
Hari kami dimulai dengan frasa "Selamat pagi!". Siang hari kami berbicara dengan kolega, kerabat, teman, dan bahkan orang asing yang menanyakan arah ke metro terdekat. Kita berbicara bahkan ketika tidak ada orang di sekitar kita untuk lebih memahami alasan kita sendiri. Semua ini adalah ucapan kita - hadiah yang benar-benar tak tertandingi dengan banyak kemungkinan lain dari tubuh manusia. Pidato memungkinkan kita untuk membangun hubungan sosial, mengekspresikan pikiran dan emosi, mengekspresikan diri kita, misalnya, dalam lagu.
Maka, mobil pintar muncul dalam kehidupan manusia. Seseorang, entah karena keingintahuan, atau karena kehausan akan pencapaian baru, sedang mencoba mengajar mesin untuk berbicara. Tetapi untuk dapat berbicara, Anda perlu mendengar dan mendengarkan. Saat ini sulit untuk mengejutkan dengan program (misalnya Siri) yang dapat mengenali pembicaraan, menemukan restoran di peta, menelepon ibu, bahkan menceritakan lelucon. Dia mengerti banyak, tidak semua, tentu saja, tetapi banyak. Tapi itu tidak selalu demikian, secara alami. Beberapa dekade yang lalu, itu untuk kebahagiaan, ketika sebuah mesin bisa mengerti setidaknya selusin kata.
Hari ini kita akan terjun ke dalam sejarah tentang bagaimana umat manusia dapat berbicara dengan mesin, yang terobosan selama berabad-abad di bidang ini telah berfungsi sebagai dorongan untuk pengembangan teknologi pengenalan suara. Kami juga melihat bagaimana perangkat modern memahami dan memproses suara kami. Ayo pergi.
Asal usul pengenalan ucapan
Apa itu bicara? Secara kasar, ini suara. Jadi, untuk mengenali ucapan, pertama-tama Anda harus mengenali suara dan merekamnya.
Sekarang kita memiliki iPod, pemutar MP3, sebelum ada tape recorder, bahkan gramofon dan gramofon sebelumnya. Ini semua adalah perangkat untuk memutar suara. Tapi siapa nenek moyang mereka semua?
 Thomas Edison dengan penemuannya. 1878 tahun
Thomas Edison dengan penemuannya. 1878 tahunItu adalah fonograf. 29 November 1877, penemu hebat Thomas Edison mendemonstrasikan kreasi barunya, yang mampu merekam dan mereproduksi suara. Itu adalah terobosan yang membangkitkan minat masyarakat.
Prinsip fonograf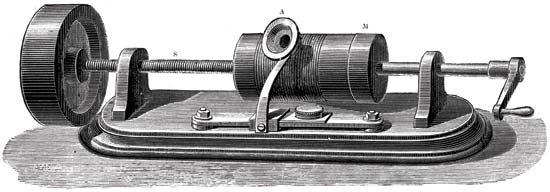
Bagian utama dari mekanisme perekaman suara adalah silinder yang dilapisi foil dan jarum pemotong. Jarum bergerak di sepanjang silinder yang diputar. Dan getaran mekanik ditangkap menggunakan membran mikrofon. Akibatnya, jarum meninggalkan bekas pada kertas timah. Hasilnya, kami menerima silinder dengan catatan. Untuk mereproduksinya, silinder yang sama pada awalnya digunakan seperti saat merekam. Tetapi kertas itu terlalu rapuh dan cepat habis, karena catatan itu berumur pendek. Kemudian mereka mulai menggunakan lilin, yang menutupi silinder. Untuk memperpanjang keberadaan catatan, mereka mulai menyalin menggunakan electroplating. Melalui penggunaan material yang lebih keras, salinannya bertahan lebih lama.
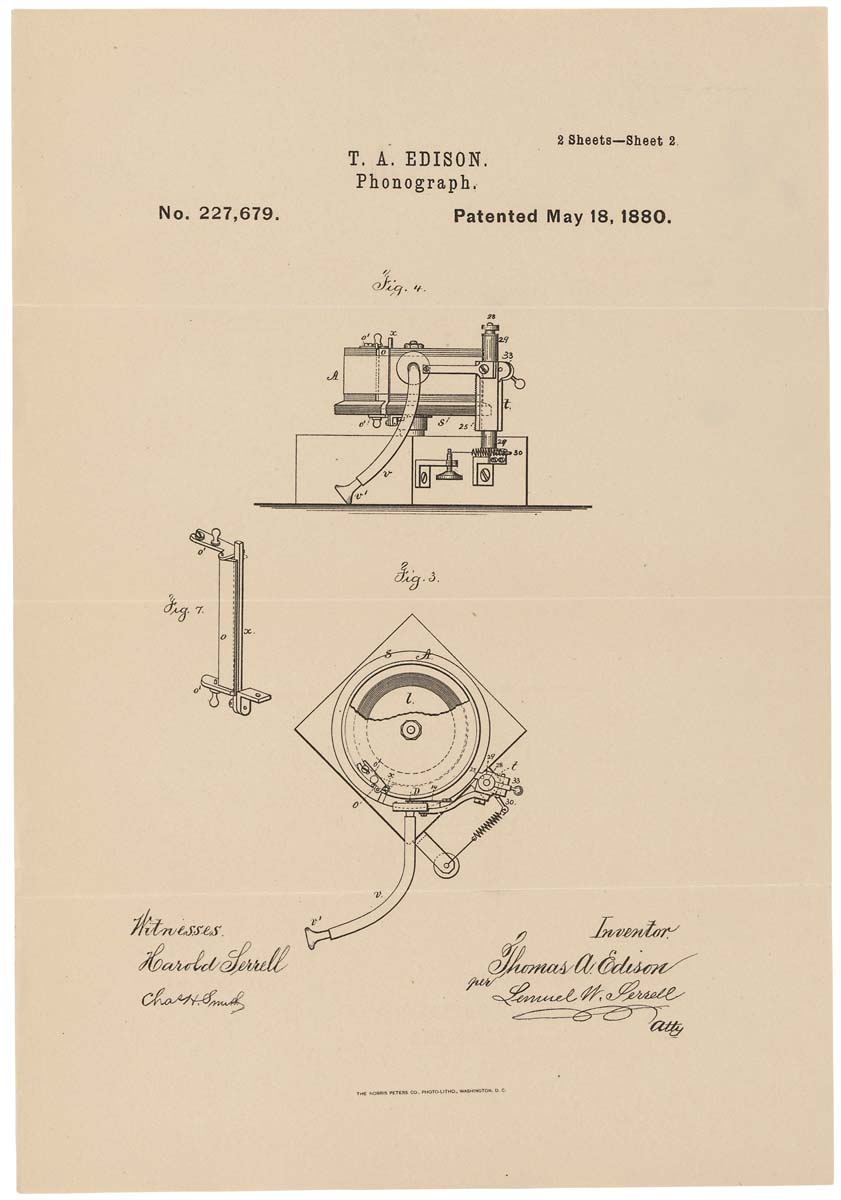 Ilustrasi skematis fonograf pada paten. 1880, 18 Mei
Ilustrasi skematis fonograf pada paten. 1880, 18 MeiMengingat kelemahan-kelemahan di atas, fonograf, meskipun itu adalah mesin yang menarik, tetapi tidak tersapu dari rak. Hanya dengan munculnya piringan hitam disk - lebih dikenal sebagai gramofon - pengakuan publik datang. Kebaruan memungkinkan membuat rekaman lebih lama (fonograf pertama hanya dapat merekam beberapa menit), yang berfungsi untuk waktu yang lama. Dan gramofon itu sendiri dilengkapi dengan speaker yang meningkatkan volume pemutaran.
Thomas Edison awalnya memahami fonograf sebagai alat untuk merekam percakapan telepon, seperti perekam suara modern. Namun, kreasinya telah mendapatkan popularitas besar dalam reproduksi karya musik. Setelah menjabat sebagai awal untuk pembentukan industri rekaman.
Pidato "organ"
Bell Labs terkenal dengan penemuannya di bidang telekomunikasi. Salah satu penemuan tersebut adalah Voder.
Kembali pada tahun 1928, Homer Dudley mulai bekerja pada vocoder, perangkat yang mampu mensintesis ucapan. Kami akan membicarakannya nanti. Sekarang kita akan mempertimbangkan bagiannya - vader.
 Ilustrasi skematis dari seorang vader
Ilustrasi skematis dari seorang vaderPrinsip dasar vader adalah memecah pembicaraan manusia menjadi komponen akustik. Mesin itu sangat kompleks, dan hanya operator terlatih yang bisa mengoperasikannya.
Vader meniru efek dari saluran vokal manusia. Ada 2 suara utama yang bisa dipilih operator dengan pergelangan tangannya. Pedal kaki digunakan untuk mengontrol generator osilasi diskontinyu (suara dengung), yang menciptakan vokal bersuara dan suara hidung. Tabung pelepasan gas (desis) menciptakan sibilants (konsonan fricative). Semua suara ini melewati salah satu dari 10 filter, yang dipilih dengan tombol. Ada juga kunci khusus untuk suara seperti "p" atau "d", dan untuk affricate "j" dalam kata "rahang" dan "ch" dalam kata "keju".
Kutipan kecil dari presentasi vader ini dengan jelas menunjukkan prinsip operasi dan tindakan operatornyaOperator dapat menghasilkan pidato yang dapat dikenali secara sah hanya setelah beberapa bulan berlatih keras dan pelatihan.
Untuk pertama kalinya, pembawa ditunjukkan di sebuah pameran di New York pada tahun 1939.
Menyimpan melalui sintesis ucapan
Sekarang perhatikan seorang vocoder, yang sebagian adalah pengemudi yang disebutkan di atas.
 Salah satu model vocoder: HY-2 (1961)
Salah satu model vocoder: HY-2 (1961)Vokoder ini awalnya dimaksudkan untuk menghemat sumber daya frekuensi tautan radio saat mengirim pesan suara. Alih-alih suara itu sendiri, nilai-nilai parameter spesifiknya dikirim, yang diproses oleh synthesizer ucapan di output.
Dasar dari vocoder adalah tiga sifat utama:
- generator kebisingan (suara konsonan);
- generator nada (vokal);
- filter formal (menciptakan karakteristik individu pembicara).
Terlepas dari tujuannya yang serius, sang vocoder menarik perhatian para musisi elektronik. Mengubah sinyal sumber dan memutarnya di perangkat lain memungkinkan untuk mencapai berbagai efek, seperti efek alat musik yang bernyanyi dalam "suara manusia".
Mesin hitung
Kembali pada tahun 1952, teknologi tidak semaju seperti sekarang. Tetapi ini tidak menghentikan para ilmuwan yang antusias untuk menetapkan diri mereka tugas yang mustahil, menurut banyak orang. Jadi tuan-tuan Stephen Balashek (S. Balashek), Ralon Biddulf (R. Biddulph) dan K.Kh. Davis (KH Davis) memutuskan untuk mengajarkan mesin untuk memahami ucapan mereka. Mengikuti gagasan itu, mobil Audrey muncul. Kemampuannya sangat terbatas - dia hanya bisa mengenali angka dari 0 hingga 9. Tapi ini sudah cukup untuk menyatakan dengan aman terobosan dalam teknologi komputer.
 Audrey dengan salah satu penciptanya (menurut internet, koreksi saya jika tidak)
Audrey dengan salah satu penciptanya (menurut internet, koreksi saya jika tidak)Meskipun kemampuannya kecil, Audrey tidak bisa membanggakan dimensi yang sama. Dia adalah "gadis" yang agak besar - kabinet estafet hampir 2 meter, dan semua elemen menempati sebuah ruangan kecil. Yang tidak mengejutkan untuk komputer saat itu.
Prosedur interaksi antara operator dan Audrey juga memiliki beberapa kondisi. Operator mengucapkan kata-kata (angka, dalam hal ini) ke dalam handset telepon biasa, selalu menjaga jeda selama 350 milidetik di antara setiap kata. Audrey menerima informasi itu, menerjemahkannya ke dalam format elektronik dan menyalakan bola lampu khusus yang sesuai dengan angka tertentu. Belum lagi fakta bahwa tidak setiap operator bisa mendapatkan jawaban yang tepat. Untuk mencapai akurasi 97%, operator harus menjadi orang yang telah berlatih "obrolan" dengan Audrey untuk waktu yang lama. Dengan kata lain, Audrey hanya mengerti penciptanya.
Bahkan dengan mempertimbangkan semua kekurangan Audrey, yang tidak terkait dengan kesalahan desain, tetapi dengan keterbatasan teknologi pada masa itu, ia menjadi bintang pertama di cakrawala mesin yang memahami suara manusia.
Masa depan di kotak sepatu
Pada tahun 1961, di IBM Advanced Systems Development Laboratory, perangkat keajaiban baru dikembangkan - Shoebox, yang dapat mengenali 16 kata (dalam bahasa Inggris secara eksklusif) dan angka dari 0 hingga 9. Penulis komputer ini adalah William C. Dersch.
 Kotak sepatu dari IBM
Kotak sepatu dari IBMNama yang tidak biasa berhubungan dengan penampilan mesin, itu ukuran dan bentuk seperti kotak sepatu. Satu-satunya hal yang menarik perhatian saya adalah mikrofon, yang terhubung ke tiga filter audio yang diperlukan untuk mengenali suara tinggi, sedang dan rendah. Filter dihubungkan ke decoder logika (rangkaian logika dioda-transistor) dan mekanisme sakelar cahaya.
Operator membawa mikrofon ke mulutnya dan mengucapkan sepatah kata (misalnya, nomor 7). Mesin mengubah data akustik menjadi sinyal elektronik. Hasil dari pemahaman adalah dimasukkannya bola lampu dengan tanda tangan "7". Selain memahami kata-kata individual, Shoebox dapat memahami masalah aritmatika sederhana (seperti 5 + 6 atau 7-3) dan memberikan jawaban yang benar.
Shoebox diperkenalkan oleh penciptanya pada tahun 1962 di Seattle World Expo.
Percakapan telepon dengan mobil
Pada tahun 1971, IBM, yang dikenal karena kecintaannya pada penemuan dan teknologi inovatif, memutuskan untuk mempraktikkan pengenalan ucapan. Sistem Identifikasi Panggilan Otomatis memungkinkan seorang insinyur yang berlokasi di mana saja di Amerika Serikat untuk memanggil komputer di Raleigh, North Carolina. Penelepon dapat mengajukan pertanyaan dan menerima jawaban suara untuk itu. Keunikan sistem ini adalah memahami banyak suara, mengingat nada suara, penekanan, volume suara, dll.
Harpy melambung tinggi
Kantor Proyek Penelitian Lanjutan Departemen Pertahanan (DARPA) mengumumkan peluncuran pengembangan pengenalan suara dan program penelitian pada tahun 1971 yang bertujuan untuk menciptakan mesin yang dapat mengenali 1.000 kata. Sebuah proyek yang berani, mengingat keberhasilan pendahulunya, dalam puluhan kata. Tetapi tidak ada batasan untuk sumber daya manusia. Dan pada tahun 1976, Universitas Carnegie Mellon menunjukkan Harpy, yang mampu mengenali 1011 kata.
Peragaan Video HarpyUniversitas telah mengembangkan sistem pengenalan ucapan - Hearsay-1 dan Dragon. Mereka digunakan sebagai dasar untuk menerapkan Harpy.
Dalam Hearsay-1, pengetahuan (mis., Kamus mesin) diwakili dalam bentuk prosedur, dan dalam Dragon - dalam bentuk jaringan Markov dengan transisi probabilistik a priori. Di Harpy, diputuskan untuk menggunakan model terbaru, tetapi tanpa transisi ini.
Dalam video ini, prinsip operasi dijelaskan secara lebih rinci.
Sederhananya, Anda dapat menggambarkan jaringan - urutan kata dan kombinasinya, serta suara dengan satu kata, agar mesin memahami pengucapan yang berbeda dari kata yang sama.
Harpy mengerti 5 operator, termasuk tiga pria dan dua wanita. Itu berbicara tentang kemampuan komputasi yang lebih besar dari mesin ini. Akurasi pengenalan suara adalah sekitar 95%.
Tangora oleh IBM
Pada awal 1980-an, IBM memutuskan untuk mengembangkan sistem yang mampu mengenali lebih dari 20.000 kata pada pertengahan dekade ini. Jadi Tangora lahir, dalam karya yang model Markov tersembunyi digunakan. Terlepas dari kosakata yang agak mengesankan, sistem ini membutuhkan tidak lebih dari 20 menit kolaborasi dengan operator baru (orang yang berbicara) untuk belajar bagaimana mengenali pidatonya.
Boneka hidup
Pada tahun 1987, perusahaan mainan Worlds of Wonder merilis novel revolusioner - boneka yang berbicara bernama Julie. Fitur yang paling mengesankan dari mainan Denmark adalah kemampuan untuk melatihnya mengenali ucapan pemiliknya. Julie bisa berbicara dengan cukup baik. Selain itu, boneka itu dilengkapi dengan banyak sensor, berkat yang bereaksi ketika diambil, digelitik, atau dipindahkan dari ruang gelap ke ruang terang.
Iklan Worlds of Wonder Julie menampilkan fitur-fiturnyaMata dan bibirnya bergerak, yang menciptakan gambar yang lebih hidup. Selain boneka itu sendiri, dimungkinkan untuk membeli buku di mana gambar dan kata-kata dibuat dalam bentuk stiker khusus. Jika Anda memegang boneka dengan jari Anda di atasnya, maka itu akan menyuarakan apa yang "terasa" saat disentuh. Doll Julie adalah perangkat pertama dengan fungsi pengenalan ucapan, yang tersedia untuk siapa saja.
Perangkat lunak dikte pertama

Pada tahun 1990, Dragon Systems merilis perangkat lunak komputer pribadi pertama berdasarkan pengakuan ucapan - DragonDictate. Program ini bekerja secara eksklusif di Windows. Pengguna harus membuat jeda kecil di antara setiap kata sehingga program dapat menguraikannya. Di masa depan, versi yang lebih sempurna muncul yang memungkinkan Anda untuk berbicara terus menerus - Dragon NaturallySpeaking (itu yang tersedia sekarang, sementara DragonDictate asli telah berhenti memperbarui sejak Windows 98). Meskipun "lambat", DragonDictate telah mendapatkan popularitas besar di kalangan pengguna PC, terutama di antara para penyandang cacat.
Sphinx non-Mesir
Universitas Carnegie Mellon, yang telah "menyala" sebelumnya, telah menjadi tempat kelahiran sistem pengenalan suara yang penting secara historis - Sphinx 2.
 Pencipta Sphinx Xuedong Huang
Pencipta Sphinx Xuedong HuangPenulis langsung sistem tersebut adalah Xuedong Huang. Sphinx 2 dibedakan dari pendahulunya oleh kecepatannya. Sistem ini difokuskan pada pengenalan suara waktu-nyata untuk program yang menggunakan bahasa lisan (sehari-hari). Di antara fitur-fitur Sphinx 2 adalah: pembentukan hipotesis, beralih dinamis antara model bahasa, deteksi padanan, dll.
Kode Sphinx 2 telah digunakan di banyak produk komersial. Dan pada tahun 2000, di situs web SourceForge, Kevin Lenzo memposting kode sumber sistem untuk tampilan umum. Mereka yang ingin mempelajari kode sumber Sphinx 2 dan variasi lainnya dapat mengikuti
tautan .
Dikte medis
Pada tahun 1996, IBM meluncurkan MedSpeak, produk komersial pertama dengan pengenalan suara. Seharusnya menggunakan program ini di dokter untuk menyusun catatan medis. Sebagai contoh, seorang ahli radiologi, yang memeriksa gambar-gambar pasien, menyuarakan komentarnya, yang diterjemahkan oleh sistem MedSpeak ke dalam teks.
Sebelum beralih ke perwakilan paling terkenal dari program dengan pengenalan ucapan, mari kita cepat, secara singkat, melihat beberapa peristiwa sejarah yang terkait dengan teknologi ini.
Blitz bersejarah
- 2002 - Microsoft mengintegrasikan pengenalan ucapan ke semua produk Office;
- 2006 - Badan Keamanan Nasional AS mulai menggunakan program pengenalan ucapan untuk mengidentifikasi kata kunci batas dalam catatan percakapan;
- 2007 (30 Januari) - Microsoft merilis Windows Vista - OS pertama dengan pengenalan suara;
- 2007 - Google memperkenalkan GOOG-411 - sistem penerusan telepon (seseorang memanggil nomor, mengatakan organisasi atau orang mana yang ia butuhkan dan sistem menghubungkannya). Sistem ini bekerja di AS dan Kanada;
- 2008 (14 November) - Google meluncurkan pencarian suara di perangkat seluler iPhone. Ini adalah penggunaan pertama teknologi pengenalan suara di ponsel;
Dan sekarang kita sampai pada periode waktu ketika banyak orang menemukan teknologi pengenalan suara.
Wanita tidak bertengkar
Pada tanggal 4 Oktober 2011, Apple mengumumkan Siri, yang memecahkan kode nama yang berbicara sendiri - Antarmuka Pidato dan Pengenalan (yaitu, Antarmuka dan Antarmuka Pengenalan Pidato).

Sejarah perkembangan Siri sangat panjang (pada kenyataannya, ia memiliki 40 tahun kerja) dan menarik. Fakta keberadaannya dan fungsinya yang luas adalah kerja bersama dari banyak perusahaan dan universitas. Namun, kami tidak akan fokus pada produk ini, karena artikelnya bukan tentang Siri, tetapi tentang pengenalan ucapan secara umum.
Microsoft tidak ingin merumput kembali, karena pada tahun 2014 (2 April) mereka mengumumkan asisten digital virtual mereka Cortana.

Fungsi Cortana mirip dengan saingannya Siri, dengan pengecualian sistem yang lebih fleksibel untuk mengatur akses ke informasi.
Debat tentang Cortana atau Siri. Siapa yang lebih baik? " dilakukan sejak penampilan mereka di pasar. Seperti, secara umum, dan perjuangan antara pengguna iOS dan Android. Tapi itu bagus. Produk-produk yang bersaing, dalam upaya terlihat lebih baik dari pesaing mereka, akan memberikan lebih banyak peluang baru, mengembangkan dan menggunakan teknologi dan teknik yang lebih maju dalam bidang pengenalan ucapan yang sama. Hanya memiliki satu perwakilan di bidang teknologi konsumen, tidak perlu membicarakan perkembangannya yang cepat.
Sebuah video lucu dari percakapan antara Siri dan Cortana (jelas dibuat, tapi tidak kalah lucu). Perhatian!: Di video ini ada kata-kata kotor.
Percakapan dengan mobil. Bagaimana mereka memahami kita?
Seperti yang saya sebutkan sebelumnya, secara kasar, bicara adalah suara. Dan apa suara untuk mobil itu? Ini adalah perubahan (fluktuasi) dalam tekanan udara, mis. gelombang suara. Agar mesin (komputer atau telepon) dapat mengenali ucapan, Anda harus terlebih dahulu membaca getaran ini. Frekuensi pengukuran harus minimal 8.000 kali per detik (bahkan lebih baik - 44.100 kali per detik). Jika pengukuran dilakukan dengan interupsi waktu besar, maka kita akan mendapatkan suara yang tidak akurat, yang berarti ucapan tidak terbaca. Proses yang dijelaskan di atas disebut sebagai digitalisasi 8kHz atau 44.1kHz.
Ketika data tentang getaran gelombang suara dikumpulkan, mereka perlu disortir. Karena dalam tumpukan umum kita memiliki suara bicara dan sekunder (suara mesin, kertas gemerisik, suara komputer yang bekerja, dll.). Melakukan operasi matematika memungkinkan kita untuk mengeluarkan pidato kita dengan tepat, yang membutuhkan pengakuan.
Selanjutnya adalah analisis gelombang suara yang dipilih - pidato. Karena terdiri dari banyak komponen terpisah yang membentuk suara tertentu (misalnya, "ah" atau "ee"). Menyoroti fitur-fitur ini dan mengubahnya menjadi ekuivalen numerik memungkinkan Anda untuk mendefinisikan kata-kata tertentu.
, , 40 (44, , 100), .. . , , . . , , «» , ( , , , ..), . , «t» «sTar» «t» «ciTy» -.
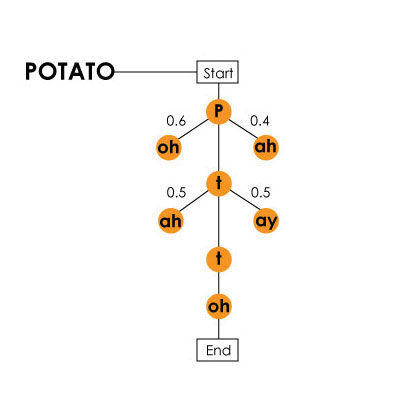 «potato» () / Harpy
«potato» () / Harpy, , . , «hang ten», — «hey, ngten», «ngten».
, , . , (), , №2 №1. «What do cats like for breakfast?» «water gaslight four brick vast?». , . . , , , . .
, . , , .
, . . - , ( , ), . . , , , . , -, , .
. 25% 3 6 !
! VPS (KVM) , , — !
VPS (KVM) c ( VPS (KVM) — E5-2650v4 (6 Cores) / 10GB DDR4 / 240GB SSD 4TB HDD / 1Gbps 10TB — $29 / , RAID1 RAID10) , , , , , «»!
. c Dell R730xd 5-2650 v4 9000 ? Dell R730xd 2 ? 2 Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 $249 !