
Apa perbedaan antara Pembelajaran Mesin dan analisis data, yang duduk di Odnoklassniki dan bagaimana memulai perjalanan Anda dalam pembelajaran mesin - kami membicarakan hal ini dalam edisi kedua dari talkshow untuk para programmer.
Video di saluran TechnostreamTuan rumah dari program ini adalah Pavel Shcherbinin, direktur teknis proyek media, dan bintang tamu adalah Dmitry Bugaychenko, seorang analis di Odnoklassniki.
00:56 Dmitry Bugaychenko: dari outsourcing ke aktivitas OK dan ilmiah
02:42 Mengapa menggabungkan pekerjaan di universitas dan di perusahaan besar
02:57 Di mana pembelajaran mesin diterapkan dalam OK
03:49 Pembelajaran mesin dan analisis data - apa bedanya?
05:08 Screencast “Kami menganalisis audiens dengan bantuan analisis data”
22:34 Apakah teman sekelas adalah layanan kencan?
24:07 Di mana untuk mulai belajar Machine Learning?
25:33 Haruskah saya berpartisipasi dalam kejuaraan pembelajaran mesin?
26:53 Cara berlatih di OK
28:18 Buku Pegangan Belajar Mesin
30:28 Acara Pembelajaran Mesin
32:48 Bagaimana saluran pipa data diatur dalam OK (tunjukkan di papan tulis)
43:42 Jajak pendapat Blitz
Ceritakan sedikit tentang diri Anda.Kita dapat mengasumsikan bahwa jalur karier saya dimulai pada tahun 1999, ketika saya memasuki matematika. Selama lima tahun, ia aktif belajar matematika, pemrograman, dan berbagai disiplin ilmu terkait. Kemudian dia bekerja agak lama di sebuah perusahaan outsourcing. Alih daya adalah pengalaman yang sangat menarik. Saya berhasil bekerja di berbagai proyek, mulai dari menulis driver untuk kulkas hingga membuat sistem perusahaan terdistribusi.
Selama ini, selain pekerjaan utama, saya mengajar di universitas untuk menjaga hubungan dengan komunitas akademik, yang cukup sulit. Ketika pada tahun 2011 saya diundang ke Odnoklassniki untuk terlibat dalam sistem rekomendasi, itu adalah kesempatan yang sangat bagus, yang saya manfaatkan. Di sini, dimungkinkan untuk menggabungkan persiapan matematika universitas dan pengalaman praktis pemrograman. Namun, saya terus mengajar di universitas.
Apakah mengajar membutuhkan banyak waktu?1,5 hari seminggu pergi ke universitas, tetapi itu sepadan, karena kami sudah memiliki tiga mantan siswa saya sebagai staf. Artinya, universitas juga bekerja sebagai bentukan personel.
Di tempat kerja, hubungkan dengan tenang fakta bahwa Anda pergi selama 1,5 hari?Mengundurkan diri. Semua orang mengerti apa untungnya dari ini, jadi saya tidak menemui oposisi apa pun.
Katakan di mana pembelajaran mesin digunakan di Odnoklassniki.Kami memiliki banyak aplikasi. Secara historis, sistem pembelajaran mesin pertama adalah rekomendasi musik. Semuanya dimulai pada tahun 2011. Lalu ada pertumbuhan yang sangat eksplosif: rekomendasi dari komunitas, rekomendasi dari teman-teman, "mungkin Anda saling kenal," berupaya untuk memberi peringkat konten dalam umpan orang tersebut. Sekarang banyak proyek sedang berkembang. Tidak peduli bagian mana dari Odnoklassniki yang Anda colek, ada komponen yang terkait dengan pembelajaran mesin atau analisis data.
Bantu pembaca kami memisahkan dua konsep ini: pembelajaran mesin dan analisis data.Data dianalisis oleh seseorang untuk menemukan beberapa pola, koneksi, menguji beberapa hipotesis. Untuk ini, berbagai cara statistik matematika digunakan. Pembelajaran mesin adalah metode yang lebih maju dalam mencari pola, menggunakan teknik yang biasanya didasarkan pada semacam model besar dan kompleks dengan sejumlah besar parameter.
Kami mencoba memilih parameter dari model ini sehingga dapat menggambarkan dengan baik fenomena yang kami butuhkan. Ada banyak algoritma yang berbeda, metode penghitungan parameter, tetapi semua ini dilakukan untuk menemukan keteraturan. Misalnya, menurut data pada sebuah pos di jejaring sosial, nilai kemungkinan seseorang akan menempatkan "kelas" pada posting ini. Artinya, pembelajaran mesin adalah alat untuk analisis data.
Bisakah Anda dan saya menyanggah salah satu mitos tentang Odnoklassniki, yang menurutnya audiens ini memiliki audiens yang sangat tua?Tidak masalah Ini adalah peta yang secara real time mencerminkan login setiap pengguna tertentu. Artinya, setiap titik adalah orang yang masuk dan melakukan sesuatu dalam Odnoklassniki.
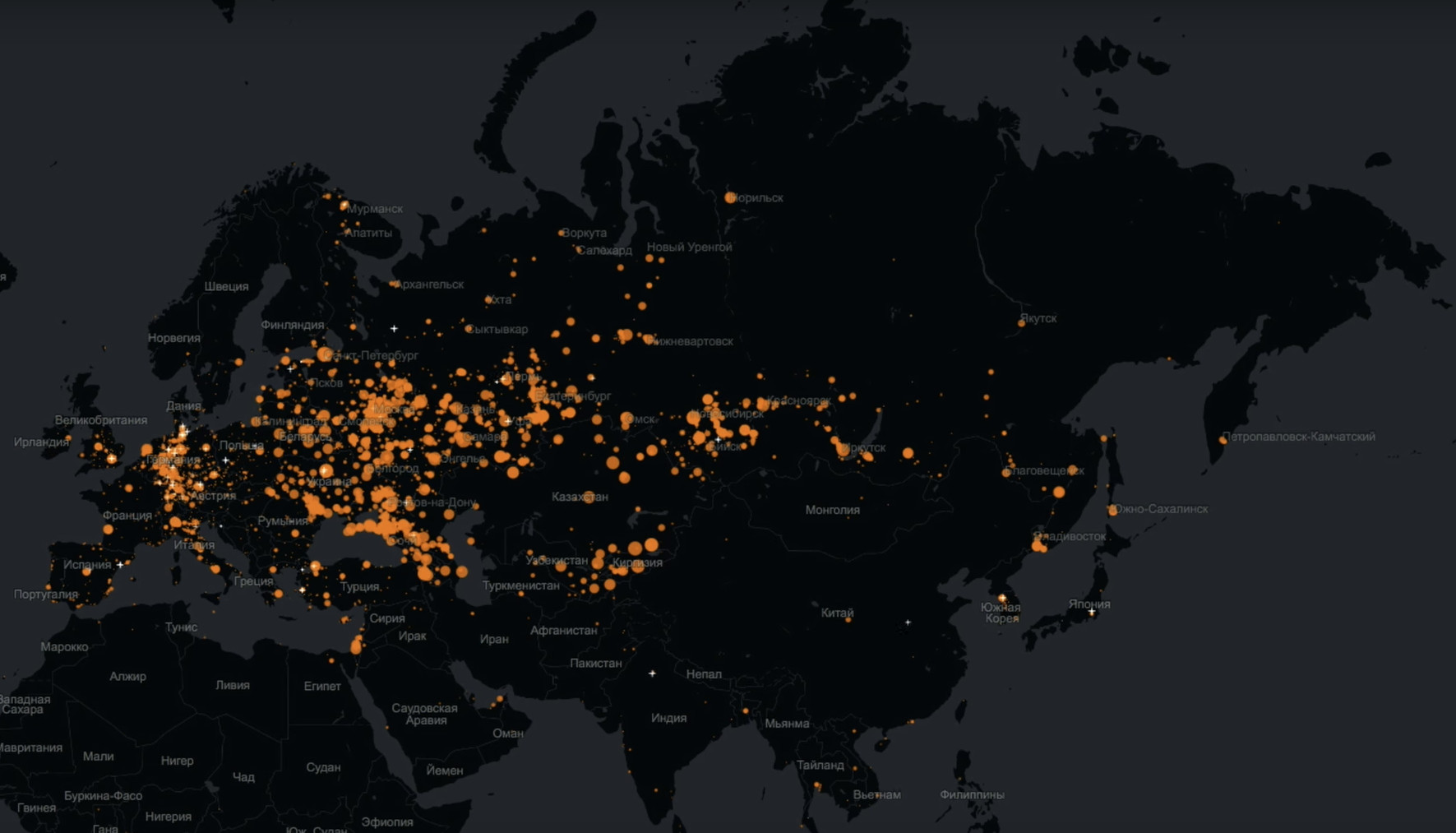
Lingkaran merah besar adalah kota tempat banyak pengguna mendatangi kami. Sangat jelas terlihat di sini bahwa Odnoklassniki tidak hanya hidup, mereka mencakup hampir seluruh Eurasia.
Mari kita hitung berapa banyak pengguna yang menaruh "kelas" di Odnoklassniki kemarin, dan lihat distribusi umur.
Di mana pengkodean dimulai? Tentu saja, dari mengimpor berbagai data yang berguna untuk perhitungan agregat masa depan. Alat utama kami adalah
Spark , untuk akses yang kami gunakan di depan web
Zeppelin . Pada dasarnya, data datang melalui
Apache Kafka , dikemas dan dipecah menjadi beberapa blok. Dalam hal ini, kami tertarik pada blok yang menggambarkan aktivitas pengguna kemarin, khususnya kelas. Ada bidang di mana demografi pengguna disimpan, termasuk hari ulang tahun.

Keluarannya adalah tahun kelahiran sepuluh catatan pertama. Sekarang mari kita coba membangun beberapa agregat dari ini. Kami ingin menghitung jumlah pengguna unik. Kami membutuhkan nomor dan tahun kelahiran, kelompok demi tahun, dan menghitung jumlah pengguna unik. Dan mari kita mainkan sedikit: pasti akan ada orang-orang yang tahun kelahirannya tidak ditunjukkan, jadi kami akan menyaring mereka sehingga mereka tidak membuat suara pada grafik.
Untuk melakukan perhitungan, sistem perlu menyekop sekitar 1 TB data. Kami mendapatkan hasilnya dan menyajikannya secara grafis:

Puncak usia jatuh pada 1983 - 35 tahun. Itu pengguna yang cukup tua untuk diri mereka sendiri.
Untuk lebih mewakili situasi, tidak ada informasi yang cukup dari satu sumber. Jika kita berbicara tentang demografi pengguna, maka sumber paling menarik untuk perbandingan adalah statistik pada populasi Rusia. Dari situs web
Rosstat, saya mengunduh data tentang tahun-tahun kelahiran Rusia, yang dikumpulkan pada tahun 2016.
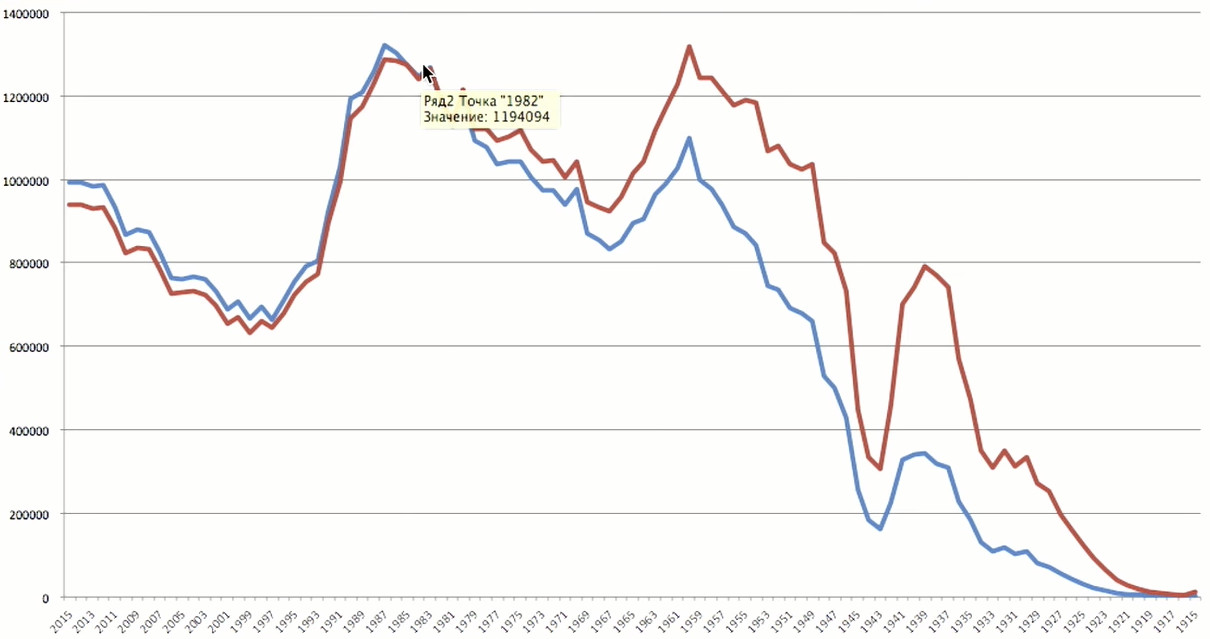
Puncak dalam statistik sangat dekat dengan puncak menurut Odnoklassniki - kami memiliki pengguna yang lahir pada tahun 1983, dan Rosstat - 1987. Yang mengejutkan saya adalah dua kegagalan besar. Lubang awal 1940-an adalah Perang Patriotik Hebat. Perang itu menelan korban tidak hanya lebih dari 20 juta, tetapi juga jutaan orang yang belum lahir. Ini adalah lubang demografis yang masih dirasakan. Lubang kedua - 1990-an. Dan kita belum sepenuhnya pulih dari krisis ini. Kita melihat gambaran yang sama dalam data Odnoklassniki: setelah 1990, ada penurunan kuat. Kami masih belum dapat memiliki orang yang lahir pada tahun 2015, karena usia minimum untuk pendaftaran adalah 5 tahun.
Tambahkan atribut gender ke sampel dan grup kami tidak hanya berdasarkan tahun, tetapi juga berdasarkan gender.
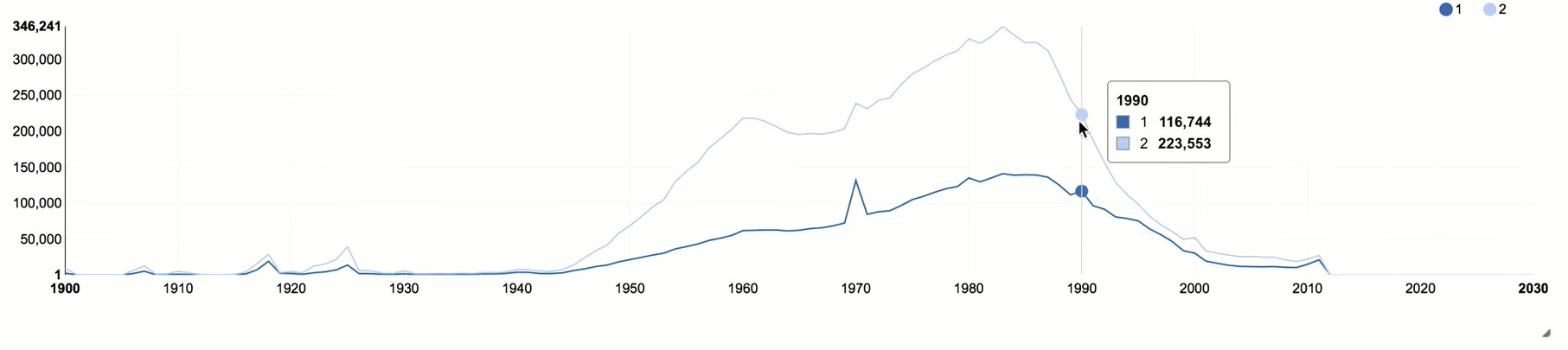
Setelah 1990, ada penurunan tajam, yang berkorelasi dengan situasi usia umum di Rusia. Wanita menempatkan "kelas" jauh lebih aktif, hampir dua kali lipat pria. Ini adalah gambaran yang cukup khas untuk jejaring sosial, karena wanita lebih aktif secara sosial daripada pria.
Anda juga dapat memperhatikan beberapa puncak yang berkorelasi dengan tahun "putaran". Berdasarkan puncak-puncak ini, seseorang dapat menilai pengaruh bot atau orang-orang yang dengan sengaja mendistorsi usia mereka, karena dalam kasus seperti itu mereka biasanya menunjukkan semacam tanggal bulat.
Kami juga tertarik dengan distribusi geografis pengguna kami. Kami memerlukan ID pengguna untuk menghitung pengunjung unik, dan alamat tempat tinggal yang ditunjukkan dalam profil. Kelompokkan menurut kota dan hitung unitnya. Urutkan berdasarkan jumlah pengguna dalam urutan menurun dan hanya menyisakan 200 kota pertama. Jalankan agregasi:

Ini adalah kota teratas dalam hal jumlah teman sekelas yang telah mengatur teman sekelasnya. Secara alami, Moskow memimpin. Bagian selatan Rusia direpresentasikan jauh lebih baik daripada Northwest. Kami memiliki pengguna di AS, Kanada, banyak di Jerman, banyak di Israel. Fakta menarik: 36 ribu orang dari Yuzhno-Sakhalinsk menyukai setiap hari. Dan secara total, menurut Wikipedia, 180 ribu orang tinggal di kota. 20% dari populasi Yuzhno-Sakhalinsk pergi ke Odnoklassniki dan menempatkan "kelas".

Perbesar dan lihat apa yang terjadi di Moskow dan wilayah Moskow.

Republik Asia Tengah, Moldova, Ukraina terwakili dengan sangat baik di Odnoklassniki.

Anda dapat segera melihat di mana mereka mencoba memblokir akses ke jejaring sosial kami, dan di mana tidak.
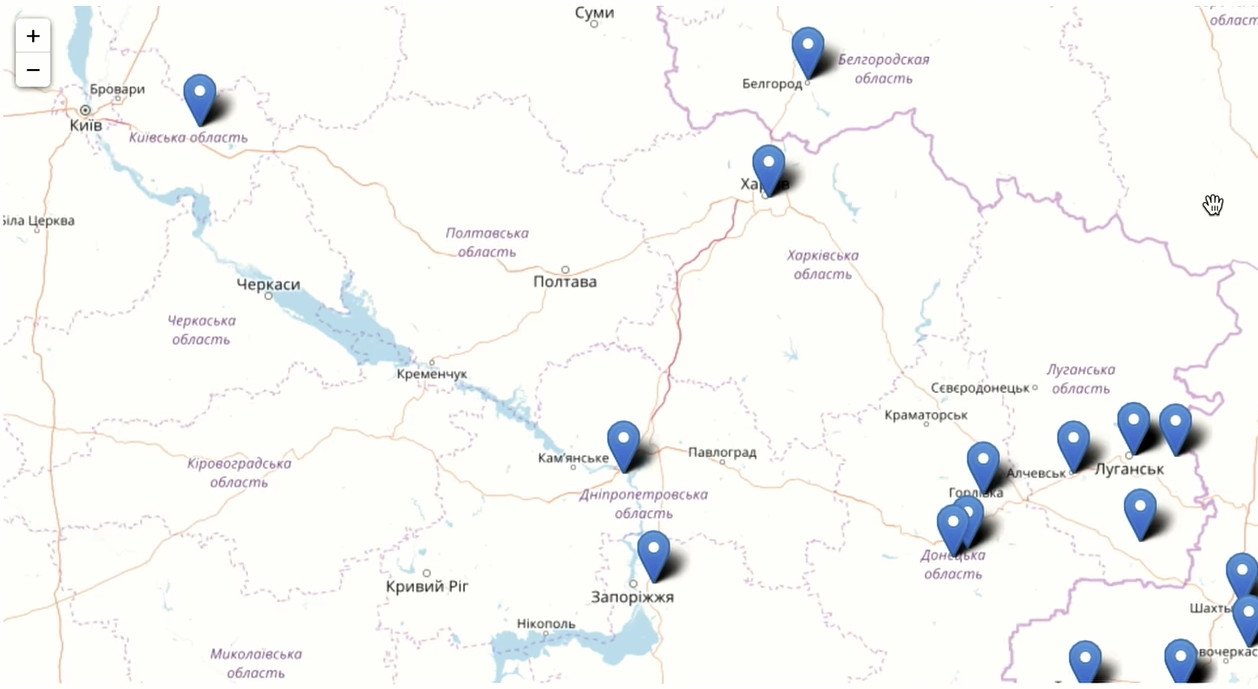
Seperti yang Anda lihat, Odnoklassniki adalah produk dinamis dan dinamis yang digunakan oleh orang muda dan orang tua di seluruh dunia, kadang-kadang bahkan di tempat yang tidak Anda harapkan. Di antara semua kategori umur, kami memiliki yang paling berusia 30 tahun.
Jejaring sosial dibangun di sekitar komunitas. Sering terjadi bahwa jika suatu komunitas telah memasuki jaringan sosial tertentu, ia tahu sedikit tentang jaringan sosial lainnya. Karena itu, misalnya, komunitas profesional jurnalis mungkin memiliki ilusi bahwa Odnoklassniki terutama adalah audiens yang berusia lanjut. Bahkan, ini adalah pendapat subjektif dari beberapa komunitas. Kami memiliki pengguna berusia 50-60 tahun ke atas, ada anak sekolah, ada remaja berusia 20 tahun, ada orang dewasa, orang dewasa berusia 30-35 tahun.
Cakupan Odnoklassniki adalah semua wilayah Rusia, negara-negara tetangga, Ukraina, Belarus, Asia Tengah. Kami telah dengan baik mewakili diaspora, misalnya, diaspora Jerman dari emigran Rusia, diaspora Amerika, dan Israel. Mereka berkomunikasi cukup aktif dengan kerabat mereka yang tetap tinggal di Rusia dan bekas republik Soviet. Dari sudut pandang ini, Odnoklassniki berkontribusi dengan sangat baik untuk pelaksanaan fungsi dasar jaringan sosial - untuk menjaga kontak antara orang-orang yang tinggal jauh dari satu sama lain.
Ada pendapat bahwa Odnoklassniki sangat menarik bagi banyak orang karena itu cara mudah untuk bertemu teman dan kenalan teman dan kerabat Anda. Artinya, Odnoklassniki disajikan sebagai layanan kencan. Seberapa jauh cara berkencan ini populer dan menjadi bagian dari ideologi Odnoklassniki?Kebutuhan untuk bertemu orang lain, termasuk lawan jenis, adalah kebutuhan dasar manusia. Secara alami, ini diekspresikan dalam jejaring sosial apa pun. Tetapi dalam Odnoklassniki itu diungkapkan tidak lebih dan tidak kurang dari pada jejaring sosial lainnya. Kami tidak memiliki penekanan pada layanan kencan. Ideologi pengembangan jejaring sosial kita didasarkan pada nilai bersama seperti komunikasi antar manusia. Tidak begitu penting bagi kami apakah teman sekelas yang telah menyebar ke kota-kota yang berbeda, atau orang-orang yang mencari jodoh. Kedua opsi sangat cocok untuk kita. Kami senang bahwa orang menemukan satu sama lain dan berkomunikasi. Tapi tidak lebih
Anda melakukan banyak pembelajaran mesin. Topik ini sekarang menggairahkan banyak orang. Di mana untuk memulai, bagaimana masuk ke profesi ini?Pertama, Anda perlu mendapatkan pengetahuan. Tidak ada masalah dengan ini, ada kursus luar biasa di
Coursera , di
Stepik dan di beberapa program universitas yang memberikan pengetahuan dasar yang sangat baik tentang pembelajaran mesin. Untuk benar-benar bergabung dengan bidang ini, Anda memerlukan tujuan dan pemahaman di mana Anda dapat menerapkannya. Karena hanya mendengarkan kursus abstrak jauh dari efektif seolah-olah Anda benar-benar akan memecahkan masalah atau masalah.
Dalam kasus siswa, pilihan ideal adalah makalah, disertasi. Dan bahkan dalam kasus ini, saya mencoba untuk tidak membiarkan tugas turun dari atas, tetapi untuk membantu ide-ide datang dari para siswa, maka mereka akan memiliki motivasi yang lebih besar.
Yaitu, setelah menetapkan tujuan, mendengarkan kursus online, dan kemudian mencoba menerapkan pengetahuan. Dan semuanya akan berubah.
Menurut saya ada cukup banyak tugas hari ini. Sejumlah besar kompetisi dari Sberbank, Tinkoff dan banyak perusahaan lain berlangsung di skittle.Tentu saja Tetapi mereka fokus, pertama-tama, pada mereka yang sudah terlibat erat dalam pembelajaran mesin. Selain itu, sangat sering di kompetisi seperti itu orang bisa mengamati bukan pembelajaran mesin, tetapi cap-kebencian. Model-model yang dilatih pada skittle tidak akan membantu dalam memecahkan masalah praktis, karena mereka mendorong terlalu banyak parameter. Sebagai hasilnya, model mengkhususkan diri khusus untuk kompetisi tertentu pada skittle, dan hanya di dalamnya setiap hasil diperoleh. Dan jika Anda mentransfer model-model ini ke dunia nyata, mereka tidak akan berfungsi.
Praktik terbaik adalah latihan. Bagaimana cara berlatih dengan tim Anda?Ada banyak cara. Jika kita berbicara tentang tim peneliti, maka kita memiliki proyek bernama OK Data Science Lab, di mana kita menyediakan sumber daya komputasi, data, pengetahuan dan pengalaman kita kepada orang-orang yang ingin mengembangkan ide-ide mereka yang terkait dengan pembelajaran mesin dan analisis data. Dan belum tentu untuk jejaring sosial. Sebagai contoh, kami memiliki penelitian di mana penulis mencoba memahami apa yang paling menarik bagi anak sekolah modern.
Jika Anda seorang spesialis dan sedang mencari pekerjaan, kami selalu memiliki banyak lowongan terbuka terkait pembelajaran mesin. Kunjungi kami untuk wawancara.
Apakah ada buku, pembaca pembelajaran mesin?Ini adalah bidang yang berubah dengan cepat sehingga menulis buku atau pembaca pembelajaran mesin terlalu ambisius. Saya dapat merekomendasikan karya klasik "
Elemen pembelajaran statistik ". Ini adalah tentang metode paling dasar pembelajaran mesin, yang berasal dari statistik.
Sergey Nikolenko menerbitkan sebuah buku tentang pembelajaran mesin dalam.Menurut pendapat saya, pembelajaran mendalam bukanlah tempat untuk memulai. Jika Anda sudah memiliki pembelajaran mesin klasik, maka ini adalah pilihan yang baik. Tetapi jika Anda belum mengetahui teknik-teknik klasik, adalah salah untuk segera memulai dengan pembelajaran yang mendalam, karena seringkali mendorong peneliti menjauh dari masalah, ini adalah alat yang sangat kuat. Sebelum menerapkannya, Anda perlu menganalisis masalah "secara manual" dengan cara yang lebih sederhana. Dan hanya kemudian, dengan pemahaman tentang bidang subjek, beralih ke pembelajaran yang mendalam. Kalau tidak, model Anda akan belajar, tetapi Anda tidak akan. Ketika Anda menjadi lebih bodoh dari model Anda, itu berarti, secara halus, tidak efektif. Anda tidak dapat mengembangkan model lebih lanjut, dan ini adalah jalan buntu. Oleh karena itu, lebih baik untuk pertama menjadi mahir dalam ML klasik. Ini tidak berarti bahwa Anda perlu menghabiskan waktu bertahun-tahun, sangat mungkin untuk menguasai dalam waktu yang wajar.
Apakah Anda memiliki acara pembelajaran mesin?Kami memiliki serangkaian
hackathon SNA Hackathon . Sejauh ini, dua kali telah berlalu. Untuk pertama kalinya, hackathon dikhususkan untuk menganalisis teks dan mencoba memprediksi berapa banyak "kelas" yang akan diperoleh tulisan tertentu. Hackathon kedua terjadi setahun yang lalu dan dikhususkan untuk analisis grafik. Sudah banyak acara menarik. Kami memberikan informasi tentang "pertemanan" dari beberapa pengguna kami, tampaknya, sepotong kecil data sekitar 1 GB. Tetapi ketika peserta yang ingin mengirim ramalan mereka mencoba bekerja dengannya, hampir tidak ada yang bisa melakukannya, bahkan pada mesin dengan memori 16 dan 32 GB semuanya jatuh, terbang ke swap, tidak mau bekerja. Kami bahkan harus dengan tergesa-gesa menjelaskan bagaimana caranya dan bagaimana tidak bekerja dengan data.
Ternyata banyak, bahkan spesialis pembelajaran mesin yang cukup canggih, telah keluar dari akarnya dan mulai melupakan prinsip-prinsip dasar pemrograman. Lupakan apa itu tinju, bagaimana tabel hash terstruktur, berapa besar memori yang bisa terjadi jika Anda menggunakan tabel hash. Jika Anda tidak memikirkan semua ini dan melakukannya langsung dengan Python, Java atau Scala, masalah yang dijelaskan akan dijelaskan. Kami melakukan demo dengan Python, rake yang sama ada di bahasa lain. Grafik 40 juta tautan, yang bisa muat dalam memori 200 MB, meledak tajam pada 20 GB hanya karena Anda lupa bagaimana struktur data dasar diatur. Itu sangat mengesankan saat itu. Bahkan jika Anda adalah spesialis pembelajaran mesin, Anda tidak boleh melupakan dasar-dasar pemrograman.
Bagaimana alur kerja pemrosesan data Anda diatur?Pengguna berinteraksi dengan seluruh ekosistem produk kami. Kami secara kondisional dapat membedakan dua level: aplikasi front-end (aplikasi mobile, portal, versi mobile, berbagai aplikasi tambahan) dan logika bisnis. Front sering berinteraksi dengan pengguna dan memiliki akses ke sejumlah server yang sangat terbatas, sehingga ada beberapa metode khusus dalam logika bisnis yang memungkinkan front untuk mencatat data.
Data ini termasuk dalam bus data tunggal Apache Kafka. Ini adalah giliran yang telah menjadi standar industri yang digunakan untuk mengumpulkan data mentah. Secara alami, sulit untuk menganalisis data mentah di Kafka, sehingga mereka secara teratur ditransfer ke Hadoop yang besar dan tebal. Seseorang mungkin mengatakan bahwa Hadoop adalah abad terakhir, sekarang Spark memerintah. Tapi Hadoop adalah platform tempat Anda dapat menjalankan banyak alat. Kami memiliki berbagai alat analisis yang berputar di atas Hadoop. Saya sering menggunakan klasifikasi ini:
- Gaya entri data .
- Pemrosesan batch. Ada sejumlah data yang entah bagaimana Anda proses.
- Pemrosesan aliran. Anda bekerja dengan data real-time yang datang langsung dari stream, dalam hal ini dari Kafka kami.
Jika selama pemrosesan batch dapat terjadi penundaan yang cukup serius - kami mengumpulkan statistik di siang hari, dan Anda melatih model pada malam hari, maka dalam kasus pemrosesan streaming, penundaan diukur dalam satuan detik antara penerimaan data dan pemrosesannya.
- Analitik operasional . Ini adalah kontrol dan pemantauan proses. Melayani produksi, itu harus bekerja sendiri, tanpa campur tangan manusia.
- Analisis interaktif . Apa yang dilakukan seseorang. Kecepatan reaksi penting di sini: mereka melakukan sesuatu, mendapatkan hasilnya.
Di setiap ceruk ini, kami memiliki ekosistem produk kami sendiri. Misalnya, analitik operasional batch terutama menggunakan MapReduce klasik, Apache Tez, dan sedikit Spark. Jika kita berbicara tentang analytics batch interaktif, ini adalah Spark SQL dan bahasa scripting Pig and Hive.
Tentu saja, tidak ada garis yang jelas, karena beberapa bahasa interaktif sering digunakan untuk analitik kumpulan operasional. Apache Samza. LinkedIn. 2014 . , Spark Streaming, -.
- production, . , Kafka, . Kafka — , , . , Kafka , Streaming Index. Kafka : Casandra , SMC.
, , 99 %. - Streaming Index, . , , , «» , . , .
, , -. ?Mac.
IDE?Idea.
: ?.
?, .
, IT- 10 ?, .
?: , . , , , .
?, . . , , . , , .
, . «»?, : «».
?, .
?Ya
?.