Pengembang Google Brain telah membuktikan bahwa gambar "yang bertentangan" dapat menampung orang dan komputer; dan kemungkinan konsekuensinya menakutkan.
Pada gambar di atas - di sebelah kiri tidak ada keraguan kucing. Tetapi dapatkah Anda mengatakan dengan pasti apakah kucing itu di sebelah kanan, atau hanya seekor anjing yang mirip dengannya? Perbedaan antara keduanya adalah bahwa yang benar dibuat menggunakan algoritma khusus yang tidak memberikan model komputer yang disebut "jaringan saraf convolutional" (CNNs), yang jelas menyimpulkan bahwa dalam gambar. Dalam hal ini, SNS percaya bahwa ini lebih dari seekor anjing daripada kucing, tetapi yang paling menarik - kebanyakan orang berpikir dengan cara yang sama.
Ini adalah contoh dari apa yang disebut "gambar kontradiktif" (selanjutnya disebut sebagai KARP): ini dimodifikasi secara khusus untuk menipu SNA dan mencegah konten diidentifikasi secara benar. Para peneliti di Google Brain ingin memahami apakah mungkin untuk membuat kerusakan jaringan saraf biologis di kepala kita dengan cara yang sama, dan sebagai hasilnya menciptakan opsi yang sama-sama memengaruhi mobil dan orang, membuat mereka berpikir bahwa mereka sedang melihat sesuatu yang tidak juga.
Apa itu gambar yang saling bertentangan?
Hampir di mana-mana, untuk pengakuan dalam SNA, algoritma klasifikasi visual digunakan. Dengan "menunjukkan" program sejumlah besar ilustrasi berbeda dengan panda, Anda dapat melatihnya untuk mengenali panda, karena panda belajar dengan perbandingan untuk memilih fitur umum untuk seluruh rangkaian. Segera setelah SNA (juga disebut
"classifier" ) mengumpulkan cukup banyak "tanda-tanda panda" pada data pelatihan, ia akan dapat mengenali panda dalam gambar baru apa pun yang akan diberikannya.
Kami mengenali panda dengan karakteristik abstraknya: telinga hitam kecil, kepala putih besar, mata hitam, bulu, dan semua jazz itu. SNA melakukan sebaliknya, yang tidak mengejutkan, karena jumlah informasi tentang lingkungan yang ditafsirkan orang setiap menit jauh lebih besar. Oleh karena itu, dengan mempertimbangkan spesifikasi model, dimungkinkan untuk memengaruhi gambar sedemikian rupa sehingga membuatnya "tidak konsisten" dengan mencampurkan dengan data yang dihitung dengan cermat, setelah itu hasilnya bagi seseorang akan terlihat hampir seperti aslinya, tetapi sangat berbeda untuk
pengklasifikasi , yang akan mulai membuat kesalahan ketika mencoba untuk menentukan isi.
Berikut ini adalah contoh panda:
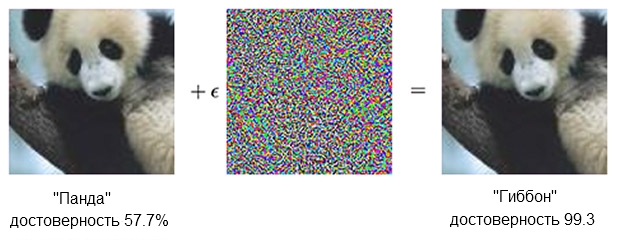 Gambar panda, dikombinasikan dengan amarah, dapat meyakinkan penggolong bahwa itu sebenarnya adalah siamang.Sumber: OpenAIPengklasifikasi
Gambar panda, dikombinasikan dengan amarah, dapat meyakinkan penggolong bahwa itu sebenarnya adalah siamang.Sumber: OpenAIPengklasifikasi berdasarkan SNA yakin bahwa panda di sebelah kiri adalah sekitar 60%. Tetapi jika Anda sedikit menambah ("membuat kemarahan") sumber dengan menambahkan apa yang tampak seperti kebisingan yang kacau, penggolong yang sama akan 99,3 persen yakin bahwa itu sekarang melihat siamang. Perubahan kecil yang bahkan tidak dapat dilihat dengan jelas menimbulkan serangan yang sangat sukses, tetapi itu hanya akan bekerja pada model komputer tertentu dan tidak akan melakukan hal-hal yang dapat "dipelajari" pada hal lain.
Untuk membuat konten yang memicu reaksi yang salah di antara sejumlah besar analis buatan, orang harus bertindak lebih kasar - koreksi kecil tidak akan mempengaruhi. Apa yang bekerja dengan andal tidak dapat dilakukan dengan "cara kecil." Dengan kata lain, jika Anda ingin konten bekerja dari semua sudut dan jarak, maka Anda harus melakukan intervensi lebih signifikan, atau seperti yang dikatakan seseorang, lebih jelas.
Di depan mata - seorang pria
Berikut adalah dua contoh Carp yang kasar, di mana seseorang dapat dengan mudah mendeteksi gangguan.
 Sumber: Buka AI di sebelah kiri, Google Brain di sebelah kanan
Sumber: Buka AI di sebelah kiri, Google Brain di sebelah kananGambar kucing di sebelah kiri, yang didefinisikan SNS sebagai komputer, dibuat menggunakan "geometri patah". Jika Anda melihat lebih dekat (atau bahkan tidak terlalu dekat), Anda akan melihat bahwa ada beberapa struktur bersudut dan berbentuk kotak yang dapat menyerupai bentuk unit sistem. Dan gambar pisang di sebelah kanan, yang diakui sebagai pemanggang roti, terus memberikan positif palsu dari sudut pandang apa pun. Orang-orang saat ini akan menemukan pisang di sini, namun alat aneh di sebelahnya memiliki beberapa tanda pemanggang roti - dan ini membuat teknologi menjadi bodoh.
Ketika Anda membuat gambar "kontradiktif" yang dijamin sesuai yang Anda butuhkan untuk mengalahkan seluruh perusahaan yang mengenali model, maka sangat sering hal ini mengarah pada penampilan "faktor manusia". Dengan kata lain, apa yang membingungkan jaringan saraf tunggal mungkin tidak dianggap sebagai masalah sama sekali, dan ketika Anda mencoba untuk mendapatkan rebus yang pasti cocok untuk menipu lima atau sepuluh sekaligus, ternyata itu bekerja berdasarkan mekanisme yang, jika orang sama sekali tidak berguna.
Akibatnya, sama sekali tidak perlu mencoba memaksa seseorang untuk percaya bahwa kucing bersudut adalah kasus komputer, dan jumlah pisang dan memulas aneh tampak seperti pemanggang roti. Jauh lebih baik ketika membuat CARP yang dirancang untuk Anda dan saya untuk segera fokus menggunakan model yang memandang dunia seperti yang dilakukan orang.
Menipu mata (dan otak)
SNA dengan pelatihan mendalam dan visi manusia agak mirip, tetapi pada dasarnya jaringan saraf "melihat" hal-hal "dengan cara seperti komputer". Misalnya, ketika dia diberi makan gambar, dia "melihat" kotak statis piksel persegi pada saat yang sama. Mata bekerja secara berbeda, seseorang merasakan detail tinggi di sektor sekitar lima derajat pada setiap sisi garis pandang, tetapi di luar zona ini, perhatian terhadap detail menurun secara linear.
Dengan demikian, tidak seperti mesin, katakanlah, mengaburkan tepi gambar tidak akan bekerja dengan seseorang dan hanya akan luput dari perhatian. Para peneliti dapat mensimulasikan fitur ini dengan menambahkan "lapisan retina" yang mengubah data yang dipasok oleh SNA menjadi seperti apa mata, dengan tujuan membatasi jaringan saraf ke kerangka yang sama dengan penglihatan normal.
Perlu dicatat bahwa seseorang mengatasi kekurangan persepsinya dengan fakta bahwa tatapan itu tidak diarahkan ke satu titik, tetapi terus bergerak, memeriksa seluruh gambar, tetapi juga memungkinkan untuk mengimbangi kondisi percobaan, meratakan perbedaan antara SNA dan orang-orang.
Catatan dari karya itu sendiri:
Setiap percobaan dimulai dengan crosshair pemasangan, yang muncul di tengah layar selama 500-1000 milidetik, dan setiap subjek diperintahkan untuk memperbaiki pandangannya pada crosshair.Penggunaan "lapisan retina" adalah langkah terakhir yang harus diambil sebagai bagian dari "kecocokan tipis" pembelajaran mesin untuk "fitur manusia". Selama generasi sampel, mereka didorong melalui sepuluh model yang berbeda, masing-masing yang seharusnya jelas memanggil, katakanlah, kucing, misalnya, seekor anjing. Jika hasilnya adalah "10 dari 10 salah", maka materi diajukan untuk pengujian pada manusia.
Apakah ini berhasil?
Tiga kelompok gambar terlibat dalam percobaan: "hewan peliharaan" (kucing dan anjing), "sayuran" (zucchini dan brokoli) dan "ancaman" (laba-laba dan ular, meskipun sebagai pemilik ular saya akan menyarankan istilah yang berbeda untuk evaluasi). Untuk setiap kelompok, kesuksesan dihitung jika orang yang diuji memilih hal yang salah - menyebut anjing kucing, dan sebaliknya. Peserta duduk di depan monitor yang menampilkan gambar sekitar 60 atau 70 milidetik, dan mereka harus menekan salah satu dari dua tombol untuk menunjukkan objek. Karena gambar diperlihatkan untuk waktu yang sangat singkat, ini menghaluskan perbedaan antara bagaimana orang dan jaringan saraf memandang dunia; ilustrasi dalam judul, dengan cara, mencolok dalam kegigihannya.
Apa yang ditunjukkan oleh subjek bisa berupa gambar yang tidak dimodifikasi (gambar), sebuah CarP (adv) "biasa", sebuah CarP "terbalik" (flip), di mana suara itu terbalik sebelum aplikasi, atau sebuah CarP "false", di mana lapisan dengan noise diterapkan pada gambar yang bukan milik salah satu tipe dalam grup (false). Dua opsi terakhir digunakan untuk mengontrol sifat gangguan (apakah struktur kebisingan akan memengaruhi terbalik, atau hanya "makan-tidak"?), Ditambah lagi, mereka memungkinkan untuk memahami apakah gangguan benar-benar menipu orang atau hanya sedikit mengurangi keakuratan.
Catatan dari karya itu sendiri:
Salah: suatu kondisi ditambahkan untuk memaksa subjek melakukan kesalahan. Kami menambahkannya, karena jika perubahan awal mengurangi akurasi pengamat, ini mungkin disebabkan oleh penurunan kualitas gambar langsung. Untuk menunjukkan bahwa CARP benar-benar berfungsi di setiap kelas, kami memperkenalkan opsi di mana tidak ada pilihan yang benar dan akurasinya adalah 0, dan kami menyaksikan dengan tepat apa jawaban "benar" dalam kasus itu. Kami mendemonstrasikan gambar sewenang-wenang dari ImageNet, yang dipengaruhi oleh satu atau beberapa kelas dalam grup, tetapi tidak cocok dengan mereka. Peserta percobaan harus menentukan apa yang ada di depannya. Misalnya, kami dapat menunjukkan gambar pesawat terbang yang terdistorsi dengan menerapkan suara "anjing", meskipun selama percobaan subjek seharusnya hanya mengenali kucing atau anjing.Berikut adalah contoh yang menunjukkan persentase jumlah orang yang dapat dengan jelas mengidentifikasi gambar sebagai anjing, tergantung pada bagaimana kebisingan digunakan. Biarkan saya mengingatkan Anda, hanya 60-70 milidetik untuk melihatnya dan mengambil keputusan.
 Sumber: Google Brain
Sumber: Google Brain
Gambar asli dengan seekor anjing; Ikan mas dengan anjing, diterima oleh manusia dan komputer sebagai kucing; kontrol gambar dengan lapisan noise terbalik.Dan inilah hasil akhirnya:
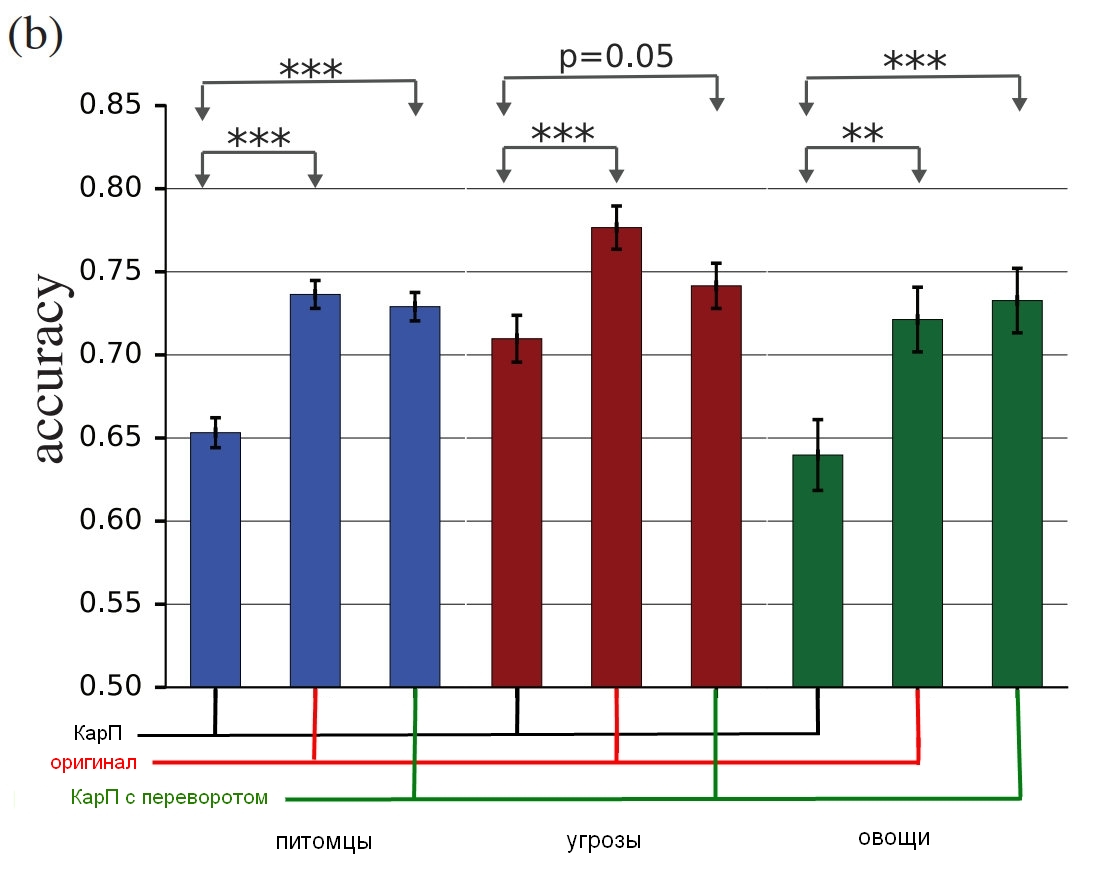 Sumber: Google Brain
Sumber: Google Brain
Hasil penelitian, bagaimana orang sejati mengidentifikasi gambar-gambar ini dibandingkan dengan yang terdistorsi.Grafik menunjukkan keakuratan pertandingan. Jika Anda memilih kucing dan itu benar-benar kucing, akurasinya meningkat. Jika Anda memilih kucing, tetapi sebenarnya itu anjing, diubah oleh suara menjadi sejenis kucing, akurasinya berkurang.
Seperti yang Anda lihat, orang jauh lebih tepat dalam memilih gambar yang tidak dikoreksi atau dengan lapisan noise terbalik daripada dalam pemilihan gambar yang "tidak konsisten". Ini membuktikan bahwa prinsip serangan terhadap persepsi dapat ditransfer dari komputer ke kita.
Tidak hanya dampaknya yang tak terbantahkan efektif, dampaknya juga lebih tipis dari yang diperkirakan - tidak ada kucing kotak atau pemanggang roti palsu, atau semacamnya. Karena kami melihat kedua layer dengan noise dan gambar sebelum dan sesudah pemrosesan, kami perlu mencari tahu apa yang sebenarnya membingungkan kami dalam hal ini. Meskipun para peneliti berhati-hati, dengan menyatakan bahwa "contoh-contoh kami dibuat khusus untuk mempermalukan kepala, jadi Anda harus berhati-hati menggunakan orang sebagai eksperimen untuk mempelajari efeknya."
Di masa depan, tim akan mencoba untuk mendapatkan beberapa aturan umum untuk kategori modifikasi tertentu, termasuk "
penghancuran tepi suatu objek , terutama oleh dampak moderat, tegak lurus terhadap garis tepi;
koreksi daerah berbatasan dengan meningkatkan kontras saat tekstur perbatasan;
mengubah tekstur ;
menggunakan bagian-bagian gelap "Gambar di mana tingkat dampak pada persepsi tinggi bahkan meskipun ada gangguan kecil." Berikut ini adalah contoh di mana area lingkaran merah di mana metode yang dijelaskan paling baik dilihat.
 Sumber: Google Brain
Sumber: Google Brain
Contoh gambar dengan prinsip distorsi yang berbedaApa hasilnya?
Intinya adalah bahwa ini lebih, lebih dari sekadar trik pintar. Orang-orang dari Google Brain mengonfirmasi bahwa mereka dapat membuat teknik penipuan yang efektif, tetapi mereka tidak sepenuhnya memahami mengapa itu bekerja, dengan mempertimbangkan tingkat abstraksi, dan mungkin saja ini secara harfiah adalah tingkat realitas dasar:
Proyek kami menimbulkan pertanyaan mendasar tentang bagaimana CARP bekerja, bagaimana jaringan saraf dan otak bekerja. Apakah Anda berhasil mentransfer serangan dari SNA ke otak karena representasi semantik dari informasi di dalamnya sama? Atau karena kedua representasi ini sesuai dengan model semantik umum tertentu, yang secara alami ada di dunia sekitarnya?
Kesimpulannya, jika Anda benar-benar ingin mendapatkan sedikit paranoid, maka para peneliti dengan senang hati membantu Anda, menunjukkan bahwa “pengenalan visual terhadap objek ... sulit untuk memberikan penilaian objektif. Apakah "Gambar. 1" benar secara objektif anjing, atau apakah itu kucing objektif yang dapat membuat orang berpikir bahwa itu adalah anjing? " Dengan kata lain, apakah gambar benar-benar berubah menjadi objek, atau hanya membuat Anda berpikir secara berbeda?
Sangat menyeramkan di sini (dan saya serius mengatakan "menyeramkan") bahwa pada akhirnya Anda bisa mendapatkan cara untuk mempengaruhi fakta apa pun, karena jarak antara memanipulasi SNA dan memanipulasi seseorang jelas tidak terlalu besar. Karenanya, teknologi pembelajaran mesin berpotensi digunakan untuk mendistorsi gambar atau video dengan cara yang benar, yang akan menggantikan persepsi kami (dan reaksi yang sesuai), dan kami bahkan tidak akan mengerti apa yang terjadi. Dari laporan:
Sebagai contoh, sekelompok model dengan pelatihan mendalam dapat dilatih tentang penilaian orang tentang tingkat kepercayaan pada tipe orang tertentu, fitur, ekspresi. Ini akan menjadi mungkin untuk menghasilkan kemarahan "bertentangan" yang akan menambah atau mengurangi perasaan "kredibilitas", dan materi "tweak" tersebut dapat digunakan dalam klip berita atau iklan politik.
Di masa depan, risiko teoritis termasuk kemungkinan menciptakan stimulasi sensorik yang masuk ke otak dalam berbagai cara dan dengan efisiensi yang sangat tinggi. Seperti yang Anda ketahui, banyak hewan dipandang rentan terhadap rangsangan berlebihan. Katakanlah kukuk secara bersamaan dapat berpura-pura menjadi tidak berdaya dan membuat panggilan sedih, yang dalam kombinasi menyebabkan burung-burung dari keturunan lain memberi makan anak-anak ayam kukuk sebelum keturunan mereka sendiri. Sampel-sampel "yang bertentangan" dapat dianggap sebagai suatu bentuk khusus stimulasi super kuat untuk jaringan saraf. Dan fakta bahwa rangsangan yang berlebihan, yang secara teori jauh lebih mungkin mempengaruhi seseorang daripada hanya membuat mereka menggantungkan tag "kucing" pada gambar anjing, menyebabkan kekhawatiran besar, dapat dibuat menggunakan mesin dan kemudian dipindahkan ke orang-orang.
Tentu saja, metode tersebut dapat digunakan "untuk kebaikan," dan sejumlah opsi telah diusulkan, seperti "mempertajam fitur karakteristik gambar untuk meningkatkan tingkat konsentrasi, misalnya, ketika mengontrol situasi udara atau menganalisis gambar sinar-X, karena pekerjaan ini monoton, dan konsekuensinya kecerobohan bisa jadi mengerikan. " Juga, "perancang antarmuka pengguna dapat menggunakan gangguan untuk mengembangkan antarmuka yang lebih intuitif." Hmmm Ini memang luar biasa, tetapi saya entah bagaimana lebih peduli dengan peretasan otak saya dan menetapkan tingkat kepercayaan pada orang, Anda tahu?
Beberapa pertanyaan yang diajukan akan menjadi subjek penelitian di masa depan - mungkin akan ditemukan apa yang membuat gambar tertentu lebih cocok untuk menyampaikan kesalahan kepada seseorang, dan ini dapat memberikan petunjuk baru untuk memahami prinsip-prinsip otak. Dan ini, pada gilirannya, akan membantu menciptakan jaringan saraf yang lebih maju yang akan belajar lebih cepat dan lebih baik. Tetapi kita harus berhati-hati dan ingat bahwa, seperti komputer, terkadang tidak begitu sulit untuk menipu kita.
Proyek
" Contoh Adversarial yang Menipu Visi Manusia dan Komputer , oleh Gamaleldin F. Elsayed, Shreya Shankar, Brian Cheung, Nicolas Papernot, Alex Kurakin, Ian Goodfellow, dan Jascha Sohl-Dickstein, dari Google Brain" , dapat diunduh dari
arXiv . Dan jika Anda membutuhkan gambar yang lebih kontroversial yang bekerja pada orang, maka materi pendukungnya ada di
sini .