Salam untuk komunitas terhormat!
Pengulangan adalah ibu dari pembelajaran, dan memahami parsing adalah keterampilan yang sangat berguna bagi programmer mana pun, jadi saya ingin mengangkat topik ini lagi dan berbicara kali ini tentang analisis recursive descent (LL) tanpa melakukan terlalu banyak formalisme (Anda selalu dapat menggunakannya nanti) kembali).
Seperti yang ditulis oleh D. Strogov, "memahami berarti menyederhanakan." Oleh karena itu, untuk memahami konsep parsing menggunakan metode turunan rekursif (alias LL-parsing), kami menyederhanakan tugas sebanyak mungkin dan secara manual menulis parser dari format yang mirip dengan JSON, tetapi lebih sederhana (jika Anda mau, Anda kemudian dapat memperluasnya ke parser JSON lengkap jika ingin berolahraga). Mari kita menulisnya, mengambil sebagai dasar gagasan
memotong tali .
Dalam buku-buku klasik dan kursus desain kompiler, mereka biasanya mulai menjelaskan topik parsing dan interpretasi, menyoroti beberapa fase:
- Analisis leksikal: membelah teks sumber menjadi array substring (token, atau token)
- Parsing: membangun pohon parsing dari berbagai token
- Interpretasi (atau kompilasi): melintasi pohon yang dihasilkan dalam urutan yang diinginkan (langsung atau terbalik) dan melakukan beberapa interpretasi atau tindakan pembuatan kode pada beberapa langkah traversal ini
tidak jugakarena dalam proses penguraian kita sudah mendapatkan urutan langkah-langkah, yang merupakan urutan kunjungan ke simpul pohon, pohon itu sendiri dalam bentuk eksplisit mungkin tidak ada sama sekali, tetapi kita belum akan pergi jauh. Bagi yang ingin masuk lebih dalam, ada tautan di bagian akhir.
Sekarang saya ingin menggunakan pendekatan yang sedikit berbeda dengan konsep yang sama ini (penguraian LL) dan menunjukkan bagaimana Anda dapat membangun penganalisis LL berdasarkan ide memotong string: fragmen dipotong dari string asli selama penguraian, itu menjadi lebih kecil, dan kemudian diurai mengekspos sisa garis. Sebagai hasilnya, kita sampai pada konsep yang sama tentang turunan rekursif, tetapi dengan cara yang sedikit berbeda dari yang biasanya dilakukan. Mungkin jalan ini akan lebih nyaman untuk memahami esensi gagasan. Dan jika tidak, maka masih ada kesempatan untuk melihat keturunan rekursif dari sudut yang berbeda.
Mari kita mulai dengan tugas yang lebih sederhana: ada garis dengan pembatas, dan saya ingin menulis iterasi atas nilainya. Sesuatu seperti:
String names = "ivanov;petrov;sidorov"; for (String name in names) { echo("Hello, " + name); }
Bagaimana ini bisa dilakukan? Cara standar adalah untuk mengubah string yang dibatasi ke array atau daftar menggunakan String.split (di Jawa), atau names.split (",") (dalam javascript), dan iterate melalui array yang sudah ada. Tetapi mari kita bayangkan bahwa kita tidak ingin atau tidak dapat menggunakan konversi ke sebuah array (misalnya, yah, tiba-tiba jika kita memprogram dalam bahasa pemrograman AVAJ ++, di mana tidak ada struktur data "array"). Anda masih dapat memindai string dan melacak pembatas, tetapi saya tidak akan menggunakan metode ini juga, karena itu membuat kode loop iterasi rumit dan, yang paling penting, itu bertentangan dengan konsep yang ingin saya tampilkan. Oleh karena itu, kami akan berhubungan dengan string yang dibatasi dengan cara yang sama seperti yang berhubungan dengan daftar dalam pemrograman fungsional. Dan di sana mereka selalu mendefinisikan fungsi head (mendapatkan elemen pertama dari daftar) dan tail (mendapatkan sisa daftar). Mulai dari dialek pertama Lisp, di mana fungsi-fungsi ini disebut benar-benar mengerikan dan tidak intuitif: mobil dan cdr (mobil = isi register alamat, cdr = isi register penurunan. Legenda lama dalam, ya, eheheh.).
Baris kami adalah garis yang dibatasi. Sorot pembagi berwarna ungu:
Dan sorot daftar item dengan warna kuning:

Kami berasumsi bahwa baris kami bisa berubah (dapat diubah) dan menulis fungsi:
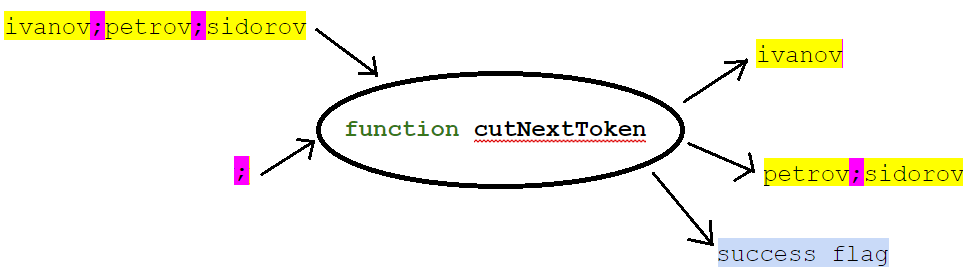
Tanda tangannya, misalnya, mungkin:
public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token)
Pada input fungsi, kami memberikan daftar (dalam bentuk string dengan pembatas) dan, pada kenyataannya, nilai pembatas. Pada output, fungsi mengembalikan elemen pertama dari daftar (segmen garis ke pemisah pertama), sisa daftar dan tanda apakah elemen pertama dikembalikan. Dalam hal ini, sisa daftar ditempatkan dalam variabel yang sama di mana daftar asli berada.
Akibatnya, kami mendapat kesempatan untuk menulis seperti ini:
StringBuilder names = new StringBuilder("ivanov;petrov;sidorov"); StringBuilder name = new StringBuilder(); while(cutNextToken(names, ";", name)) { System.out.println(name); }
Output seperti yang diharapkan:
ivanov
petrov
sidorov
Kami melakukannya tanpa konversi ke ArrayList, tetapi merusak variabel nama, dan sekarang memiliki string kosong. Ini belum terlihat sangat berguna, seolah-olah mereka mengubah penusuk untuk sabun. Tapi mari kita melangkah lebih jauh. Di sana kita akan melihat mengapa itu perlu dan ke mana itu akan menuntun kita.
Sekarang mari kita parsing sesuatu yang lebih menarik: daftar pasangan kunci-nilai. Ini juga merupakan tugas yang sangat umum.
StringBuilder pairs = new StringBuilder("name=ivan;surname=ivanov;middlename=ivanovich"); StringBuilder pair = new StringBuilder(); while (cutNextToken(pairs, ";", pair)) { StringBuilder paramName = new StringBuilder(); StringBuilder paramValue = new StringBuilder(); cutNextToken(pair, "=", paramName); cutNextToken(pair, "=", paramValue); System.out.println("param with name \"" + paramName + "\" has value of \"" + paramValue + "\""); }
Kesimpulan:
param with name "name" has value of "ivan" param with name "surname" has value of "ivanov" param with name "middlename" has value of "ivanovich"
Juga diharapkan. Dan hal yang sama dapat dicapai dengan String.split, tanpa memotong garis.
Tetapi katakanlah sekarang kita ingin menyulitkan format kita dan beralih dari nilai kunci datar ke format nestable yang mengingatkan kita pada JSON. Sekarang kami ingin membaca sesuatu seperti ini:
{'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}
Pemisah apa yang dipisah? Jika itu koma, maka di salah satu token kami akan memiliki garis
'birthdate':{'year':'1984'
Jelas bukan yang kita butuhkan. Karena itu, kita harus memperhatikan struktur garis yang ingin kita uraikan.
Dimulai dengan penjepit keriting dan berakhir dengan penjepit keriting (dipasangkan dengan itu, yang penting). Di dalam tanda kurung ini adalah daftar 'kunci' pasangan: 'nilai', setiap pasangan dipisahkan dari pasangan berikutnya dengan koma. Kunci dan nilai dipisahkan oleh titik dua. Kunci adalah serangkaian huruf yang dilampirkan dalam apostrof. Nilai dapat berupa string karakter yang dilampirkan dalam apostrof, atau bisa juga struktur yang sama, dimulai dan diakhiri dengan kurung kurawal berpasangan. Kami menyebut struktur seperti itu dengan kata "objek", seperti kebiasaan untuk menyebutnya dalam JSON.
Kami hanya secara informal menggambarkan tata bahasa format JSON kami. Biasanya, tata bahasa dijelaskan secara terbalik, dalam bentuk formal, dan notasi BNF atau variasinya digunakan untuk menulisnya. Tapi sekarang saya bisa melakukannya tanpa itu, dan kita akan lihat bagaimana Anda dapat "memotong" baris ini sehingga dapat diurai sesuai dengan aturan tata bahasa ini.
Sebenarnya, "objek" kita dimulai dengan penjepit keriting pembuka dan berakhir dengan sepasang yang menutupnya. Apa yang bisa dilakukan fungsi parsing format seperti itu? Kemungkinan besar, berikut ini:
- pastikan string yang diteruskan dimulai dengan penjepit pembuka
- pastikan bahwa string yang diteruskan berakhir dengan sepasang kawat gigi penutup
- jika kedua kondisi benar, potong tanda kurung buka dan tutup, dan yang tersisa, berikan fungsi yang mem-parsing daftar pasangan 'kunci': 'nilai'
Harap dicatat: kata-kata "fungsi parsing format ini" dan "fungsi parsing daftar pasangan 'kunci': 'nilai'" muncul. Kami memiliki dua fitur! Ini adalah fungsi yang dalam deskripsi klasik dari algoritma turunan rekursif disebut "fungsi parsing simbol nonterminal", dan yang mengatakan bahwa "untuk setiap simbol nonterminal, fungsi parsing sendiri dibuat". Yang sebenarnya, mem-parsingnya. Kita bisa memberi nama mereka, katakanlah, parseJsonObject dan parseJsonPairList.
Juga sekarang kita perlu memperhatikan bahwa kita sudah mendapat konsep "pasang braket" selain konsep "pemisah". Jika untuk memotong garis ke pemisah berikutnya (titik dua antara kunci dan nilai, koma antara pasangan "kunci: nilai") fungsi cutNextToken sudah cukup bagi kita, sekarang kita dapat menggunakan tidak hanya string, tetapi juga objek, kita perlu berfungsi "potong ke pasangan kurung berikutnya". Sesuatu seperti ini:

Fungsi ini memotong sebuah fragmen dari garis dari braket pembuka ke pasangan yang menutupnya, diberi tanda kurung, jika ada. Tentu saja, Anda tidak dapat terbatas pada tanda kurung, tetapi menggunakan fungsi yang sama untuk memotong berbagai struktur blok yang dapat disarangkan: blok operator mulai..mengakhiri, jika..menerima, untuk..makhor dan yang sejenis.
Mari kita menggambar secara grafis apa yang akan terjadi pada string. Warna pirus - ini berarti kita memindai garis ke depan ke simbol yang disorot dalam pirus untuk menentukan apa yang harus kita lakukan selanjutnya. Violet adalah "apa yang harus dipotong, ini adalah saat kita memotong fragmen yang disorot dalam warna violet dari garis, dan terus mengurai apa yang tersisa dari itu lebih jauh.

Sebagai perbandingan, output dari program (teks program diberikan dalam lampiran) yang mem-parsing baris ini:
Demonstrasi penguraian struktur seperti JSON
ok, about to parse JSON object {'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}} ok, about to parse pair list 'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'name' found VALUE of type STRING:'ivan' ok, about to parse pair list 'surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'surname' found VALUE of type STRING:'ivanov' ok, about to parse pair list 'birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'birthdate' found VALUE of type OBJECT:{'year':'1984','month':'october','day':'06'} ok, about to parse JSON object {'year':'1984','month':'october','day':'06'} ok, about to parse pair list 'year':'1984','month':'october','day':'06' found KEY: 'year' found VALUE of type STRING:'1984' ok, about to parse pair list 'month':'october','day':'06' found KEY: 'month' found VALUE of type STRING:'october' ok, about to parse pair list 'day':'06' found KEY: 'day' found VALUE of type STRING:'06'
Kapan saja, kami tahu apa yang kami harapkan akan ditemukan di jalur input kami. Jika kita memasuki fungsi parseJsonObject, maka kita berharap bahwa objek itu diberikan kepada kita di sana, dan kita dapat memeriksa ini dengan kehadiran tanda kurung buka dan tutup di awal dan di akhir. Jika kita memasuki fungsi parseJsonPairList, maka kita mengharapkan daftar pasangan "key: value" di sana, dan setelah kita "menggigit" kunci (sebelum pemisah ":"), kami berharap bahwa hal berikutnya yang kami "gigit" adalah nilai. Kita dapat melihat karakter pertama dari nilai, dan menarik kesimpulan tentang jenisnya (jika tanda kutip, maka nilainya dari jenis "string", jika braket keriting pembukaan adalah nilainya dari jenis "objek").
Dengan demikian, memotong fragmen dari string, kita dapat menguraikannya dengan metode analisis top-down (keturunan rekursif). Dan ketika kita dapat menguraikan, kita dapat mem-parsing format yang kita butuhkan. Atau buat format Anda sendiri yang nyaman bagi kami dan bongkar. Atau muncul dengan Bahasa Spesifik Domain (DSL) untuk area spesifik kami dan rancang juru bahasa untuk itu. Dan untuk mengkonstruksinya dengan benar, tanpa solusi tersiksa pada regexp atau mesin negara buatan sendiri yang muncul untuk programmer yang mencoba untuk memecahkan beberapa masalah yang membutuhkan penguraian, tetapi tidak cukup memiliki materi.
Di sini Selamat untuk semua pada musim panas mendatang dan berharap Anda baik, cinta dan parser fungsional :)
Untuk bacaan lebih lanjut:
Ideologis: beberapa artikel yang panjang tapi layak dibaca oleh Steve Yeegge:
Makanan programmer kayaBeberapa kutipan dari sana:
Anda bisa belajar kompiler dan mulai menulis DSL Anda sendiri, atau membuat bahasa Anda lebih baik
Fase besar pertama dari pipa kompilasi adalah parsing
Masalah pinocchiomKutipan dari sana:
Ketik gips, penyempitan dan pelebaran konversi, fungsi teman untuk mem-bypass perlindungan kelas standar, memasukkan bahasa minilang ke dalam string dan menguraikannya dengan tangan , ada lusinan cara untuk mem-bypass sistem tipe di Java dan C ++, dan programmer menggunakannya sepanjang waktu , karena (sedikit yang mereka tahu) mereka sebenarnya mencoba membangun perangkat lunak, bukan perangkat keras.
Teknis: dua artikel tentang parsing tentang perbedaan antara pendekatan LL dan LR:
LL dan LR Parsing DemystifiedLL dan LR dalam Konteks: Mengapa Parsing Tools SulitDan bahkan lebih dalam ke topik: bagaimana menulis interpreter Lisp di C ++
Lisp interpreter dalam 90 baris C ++Aplikasi. Kode contoh (java) yang mengimplementasikan analisa yang dijelaskan dalam artikel: package demoll; public class DemoLL { public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token) { String s = svList.toString(); if (s.trim().isEmpty()){ return false; } int sepIndex = s.indexOf(separator); if (sepIndex == -1) {