Pada tanggal 28 Mei, pada konferensi
RootConf 2018, yang berlangsung sebagai bagian dari
festival RIT ++ 2018, di bagian “Penebangan dan Pemantauan”, sebuah laporan “Pemantauan dan Kubernet” disampaikan. Ini menceritakan tentang pengalaman pengaturan pemantauan dengan Prometheus, yang diperoleh oleh Flant sebagai hasil dari operasi puluhan proyek Kubernetes dalam produksi.

Secara tradisi, kami senang menyajikan
video dengan laporan (sekitar satu jam,
jauh lebih informatif
daripada artikel) dan penekanan utama dalam bentuk teks. Ayo pergi!
Apa itu pemantauan?
Ada banyak sistem pemantauan:

Tampaknya mengambil dan menginstal salah satunya - itu saja, pertanyaannya sudah ditutup. Tetapi latihan menunjukkan bahwa ini tidak benar. Dan inilah alasannya:
- Speedometer menunjukkan kecepatan . Jika kita mengukur kecepatan satu menit sekali dengan speedometer, maka kecepatan rata-rata, yang kita hitung berdasarkan data ini, tidak akan bertepatan dengan data odometer. Dan jika dalam kasus mobil ini jelas, maka ketika menyangkut banyak, banyak indikator untuk server, kita sering melupakannya.
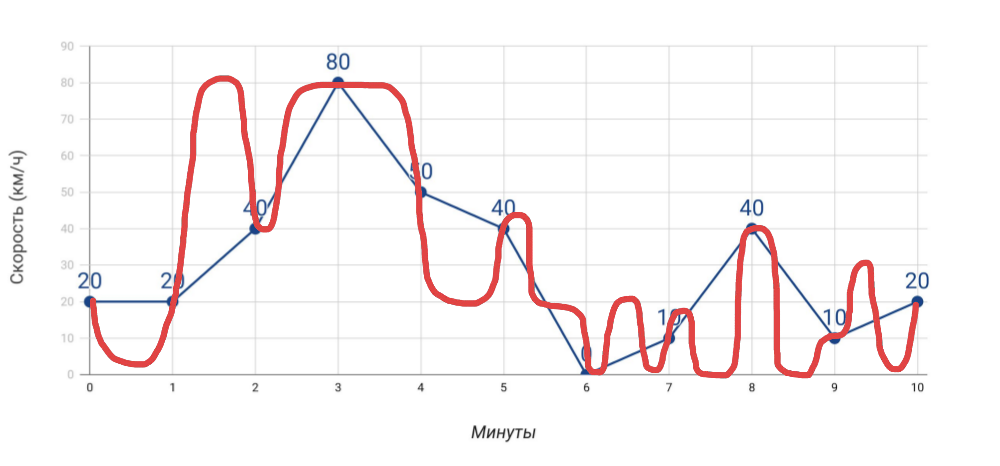
Apa yang kami ukur dan bagaimana kami bepergian - Lebih banyak pengukuran . Semakin banyak indikator yang kita dapatkan, diagnosis masalah akan lebih akurat ... tetapi hanya dengan syarat bahwa ini adalah indikator yang benar-benar bermanfaat, dan bukan hanya segala sesuatu yang Anda kumpulkan.
- Lansiran . Tidak ada yang rumit dalam mengirim peringatan. Namun, dua masalah umum: a) alarm palsu terjadi sangat sering sehingga kita berhenti merespons peringatan apa pun, b) peringatan datang pada saat terlambat (semuanya sudah meledak). Dan untuk mencapai dalam memantau bahwa masalah ini tidak muncul adalah seni asli!
Pemantauan adalah kue tiga lapis, yang masing-masing sangat penting:
- Pertama-tama, ini adalah sistem yang memungkinkan Anda untuk mencegah kecelakaan , memberi tahu tentang kecelakaan (jika tidak dapat dicegah) dan melakukan diagnosis masalah dengan cepat .
- Apa yang dibutuhkan untuk ini? Data akurat , bagan berguna (lihat mereka dan pahami di mana masalahnya), peringatan yang relevan (tiba pada waktu yang tepat dan mengandung informasi yang jelas).
- Dan agar semua ini berfungsi, diperlukan sistem pemantauan .
Pengaturan yang tepat dari sistem pemantauan yang benar-benar berfungsi bukanlah tugas yang mudah, membutuhkan pendekatan yang bijaksana untuk implementasi bahkan tanpa Kubernetes. Tapi apa yang terjadi dengan penampilannya?
Spesifik pemantauan Kubernetes
1 Lebih besar dan lebih cepat
Kubernet berubah banyak karena infrastrukturnya semakin besar dan cepat. Jika sebelumnya, dengan server besi biasa, jumlahnya sangat terbatas, dan proses penambahannya sangat lama (butuh berhari-hari atau berminggu-minggu), maka dengan mesin virtual jumlah entitas meningkat secara signifikan, dan waktu pengenalan mereka ke pertempuran berkurang menjadi detik.
Dengan Kubernetes, jumlah entitas telah bertambah dengan urutan besarnya, penambahan mereka sepenuhnya otomatis (manajemen konfigurasi diperlukan, karena tanpa deskripsi pod baru tidak dapat dibuat), seluruh infrastruktur menjadi sangat dinamis (misalnya, pod dihapus dan dirilis setiap kali dibuat lagi).
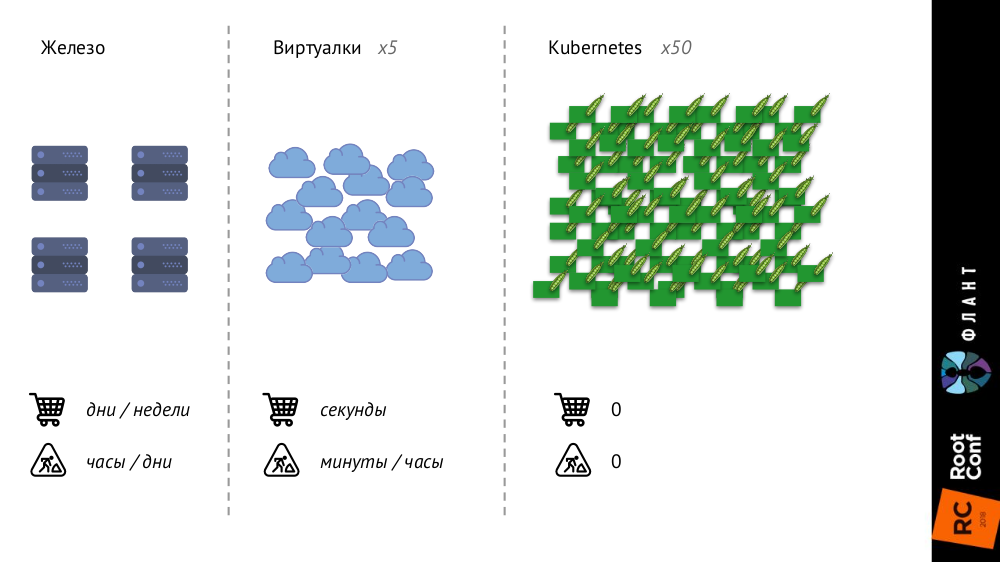
Apa yang berubah?
- Pada prinsipnya, kita berhenti melihat pod atau wadah individu - sekarang kita hanya tertarik pada kelompok objek .
- Service Discovery menjadi sangat wajib , karena "kecepatan" sudah sedemikian sehingga, pada prinsipnya, kami tidak dapat secara manual memulai / menghapus entitas baru, seperti sebelumnya, ketika server baru dibeli.
- Jumlah data tumbuh secara signifikan . Jika metrik sebelumnya dikumpulkan dari server atau mesin virtual, sekarang dari pod, jumlahnya jauh lebih besar.
- Perubahan paling menarik yang saya sebut " aliran metadata " dan saya akan memberi tahu Anda lebih banyak tentang hal itu.
Saya akan mulai dengan perbandingan ini:
- Ketika Anda mengirim anak Anda ke taman kanak-kanak, ia akan diberi kotak pribadi, yang ditugaskan kepadanya untuk tahun berikutnya (atau lebih) dan di mana namanya disebutkan.
- Ketika Anda datang ke kolam, loker Anda tidak ditandatangani dan diberikan kepada Anda untuk satu "sesi".
Jadi
sistem pemantauan klasik berpikir bahwa mereka adalah taman kanak-kanak , bukan kolam: mereka menganggap bahwa objek pemantauan datang kepada mereka selamanya atau untuk waktu yang lama, dan memberi mereka loker yang sesuai. Tetapi kenyataan di Kubernet berbeda: polong datang ke kolam (mis. Diciptakan), berenang di dalamnya (sampai penyebaran baru) dan meninggalkan (dihancurkan) - semua ini terjadi dengan cepat dan teratur. Dengan demikian, sistem pemantauan harus memahami bahwa objek yang dipantau hidup singkat, dan harus dapat sepenuhnya melupakannya pada waktu yang tepat.
2 Realitas paralel ada
Poin penting lainnya - dengan munculnya Kubernetes, kami secara bersamaan memiliki dua "realitas":
- Dunia Kubernetes di mana ada ruang nama, penyebaran, pod, wadah. Ini adalah dunia yang kompleks, tetapi logis, terstruktur.
- Dunia "fisik", terdiri dari banyak (secara harfiah - tumpukan) kontainer pada setiap simpul.
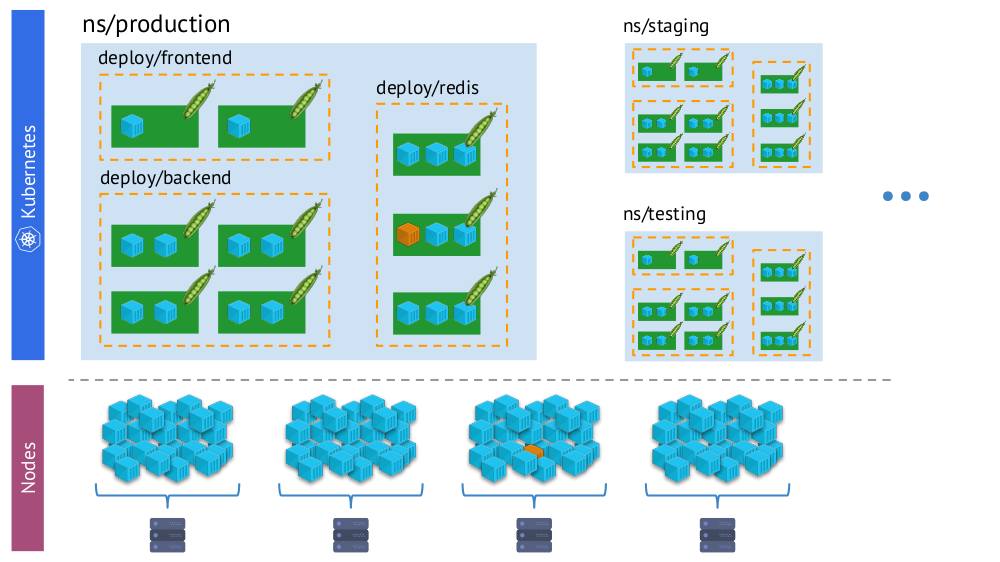 Satu dan wadah yang sama di Kubernet “realitas virtual” (di atas) dan dunia fisik simpul (di bawah)
Satu dan wadah yang sama di Kubernet “realitas virtual” (di atas) dan dunia fisik simpul (di bawah)Dan dalam proses pemantauan, kita perlu terus-menerus
membandingkan dunia fisik wadah dengan realitas Kubernet . Misalnya, ketika kita melihat beberapa namespace, kita ingin tahu di mana semua wadahnya (atau wadah salah satu perapiannya) berada. Tanpa ini, peringatan tidak akan visual dan nyaman digunakan - karena penting bagi kita untuk memahami objek apa yang mereka laporkan.
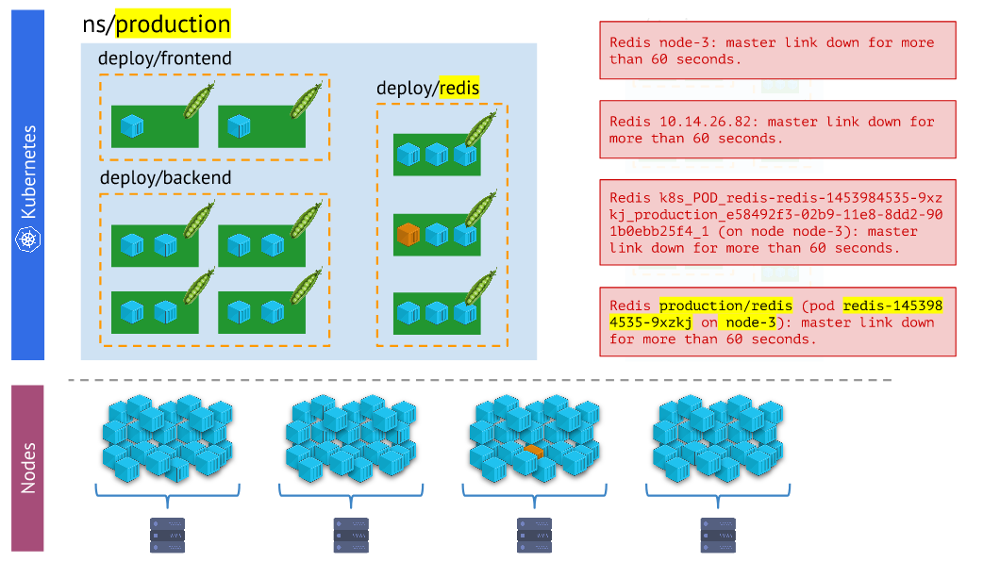 Berbagai jenis lansiran - yang terakhir lebih visual dan nyaman digunakan daripada yang lainnyaKesimpulan di
Berbagai jenis lansiran - yang terakhir lebih visual dan nyaman digunakan daripada yang lainnyaKesimpulan di sini adalah:
- Sistem pemantauan harus menggunakan primitif bawaan Kubernetes.
- Ada lebih dari satu kenyataan: sering kali masalah tidak terjadi dengan perapian, tetapi dengan simpul tertentu, dan kita perlu terus-menerus memahami seperti apa "realitas" yang mereka hadapi.
- Dalam satu cluster, sebagai aturan, ada beberapa lingkungan (selain produksi), yang berarti bahwa ini harus diperhitungkan (misalnya, tidak menerima peringatan di malam hari tentang masalah pada dev).
Jadi, kami memiliki tiga syarat yang diperlukan agar semuanya berjalan:
- Kami sangat memahami apa itu pemantauan.
- Kami tahu tentang fitur-fiturnya, fitur yang muncul dengan Kubernetes.
- Kami mengadopsi Prometheus.
Jadi, untuk benar-benar berhasil, tetap hanya membuat
banyak usaha! Ngomong-ngomong, mengapa tepatnya Prometheus? ..
Prometheus
Ada dua cara untuk menjawab pertanyaan tentang memilih Prometheus:
- Lihat siapa dan apa yang biasanya digunakan untuk memantau Kubernet.
- Pertimbangkan keunggulan teknisnya.
Untuk yang pertama, saya menggunakan data survei dari The New Stack (dari
The State of the Kubernetes Ecosystem e-book), yang menurutnya Prometheus paling tidak lebih populer daripada solusi lain (baik Open Source, dan SaaS), dan jika Anda lihat, ini memiliki keunggulan statistik lima kali lipat. .
Sekarang mari kita lihat bagaimana Prometheus bekerja, bersamaan dengan bagaimana kapabilitasnya bergabung dengan Kubernetes dan menyelesaikan tantangan terkait.
Bagaimana Prometheus terstruktur?
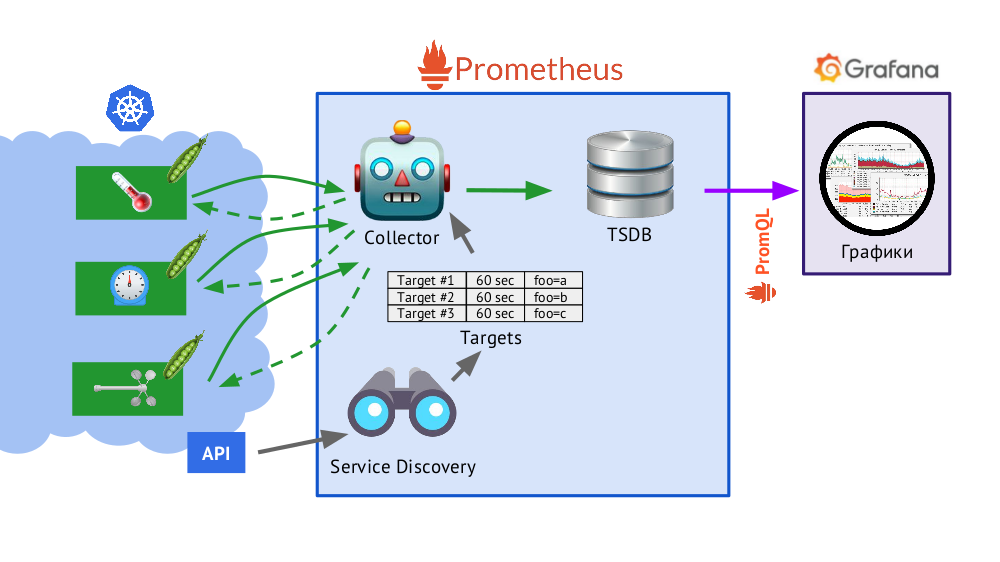
Prometheus ditulis dalam Go dan didistribusikan sebagai file biner tunggal, di mana semuanya built-in. Algoritma dasar untuk operasinya adalah sebagai berikut:

- Kolektor membaca tabel target , mis. daftar objek yang akan dipantau dan frekuensi pemungutan suaranya (secara default - 60 detik).
- Setelah itu, kolektor mengirimkan permintaan HTTP ke setiap pod yang Anda butuhkan dan menerima respons dengan serangkaian metrik - mungkin ada seratus, seribu, sepuluh ribu ... Setiap metrik memiliki nama, nilai, dan label .
- Respons yang diterima disimpan dalam basis data TSDB , di mana cap waktu tanda terima dan label objek dari mana ia diambil ditambahkan ke data metrik yang diterima.
Secara singkat tentang TSDBTSDB - basis data deret waktu (DB untuk deret waktu) on Go, yang memungkinkan Anda menyimpan data selama beberapa hari dan melakukannya dengan sangat efisien (dalam ukuran, memori, dan input / output). Data disimpan hanya secara lokal, tanpa pengelompokan dan replikasi, yang merupakan nilai tambah (ini berfungsi dengan mudah dan terjamin) dan nilai minus (tidak ada penskalaan horizontal penyimpanan), tetapi dalam kasus pengabaian Prometheus dilakukan dengan baik, federasi - lebih lanjut tentang ini nanti.
- Disajikan dalam skema, Service Discovery adalah mesin penemuan layanan yang dibangun di Prometheus yang memungkinkan Anda menerima data "dari kotak" (melalui API Kubernetes) untuk membuat tabel sasaran.
Seperti apa tabel ini? Untuk setiap entri, ia menyimpan URL yang digunakan untuk mendapatkan metrik, frekuensi panggilan dan label.
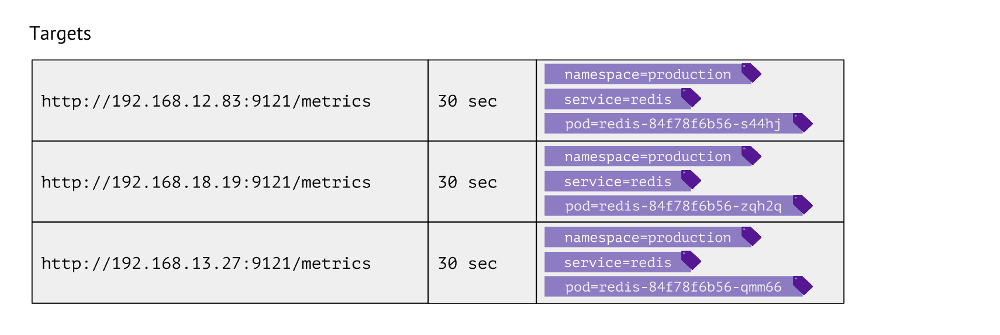
Label digunakan untuk penjajaran "dunia" Kubernetes dengan fisik. Misalnya, untuk menemukan pod dengan Redis, kita perlu memiliki nilai namespace, layanan (digunakan alih-alih penyebaran karena fitur teknis untuk kasus tertentu) dan pod aktual. Dengan demikian, 3 label ini disimpan dalam entri tabel tujuan untuk metrik Redis.
Entri-entri dalam tabel ini dibentuk berdasarkan
scrape_configs Prometheus di mana objek pemantauan dijelaskan: di bagian
scrape_configs ,
scrape_configs ditentukan, yang menunjukkan label mana yang akan mencari objek untuk dipantau, cara memfilternya, dan label mana yang akan direkam.
Data apa yang dikumpulkan Kubernet?
- Pertama, penyihir di Kubernetes cukup rumit - dan sangat penting untuk memantau keadaan kerjanya (kube-apiserver, kube-controller-manager, kube-scheduler, kube-etcd3 ...), terlebih lagi, ia terikat pada node cluster.
- Kedua, penting untuk mengetahui apa yang sedang terjadi di dalam Kubernetes . Untuk melakukan ini, kami mendapatkan data dari:
- kubelet - komponen Kubernetes ini berjalan di setiap node cluster (dan terhubung ke wizard K8s); cAdvisor dibangun di dalamnya (semua metrik menurut wadah), dan juga menyimpan informasi tentang Persistent Volume yang terhubung;
- kube-state-metrics - sebenarnya, ini adalah Eksportir Prometheus untuk API Kubernetes (memungkinkan Anda untuk mendapatkan informasi tentang objek yang disimpan di Kubernet: pod, layanan, penyebaran, dll.; misalnya, kami tidak akan tahu tanpanya wadah atau status perapian);
- simpul-eksportir - memberikan informasi tentang simpul itu sendiri, metrik dasar pada sistem Linux (cpu, diskstats, meminfo, dan sebagainya ).
- Berikutnya adalah komponen Kubernetes , seperti kube-dns, kube-prometheus-operator dan kube-prometheus, ingress-nginx-controller, dll.
- Kategori objek berikutnya untuk dipantau sebenarnya adalah perangkat lunak yang diluncurkan di Kubernetes. Ini adalah layanan server yang khas seperti nginx, php-fpm, Redis, MongoDB, RabbitMQ ... Kami melakukannya sendiri sehingga ketika kami menambahkan label tertentu ke layanan, secara otomatis mulai mengumpulkan data yang diperlukan, yang menciptakan dasbor saat ini di Grafana.
- Akhirnya, kategori untuk semua yang lain adalah kebiasaan . Alat Prometheus memungkinkan Anda untuk mengotomatiskan koleksi metrik sewenang-wenang (misalnya, jumlah pesanan) dengan hanya menambahkan satu label
prometheus-custom-target ke deskripsi layanan.

Grafik
Data yang diterima
(dijelaskan di atas) digunakan untuk mengirim peringatan dan membuat grafik. Kami menggambar grafik menggunakan
Grafana . Dan "detail" penting di sini adalah
PromQL , bahasa permintaan Prometheus yang terintegrasi sempurna dengan Grafana.
Ini cukup sederhana dan nyaman untuk sebagian besar tugas
(tetapi, misalnya, bergabung dengan bergabung di dalamnya sudah tidak nyaman, tetapi Anda masih harus melakukannya) . PromQL memungkinkan Anda untuk menyelesaikan semua tugas yang diperlukan: dengan cepat memilih metrik yang diperlukan, membandingkan nilai, melakukan operasi aritmatika pada mereka, grup, bekerja dengan interval waktu dan banyak lagi. Sebagai contoh:

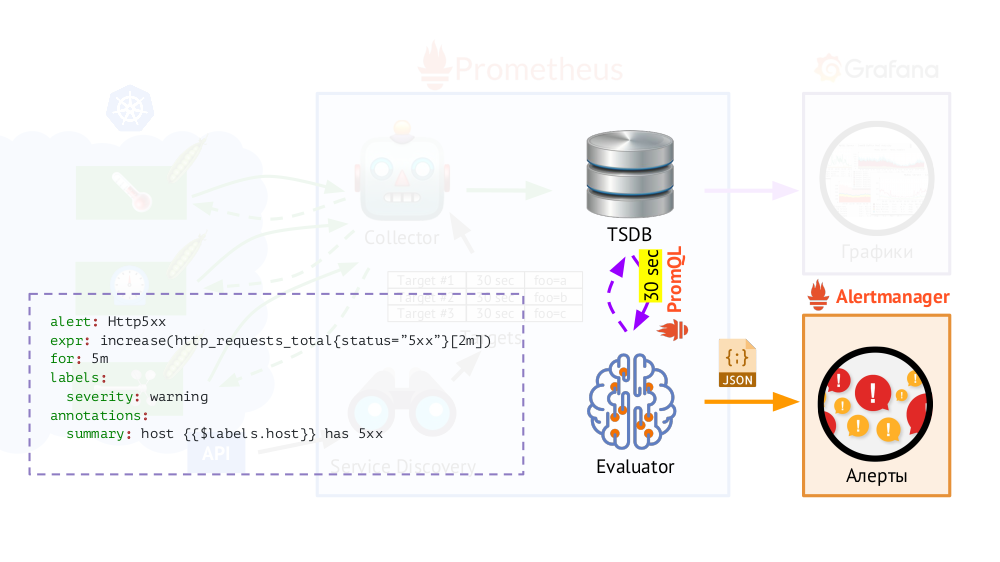
Selain itu, Prometheus memiliki
Evaluator , yang, menggunakan PromQL yang sama, dapat mengakses TSDB dengan frekuensi yang ditentukan. Kenapa ini? Contoh: mulai mengirimkan peringatan jika kami memiliki, berdasarkan metrik yang tersedia, kesalahan 500 pada server web selama 5 menit terakhir. Selain label yang ada dalam permintaan, Evaluator menambahkan yang tambahan (seperti yang kita konfigurasi) ke data untuk peringatan, setelah itu mereka dikirim dalam format JSON ke komponen Prometheus lain -
Alertmanager .
Prometheus secara berkala (sekali setiap 30 detik) mengirimkan peringatan kepada Alertmanager, yang menduplikasi mereka (setelah menerima peringatan pertama, itu akan mengirimnya, dan yang berikutnya tidak akan dikirim lagi).
 Catatan : Kami tidak menggunakan Alertmanager di rumah, tetapi mengirim data dari Prometheus langsung ke sistem kami, yang digunakan petugas kami untuk bekerja, tetapi ini tidak masalah dalam skema umum.
Catatan : Kami tidak menggunakan Alertmanager di rumah, tetapi mengirim data dari Prometheus langsung ke sistem kami, yang digunakan petugas kami untuk bekerja, tetapi ini tidak masalah dalam skema umum.Prometheus at Kubernetes: The Big Picture
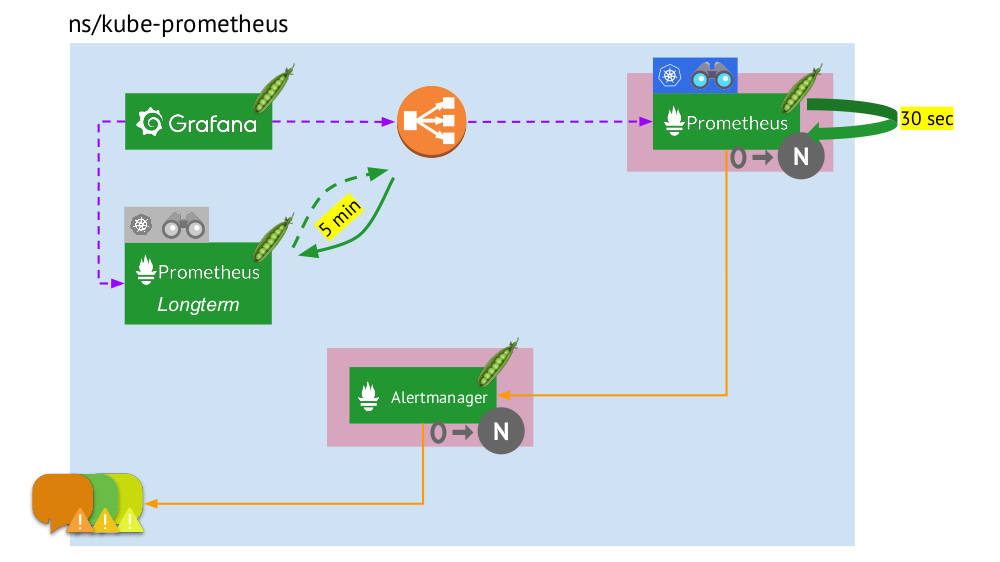
Sekarang mari kita lihat bagaimana seluruh bundel Prometheus ini bekerja di dalam Kubernetes:
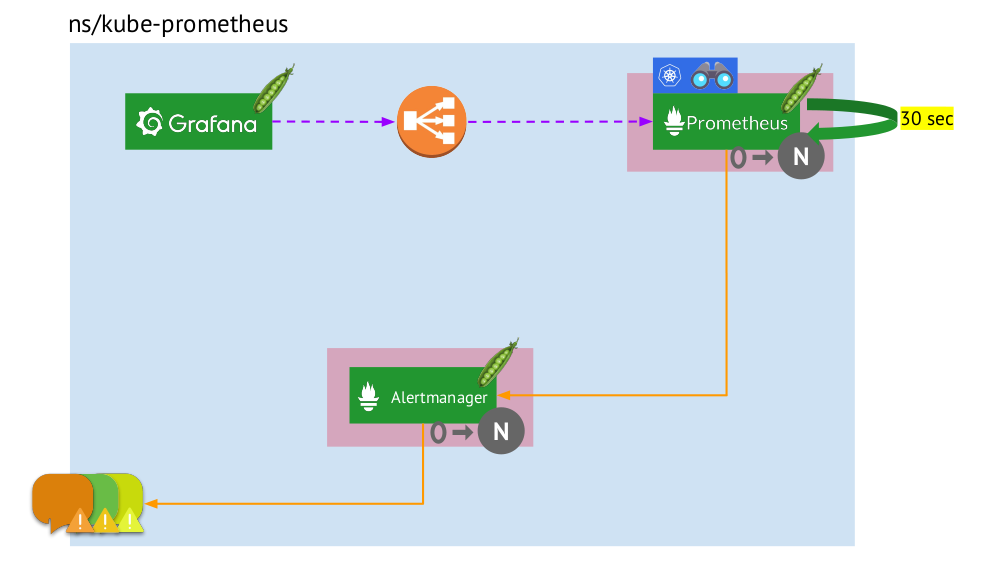
- Kubernetes memiliki namespace sendiri untuk Prometheus (kami memiliki
kube-prometheus dalam ilustrasi) . - Namespace ini meng-host pod dengan instalasi Prometheus, yang setiap 30 detik mengumpulkan metrik dari semua target yang diterima melalui Service Discovery di cluster.
- Ia juga menampung pod dengan Alertmanager, yang menerima data dari Prometheus dan mengirimkan peringatan (ke surat, Slack, PagerDuty, WeChat, integrasi pihak ketiga, dan sebagainya ) .
- Prometheus menghadapi penyeimbang beban - Layanan reguler di Kubernetes - dan Grafana mengakses Prometheus melalui itu. Untuk memastikan toleransi kesalahan, Prometheus menggunakan beberapa pod dengan instalasi Prometheus, yang masing-masing mengumpulkan semua data dan menyimpannya dalam TSDB-nya. Melalui penyeimbang, Grafana memukul salah satunya.
- Jumlah pod dengan Prometheus dikendalikan oleh pengaturan StatefulSet - kami biasanya membuat tidak lebih dari dua pod, tetapi Anda dapat menambah jumlah ini. Demikian pula, melalui StatefulSet, seorang Alertmanager juga dikerahkan, untuk toleransi kesalahan yang membutuhkan setidaknya 3 polong (karena kuorum diperlukan untuk membuat keputusan tentang mengirimkan peringatan).
Apa yang hilang di sini? ..
Federasi untuk Prometheus
Ketika data dikumpulkan setiap 30 (atau 60) detik, tempat untuk menyimpannya dengan sangat cepat berakhir, dan bahkan lebih buruk, itu membutuhkan banyak sumber daya komputasi (ketika menerima dan memproses sejumlah besar titik dari TSDB). Tetapi kami ingin menyimpan dan memiliki kemampuan untuk mengunduh informasi untuk
interval waktu besar dan e waktu . Bagaimana cara mencapai ini?
Cukup menambahkan
satu instalasi lagi Prometheus (kami menyebutnya
jangka panjang ) ke skema umum, di mana Service Discovery dinonaktifkan, dan di tabel tujuan hanya ada catatan statis yang mengarah ke Prometheus
utama (
utama ).
Ini dimungkinkan berkat federasi : Prometheus memungkinkan Anda mengembalikan nilai terbaru semua metrik dalam satu kueri. Dengan demikian, instalasi pertama Prometheus masih berfungsi (mengakses setiap 60 atau, misalnya, 30 detik) ke semua target di kluster Kubernetes, dan yang kedua - sekali setiap 5 menit, menerima data dari yang pertama dan menyimpannya untuk dapat menonton data untuk jangka waktu yang lama ( tetapi tanpa detail yang dalam).
 Instalasi Prometheus kedua tidak perlu Service Discovery, dan tabel sasaran akan terdiri dari satu baris
Instalasi Prometheus kedua tidak perlu Service Discovery, dan tabel sasaran akan terdiri dari satu baris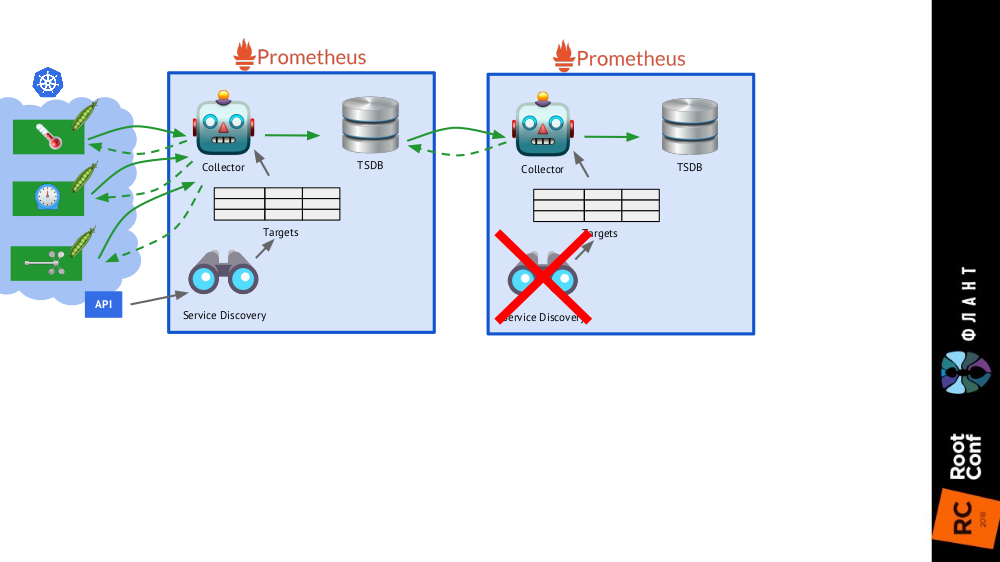 Seluruh gambar dengan instalasi Prometheus dari dua jenis: utama (atas) dan jangka panjang
Seluruh gambar dengan instalasi Prometheus dari dua jenis: utama (atas) dan jangka panjangSentuhan terakhir adalah
menghubungkan Grafana ke instalasi Prometheus dan membuat dasbor dengan cara khusus sehingga Anda dapat beralih di antara sumber data (
utama atau
jangka panjang ). Untuk melakukan ini, menggunakan mesin templat, gantikan variabel
$prometheus alih-alih sumber data di semua panel.
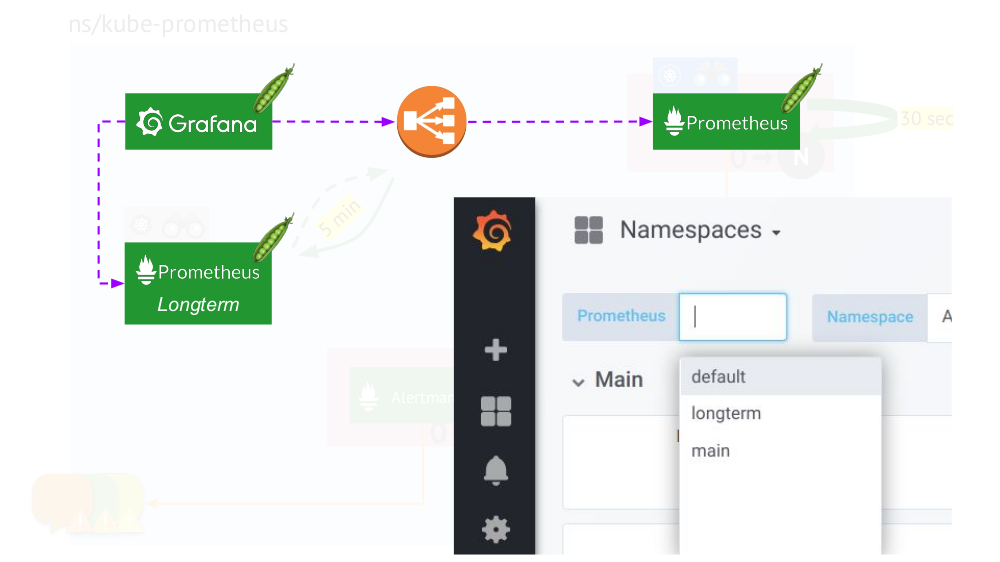
Apa lagi yang penting dalam grafik?
Dua poin utama yang perlu dipertimbangkan ketika mengatur jadwal adalah dukungan untuk primitif Kubernetes dan kemampuan untuk dengan cepat menelusuri dari gambaran keseluruhan (atau "tampilan" yang lebih rendah) ke layanan tertentu dan sebaliknya.
Dukungan untuk primitif (ruang nama, polong, dll.) Telah disebutkan - ini adalah kondisi yang diperlukan pada prinsipnya untuk pekerjaan yang nyaman dalam realitas Kubernetes. Dan berikut adalah contoh tentang menelusuri:
- Kami melihat grafik konsumsi sumber daya oleh tiga proyek (mis., Tiga ruang nama) - kami melihat bahwa bagian utama CPU (atau memori, atau jaringan, ...) jatuh pada proyek A.
- Kami melihat grafik yang sama, tetapi sudah untuk layanan Proyek A: yang mana dari mereka yang paling banyak mengkonsumsi CPU?
- Kami beralih ke bagan layanan yang diinginkan: pod mana yang “disalahkan”?
- Kita beralih ke grafik pod yang diinginkan: wadah mana yang harus "disalahkan"? Inilah tujuan yang diinginkan!
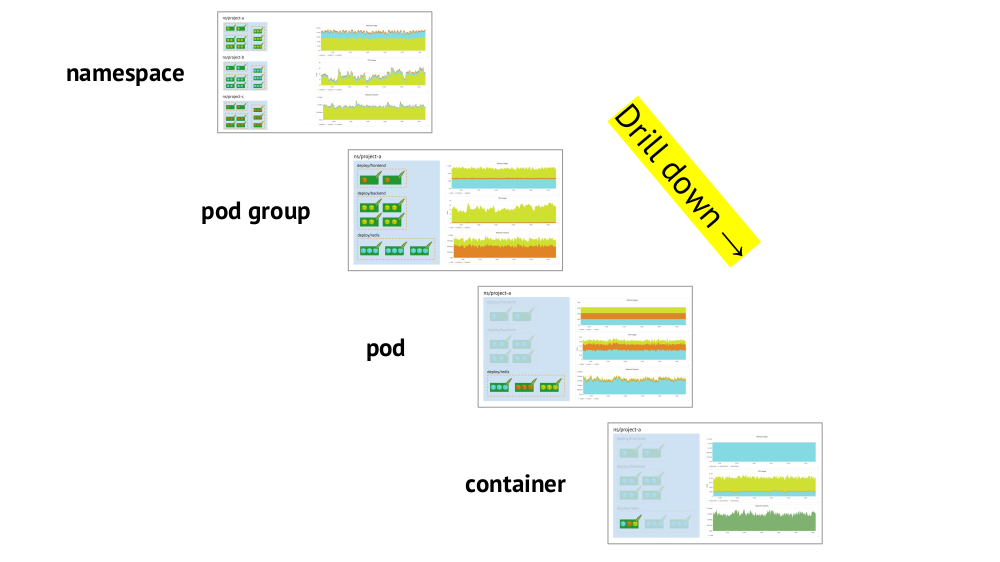
Ringkasan
- Nyatakan secara akurat untuk diri Anda sendiri apa itu pemantauan. (Biarkan "kue tiga lapis" berfungsi sebagai pengingat ini ... serta fakta bahwa memanggang dengan kompeten tidak mudah bahkan tanpa Kubernetes!)
- Ingat bahwa Kubernetes menambahkan spesifik wajib: pengelompokan target, penemuan layanan, sejumlah besar data, aliran metadata. Selain itu:
- ya, beberapa dari mereka secara ajaib ("out of the box") diselesaikan di Prometheus;
- namun, masih ada bagian lain yang perlu dipantau secara independen dan dipertimbangkan.
Dan ingat bahwa
konten lebih penting daripada sistem , mis. bagan dan peringatan yang benar adalah yang utama, dan bukan Prometheus (atau perangkat lunak serupa lainnya).

Video dan slide
Video dari kinerja (sekitar satu jam):
Penyajian laporan:
PS
Laporan lain di blog kami:
Anda mungkin juga tertarik dengan publikasi berikut: