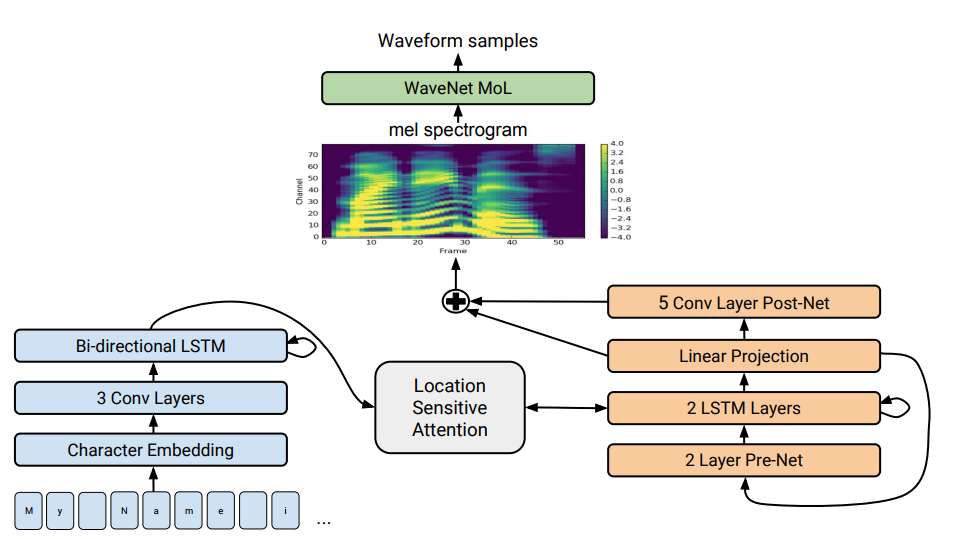
 Arsitektur Tacotron 2. Di bagian bawah ilustrasi, model penawaran-ke-penawaran ditampilkan yang menerjemahkan urutan huruf ke dalam urutan atribut dalam ruang 80-dimensi. Untuk deskripsi teknis, lihat artikel ilmiah.
Arsitektur Tacotron 2. Di bagian bawah ilustrasi, model penawaran-ke-penawaran ditampilkan yang menerjemahkan urutan huruf ke dalam urutan atribut dalam ruang 80-dimensi. Untuk deskripsi teknis, lihat artikel ilmiah.Sintesis ucapan - reproduksi tiruan pembicaraan manusia dari suatu teks - secara tradisional dianggap sebagai salah satu komponen kecerdasan buatan. Sebelumnya, sistem seperti itu hanya dapat dilihat dalam film fiksi ilmiah, tetapi sekarang mereka bekerja di setiap smartphone: ini adalah Siri, Alice, dan sejenisnya. Tapi mereka tidak mengucapkan ungkapan yang sangat realistis: suara mati, kata-kata dipisahkan satu sama lain.
Google telah
mengembangkan synthesizer pidato generasi mendatang yang canggih. Ini disebut Tacotron 2 dan didasarkan pada jaringan saraf. Untuk menunjukkan kemampuannya, perusahaan memposting
contoh-contoh sintesis . Di bagian bawah halaman dengan contoh, Anda dapat mengikuti tes dan mencoba menentukan di mana teks dikirim oleh synthesizer ucapan dan di mana orang itu berada. Menentukan perbedaannya hampir mustahil.
Terlepas dari penelitian selama puluhan tahun, sintesis wicara tetap merupakan tugas mendesak bagi komunitas ilmiah. Selama beberapa tahun terakhir, teknik yang berbeda telah berlaku di bidang ini: sintesis concatenative dengan pilihan fragmen baru-baru ini dianggap sebagai yang paling canggih - proses penggabungan bersama fragmen suara kecil yang telah direkam, serta sintesis statistik parametrik statistik, di mana vocoder mensintesis jalur pengucapan halus. Metode kedua memecahkan banyak masalah sintesis concatenative dengan artefak di batas antara fragmen. Namun, dalam kedua kasus, suara yang disintesis terdengar tidak jelas dan tidak alami dibandingkan dengan ucapan manusia.
Kemudian muncul mesin suara WaveNet (model gelombang bentuk generatif dalam domain waktu), yang untuk pertama kalinya mampu menunjukkan kualitas suara yang sebanding dengan manusia. Sekarang digunakan dalam sistem sintesis pidato
Deep Voice 3 .
Sebelumnya pada 2017, Google memperkenalkan
arsitektur penawaran-ke-penawaran
Tacotron . Ini menghasilkan spektrogram amplitudo dari serangkaian karakter. Tacotron menyederhanakan konveyor mesin audio tradisional. Di sini, fitur linguistik dan akustik dihasilkan oleh jaringan saraf tunggal yang hanya dilatih pada data. Frasa "kalimat-ke-kalimat" berarti bahwa jaringan saraf membangun korespondensi antara urutan huruf dan urutan atribut untuk suara enkode. Tanda-tanda dihasilkan dalam spektogram audio 80-dimensi dengan bingkai 12,5 milidetik.
Jaringan saraf belajar tidak hanya pengucapan kata-kata, tetapi juga karakteristik suara tertentu, seperti volume, kecepatan dan intonasi.
Kemudian, gelombang suara secara langsung dihasilkan menggunakan algoritma Griffin-Lim (untuk estimasi fase) dan transformasi Fourier jangka pendek terbalik. Seperti yang dicatat oleh penulis, ini adalah solusi sementara untuk menunjukkan kemampuan jaringan saraf. Bahkan, mesin WaveNet dan sejenisnya menciptakan suara yang lebih baik daripada algoritma Griffin-Lim, dan tanpa artefak.
Dalam sistem Tacotron 2 yang dimodifikasi, spesialis dari Google masih menghubungkan vocoder WaveNet ke jaringan saraf. Dengan demikian, jaringan saraf menciptakan spektrogram, dan kemudian versi modifikasi dari WaveNet menghasilkan suara pada 24 kHz.
Jaringan saraf belajar secara mandiri (ujung ke ujung) pada suara suara manusia, yang disertai dengan teks. Jaringan saraf yang terlatih kemudian membaca teks sedemikian rupa sehingga hampir tidak mungkin untuk membedakan dari suara ucapan manusia, seperti dapat dilihat pada
contoh nyata .
Peneliti mencatat bahwa sistem Deep Voice 3 menggunakan pendekatan yang serupa, tetapi kualitas sintesisnya masih belum bisa dibandingkan dengan ucapan manusia. Tapi Tacotron 2 bisa, lihat hasil tes Mean Opinion Score (MOS) dalam tabel.
Ada synthesizer ucapan lain yang juga berfungsi pada jaringan saraf - ini adalah
Char2Wav , tetapi memiliki arsitektur yang sama sekali berbeda.
Para ilmuwan mengatakan bahwa secara umum, jaringan saraf berfungsi dengan baik, tetapi masih mengalami kesulitan mengucapkan beberapa kata yang rumit (seperti
kesopanan atau
merlot ). Dan kadang-kadang secara acak menghasilkan suara-suara aneh - alasan untuk ini sekarang sedang diklarifikasi. Selain itu, sistem tidak dapat bekerja secara real time, dan penulis belum dapat mengendalikan mesin, yaitu, mengatur intonasi yang diinginkan untuk itu, misalnya, suara bahagia atau sedih. Setiap masalah ini menarik dalam dirinya sendiri, tulis mereka.
Artikel ilmiah ini
diterbitkan pada 16 Desember 2017 di situs preprint arXiv.org (arXiv: 1712.05884v1).