Halo, Habr! Akhirnya, kami menunggu bagian lain dari rangkaian materi dari lulusan program
Big Data Specialist dan
Deep Learning kami , Cyril Danilyuk, tentang penggunaan Mask R-CNN, jaringan saraf yang saat ini populer, sebagai bagian dari sistem untuk mengklasifikasikan gambar, yaitu menilai kualitas hidangan yang disiapkan menggunakan dataset dari sensor.
Setelah memeriksa dataset mainan yang terdiri dari gambar rambu-rambu jalan di
artikel sebelumnya , kita sekarang dapat melanjutkan untuk menyelesaikan masalah yang saya hadapi dalam kehidupan nyata:
"Apakah mungkin untuk mengimplementasikan algoritma Deep Learning, yang dapat membedakan hidangan berkualitas tinggi dari hidangan buruk satu per satu foto? " . Singkatnya, bisnis menginginkan ini:
Apa yang diwakili bisnis saat memikirkan pembelajaran mesin:Ini adalah contoh dari masalah yang diajukan secara tidak benar: dalam hal ini tidak mungkin untuk menentukan apakah suatu solusi ada, apakah itu unik dan stabil. Apalagi pernyataan masalah itu sendiri sangat kabur, belum lagi implementasi solusinya. Tentu saja, artikel ini tidak ditujukan untuk efektivitas komunikasi atau manajemen proyek, tetapi penting untuk dicatat:
jangan pernah mengambil proyek di mana hasil akhirnya tidak didefinisikan dan dicatat dalam pernyataan kerja. Salah satu cara yang paling dapat diandalkan untuk mengatasi ketidakpastian tersebut adalah dengan terlebih dahulu membangun prototipe, dan kemudian, dengan menggunakan pengetahuan baru, strukturkan sisa tugas. Itu yang kami lakukan.
Pernyataan masalah
Dalam prototipe saya, saya fokus pada satu antena piringan dari menu - telur dadar - dan membangun pipa yang skalabel, yang menentukan "kualitas" telur dadar pada output. Ini dapat dijelaskan secara lebih rinci sebagai berikut:
- Jenis masalah: klasifikasi multikelas dengan 6 kelas kualitas diskrit: baik (baik), broken_yolk (dengan kuning telur), overroasted (matang), two_eggs (dua telur), four_eggs (empat telur), misplaced_pieces (dengan potongan tersebar di atas piring) .
- Dataset: 351 foto yang dikumpulkan secara manual dari berbagai omelet. Pelatihan / validasi / contoh uji: 139/32/180 foto campuran.
- Label kelas: setiap foto sesuai dengan label kelas yang sesuai dengan penilaian subyektif kualitas telur dadar.
- Metrik: lintas-entropi kategoris.
- Pengetahuan domain minimum: telur dadar "berkualitas" akan terlihat seperti ini: terdiri dari tiga telur, sejumlah kecil daging asap, daun peterseli di bagian tengah, tidak memiliki kuning telur dan potongan matang yang terlalu matang. Juga, komposisi keseluruhan harus "terlihat bagus," yaitu, potongan tidak boleh tersebar di seluruh piring.
- Kriteria penyelesaian: nilai terbaik dari cross-entropy dalam sampel uji di antara semua yang mungkin setelah dua minggu pengembangan prototipe.
- Metode visualisasi akhir: t-SNE pada ruang data dimensi yang lebih kecil.
 Masukkan gambar
Masukkan gambarTujuan utama dari pipa adalah untuk belajar menggabungkan beberapa jenis sinyal (misalnya, gambar dari sudut yang berbeda, peta panas, dll), setelah menerima representasi pra-kompresi masing-masing dari mereka dan melewati fitur-fitur ini melalui pengklasifikasi jaringan saraf untuk prediksi akhir. Jadi, kita dapat mewujudkan prototipe kita dan membuatnya praktis dapat diterapkan dalam pekerjaan lebih lanjut. Berikut adalah beberapa sinyal yang digunakan dalam prototipe:
- Topeng dari bahan utama (Topeng R-CNN): Sinyal No. 1 .
- Jumlah bahan utama pada bingkai., Nomor sinyal 2 .
- RGB memotong piring dengan telur dadar tanpa latar belakang. Untuk kesederhanaan, saya memutuskan untuk tidak menambahkannya ke model, meskipun mereka adalah sinyal yang paling jelas: di masa depan, Anda dapat melatih jaringan saraf convolutional untuk klasifikasi menggunakan beberapa fungsi kehilangan triplet yang memadai, menghitung embeddings gambar dan memotong jarak L2 dari saat ini Gambar menjadi sempurna. Sayangnya, saya tidak memiliki kesempatan untuk menguji hipotesis ini, karena sampel uji hanya terdiri dari 139 objek.
Pandangan umum dari pipa
Saya perhatikan bahwa saya harus melewati beberapa langkah penting, seperti analisis data eksplorasi, membangun klasifikasi dasar dan pelabelan aktif (istilah yang saya usulkan, yang berarti penjelasan objek semi-otomatis, terinspirasi oleh
video demo Polygon-RNN ) untuk saluran pipa Masker R-CNN (lebih lanjut tentang ini di posting berikutnya).
Lihatlah keseluruhan pipa secara umum:
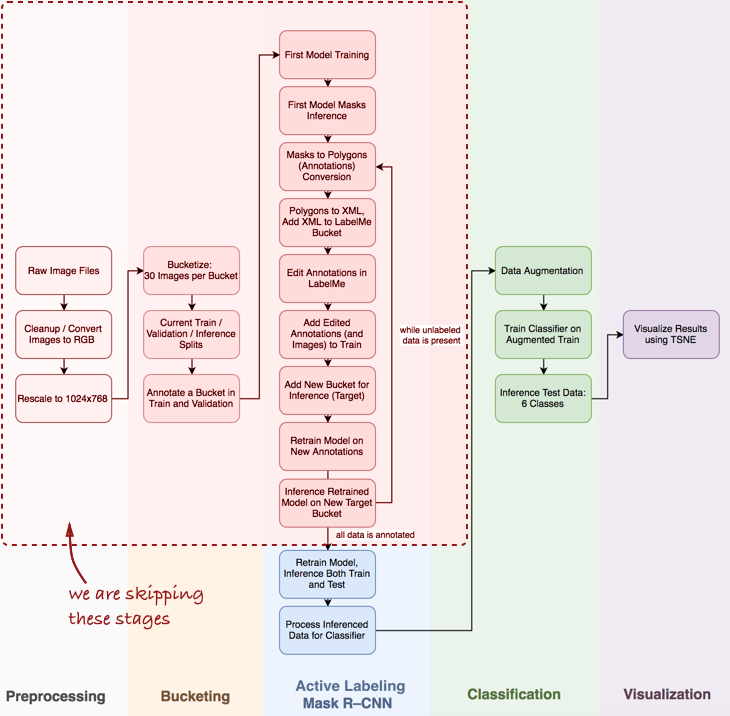 Pada artikel ini, kami tertarik pada tahapan Mask R-CNN dan klasifikasi dalam pipa.
Pada artikel ini, kami tertarik pada tahapan Mask R-CNN dan klasifikasi dalam pipa.Berikutnya, kami akan mempertimbangkan tiga tahap: 1) menggunakan Masker R-CNN untuk membuat masker dari bahan dadar; 2) Klasifikasi ConvNet berdasarkan Keras; 3) visualisasi hasil menggunakan t-SNE.
Tahap 1: Topeng R-CNN dan masker bangunan
Topeng R-CNN (MRCNN) baru-baru ini berada di puncak popularitas. Dimulai dari
artikel Facebook asli dan berakhir dengan
Data Science Bowl 2018 di Kaggle, Mask R-CNN telah memantapkan dirinya sebagai arsitektur yang kuat untuk segmentasi contoh (mis., Tidak hanya segmentasi gambar pixel-demi-pixel, tetapi juga pemisahan beberapa objek milik kelas yang sama) ) Selain itu, senang bekerja dengan
implementasi MRCNN dari Matterport di Keras. Kode tersebut terstruktur dengan baik, memiliki dokumentasi yang baik, dan berfungsi dengan baik, meskipun lebih lambat dari yang diharapkan.
Dalam praktiknya, terutama ketika mengembangkan prototipe, sangat penting untuk memiliki jaringan saraf convolutional pra-terlatih. Dalam kebanyakan kasus, dataset tag data ilmuwan sangat terbatas atau tidak sama sekali, sementara ConvNet membutuhkan banyak data yang ditandai untuk mencapai konvergensi (misalnya, dataset ImageNet berisi 1,2 juta gambar yang ditandai). Di sini
pembelajaran transfer datang untuk menyelamatkan: kita dapat memperbaiki bobot lapisan konvolusional dan hanya melatih penggolongnya saja. Memperbaiki lapisan konvolusional penting untuk dataset kecil, karena teknik ini mencegah pelatihan ulang.
Inilah yang saya dapatkan setelah era pertama pelatihan ulang:
 Hasil segmentasi objek: semua bahan utama dikenali
Hasil segmentasi objek: semua bahan utama dikenaliPada tahap berikutnya dari pipeline (
Process Inferenced Data for Classifier ), Anda perlu memotong bagian gambar yang berisi pelat dan mengekstrak topeng biner dua dimensi untuk setiap bahan pada pelat ini:
 Gambar yang dipangkas dengan bahan-bahan utama dalam bentuk topeng biner.
Gambar yang dipangkas dengan bahan-bahan utama dalam bentuk topeng biner.Topeng biner ini kemudian digabungkan menjadi gambar 8-saluran (karena saya mendefinisikan 8 kelas mask untuk MRCNN), dan kami mendapatkan
Sinyal No. 1 :
 Sinyal No. 1 : gambar 8-saluran yang terdiri dari topeng biner. Berwarna untuk visualisasi yang lebih baik.
Sinyal No. 1 : gambar 8-saluran yang terdiri dari topeng biner. Berwarna untuk visualisasi yang lebih baik.Untuk mendapatkan
Sinyal No. 2 , saya menghitung berapa kali masing-masing bahan ditemukan pada tanaman piring dan mendapat satu set vektor fitur, yang masing-masing sesuai dengan tanamannya.
Tahap 2: ConvNet Classifier di Keras
Klasifikasi CNN diimplementasikan dari awal menggunakan Keras. Saya ingin menggabungkan beberapa sinyal (
Sinyal No. 1 dan
Sinyal No. 2 , serta kemungkinan penambahan data di masa depan) dan membiarkan jaringan saraf menggunakannya untuk membuat perkiraan mengenai kualitas hidangan. Arsitektur yang disajikan di bawah ini adalah uji coba dan jauh dari ideal:

Beberapa kata tentang arsitektur classifier:
- Modul konvolusional multiskala : Saya awalnya memilih filter 5x5 untuk lapisan konvolusional, tetapi ini hanya menghasilkan hasil yang memuaskan. Perbaikan dicapai dengan menerapkan AveragePooling2D ke beberapa lapisan dengan filter berbeda: 3x3, 5x5, 7x7, 11x11. Lapisan konvolusional 1x1 tambahan ditambahkan di depan setiap lapisan untuk mengurangi dimensi. Komponen ini agak mirip modul Inception , meskipun saya tidak berencana untuk membangun jaringan terlalu dalam.
- Filter yang lebih besar : Saya menggunakan filter yang lebih besar, karena mereka membantu untuk dengan mudah mengekstraksi tanda-tanda yang lebih besar dari gambar input (yang pada dasarnya merupakan lapisan aktivasi dengan 8 filter - penutup setiap bahan dapat dianggap sebagai filter terpisah).
- Menggabungkan sinyal : dalam implementasi saya yang naif, hanya satu lapisan yang digunakan yang menghubungkan dua set atribut: topeng biner yang diproses ( Sinyal No. 1 ) dan bahan yang dihitung ( Sinyal No. 2 ). Namun, meskipun sederhana, penambahan Signal No. 2 memungkinkan untuk mengurangi metrik lintas-entropi dari 0,8 menjadi [0,7, 0,72] .
- Logit : dalam hal TensorFlow, logit adalah layer di mana tf.nn.softmax_cross_entropy_with_logits diterapkan untuk menghitung kehilangan batch .
Tahap 3: visualisasi hasil menggunakan t-SNE
Untuk memvisualisasikan hasil pengklasifikasi pada data uji, saya menggunakan t-SNE - sebuah algoritma yang memungkinkan Anda untuk mentransfer data sumber ke ruang dimensi yang lebih rendah (untuk memahami prinsip algoritma, saya sarankan membaca
artikel asli , itu sangat informatif dan ditulis dengan baik).
Sebelum visualisasi, saya mengambil gambar uji, mengekstraksi lapisan logite dari classifier dan menerapkan algoritma t-SNE pada dataset ini. Meskipun saya belum mencoba nilai yang berbeda dari parameter kebingungan, hasilnya masih terlihat cukup bagus:
 Hasil t-SNE pada data uji dengan prediksi classifier
Hasil t-SNE pada data uji dengan prediksi classifierTentu saja, pendekatan ini tidak sempurna, tetapi berhasil. Mungkin ada beberapa kemungkinan perbaikan:
- Lebih banyak data. Jaringan konvolusi membutuhkan banyak data, dan saya hanya memiliki 139 gambar untuk pelatihan. Teknik seperti augmentasi data berfungsi dengan baik (saya menggunakan D4 atau augmentasi dihedral simetris , menghasilkan lebih dari 2 ribu gambar), tetapi memiliki lebih banyak data nyata masih sangat penting.
- Fungsi kerugian lebih cocok. Untuk kesederhanaan, saya menggunakan lintas-entropi kategoris, yang bagus karena berfungsi langsung di luar kotak. Pilihan terbaik adalah menggunakan fungsi kerugian, yang memperhitungkan variasi akun di dalam kelas, misalnya, fungsi triplet loss (lihat artikel FaceNet ).
- Memperbaiki arsitektur classifier. Penggolong saat ini pada dasarnya adalah prototipe, satu-satunya tujuan adalah untuk membangun topeng biner dan menggabungkan beberapa set fitur untuk membentuk pipa tunggal.
- Tata letak gambar ditingkatkan. Saya sangat ceroboh ketika menandai gambar secara manual: pengklasifikasi melakukan pekerjaan ini lebih baik daripada saya pada selusin gambar uji.
Kesimpulan Akhirnya harus diakui bahwa bisnis tidak memiliki data, atau penjelasan, atau bahkan tugas yang lebih jelas yang perlu diselesaikan. Dan ini bagus (jika tidak, mengapa mereka membutuhkan Anda?), Karena pekerjaan Anda adalah menggunakan berbagai alat, prosesor multi-inti, model pra-terlatih dan campuran keahlian teknis dan bisnis untuk menciptakan nilai tambah di perusahaan.
Mulai dari yang kecil: prototipe yang berfungsi dapat dibuat dari beberapa blok kode mainan, dan itu akan secara signifikan meningkatkan produktivitas percakapan lebih lanjut dengan manajemen perusahaan. Ini adalah pekerjaan seorang ilmuwan data - untuk menawarkan bisnis pendekatan dan ide baru.
Pada 20 September 2018,
"Big Data Specialist 9.0" dimulai, di mana, di antara hal-hal lain, Anda akan belajar bagaimana memvisualisasikan data dan memahami logika bisnis di balik tugas ini atau itu, yang akan membantu untuk secara lebih efektif menyajikan hasil pekerjaan Anda kepada kolega dan manajemen.