksi;
- 128 GB / s - total bandwidth maksimum;
- Kompresi bandwidth built-in
Kapasitas memori:- 768 GB = 128 GB x 6 koneksi;
Jenis memori:- Koneksi DDR4 64-bit dengan ECC 8-bit;
- RDIMM dan LRDIMM;
Antarmuka yang didukung:- GPIO
- I²C;
- SPI
- 8-band SATA Gen 3;
- 32 PCIe Gen3 dengan kemampuan untuk menghubungkan hingga 6 pengendali PCIe;
Selain karakteristik di atas, perlu dicatat bahwa prosesor ini memiliki 18 miliar transistor pada setiap chip. Dan semua intinya dihubungkan oleh bus cincin dua arah. Pada beban maksimum, Centriq 2400 hanya mengkonsumsi 120 watt.
Fokus utama dari prosesor baru ini masih berupa solusi cloud. Menurut perwakilan perusahaan, Centriq 2400 akan memungkinkan Anda untuk membuat sistem server yang akan ditandai dengan kinerja tinggi, efisiensi dan skalabilitas.
Ini tidak dapat gagal untuk menarik banyak perusahaan, teknologi cloud yang hampir menjadi dasar dari kegiatan mereka. Presentasi dihadiri oleh: Alibaba, LinkedIn, Cloudflare, American Megatrends Inc., Arm, Sistem Desain irama, Canonical, Chelsio Communications, Excelero, Hewlett Packard Enterprise, Illumina, MariaDB, Mellanox, Microsoft Azure, MongoDB, Netronome, Packet, Red Hat, ScyllaDB, 6WIND, Samsung, Solarflare, Smartcore, SUSE, Synopsys, Uber, Xilinx. Daftar ini cukup mengesankan, yang menunjukkan peningkatan perhatian pada produk ini.
Saat ini, prosesor Qualcomm Centriq 2400 hanya mendapatkan momentum, baik dalam hal prevalensi maupun popularitas. Yang, tentu saja, akan mengarah pada munculnya sesuatu yang baru, serupa atau bahkan lebih produktif, dari para pesaing QDT.
Tapi tidak semua orang secara membuta percaya pada kesejukan item baru. Jika mereka yang percaya bahwa melakukan tes dan analisis komparatif dari beberapa prosesor akan memungkinkan Anda untuk melihat hasil yang jauh lebih indikatif daripada kata-kata promotor Centriq 2400.
Cloudflare melakukan analisis komparatif dari tiga platform: Grantley (Intel), Purley (Intel) dan Centriq (Qualcomm).
Di bawah ini disajikan grafik analisis ini dan kesimpulan penulisnya -
Vlad Krasnova . (
Asli analisis ini di blog Cloudflare )
Kriptografi Kunci Publik
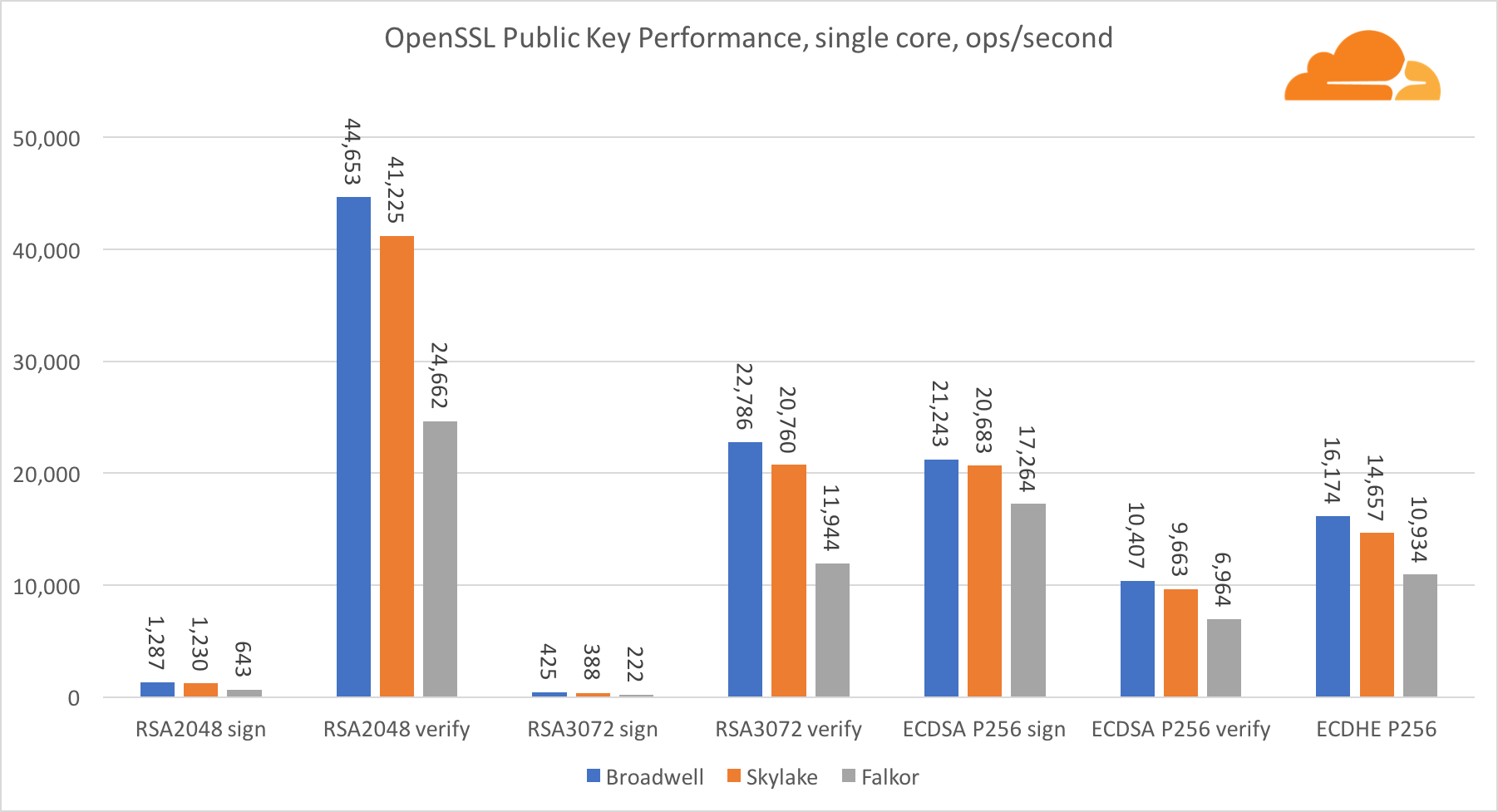
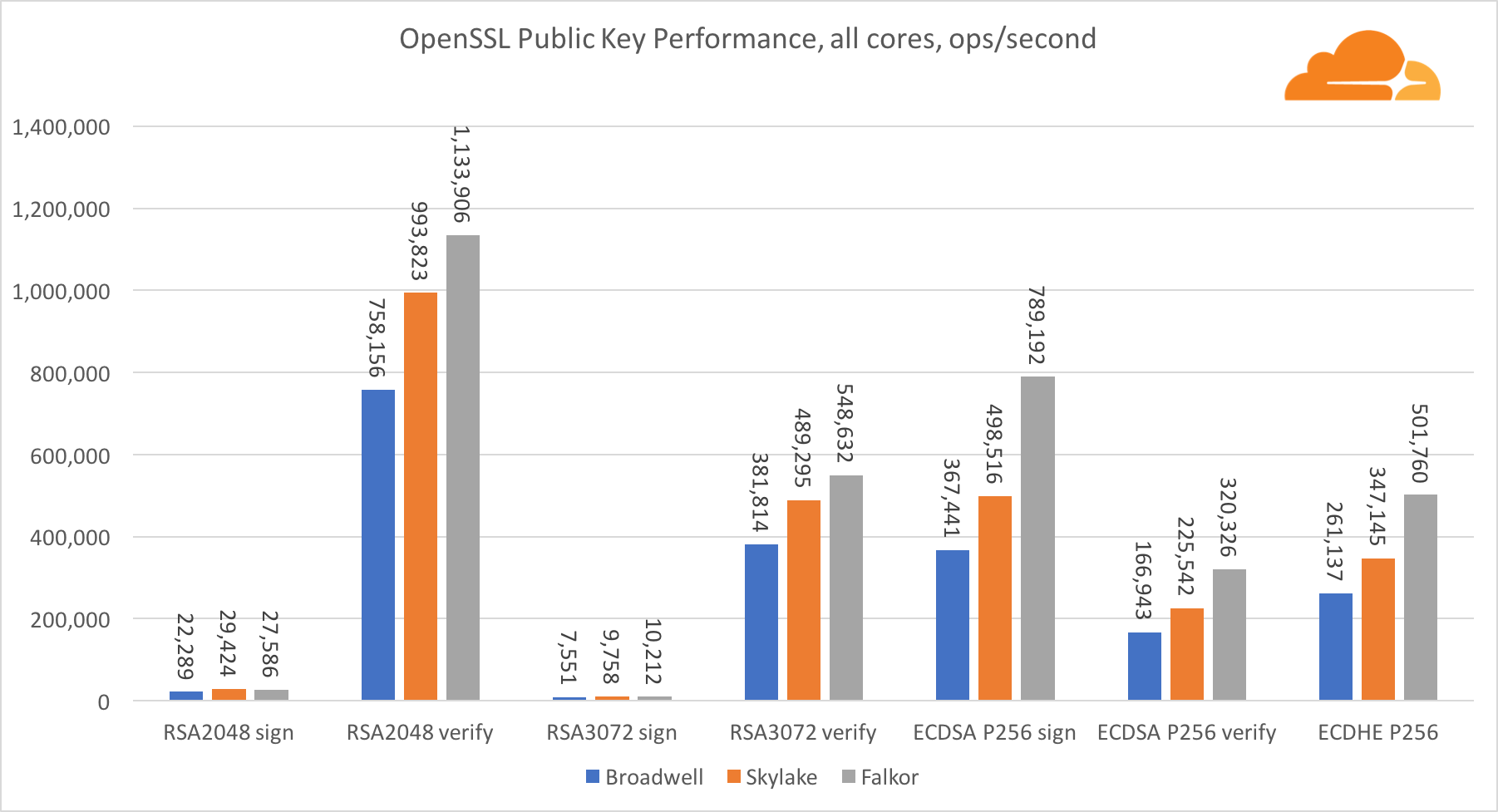
Kriptografi kunci publik adalah kinerja paling murni dari ALU (perangkat logika aritmatika). Sangat menarik, tetapi tidak mengejutkan, bahwa dalam satu tolok ukur dasar, inti Broadwell lebih cepat daripada Skylake, dan keduanya lebih cepat daripada Falkor. Ini karena Broadwell beroperasi pada frekuensi yang lebih tinggi, meskipun dalam hal arsitektur tidak jauh lebih rendah daripada Skylake.
Falkor lebih rendah dari yang lain dalam tes ini. Pertama, mode turbo dihidupkan di salah satu tolok ukur dasar, yang berarti bahwa prosesor Intel beroperasi pada frekuensi yang lebih tinggi. Selain itu, Intel memperkenalkan dua instruksi khusus di Broadwell untuk mempercepat pemrosesan sejumlah besar: ADCX dan ADOX. Mereka melakukan dua operasi add-with-carry independen per siklus, sementara ARM hanya dapat melakukan satu. Demikian pula, set instruksi ARMv8 tidak memiliki perintah tunggal untuk melakukan perkalian 64-bit, sebagai gantinya, sepasang instruksi MUL dan UMULH digunakan.
Namun, di tingkat SoC, Falkor menang. Ini sedikit lebih lambat daripada Skylake dalam hal RSA2048, dan hanya karena RSA2048 tidak memiliki implementasi yang dioptimalkan untuk ARM. Kinerja ECDSA sangat tinggi. Satu chip Centriq dapat memenuhi kebutuhan hampir semua perusahaan di dunia dengan ECDSA.
Juga sangat menarik untuk melihat bahwa Skylake melampaui Broadwell sebesar 30%, terlepas dari kenyataan bahwa Skylake kehilangan satu inti dalam pengujian dan hanya memiliki inti 20% lebih banyak daripada Broadwell. Ini dapat dijelaskan dengan mode turbo yang lebih efisien dan peningkatan hyper-threading.
Kriptografi Simetris
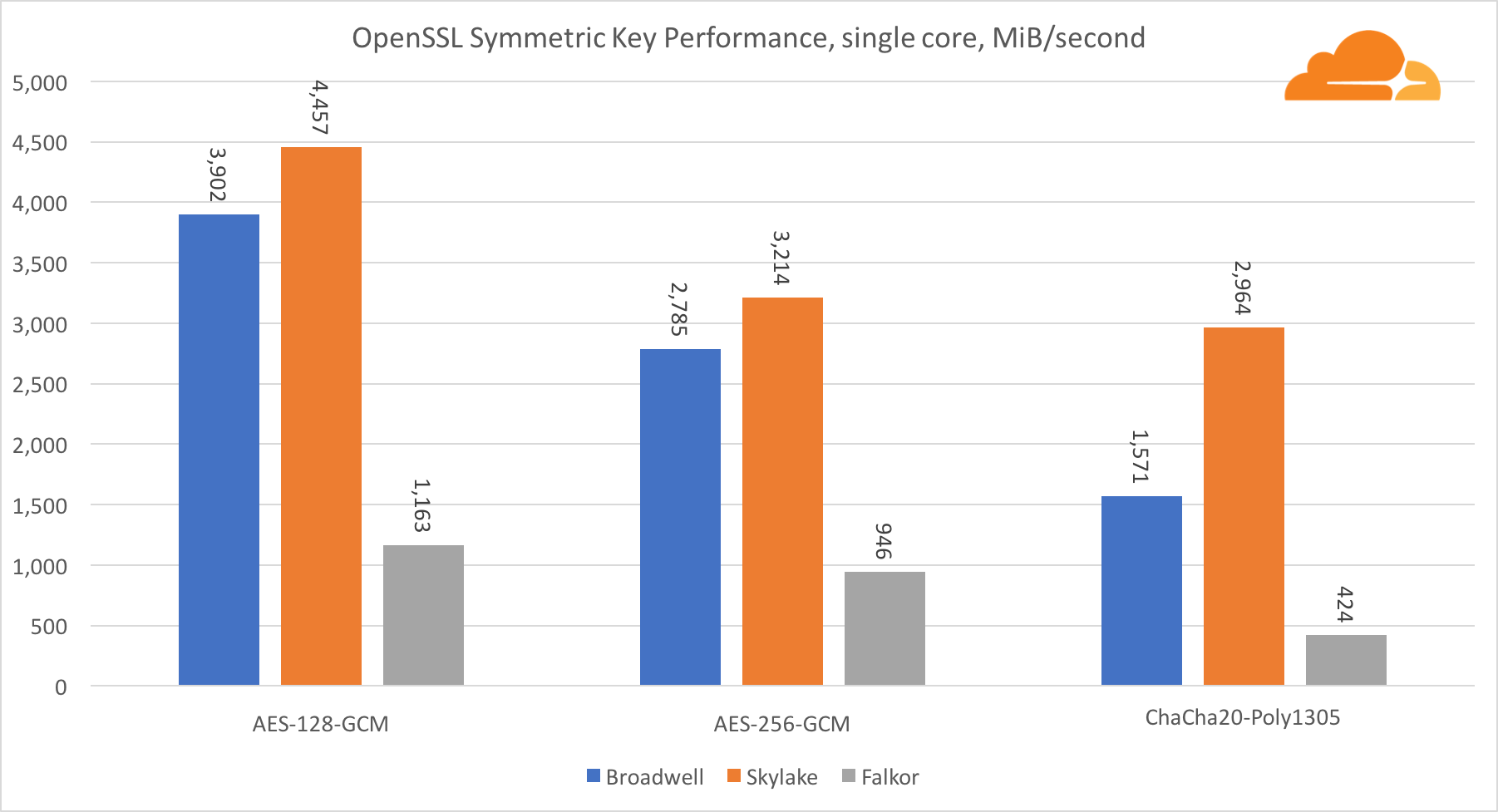
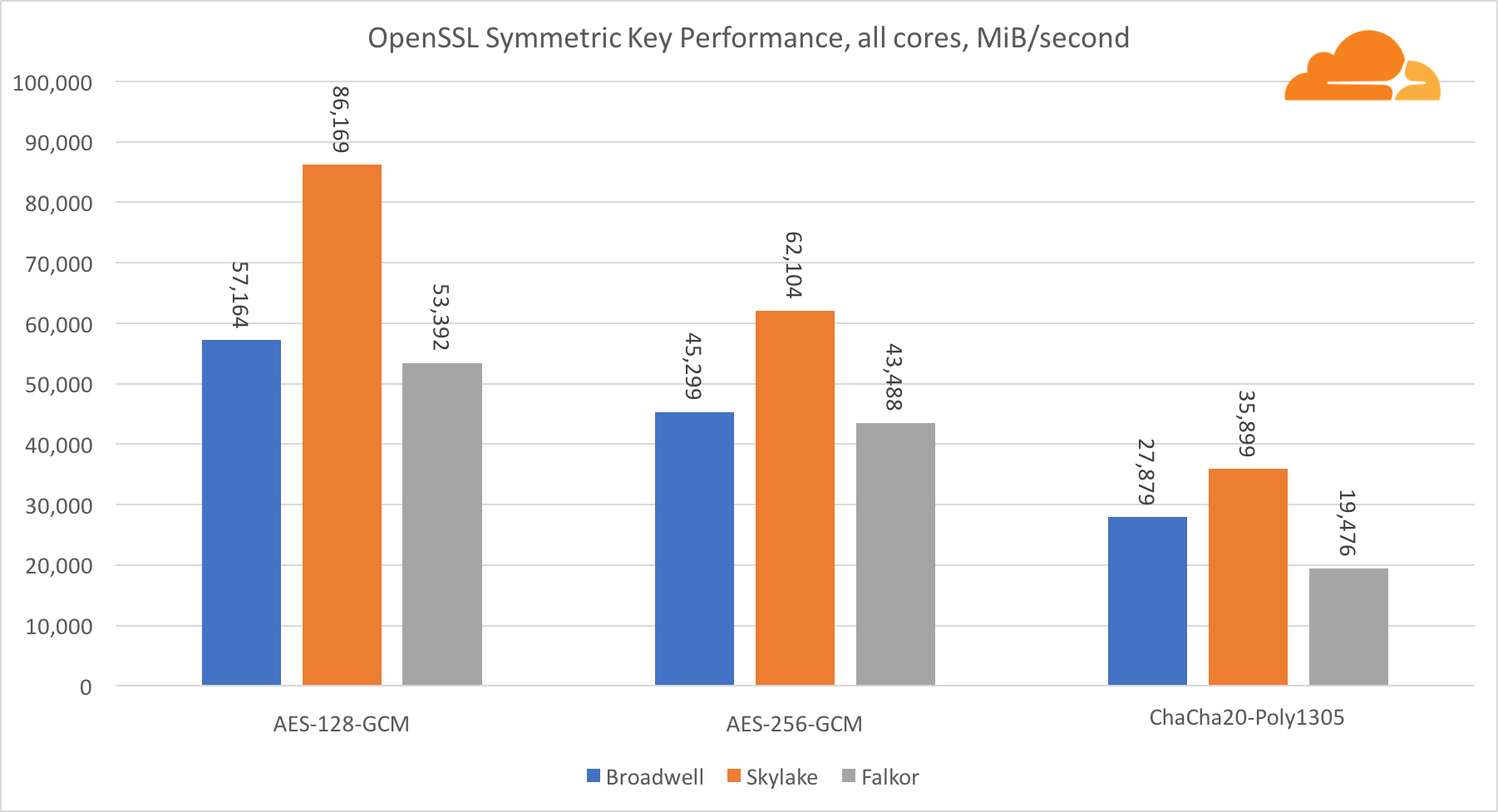
Kinerja core Intel dalam kriptografi simetris sangat luar biasa.
AES-GCM menggunakan kombinasi instruksi perangkat keras khusus untuk mempercepat AES dan CLMUL. Intel pertama kali memperkenalkan instruksi ini pada tahun 2010, dengan prosesor Westmere mereka dan dengan setiap generasi mereka meningkatkan kinerja mereka. ARM baru-baru ini memperkenalkan seperangkat instruksi serupa dengan set instruksi 64-bit sebagai tambahan opsional. Untungnya, setiap pemasok peralatan yang saya tahu telah menerapkannya. Sangat mungkin bahwa Qualcomm akan meningkatkan kinerja instruksi kriptografi pada generasi mendatang.
ChaCha20-Poly1305 adalah algoritma yang lebih umum yang dirancang sedemikian rupa agar dapat menggunakan modul SIMD lebar dengan lebih baik. Qualcomm hanya memiliki 128-bit NEON SIMD, Broadwell memiliki 256-bit AVX2, dan Skylake memiliki 512-bit AVX-512. Ini menjelaskan mengapa Skylake dengan margin yang tersisa dalam memimpin dalam mengevaluasi pekerjaan dengan inti tunggal. Dalam pengujian semua inti, celah Skylake dari yang lain berkurang pada saat yang sama, karena seharusnya mengurangi frekuensi jam saat melakukan beban kerja AVX-512. Saat menjalankan AVX-512 pada semua core, frekuensi dasar berkurang menjadi 1,4 GHz. Ingatlah ini jika Anda mencampur AVX-512 dan kode lainnya.
Kesimpulan mengenai kriptografi simetris adalah bahwa meskipun Skylake unggul, Broadwell dan Falkor menunjukkan hasil yang sangat baik, memiliki kinerja yang cukup tinggi untuk kasus nyata, mengingat fakta bahwa di pihak kami RSA menghabiskan lebih banyak waktu prosesor daripada semua algoritma kriptografi lainnya digabungkan .
Kompresi (kompresi)
Tes berikutnya yang ingin saya lakukan adalah kompresi. Karena dua alasan. Pertama, ini adalah beban kerja yang penting, karena semakin baik kompresi, semakin sedikit kesenjangan dalam kemampuan, dan ini memungkinkan pengiriman konten yang lebih cepat ke klien. Kedua, ini adalah beban kerja misprediksi cabang frekuensi tinggi yang sangat menuntut.
Jelas, tes pertama akan menjadi perpustakaan zlib yang populer. Di Cloudflare, kami menggunakan versi perpustakaan yang lebih baik yang dioptimalkan untuk prosesor Intel 64-bit, dan meskipun ditulis terutama dalam C, ia menggunakan beberapa fitur bawaan khusus Intel. Tidak adil membandingkan versi yang dioptimalkan ini dengan zlib asli. Tapi jangan khawatir, sedikit usaha dan saya mengadaptasi perpustakaan sehingga berfungsi pada arsitektur ARMv8, menggunakan properti NEON dan CRC32. Apalagi kecepatannya 2 kali lebih tinggi dari aslinya, untuk beberapa file.
Tes kedua adalah perpustakaan brotli baru, ditulis dalam C dan memungkinkan penggunaan kondisi yang sama untuk semua platform.
Semua tes dilakukan di blog.cloudflare.com HTML, dalam memori, mirip dengan bagaimana NGINX melakukan kompresi streaming. Kecuali versi spesifik dari file HTML adalah 29329 bytes, yang merupakan indikator yang baik, karena sesuai dengan ukuran sebagian besar file yang kita kompres. Tes kompresi paralel adalah kompresi paralel dari beberapa file secara bersamaan, kompresi tunggal adalah kompresi satu file menjadi beberapa stream, mirip dengan cara kerja NGINX.
gzip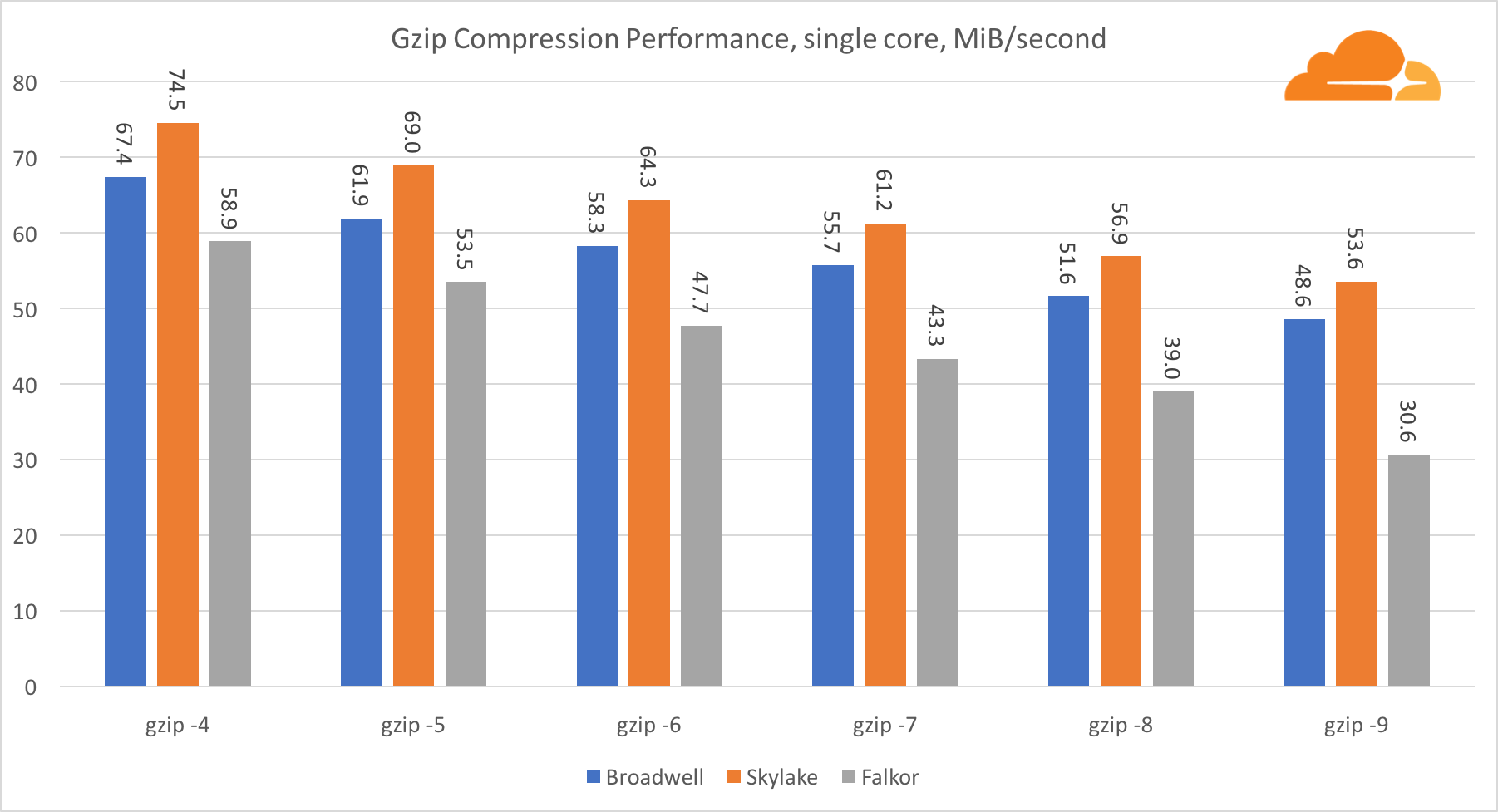
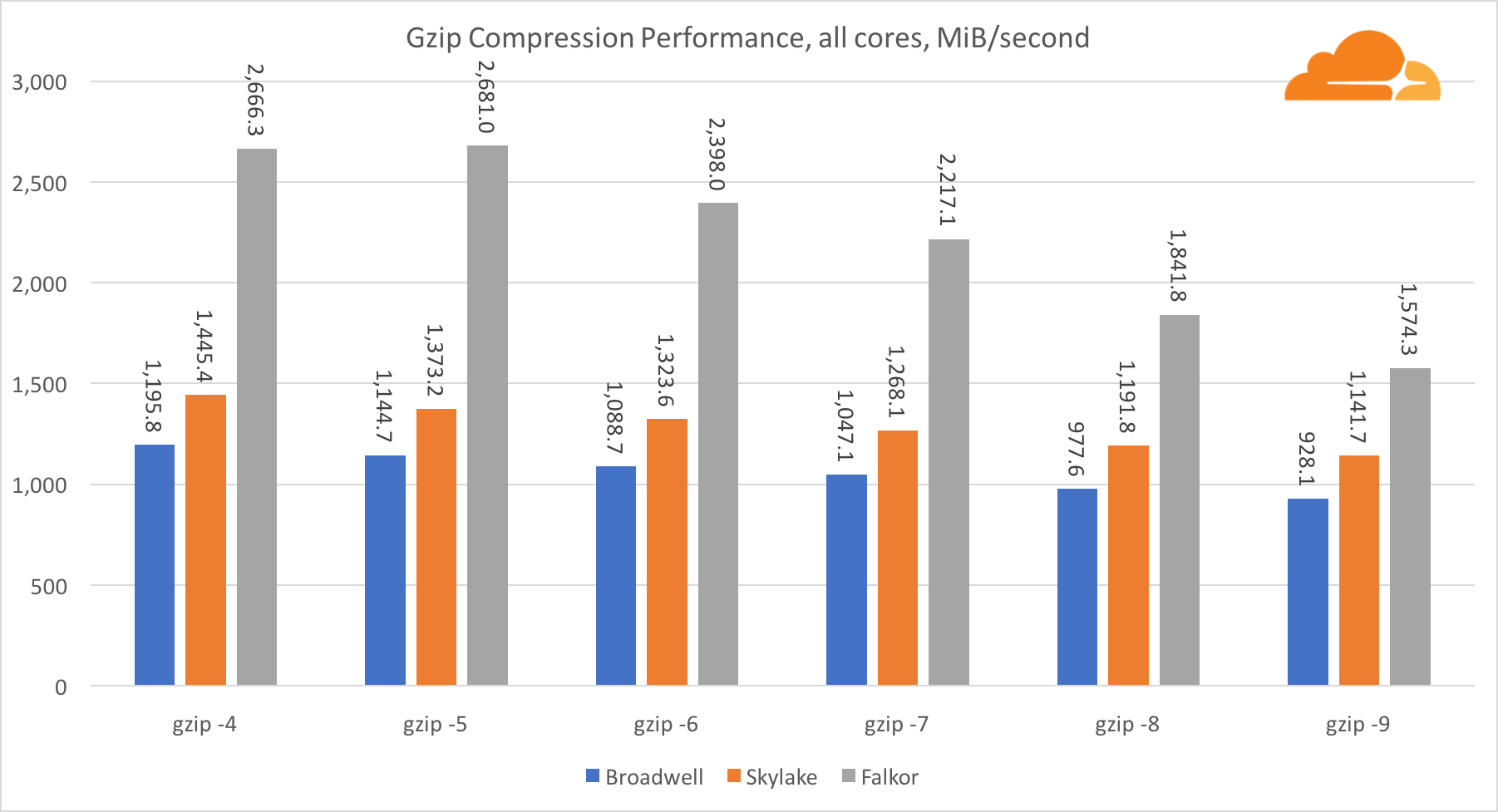
Menggunakan gzip di tingkat inti tunggal, Skylake tidak diragukan lagi menang. Dengan frekuensi yang lebih rendah dari Broadwell, Skylake mendapat manfaat dari paparan yang lebih rendah untuk salah duga cabang. Inti Falkor tidak jauh di belakang. Pada level sistem, Falkor berkinerja lebih baik dengan core lebih banyak. Perhatikan bagaimana gzip berskala jauh di beberapa inti.
BrotliDengan brotli pada satu inti, situasinya mirip dengan yang sebelumnya. Skylake adalah yang tercepat, tetapi Falkor tidak jauh di belakang. Dan pada standar 9, Falkor bahkan lebih cepat. Standard 4 Brotli sangat mirip dengan gzip level 5, sedangkan kompresi sebenarnya masih lebih baik (8010B versus 8187B).
Ketika mengompresi beberapa core, situasinya menjadi sedikit membingungkan. Untuk level 4, 5 dan 6, timbangan brotli sangat baik. Pada level 7 dan 8, itu mulai turun secara produktif pada inti, tenggelam ke bawah pada level 9, di mana kita mendapatkan produktivitas 3 kali lebih rendah dari semua core dibandingkan dengan satu.
Menurut pendapat saya, ini disebabkan oleh fakta bahwa dengan setiap level, brotli mulai mengkonsumsi lebih banyak memori dan crash cache. Indikator sudah mulai pulih di level 10 dan 11.
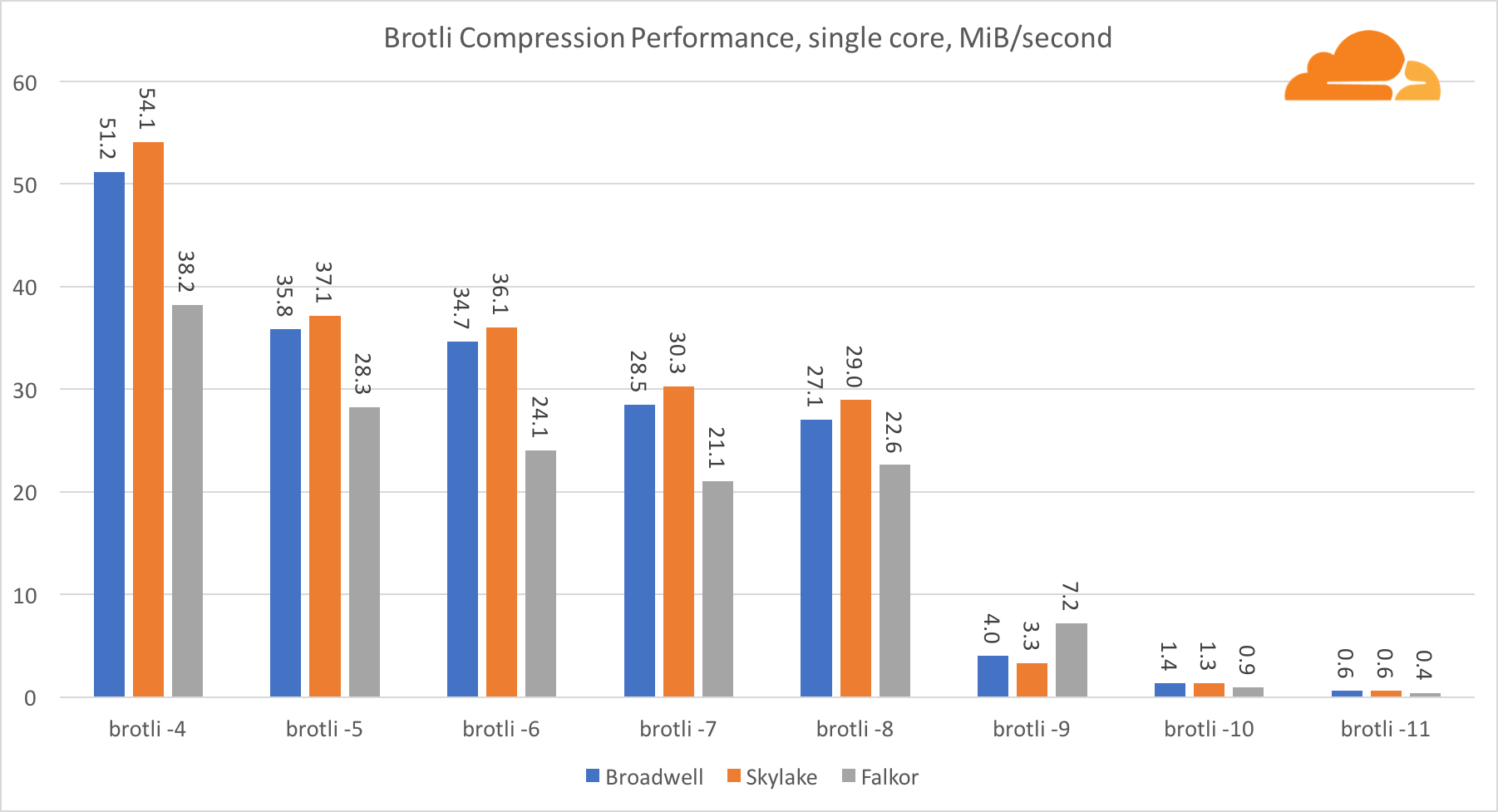
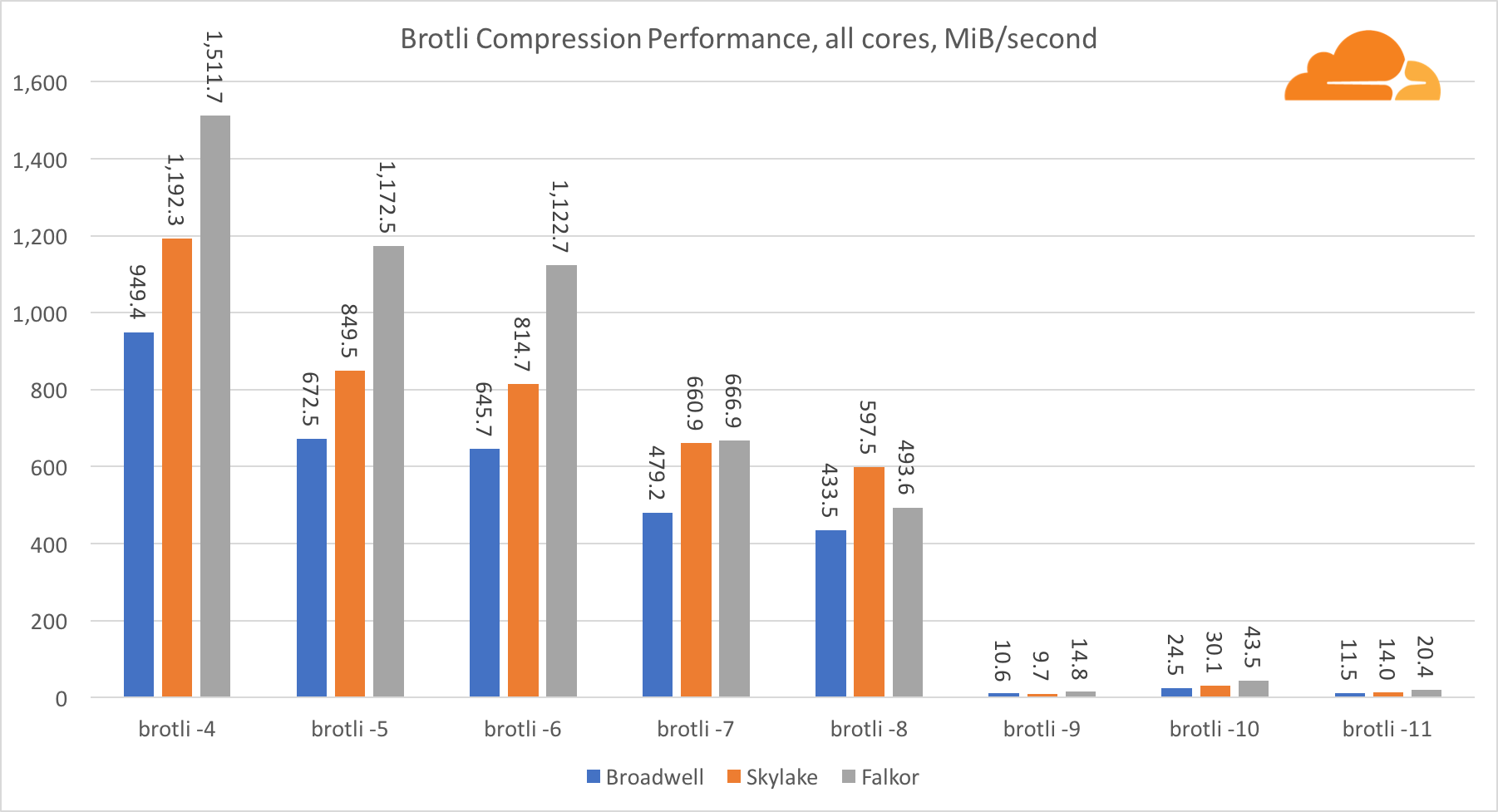
Sebagai kesimpulan, Falkor menang, mengingat bahwa kompresi dinamis tidak akan pergi di atas level 7.
Golang
Golang adalah bahasa lain yang sangat penting untuk Cloudflare. Ini juga salah satu bahasa pertama yang mendukung ARMv8, sehingga Anda dapat mengharapkan kinerja yang baik. Saya menggunakan beberapa tes bawaan, tetapi memodifikasinya untuk beberapa goroutine.
Pergi cryptoSaya ingin memulai dengan tes kinerja enkripsi. Berkat OpenSSL, kami memiliki data sumber yang sangat baik, dan akan sangat menarik untuk melihat seberapa bagus perpustakaan Go.
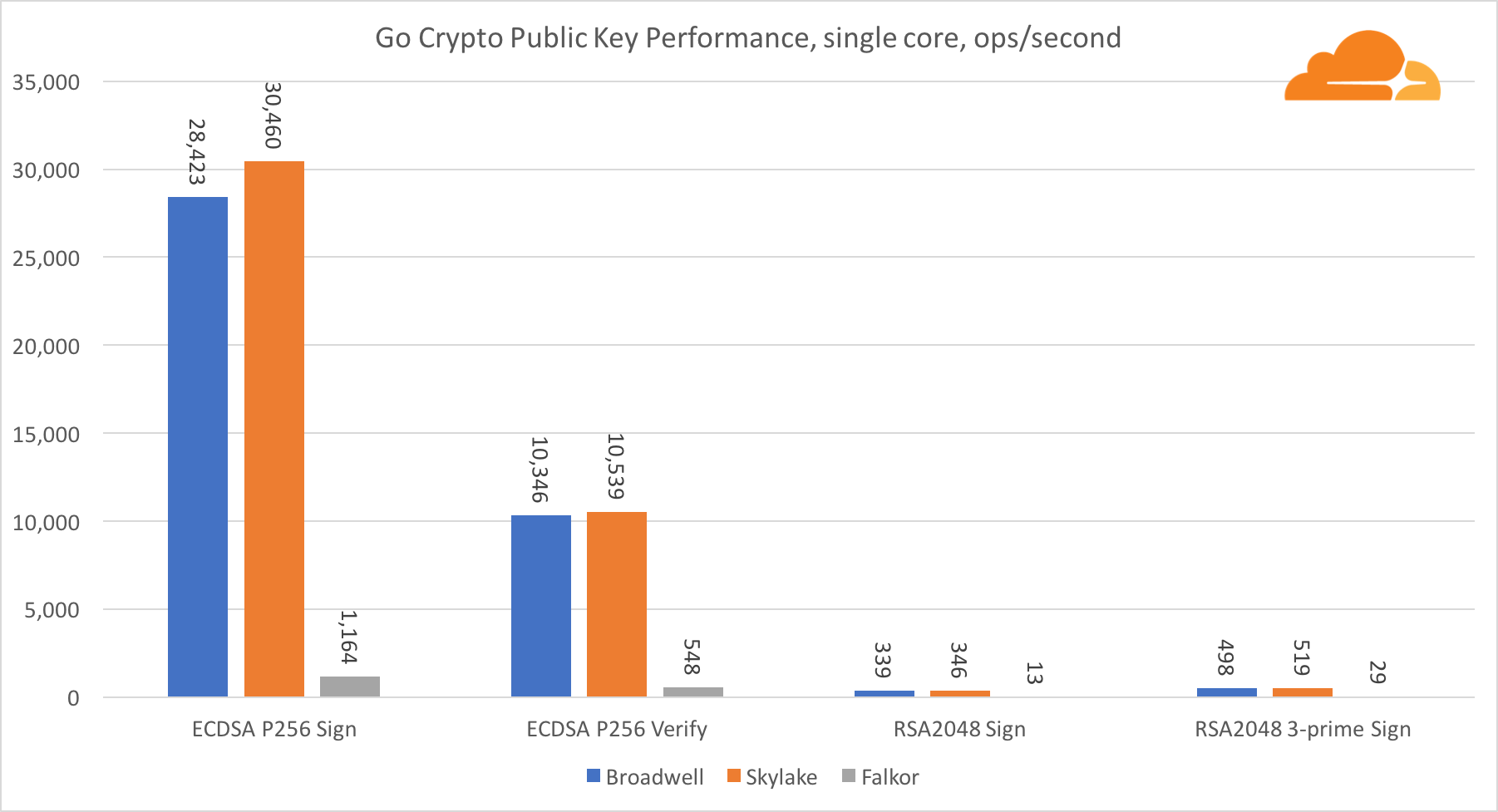
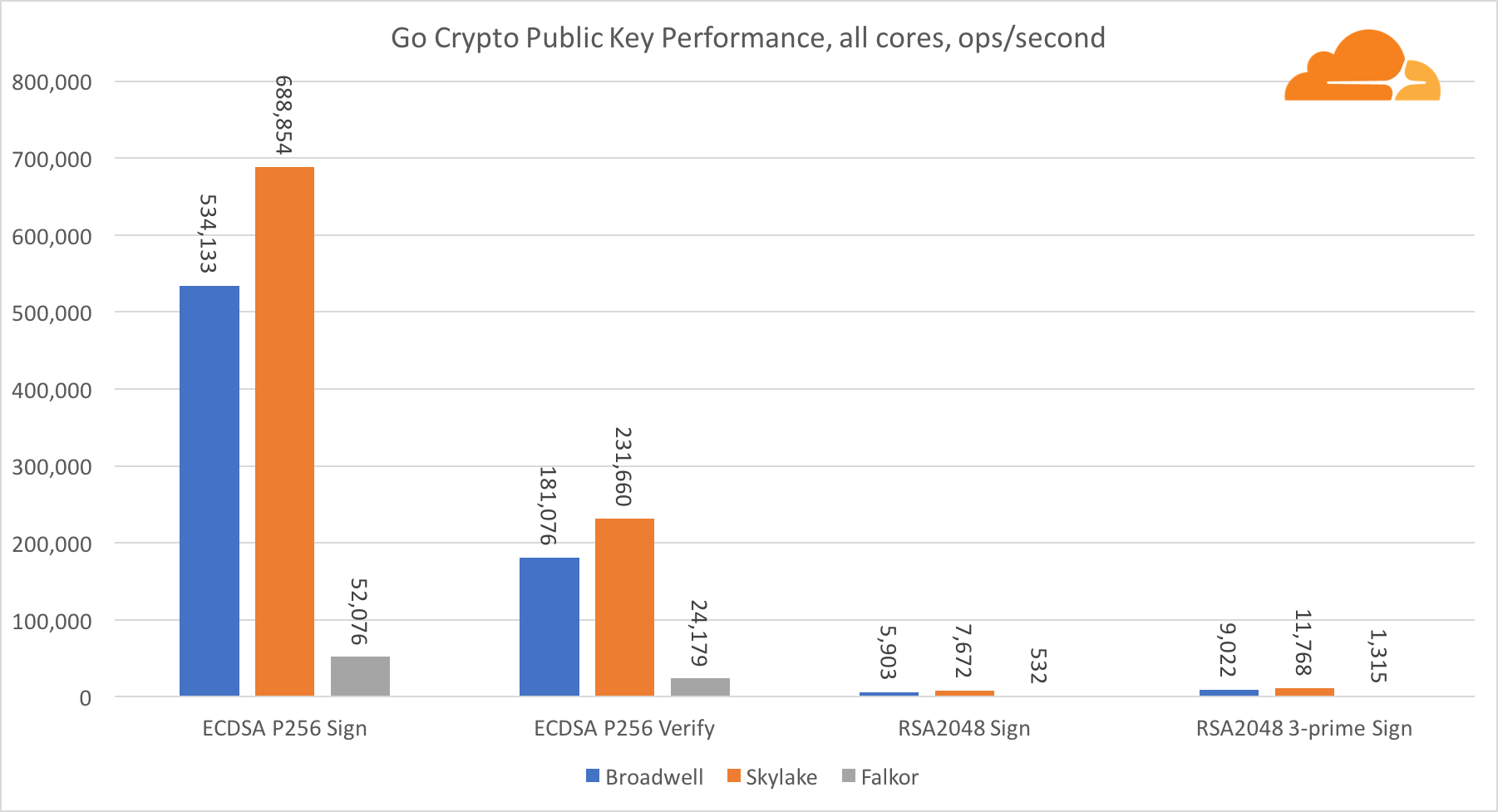
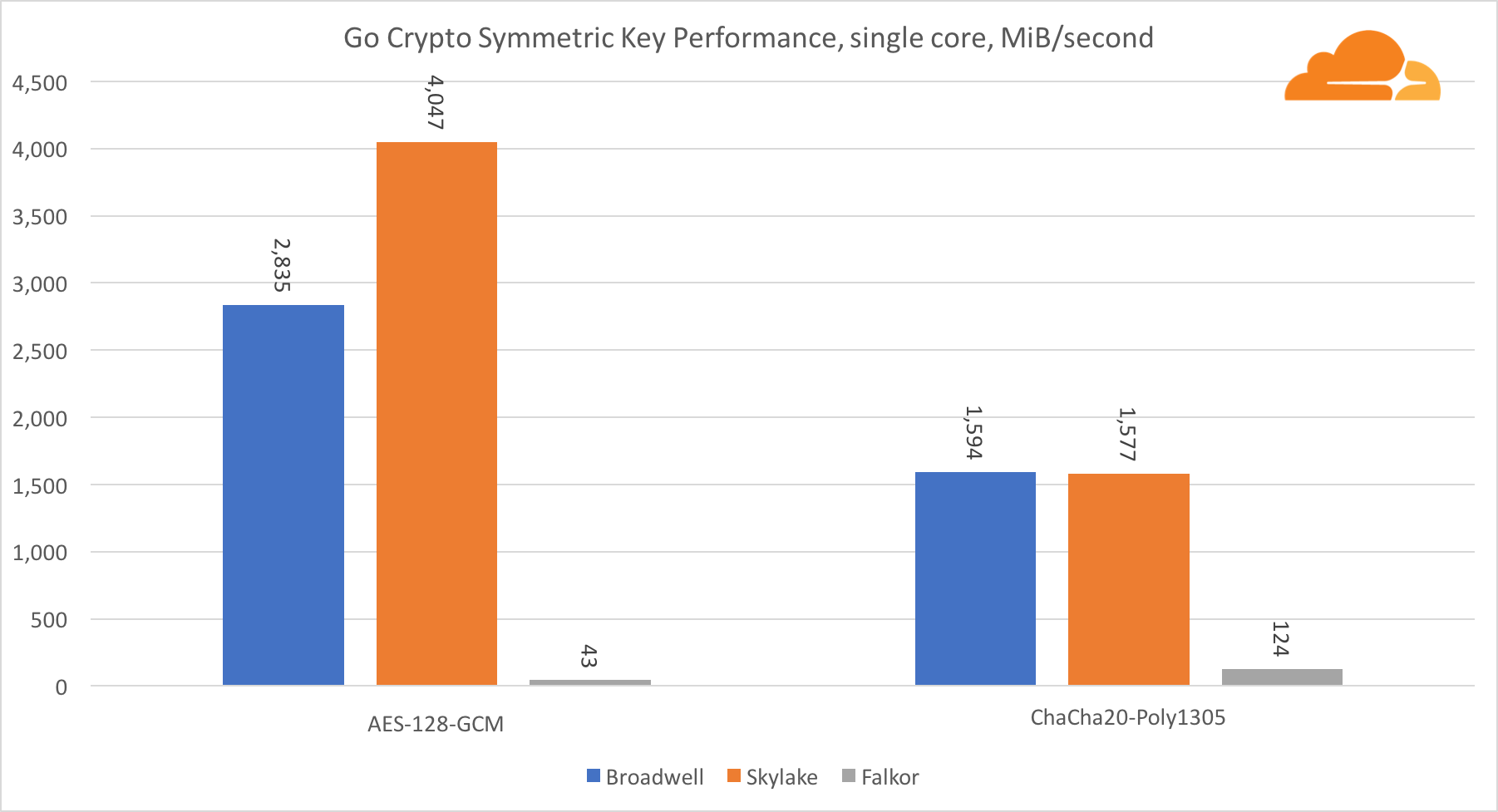
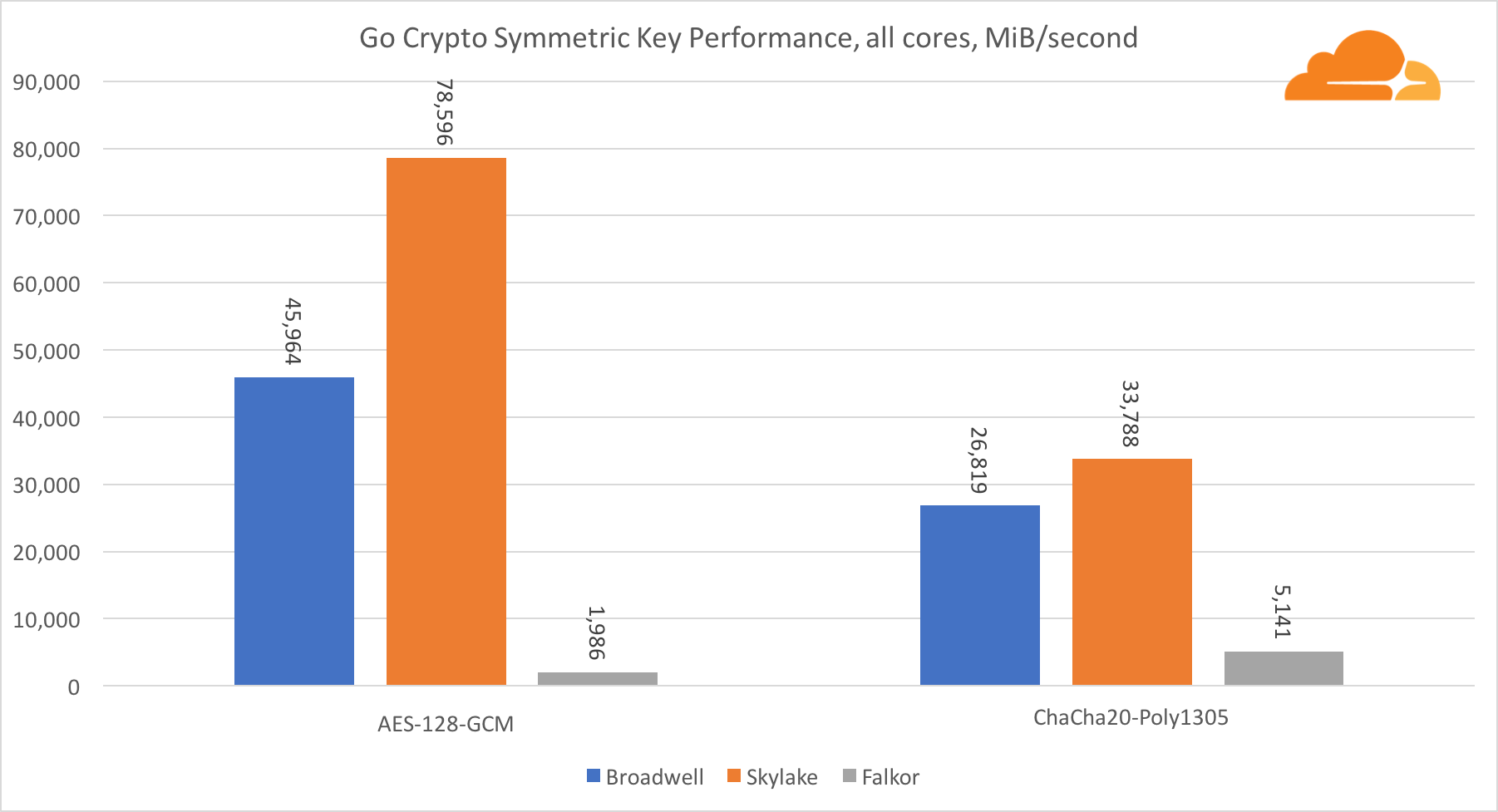
Mengenai Go crypto, ARM dan Intel bahkan tidak dalam kategori bobot yang sama. Go memiliki kode assembler yang sangat optimal untuk ECDSA, AES-GCM, dan Chacha20-Poly1305 pada Intel. Ada juga fungsi matematika yang dioptimalkan yang digunakan dalam perhitungan RSA. ARMv8 tidak memiliki semua ini, yang menempatkannya pada posisi yang sangat tidak menguntungkan.
Namun demikian, kesenjangan dapat dikurangi dengan sedikit usaha, dan kami tahu bahwa dengan optimalisasi yang tepat, kinerja dapat setara dengan OpenSSL. Bahkan perubahan yang sangat kecil, seperti penerapan fungsi addMulVVW di majelis, menyebabkan peningkatan lebih dari sepuluh kali lipat dalam kinerja RSA, menempatkan Falkor (dengan skor 8009) di atas Broadwell dan Skylake.
Perlu dicatat hal lain yang menarik - pada Skylake, kode Go Chacha20-Poly1305 yang menggunakan AVX2 bekerja dengan cara yang hampir sama dengan kode OpenSSL AVX512. Sekali lagi, ini disebabkan oleh fakta bahwa AVX2 beroperasi pada frekuensi clock yang lebih tinggi.
Pergi gzipSekarang mari kita lihat kinerja Go gzip. Ada juga panduan hebat untuk kode yang dioptimalkan dengan cukup baik, dan kita dapat membandingkannya dengan Go. Dalam kasus perpustakaan gzip, tidak ada optimasi khusus untuk Intel.
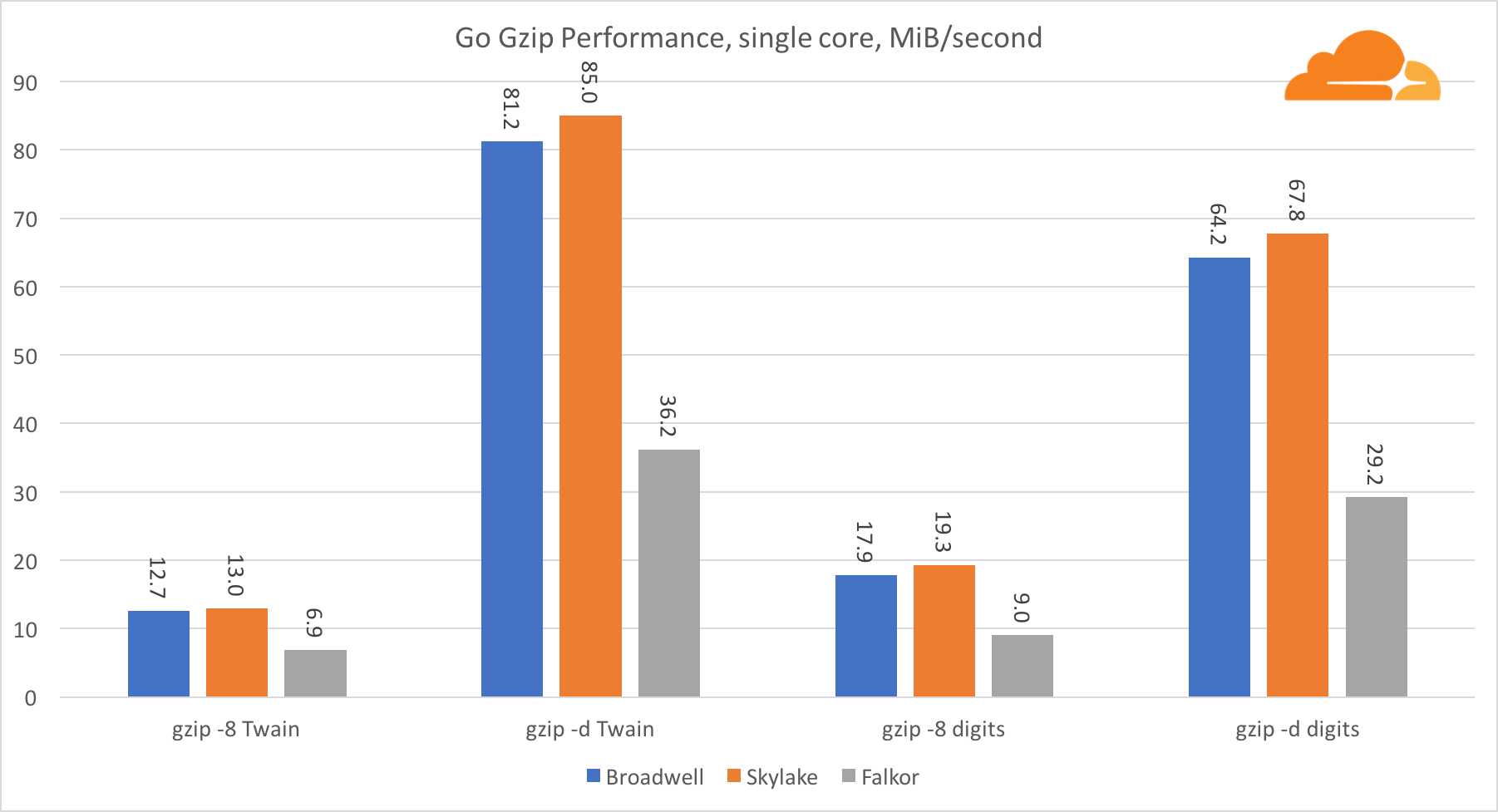

Performa Gzip cukup bagus. Kinerja pada satu inti Falkor secara signifikan tertinggal di belakang kedua prosesor Intel, tetapi pada tingkat sistem, ia berhasil mengalahkan Broadwell dan berada di bawah Skylake. Karena kita sudah tahu bahwa Falkor lebih unggul dari dua prosesor lainnya saat menjalankan C. Ini hanya dapat berarti satu hal - backend Go untuk ARMv8 masih belum selesai dibandingkan dengan gcc.
Pergi regexpRegexp banyak digunakan dalam berbagai tugas, karena kinerjanya juga sangat penting. Saya menjalankan tes bawaan pada aliran 32 kb.
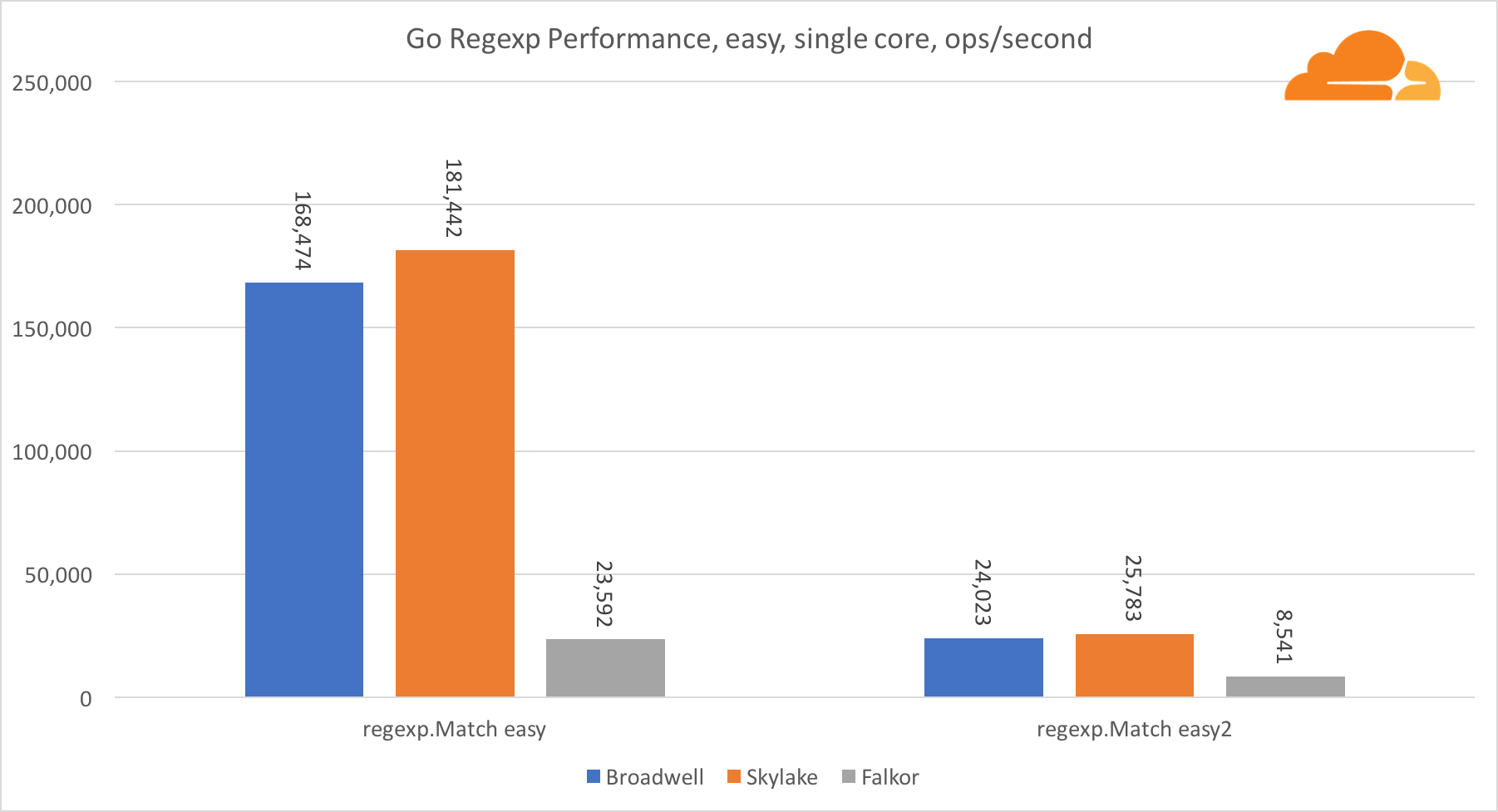
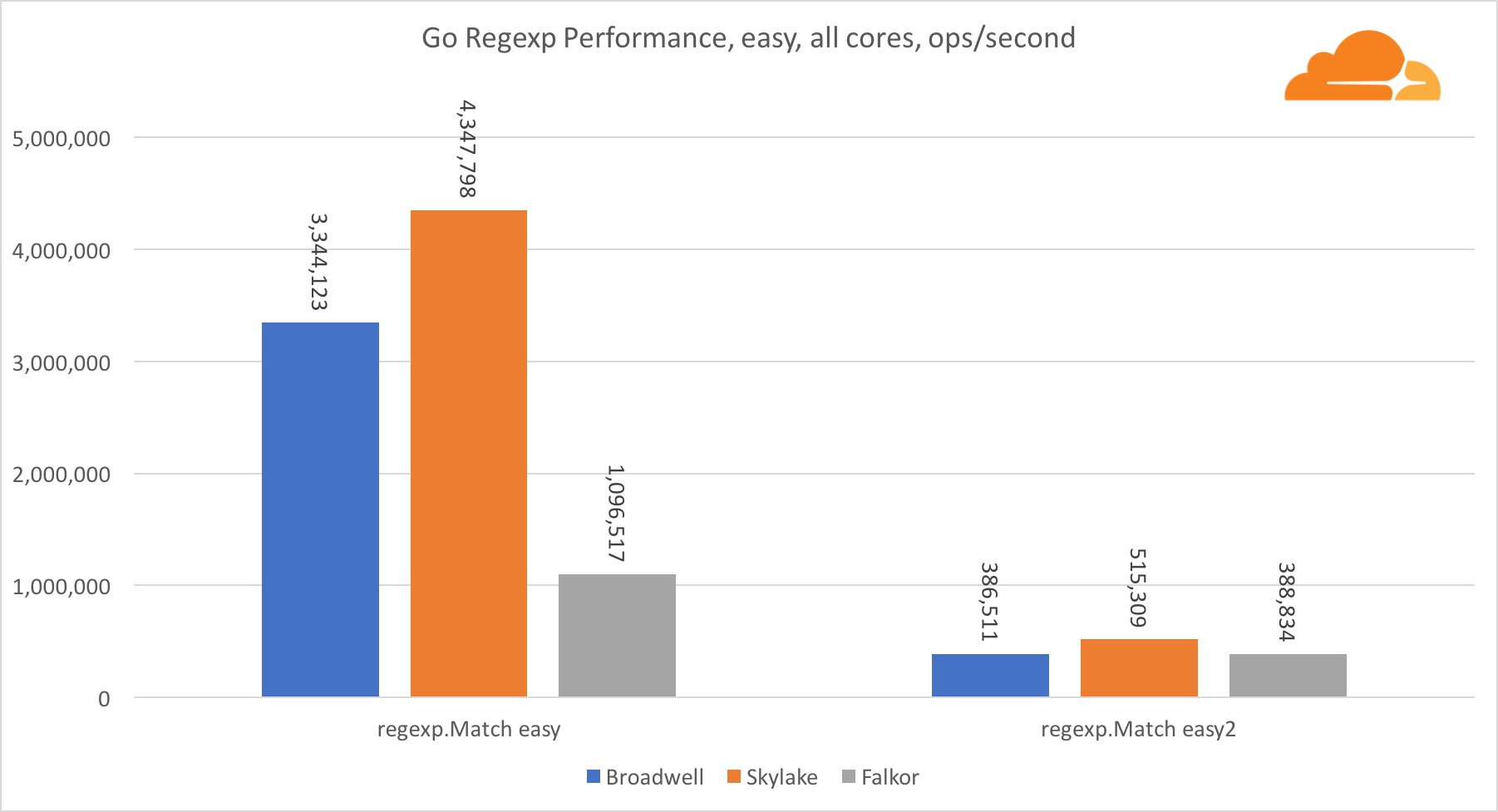
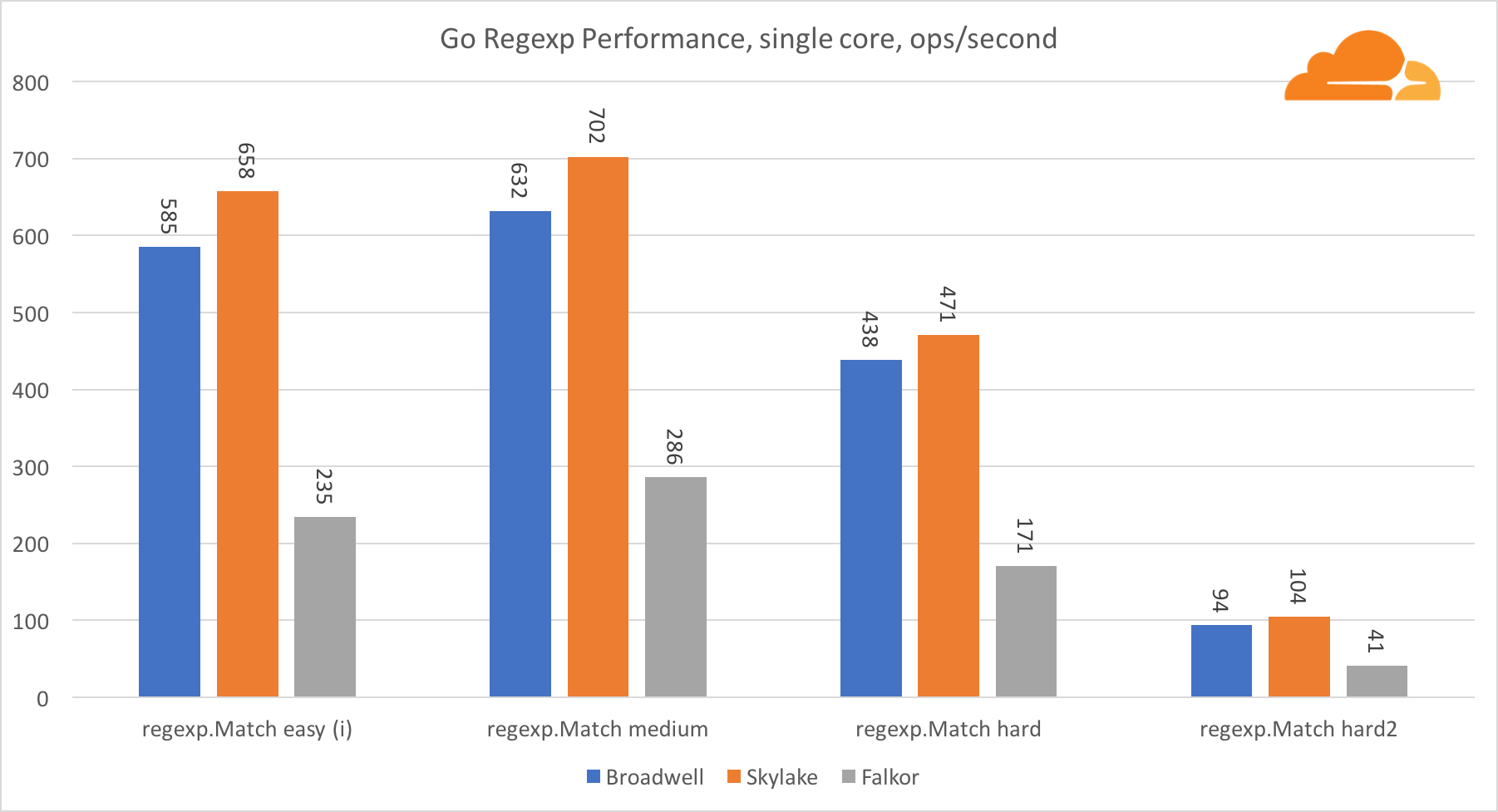
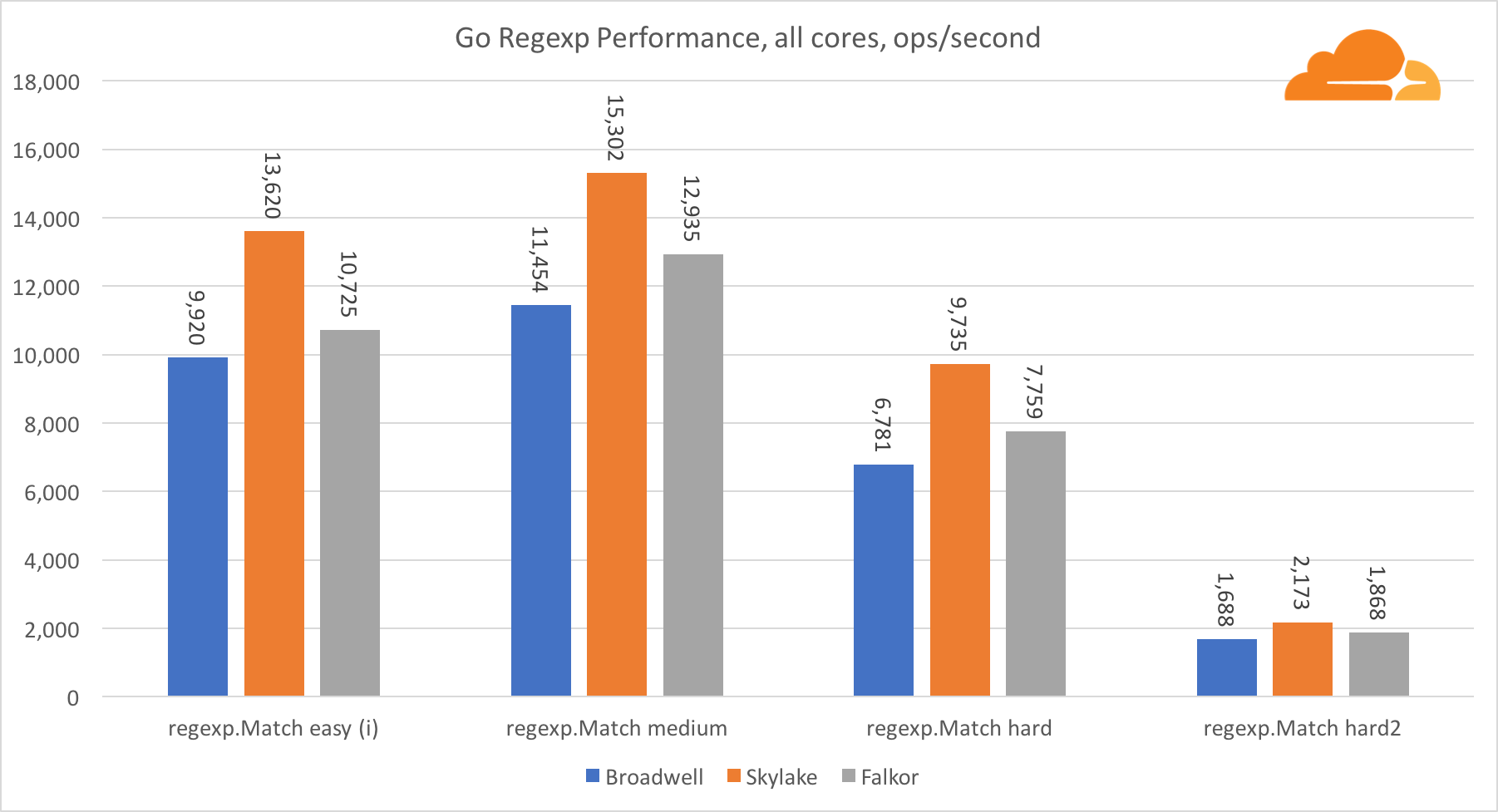
Di Falkor, kinerja Go regexp tidak terlalu baik. Dia mengambil tempat kedua pada tes menengah dan kompleks, berkat jumlah inti yang lebih besar, tetapi, bagaimanapun, Skylake jauh lebih cepat.
Melihat lebih dekat pada proses tersebut menunjukkan bahwa banyak waktu dihabiskan untuk fungsi bytes.IndexByte. Fungsi ini memiliki implementasi assembler untuk amd64 (runtime.indexbytebody), tetapi implementasi utamanya adalah untuk Go. Selama pengujian ringan, regexp menghabiskan lebih banyak waktu pada fitur ini, yang menjelaskan kesenjangan yang lebih luas.
Pergi stringPustaka penting lainnya untuk server web adalah string Go. Saya hanya menguji kelas Replacer utama.
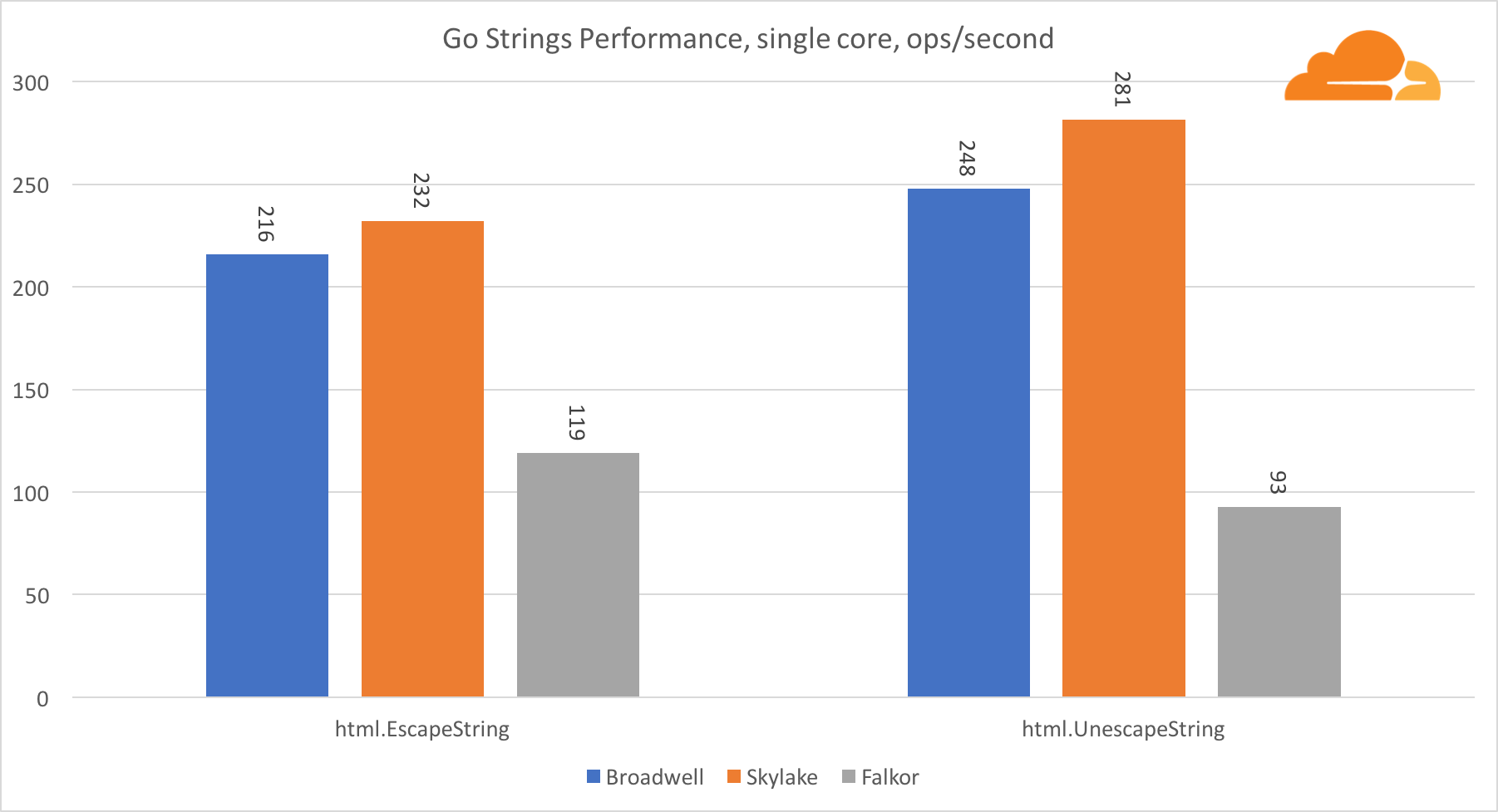
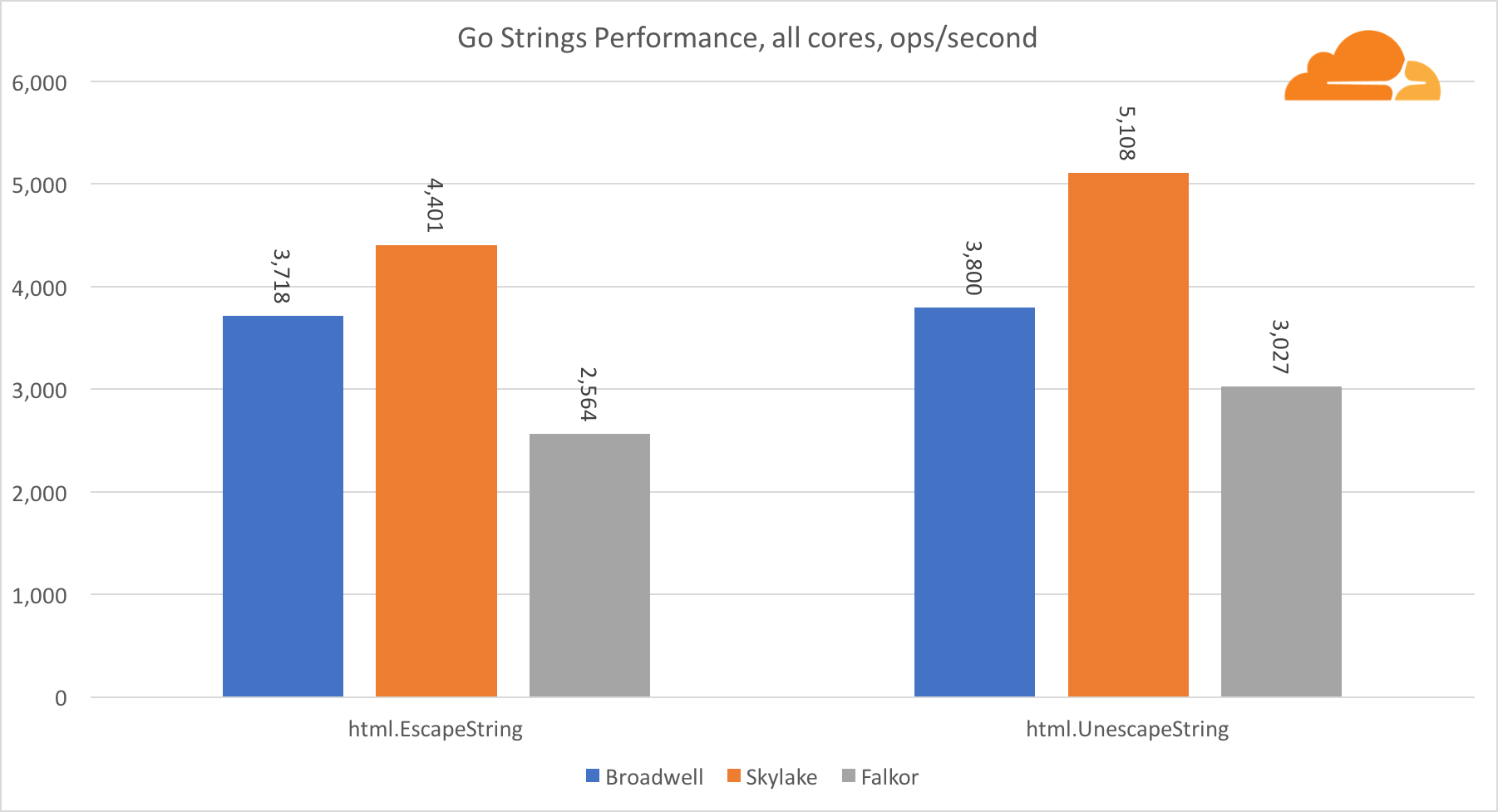
Dalam tes ini, Falkor sekali lagi tertinggal, bahkan di belakang Broadwell. Pandangan yang lebih dekat mengungkapkan tinggal lama dalam fungsi runtime.memmove. Apakah kamu tahu? Dia memiliki kode assembler yang dioptimalkan sempurna untuk amd64 yang menggunakan AVX2, tetapi hanya assembler yang paling sederhana yang menyalin 8 byte pada satu waktu. Dengan mengubah 3 baris dalam kode ini dan menggunakan instruksi LDP / STP (pair loading / pair storage), Anda dapat menyalin 16 byte sekaligus, yang meningkatkan kinerja memmove sebesar 30%, yang pada gilirannya, mempercepat EscapeString dan UnescapeString sebesar 20%. Dan ini hanyalah puncak gunung es.
Pergi kesimpulanDukungan go pada aarch64 cukup mengecewakan. Saya senang mengumumkan bahwa semuanya dikompilasi dan bekerja dengan sempurna, tetapi di sisi kinerja bisa lebih baik. Orang mendapat kesan bahwa sebagian besar upaya dihabiskan untuk backend compiler, dan perpustakaan hampir tidak tersentuh. Ada banyak optimasi tingkat rendah, misalnya perbaikan addMulVVW saya, yang membutuhkan waktu 20 menit. Qualcomm dan vendor ARMv8 lainnya bermaksud untuk menghabiskan sumber daya teknis yang signifikan untuk memperbaiki situasi, tetapi siapa pun dapat berkontribusi untuk Go. Karena itu, jika Anda ingin meninggalkan jejak pada sejarah, sekaranglah saatnya.
Luajit
Lua adalah lem yang menyatukan Cloudflare.
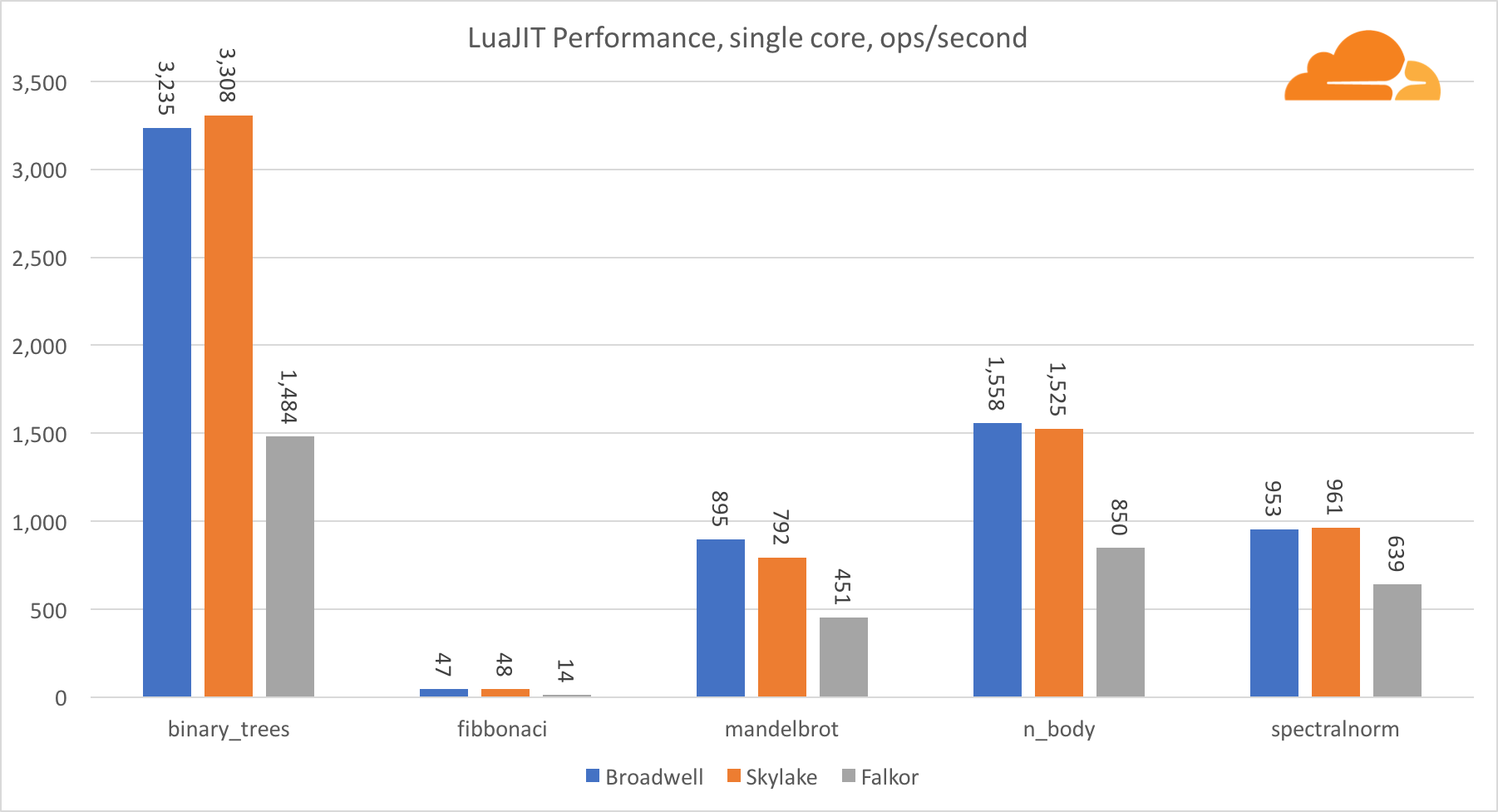
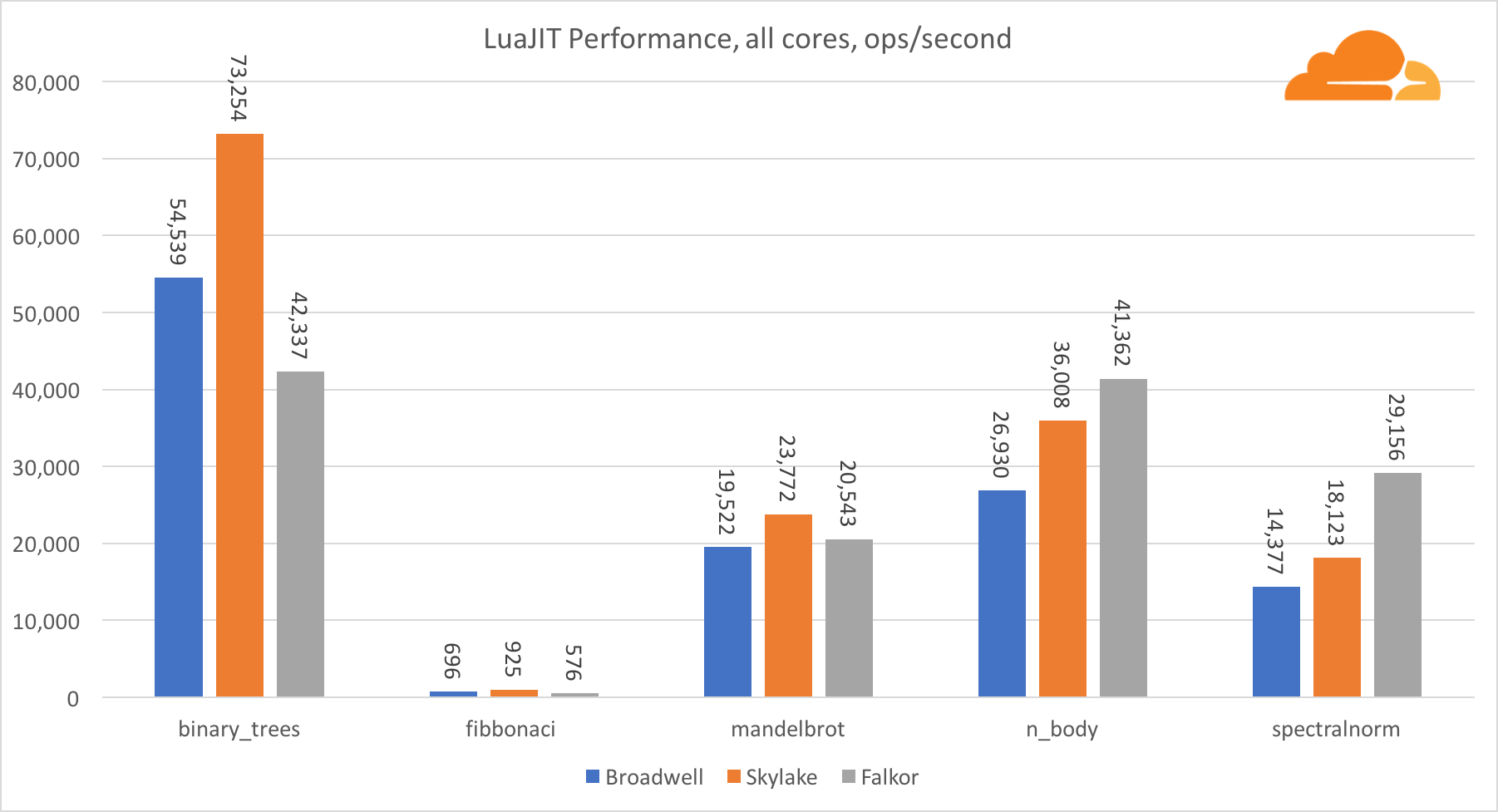
Dengan pengecualian dari tes binary_trees, kinerja LuaJIT pada ARM sangat kompetitif. Dia memenangkan dua tes, dan yang ketiga berhadapan dengan pesaing.
Perlu dicatat bahwa tes binary_trees sangat penting, karena melibatkan banyak siklus alokasi memori dan pengumpulan sampah. Itu membutuhkan pertimbangan yang lebih teliti di masa depan.
Nginx
Sebagai beban kerja NGINX, saya memutuskan untuk membuatnya yang menyerupai server sebenarnya.
Saya mengonfigurasi server yang menyajikan file HTML yang digunakan dalam uji gzip melalui https menggunakan cipher suite ECDHE-ECDSA-AES128-GCM-SHA256.
Itu juga menggunakan LuaJIT untuk mengarahkan permintaan masuk, menghapus semua jeda baris dan spasi tambahan dari file HTML saat menambahkan stempel waktu. HTML kemudian dikompres menggunakan brotli 5.
Setiap server dikonfigurasi untuk bekerja dengan pengguna sebanyak prosesor virtual. 40 untuk Broadwell, 48 untuk Skylake dan 46 untuk Falkor.
Sebagai klien untuk tes ini, saya menggunakan program hei yang berjalan di 3 server Broadwell.
Pada saat yang sama dengan pengujian, kami mengambil pembacaan daya dari blok BMC yang sesuai dari masing-masing server.
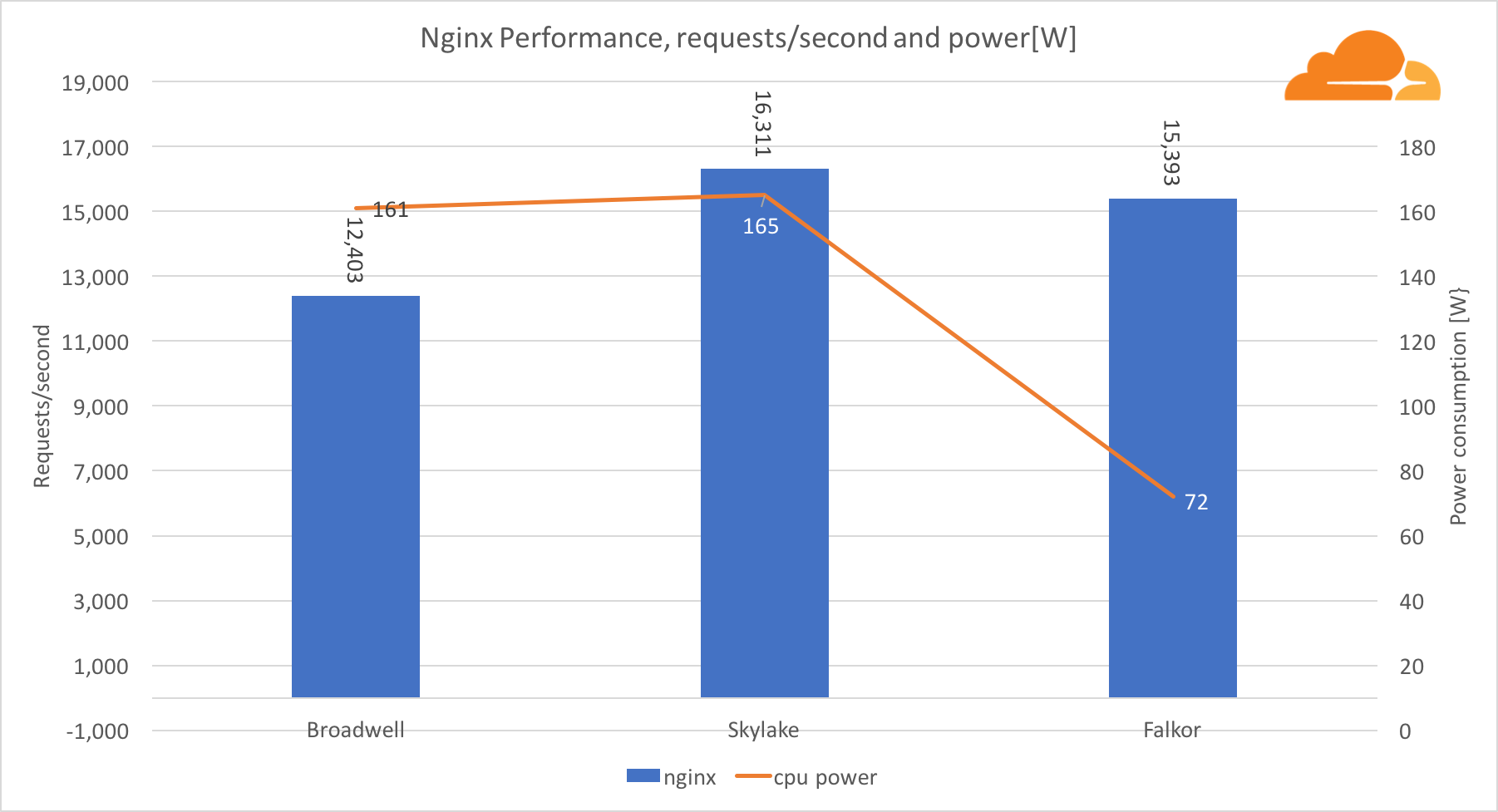
Dengan beban kerja, NGINX Falkor menangani jumlah permintaan yang hampir sama dengan server Skylake, dan keduanya jauh di depan Broadwell. Pembacaan daya yang diambil dari BMC menunjukkan bahwa ini terjadi ketika daya dikonsumsi setengah dari prosesor lainnya. Ini berarti bahwa Falkor berhasil mendapatkan 214 permintaan / W, Skylake - 99 permintaan / W dan Broadwell - 77 permintaan / W.
Saya terkejut bahwa Skylake dan Broadwell mengkonsumsi jumlah energi yang sama, mengingat bahwa mereka diproduksi dengan cara yang sama, dan Skylake memiliki lebih banyak inti.
Konsumsi daya rendah Falkor tidak mengejutkan, karena prosesor Qualcomm dikenal karena efisiensi energinya yang tinggi, yang memungkinkan mereka untuk menempati posisi dominan di pasar prosesor untuk perangkat seluler.
Kesimpulan
Sampel Falkor yang kami dapatkan benar-benar membuat saya terkesan. Ini adalah peningkatan besar dari upaya sebelumnya di server berbasis ARM. Tentu saja, membandingkan inti dengan inti, Intel Skylake jauh lebih baik, tetapi jika kita melihat tingkat sistem, kinerjanya menjadi sangat menarik.
Versi produksi Centriq SoC akan berisi 48 core Falkor yang beroperasi pada frekuensi hingga 2,6 GHz, yang memberikan potensi peningkatan kinerja 8%.
Tentunya, Skylake yang kami uji bukanlah kapal unggulan seperti Platinum dengan 28 core-nya, tetapi 28 core ini harganya banyak dan menghabiskan 200W, sementara kami mencoba mengoptimalkan biaya kami dan meningkatkan kinerja sebesar 1 watt.
Saat ini, saya sangat prihatin dengan buruknya kinerja bahasa Go, tetapi ini akan berubah segera setelah server berbasis ARM menempati ceruk pasar mereka.
Kinerja C dan LuaJIT sangat kompetitif, dan dalam banyak kasus lebih unggul daripada Skylake. Di hampir semua tes, Falkor terbukti menjadi pengganti yang layak untuk Broadwell.
Nilai tambah terbesar untuk Falkor saat ini adalah konsumsi daya yang rendah. Meskipun TDP 120W, selama tes saya angka ini tidak pernah melebihi 89W (untuk tes go). Sebagai perbandingan, Skylake dan Broadwell melebihi 160W, sedangkan TDP mereka 170W.
Sebagai iklan. Ini bukan hanya server virtual! Ini adalah VPS (KVM) dengan drive khusus, yang tidak lebih buruk dari server khusus, dan dalam kebanyakan kasus - lebih baik!
Kami membuat VPS (KVM) dengan drive khusus di Belanda dan Amerika Serikat (konfigurasi dari VPS (KVM) - E5-2650v4 (6 Cores) / 10GB DDR4 / 240GB SSD atau 4TB HDD / 1Gbps 10TB tersedia dengan harga rendah yang unik - mulai dari $ 29 / bulan) , opsi dengan RAID1 dan RAID10 tersedia) , jangan lewatkan kesempatan untuk melakukan pemesanan untuk server virtual jenis baru, di mana semua sumber daya milik Anda, seperti pada yang khusus, dan harganya jauh lebih rendah, dengan perangkat keras yang jauh lebih produktif!
Cara membangun infrastruktur gedung. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen? Dell R730xd 2 kali lebih murah? Hanya kami yang memiliki
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV dari $ 249 di Belanda dan Amerika Serikat!