Contoh operasi AttnGAN. Di baris atas adalah beberapa gambar dengan resolusi berbeda yang dihasilkan oleh jaringan saraf. Baris kedua dan ketiga menunjukkan pemrosesan lima kata yang paling cocok oleh dua model perhatian jaringan saraf untuk menggambar bagian yang paling relevanSecara otomatis membuat gambar dari deskripsi teks dalam bahasa alami adalah masalah mendasar bagi banyak aplikasi, seperti pembuatan seni dan desain komputer. Masalah ini juga merangsang kemajuan dalam bidang pelatihan AI multimodal dengan hubungan antara visi dan bahasa.
Penelitian terbaru oleh para peneliti di bidang ini didasarkan pada jaringan permusuhan generatif (GAN). Pendekatan umum adalah menerjemahkan seluruh deskripsi teks ke dalam vektor kalimat global. Pendekatan ini menunjukkan sejumlah hasil yang mengesankan, tetapi memiliki kelemahan utama: kurangnya detail yang jelas di tingkat kata dan ketidakmampuan untuk menghasilkan gambar resolusi tinggi. Sebuah tim pengembang dari Universitas Lichai, Universitas Rutgers, Universitas Duke (semua - AS) dan Microsoft mengusulkan solusi mereka
sendiri untuk masalah ini: jaringan saraf baru.
Attentional Generative Adversarial Network (AttnGAN) mewakili peningkatan dalam pendekatan tradisional dan memungkinkan perubahan multi-tahap dari gambar yang dihasilkan, mengubah kata-kata individual dalam teks. deskripsi.
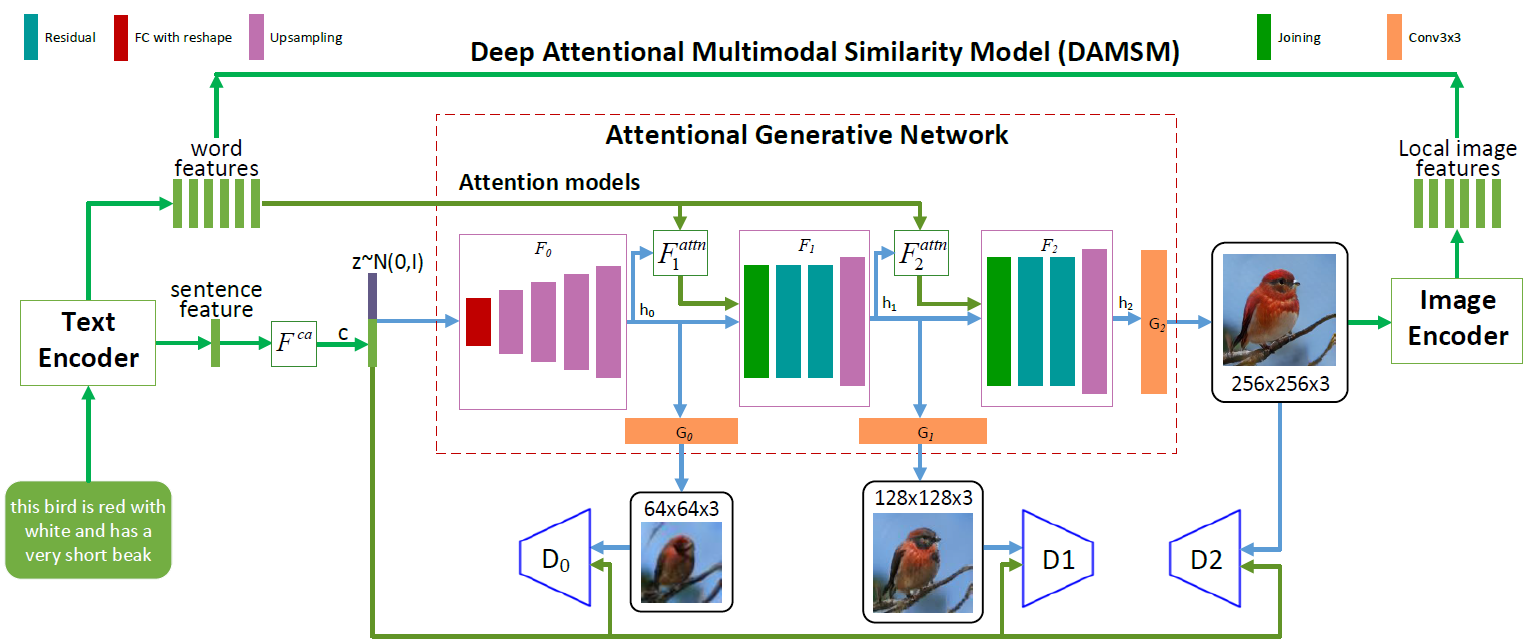 Arsitektur jaringan saraf AttnGAN. Setiap model perhatian secara otomatis menerima kondisi (mis. Vektor kosakata yang sesuai) untuk menghasilkan area gambar yang berbeda. Modul DAMSM menyediakan rincian tambahan untuk fungsi kehilangan kesesuaian dalam terjemahan dari gambar ke teks dalam jaringan generatif
Arsitektur jaringan saraf AttnGAN. Setiap model perhatian secara otomatis menerima kondisi (mis. Vektor kosakata yang sesuai) untuk menghasilkan area gambar yang berbeda. Modul DAMSM menyediakan rincian tambahan untuk fungsi kehilangan kesesuaian dalam terjemahan dari gambar ke teks dalam jaringan generatifSeperti yang dapat Anda lihat dalam ilustrasi yang menggambarkan arsitektur jaringan saraf, model AttnGAN memiliki dua inovasi dibandingkan dengan pendekatan tradisional.
Pertama, ini adalah jaringan permusuhan, yang mengacu pada perhatian sebagai faktor pembelajaran (Attentional Generative Adversarial Network). Artinya, ia mengimplementasikan mekanisme perhatian, yang menentukan kata-kata yang paling cocok untuk menghasilkan bagian gambar yang sesuai. Dengan kata lain, selain mengkode seluruh deskripsi teks dalam ruang vektor global kalimat, setiap kata individual juga dikodekan sebagai vektor teks. Pada tahap pertama, jaringan saraf generatif menggunakan ruang vektor global kalimat untuk membuat gambar resolusi rendah. Dalam langkah-langkah berikut, ia menggunakan vektor gambar di setiap wilayah untuk kueri vektor kamus, menggunakan lapisan perhatian untuk membentuk vektor konteks kata. Kemudian, vektor gambar regional dikombinasikan dengan vektor konteks kata yang sesuai untuk membentuk vektor konteks multimoda, berdasarkan model yang menghasilkan fitur gambar baru di masing-masing daerah. Ini memungkinkan Anda untuk secara efektif meningkatkan resolusi seluruh gambar secara keseluruhan, karena pada setiap tahap ada lebih banyak dan lebih detail.
Inovasi jaringan syaraf kedua Microsoft adalah modul Deep Attentional Multimodal Similarity Model (DAMSM). Menggunakan mekanisme perhatian, modul ini menghitung tingkat kesamaan antara gambar yang dihasilkan dan kalimat teks, menggunakan informasi dari tingkat ruang vektor kalimat dan tingkat vektor kamus yang terinci dengan baik. Dengan demikian, DAMSM memberikan rincian tambahan untuk hilangnya fungsi fit pada terjemahan dari gambar ke teks saat melatih generator.
Berkat dua inovasi ini, jaringan saraf AttnGAN menunjukkan hasil yang jauh lebih baik daripada yang terbaik dari sistem GAN tradisional, tulis pengembang. Secara khusus, skor awal yang diketahui maksimum untuk jaringan saraf yang ada ditingkatkan sebesar 14,14% (dari 3,82 menjadi 4,36) pada dataset CUB dan meningkat sebanyak 170,25% (dari 9,58 menjadi 25,89) pada dataset COCO yang lebih canggih.
Pentingnya perkembangan ini sulit ditaksir terlalu tinggi. Jaringan saraf AttnGAN untuk pertama kalinya menunjukkan bahwa jaringan generatif-permusuhan multilayer, yang merujuk pada perhatian sebagai faktor pembelajaran, dapat secara otomatis menentukan kondisi tingkat kata untuk menghasilkan bagian-bagian individual dari suatu gambar.
Artikel ilmiah ini
diterbitkan pada 28 November 2017 di situs pracetak arXiv.org (arXiv: 1711.10485v1).