
Selama dekade terakhir, Deep Neural Networks (DNNs) telah menjadi alat yang sangat baik untuk sejumlah tugas AI seperti klasifikasi gambar, pengenalan ucapan, dan bahkan partisipasi dalam permainan. Ketika pengembang mencoba menunjukkan apa yang menyebabkan keberhasilan DNN di bidang klasifikasi gambar, dan menciptakan alat visualisasi (misalnya, Deep Dream, Filter) yang membantu memahami "apa" yang sebenarnya "mempelajari" model DNN, muncul aplikasi baru yang menarik. : mengekstraksi "gaya" dari satu gambar dan menerapkan ke konten lain yang berbeda. Ini disebut "transfer gaya gambar".
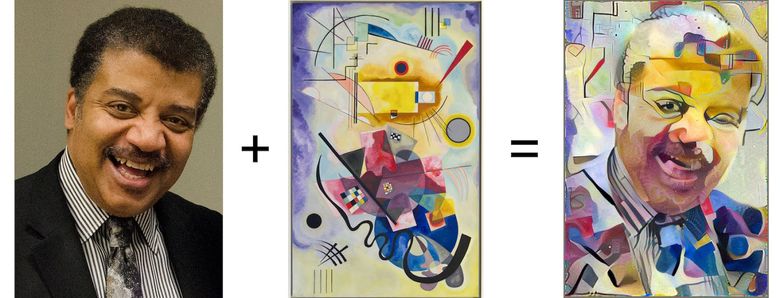
Kiri: gambar dengan konten yang bermanfaat, di tengah: gambar dengan gaya, kanan: konten + gaya (sumber: Google Research Blog )
Ini tidak hanya membangkitkan minat banyak peneliti lain (misalnya, 1 dan 2 ), tetapi juga menyebabkan munculnya beberapa aplikasi seluler yang sukses. Selama beberapa tahun terakhir, metode transfer gaya visual ini telah meningkat pesat.

Pembungkus gaya Adobe (sumber: Engadget )

Contoh dari situs web Prisma
Pengantar singkat untuk algoritma tersebut:
Namun, terlepas dari kemajuan dalam bekerja dengan gambar, penerapan teknik ini di bidang lain, misalnya, untuk memproses musik, sangat terbatas (lihat 3 dan 4 ), dan hasilnya sama sekali tidak mengesankan seperti dalam kasus gambar. Ini menunjukkan bahwa jauh lebih sulit untuk mentransfer gaya dalam musik. Pada artikel ini, kami akan memeriksa masalah secara lebih rinci dan membahas beberapa pendekatan yang mungkin.
Mengapa begitu sulit untuk mentransfer gaya dalam musik?
Mari kita jawab pertanyaan pertama: apa itu "transfer gaya" dalam musik ? Jawabannya tidak begitu jelas. Dalam gambar, konsep "konten" dan "gaya" adalah intuitif. "Konten Gambar" menggambarkan objek yang diwakili, misalnya, anjing, rumah, wajah, dan sebagainya, dan "gaya gambar" mengacu pada warna, pencahayaan, sapuan kuas, dan tekstur.
Namun, musik bersifat semantik abstrak dan multidimensi . "Konten Musik" dapat memiliki arti yang berbeda dalam konteks yang berbeda. Seringkali, isi musik dikaitkan dengan melodi, dan gaya dengan pengaturan atau harmonisasi. Namun, isinya mungkin berupa lirik, dan melodi yang berbeda yang digunakan untuk menyanyi dapat diartikan sebagai gaya yang berbeda. Dalam musik klasik, konten dapat dianggap sebagai skor (yang mencakup harmonisasi), sedangkan gaya adalah interpretasi dari catatan oleh pemain, yang membawa ekspresinya sendiri (memvariasikan dan menambahkan beberapa suara dari dirinya sendiri). Untuk lebih memahami esensi transfer gaya dalam musik, lihat beberapa video ini:
Dalam video kedua, berbagai teknik pembelajaran mesin digunakan.
Jadi, transfer gaya dalam musik, menurut definisi, sulit untuk diformalkan. Ada faktor kunci lain yang menyulitkan tugas:
- Mesin BAD memahami musik (untuk saat ini): keberhasilan dalam mentransfer gaya dalam gambar berasal dari keberhasilan DNN dalam tugas yang berkaitan dengan memahami gambar, seperti pengenalan objek. Karena DNN dapat mempelajari properti yang bervariasi antar objek, teknik propagasi balik dapat digunakan untuk memodifikasi gambar target agar sesuai dengan properti konten. Meskipun kami telah membuat kemajuan yang signifikan dalam menciptakan model berbasis DNN yang mampu memahami tugas-tugas musik (misalnya, menyalin melodi, mendefinisikan genre, dll.), Kami masih jauh dari ketinggian yang dicapai dalam pemrosesan gambar. Ini adalah hambatan serius untuk transfer gaya dalam musik. Model yang ada tidak bisa mempelajari sifat "luar biasa" yang memungkinkan untuk mengklasifikasikan musik, yang berarti bahwa aplikasi langsung dari algoritma transfer gaya yang digunakan ketika bekerja dengan gambar tidak memberikan hasil yang sama.
- Musik cepat berlalu : itu adalah data yang mewakili deret dinamis, yaitu fragmen musik berubah seiring waktu. Ini menyulitkan pembelajaran. Meskipun jaringan saraf berulang dan LSTM (Long Short-Term Memory) memungkinkan Anda untuk belajar lebih banyak dari data sementara, kami masih harus membuat model yang andal yang dapat mempelajari cara mereproduksi struktur musik jangka panjang (catatan: ini adalah bidang penelitian aktual, dan para ilmuwan dari tim Google Magenta telah mencapai beberapa keberhasilan dalam hal ini ).
- Musik itu diskrit (setidaknya pada tingkat simbolik): simbolis, atau musik yang direkam di atas kertas, bersifat diskrit. Dalam temperamen seragam , sistem tuning alat musik paling populer saat ini, nada suara menempati posisi diskrit pada skala frekuensi terus menerus. Pada saat yang sama, durasi nada juga terletak di ruang diskrit (biasanya seperempat nada, nada penuh dan sebagainya). Oleh karena itu, sangat sulit untuk mengadaptasi metode propagasi kembali piksel (digunakan untuk bekerja dengan gambar) di bidang musik simbolik.
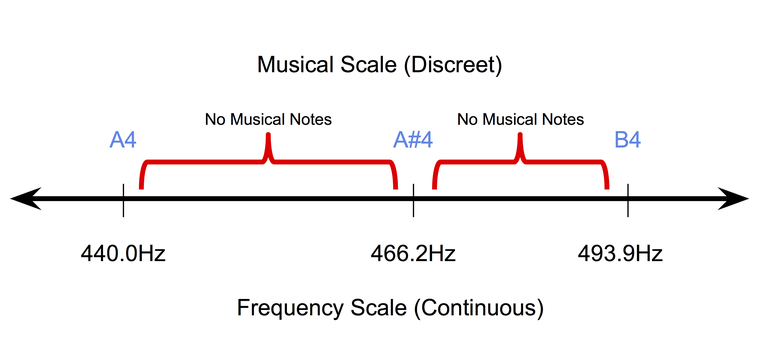
Sifat diskrit catatan musik dalam temperamen seragam.
Oleh karena itu, teknik yang digunakan untuk mentransfer gaya dalam gambar tidak secara langsung berlaku untuk musik. Untuk melakukan ini, mereka perlu diproses dengan penekanan pada konsep dan ide musik.
Untuk apa gaya transfer musik?
Mengapa Anda perlu mengatasi masalah ini? Seperti halnya gambar, potensi penggunaan gaya transfer dalam musik cukup menarik. Misalnya, mengembangkan alat untuk membantu komposer . Misalnya, instrumen otomatis yang mampu mengubah melodi menggunakan pengaturan dari genre yang berbeda akan sangat berguna bagi komposer yang perlu dengan cepat mencoba ide yang berbeda. DJ juga akan tertarik pada instrumen seperti itu.
Hasil tidak langsung dari penelitian tersebut akan menjadi peningkatan yang signifikan dalam sistem informatika musikal. Seperti dijelaskan di atas, agar pemindahan gaya bekerja dalam musik, model yang kita buat harus belajar untuk lebih "memahami" berbagai aspek.
Sederhanakan tugas mentransfer gaya dalam musik
Mari kita mulai dengan tugas yang sangat sederhana untuk menganalisis melodi monofonik dalam genre yang berbeda. Melodi monofonik adalah urutan not, yang masing-masing ditentukan oleh nada dan durasi. Progresi pitch sebagian besar tergantung pada skala melodi, dan progres durasinya tergantung pada ritme. Jadi pertama-tama, kami dengan jelas memisahkan " konten nada" dan "gaya ritmis" sebagai dua entitas yang dengannya Anda dapat menguraikan kembali tugas mentransfer gaya. Juga, ketika bekerja dengan melodi monofonik, kita sekarang akan menghindari tugas yang terkait dengan pengaturan dan teks.
Dengan tidak adanya model pra-terlatih yang dapat berhasil membedakan antara perkembangan nada dan ritme melodi monophonic, pertama-tama kita menggunakan pendekatan yang sangat sederhana untuk mentransfer gaya. Alih-alih mencoba mengubah konten nada yang dipelajari pada melodi target dengan gaya ritmis yang dipelajari pada ritme target, kami akan mencoba mengajarkan secara individual pola-pola nada dan durasi dari genre yang berbeda, dan kemudian mencoba menggabungkannya. Skema pendekatan perkiraan:
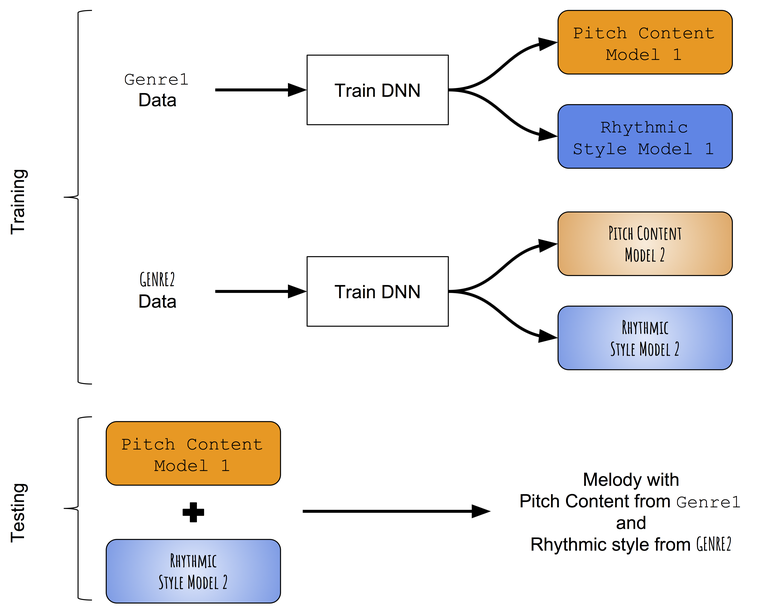
Skema metode transfer gaya antar generasi.
Kami mengajarkan secara terpisah perkembangan nada dan ritme
Presentasi data
Kami akan menyajikan melodi monofonik sebagai urutan catatan musik, yang masing-masing memiliki indeks nada dan urutan. Agar kunci presentasi kami menjadi independen, kami akan menggunakan presentasi berdasarkan interval: nada catatan berikutnya akan disajikan sebagai penyimpangan (± semitone) dari nada catatan sebelumnya. Mari kita buat dua kamus untuk nada dan durasi di mana masing-masing keadaan diskrit (untuk nada: +1, -1, +2, -2, dan seterusnya; untuk jangka waktu: not seperempat, not penuh, seperempat dengan titik, dan sebagainya) diberikan indeks kamus.
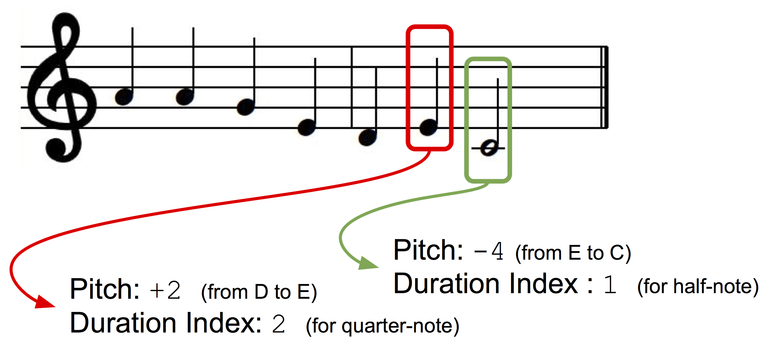
Penyajian data.
Arsitektur model
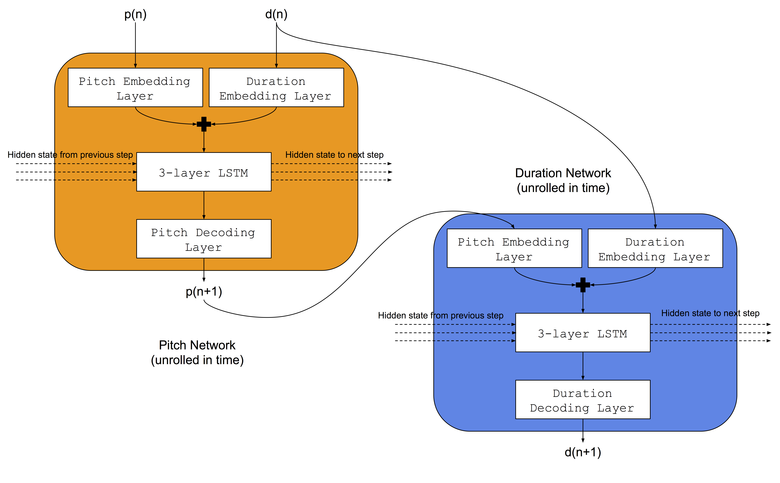
Kami akan menggunakan arsitektur yang sama seperti yang digunakan Colombo dan rekan - mereka secara bersamaan mengajarkan dua jaringan saraf LSTM ke genre musik yang sama: a) jaringan nada belajar untuk memprediksi nada berikutnya berdasarkan catatan sebelumnya dan durasi sebelumnya, b) durasi jaringan belajar untuk memprediksi durasi berikutnya berdasarkan catatan berikutnya dan durasi sebelumnya. Selain itu, sebelum jaringan LSTM, kami akan menambahkan layer embedding untuk membandingkan indeks dan durasi nada input dalam ruang embed yang dihafalkan. Arsitektur jaringan saraf ditunjukkan pada gambar:
Prosedur pelatihan
Untuk setiap genre, jaringan yang bertanggung jawab untuk nada dan durasi dilatih pada saat yang sama. Kami akan menggunakan dua dataset: a) Norbeck Folk Dataset , yang mencakup sekitar 2.000 melodi rakyat Irlandia dan Swedia, b) dataset jazz (tidak tersedia untuk umum), mencakup sekitar 500 lagu jazz.
Menggabungkan model terlatih
Selama pengujian, melodi pertama kali dihasilkan menggunakan jaringan nada dan jaringan durasi yang dilatih dalam genre pertama (misalnya, folk). Kemudian urutan nada dari melodi yang dihasilkan digunakan pada input untuk jaringan urutan yang dilatih dalam genre lain (katakanlah, jazz), dan hasilnya adalah urutan durasi baru. Oleh karena itu, melodi yang dibuat menggunakan kombinasi dua jaringan saraf memiliki urutan nada yang sesuai dengan genre pertama (folk) dan urutan durasi yang sesuai dengan genre kedua (jazz).
Hasil Awal
Kutipan singkat dari beberapa lagu yang dihasilkan:
Nada Rakyat dan Durasi Rakyat

Ekstrak dari notasi musik.
Nada Rakyat dan Durasi Jazz

Ekstrak dari notasi musik.
Nada dan urutan jazz

Ekstrak dari notasi musik .
Nada dan urutan folk jazz

Ekstrak dari notasi musik.
Kesimpulan
Meskipun algoritma saat ini tidak buruk untuk memulai, ia memiliki sejumlah kelemahan kritis:
- Tidak mungkin untuk "mentransfer gaya" berdasarkan melodi target tertentu . Model mempelajari pola nada dan durasi dalam suatu genre, yang berarti bahwa semua transformasi ditentukan oleh genre. Akan ideal untuk memodifikasi karya musik dengan gaya lagu atau karya target tertentu.
- Tidak mungkin mengontrol tingkat perubahan gaya. Akan sangat menarik untuk mendapatkan "pegangan" yang mengatur aspek ini.
- Saat menggabungkan genre, tidak mungkin mempertahankan struktur musik dalam melodi yang ditransformasikan. Struktur jangka panjang penting untuk evaluasi musik secara umum, dan agar melodi yang dihasilkan menjadi estetis musik, struktur tersebut harus dilestarikan.
Dalam artikel berikut, kita akan melihat cara untuk menghindari kekurangan ini.