 Diposting oleh Igor Masternaya, Pengembang Senior, Pemimpin Komunitas Java DataArt
Diposting oleh Igor Masternaya, Pengembang Senior, Pemimpin Komunitas Java DataArtPada 18-19 Mei, JEEonf diadakan di Kiev, salah satu acara yang paling dinanti untuk seluruh komunitas Jawa di Eropa Timur. DataArt bermitra dengan konferensi. Pembicara dari seluruh dunia berbicara pada empat tahap: Volker Simonis, Perwakilan SAP di
JCP dan kontributor OpenJDK, Jürgen Höller, Kepala Insinyur Pivotal, bapak Kerangka Kerja Musim Semi tercinta, Klaus Ibsen, pencipta Apache Camel, dan Hugh McKee, penginjil di Lightbend.
Jadwal sangat sibuk: dalam dua hari lebih dari 50 pertunjukan, masing-masing 45 menit. Istirahat 10 menit - dan lari ke laporan baru. Ini akan memakan waktu lama untuk menonton semua video ketika mereka muncul di jaringan. Oleh karena itu, saya akan menjelaskan secara singkat laporan yang menurut saya paling menarik dan yang saya kunjungi secara pribadi.
15 tahun Musim Semi
Konferensi dibuka oleh Jürgen Höller. Dia berbicara tentang 15 tahun (!) History of the Spring Framework, dari konfigurasi XML "favorit" di versi 0.9 hingga Spring WebFlux reaktif, yang muncul dari proyek penelitian yang dipengaruhi oleh
Reactive Manifesto . Jürgen berbicara tentang koeksistensi Spring MVC dan Spring WebFlux di Spring WEB, menjelaskan mengapa mereka memutuskan untuk tidak mengintegrasikannya. Intinya adalah bahwa abstraksi utama Spring MVC adalah Servlet API 3.0 dan memblokir IO, sementara Spring WebFlux menggunakan abstraksi Reactive Streams dan non-blocking IO. Anda dapat menjalankan layanan Anda di SpringWebFlux di server mana pun yang mendukung IO non-blocking: Netty, versi baru Tomcat (> 8.5), Jetty. Membuat pengontrol WebFlux reaktif tidak jauh berbeda dengan membuatnya menggunakan Spring MVC, tetapi masih ada perbedaan. Memproses permintaan pengguna, pengontrol reaktif tidak memprosesnya dalam pengertian biasa, tetapi membuat saluran pipa untuk memproses permintaan tersebut. Dispatcher memanggil metode pengontrol, yang membuat pipa dan segera memberikannya sebagai aliran penerbit. Aliran penerbit di Reactive Spring disajikan sebagai dua abstraksi: Fluks / Mono. Flux mengembalikan aliran objek, sementara Mono selalu mengembalikan satu objek.
Jürgen juga menyebutkan kemudahan menggunakan Java 8-style ketika bekerja dengan Spring 5.0 dan menjanjikan kandidat rilis Spring 5.1 pada Juli 2018 dan rilis pada bulan September, yang akan mendukung Java 11 dan bekerja pada fine tuning fitur Spring 5.0 yang baru.
Integrasi python / Java
Ada banyak laporan, dan memilih yang paling menarik di slot berikutnya itu sulit. Deskripsinya sama-sama menarik, jadi saya memercayai naluri saya dan memutuskan untuk mendengarkan Tamas Rozman, wakil presiden BlackRock dari Hongaria. Tetapi akan lebih baik jika saya mendengarkan lagi tentang Acara Sourcing dan CQRS. Dilihat oleh deskripsi, perusahaan bergerak dalam Ilmu Data untuk dana investasi besar. Tujuan dari laporan ini adalah untuk menunjukkan bagaimana mereka menciptakan sistem yang stabil dan dapat diskalakan, yang sama nyamannya bagi analis data dengan Python mereka, dan untuk pengembang Java dari sistem utama. Namun, bagi saya agak ragu bahwa sistem yang dibangun benar-benar nyaman. Untuk berteman dengan Python dan Java, para insinyur di BlackRock datang dengan ide memulai interpreter Python sebagai proses dari aplikasi Java. Mereka datang ke sini karena beberapa alasan:
- Jython (Python pada JVM) tidak cocok karena basis kode yang ketinggalan zaman 2.7 vs CPython 3.6.
- Mereka menganggap opsi untuk menulis ulang logika Ilmu Data di Jawa sebagai proses yang terlalu lama.
- Apache Spark memutuskan untuk tidak mengambilnya, karena, seperti yang dijelaskan oleh pembicara, Anda tidak dapat mencampur beban kerja yang ditulis dalam Java dan Python. Meskipun tidak jelas mengapa UDF dan UDFA tidak cocok [ 2 ]. Juga, Spark tidak cocok, karena mereka sudah memiliki semacam kerangka kerja, dan mereka tidak benar-benar ingin memperkenalkan yang baru. Dan, ternyata, mereka juga tidak memiliki Big Data, dan semua pemrosesan tergantung pada statistik pada file 100 MB yang menyedihkan.
Komunikasi dari Jawa dengan proses Python diatur menggunakan file yang dipetakan memori (satu file digunakan sebagai file data input) dan perintah (file kedua adalah output dari proses Python). Jadi, komunikasi adalah sesuatu dalam bentuk:
Java: calcExr | 1 + javaFunc (sqrt (36))
Python: 1 + javaFunct | 6
Java: 1 + sukses | 64
Python: sukses | 65
Masalah utama dari integrasi tersebut, Tamas disebut overhead selama serialisasi dan deserialisasi parameter input / output.

Java 10 App CDS
Setelah presentasi tentang seluk-beluk menjalankan Python, saya benar-benar ingin mendengarkan sesuatu yang sangat teknis dari dunia Java. Jadi saya pergi ke laporan oleh Volker Simonis, di mana dia berbicara tentang fitur berbagi data kelas Aplikasi dari
Java 10+ . Di dunia modern yang dibangun di atas layanan microser di Docker, kemampuan untuk berbagi Java Codecache dan Metaspace mempercepat peluncuran aplikasi dan menghemat memori. Gambar tersebut menunjukkan hasil peluncuran tomat dengan dok yang dibagikan / dibagikan bersama kelas Tomcat. Seperti yang Anda lihat, untuk proses kedua, beberapa halaman dalam memori sudah ditandai sebagai shared_clean - yang berarti bahwa saat ini dan setidaknya satu proses (tomcat berjalan kedua) merujuk kepada mereka.

Detail tentang cara bermain dengan CDS di OpenJDK 10 dapat ditemukan di:
App CDS . Selain membagi kelas aplikasi antara proses, di masa depan direncanakan untuk berbagi string diinternir di
JEP-250 .
Keterbatasan utama AppCDS:
Tidak bekerja dengan kelas hingga 1,5.
- Anda tidak dapat menggunakan kelas yang diambil dari file (hanya arsip .jar).
- Kelas yang dimodifikasi oleh classloader tidak dapat digunakan.
- Kelas yang dimuat oleh banyak kelas dapat digunakan kembali hanya sekali.
- Penulisan ulang kode byte tidak berfungsi, yang dapat menyebabkan penurunan kinerja hingga 2%. JDK-8074345

Pipa pemrosesan bahasa alami dengan Apache Spark
Laporan tentang NLP dan Apache Spark disampaikan oleh Vitaliy Kotlyarenko - insinyur dari Grammarly. Vitaliy menunjukkan bagaimana Grammarly prototipe NLP-Jobs di Apache Zeppelin. Contohnya adalah pembangunan pipa sederhana untuk pemodelan tematis berdasarkan algoritma
LDA dari arsip Internet
crawl umum . Hasil pemodelan topik digunakan untuk memfilter situs dengan konten yang tidak pantas sebagai contoh fungsi kontrol orang tua. Untuk membuat pipa, kami menggunakan skrip Terraform dan
AWS EMR Spark, yang memungkinkan Anda untuk menggunakan Spark Cluster dengan BENANG di Amazon. Secara skematis, pipa terlihat seperti ini:
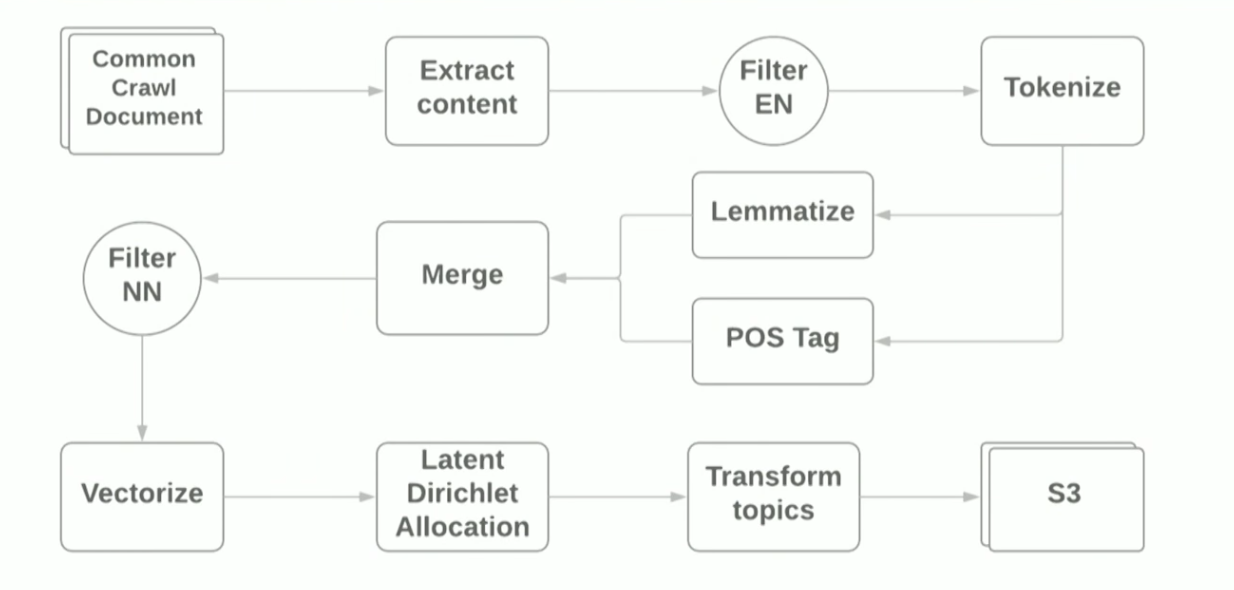
Tujuan dari laporan ini adalah untuk menunjukkan bahwa menggunakan kerangka kerja modern untuk membuat prototipe untuk tugas-ML cukup sederhana, namun, menggunakan perpustakaan standar, Anda masih mengalami kesulitan. Sebagai contoh:
- Pada langkah pertama membaca file WARC menggunakan pustaka HadoopInputFormat , IllegalStateExceptions kadang-kadang macet karena header file yang salah, perpustakaan harus ditulis ulang dan file yang salah dilewati.
- Ketergantungan pada jambu biji - perpustakaan definisi bahasa - berbenturan dengan dependensi yang diseret oleh Spark. Java 8 membantu, dengan bantuan yang memungkinkan untuk membuang ketergantungan pada jambu biji di perpustakaan yang digunakan.
Selama demo, kami memantau pelaksanaan pekerjaan menggunakan Spark standar UI dan subsistem pemantauan
Ganglia , yang secara otomatis tersedia ketika digunakan untuk AWS EMR. Penulis fokus pada peta panas Server Load Distribution, yang menunjukkan distribusi beban antara node dalam cluster, dan memberikan saran umum tentang mengoptimalkan pekerjaan Spark Job: meningkatkan jumlah partisi, mengoptimalkan serialisasi data, menganalisis log GC. Anda dapat membaca lebih lanjut tentang cara mengoptimalkan Spark Jobs di
sini . File sumber untuk demo dapat ditemukan di
github penulis laporan.
Graal, Truffle, SubstrateVM, dan fasilitas lainnya: apa saja itu dan mengapa Anda membutuhkannya
Yang paling dinantikan saya adalah laporan oleh Oleg Chirukhin dari JUG.ru. Dia memberi tahu cara mengoptimalkan kode jadi menggunakan Grail. Apa itu Cawan? Grail adalah merek
Oracle Labs , yang menggabungkan kompiler JIT (just-in-time), kerangka kerja untuk menulis bahasa DSL - Truffle - dan JVM (
SubstrateVM ) khusus - mesin virtual
dunia-tertutup universal yang dapat Anda tulis dalam JavaScript, Ruby, Python, Java, Scala. Laporan ini berfokus pada kompiler JIT dan pengujiannya dalam produksi.
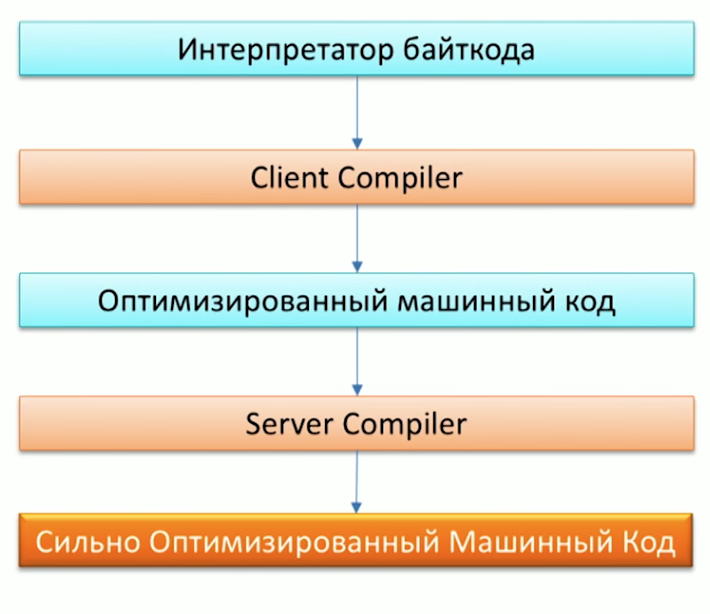
Pertama, ingat proses mengeksekusi kode oleh mesin Java dan perhatikan bahwa Java sudah memiliki dua kompiler: C1 (Client compiler) dan C2 (Server Compiler). Grail dapat digunakan sebagai kompiler C2.
Ketika ditanya mengapa kami membutuhkan kompiler lain, salah satu karyawan Oracle Labs, Dr. Chris Seaton, menjawab dengan sangat baik dalam artikel
Memahami Cara Kerja Graal . Singkatnya, ide asli proyek Graal, serta proyek
Metropolis , adalah untuk menulis ulang bagian dari kode JVM yang ditulis dalam C ++ di Jawa. Ini akan memungkinkan di masa depan untuk melengkapi kode dengan mudah. Sebagai contoh, salah satu optimasi - P
artial Escape Analysis - sudah ada di Grail, tetapi tidak di Hotspot -
karena memperluas kode Grail jauh lebih mudah daripada kode C2 .
Kedengarannya hebat, tetapi bagaimana ini akan bekerja dalam proyek saya, Anda bertanya? Grail cocok untuk proyek:
- Yang banyak mengotori, menciptakan banyak benda kecil.
- Ditulis dengan gaya Jawa 8, dengan banyak aliran dan lambda.
- Menggunakan berbagai bahasa: Ruby, Java, R.
Salah satu yang pertama dalam produksi, Grail mulai digunakan di Twitter. Anda dapat membaca lebih lanjut tentang ini dalam sebuah wawancara dengan Christian Talinger, yang diterbitkan di Habré (
interview_1 dan
interview_2 ). Di sana, ia menjelaskan bahwa dengan mengganti C2 dengan Graal, Twitter mulai menghemat sekitar 8% dari utilisasi CPU, yang cukup baik mengingat ukuran organisasi.
Pada konferensi tersebut, kami juga dapat memverifikasi kecepatan Graal dengan meluncurkan salah satu tolok ukur Scala di bawahnya -
Scala DaCapo . Sebagai hasilnya, pada Graal, benchmark dilewatkan dalam ~ 7000 ms, dan pada JVM reguler dalam ~ 14000 ms! Mengapa ini terjadi, Anda bisa melihat dengan melihat tes gclog. Jumlah kegagalan Alokasi saat menggunakan Graal secara signifikan kurang dari Hotspot. Namun, Anda masih tidak dapat mengatakan bahwa Grail akan menjadi solusi untuk masalah kinerja aplikasi Java Anda. Oleg juga menunjukkan kisah kegagalan dalam laporannya, membandingkan karya
Apache Ignite di bawah Grail dan tanpa itu - tidak ada perubahan kinerja yang nyata.

Merancang Layanan Kesalahan Toleransi
Laporan lain tentang arsitektur microservice gagal-aman dibaca oleh Orkhan Gasimov dari AppsFlyer. Dia memperkenalkan pola desain populer untuk membangun aplikasi terdistribusi. Kita mungkin mengenal banyak dari mereka, tetapi berjalan-jalan dan mengingat mereka masing-masing tidak akan menyakitkan sama sekali.
Masalah utama toleransi kesalahan layanan dengan mana pola yang dijelaskan dalam laporan dipanggil untuk melawan adalah: jaringan, beban puncak, mekanisme komunikasi antar layanan RPC.
Untuk memecahkan masalah dengan jaringan, ketika salah satu layanan tidak lagi tersedia, kita perlu kemampuan untuk segera menggantinya dengan yang lain yang sama. Dalam praktiknya, ini dapat dicapai dengan beberapa instance dari layanan yang sama dan deskripsi jalur alternatif untuk instance ini, yang merupakan pola
Penemuan Layanan . Terlibat dalam layanan
detak jantung dan mendaftarkan layanan baru akan menjadi contoh yang terpisah - Service Registry. Merupakan kebiasaan untuk menggunakan
Zookeeper atau
Konsul yang terkenal sebagai Registry Layanan. Yang, pada gilirannya, juga memiliki sifat terdistribusi dan dukungan untuk toleransi kesalahan.
Setelah menyelesaikan masalah dengan jaringan, kami beralih ke masalah beban puncak ketika beberapa layanan berada di bawah beban dan memproses permintaan jauh lebih lambat daripada mode biasa. Untuk mengatasinya, Anda dapat menggunakan pola
penskalaan otomatis . Dia tidak hanya akan mengambil tugas untuk secara otomatis mengubah skala layanan yang sangat banyak, tetapi juga menghentikan mesin virtual setelah periode beban puncak.
Bab terakhir dari laporan penulis adalah deskripsi tentang kemungkinan masalah komunikasi antarperusahaan RPC internal. Urahan memberikan perhatian khusus pada tesis "Pengguna tidak harus menunggu pesan kesalahan untuk waktu yang lama." Situasi seperti itu dapat muncul jika permintaannya diproses oleh rantai layanan dan masalahnya ada di akhir rantai: oleh karena itu, pengguna dapat menunggu permintaan diproses oleh masing-masing layanan dalam rantai dan hanya pada tahap terakhir yang menerima kesalahan. Yang terburuk, jika layanan akhir kelebihan beban, dan setelah menunggu lama, klien akan menerima HTTP-ERROR yang tidak berarti: 500.
Untuk mengatasi situasi seperti itu, Anda dapat menggunakan
Timeout , namun, permintaan yang masih dapat diproses dengan benar dapat masuk ke dalam timeout. Untuk melakukan ini, logika batas waktu bisa rumit dan nilai ambang batas khusus untuk jumlah kesalahan layanan per interval waktu dapat ditambahkan. Ketika jumlah kesalahan melebihi nilai ambang batas, kami memahami bahwa layanan ini sedang dimuat dan menganggapnya tidak tersedia, memberikannya waktu yang diperlukan untuk mengatasi tugas saat ini. Pendekatan ini menggambarkan pola
Circuit Breaker . Anda juga dapat menggunakan CircuitBreaker.html "> Circuit Beaker sebagai metrik tambahan untuk pemantauan, yang memungkinkan Anda untuk dengan cepat merespons kemungkinan masalah dan dengan jelas mengidentifikasi rantai layanan yang mengalaminya. Untuk melakukan ini, setiap panggilan layanan harus dibungkus dengan Circuit Breaker.
Juga dalam laporan tersebut, penulis mengingat pola
redundansi N-Modular , yang dirancang untuk "memproses permintaan lebih cepat jika mungkin," dan memberikan contoh yang indah tentang penggunaannya untuk memvalidasi alamat klien. Permintaan dalam sistem mereka melalui cache alamat segera dikirim ke beberapa penyedia Geo Map, yang karenanya respons tercepat dimenangkan.
Selain pola yang dijelaskan, berikut ini disebutkan:
- Pola Jalur Cepat , yang dapat diterapkan, misalnya, saat caching hasil kueri. Maka akses cache adalah jalur cepat.
- Pola Kernel Kesalahan - pola dari dunia Akka yang melibatkan pembagian tugas menjadi sub-tugas dan mendelegasikan sub-tugas ke aktor hilir. Dengan cara ini, fleksibilitas pemrosesan kesalahan eksekusi sub-tugas tercapai.
- Penyembuh Instance , yang mengasumsikan keberadaan layanan khusus - pengawas yang mengelola layanan lain dan menanggapi perubahan di negara mereka. Misalnya, jika terjadi kesalahan dalam layanan, pengawas dapat memulai kembali layanan masalah.

Clustered Event Sourcing dan CQRS dengan Akka dan Java
Laporan terakhir yang ingin saya tarik perhatian Anda dibacakan oleh salah satu penginjil dan arsitek Lightbend Hugh McKee. Lightbend (sebelumnya Typesafe) adalah sesuatu seperti Oracle, tetapi untuk bahasa Scala. Perusahaan juga aktif mengembangkan kerangka kerja
Akka.io. Dalam sebuah laporan, Hugh berbicara tentang implementasi pendekatan
CQRS (Command Query Responsibility Commands / SEGREGATION) yang populer pada kerangka Akka. Secara skematis, arsitektur sistem CQRS terlihat seperti ini:
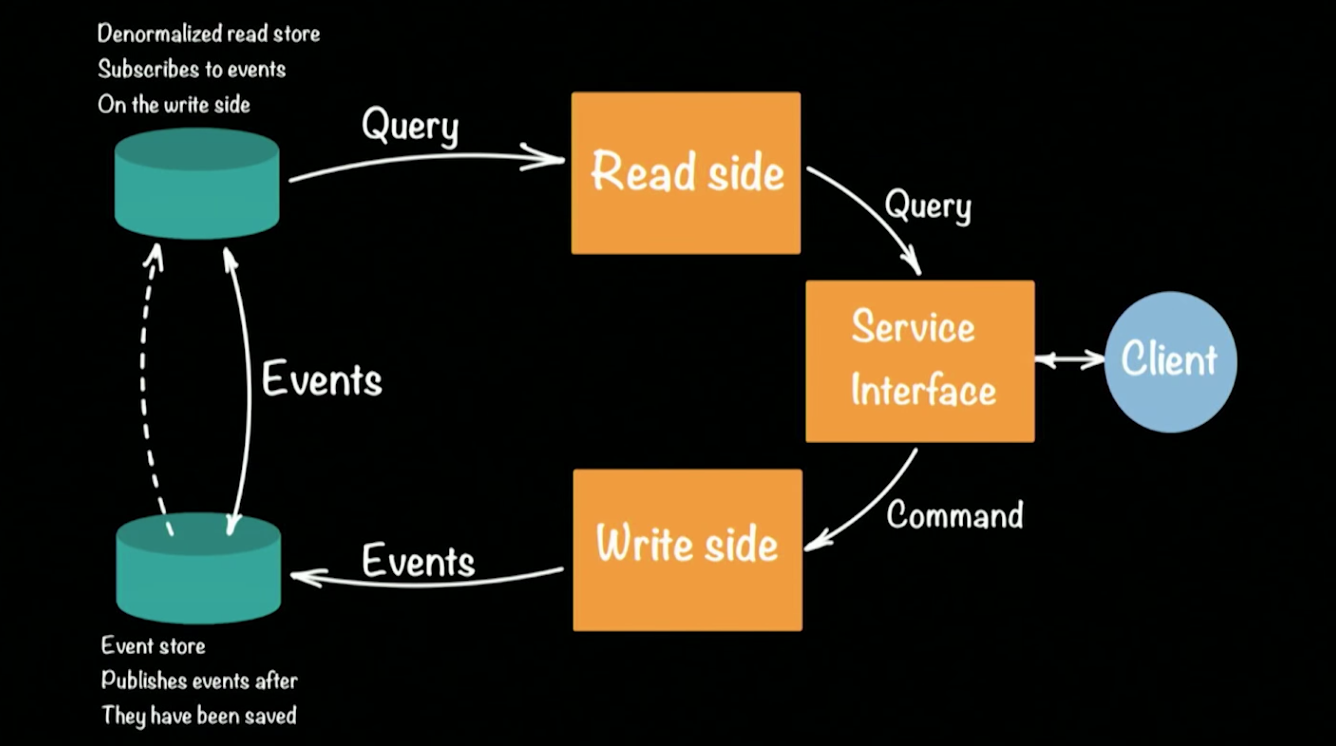
Hugh mengambil prototipe bank sebagai contoh sistem kerja. Klien dalam arsitektur CQRS melakukan dua operasi: permintaan, perintah. Setiap tim (misalnya, transaksi bank yang mentransfer uang dari satu akun ke akun lain) menghasilkan acara (faitertai) yang akan dicatat di EventStore (misalnya: Cassandra). Agregasi rantai (menyetor uang ke dalam akun, transfer dari akun ke akun, menarik di ATM) dari peristiwa membentuk keadaan klien saat ini, saldo uangnya di akun. Permintaan untuk keadaan saat ini pergi ke repositori yang terpisah, snapshot dari repositori acara, karena tidak masuk akal untuk menyimpan riwayat lengkap rekening bank. Cukup untuk memperbarui status yang dilemparkan secara berkala untuk setiap pengguna.
Pendekatan ini memungkinkan untuk pulih secara otomatis ketika kesalahan terjadi: untuk ini kita perlu mendapatkan peran terakhir dari status pengguna dan menerapkan semua peristiwa yang terjadi sebelum kesalahan terjadi. Karena adanya dua penyimpanan, arsitektur CQRS mentoleransi beban puncak yang muncul (paku) dengan baik. Sejumlah besar acara akan memuat Toko Acara, tetapi tidak akan memengaruhi Read Store, dan pengguna masih dapat memenuhi kueri ke database.
Mari kita kembali ke prototipe sistem perbankan pada Akka dan CQRS. Setiap klien bank / akun / tim yang memungkinkan dalam sistem akan diwakili oleh satu (!)
Aktor . Sebuah bank besar dapat mendukung ratusan ribu akun, dan ini tidak akan menjadi masalah bagi Akka. Kerangka out-of-the-box mendukung pengelompokan dan dapat dijalankan pada ratusan JVM. Jika salah satu mesin di cluster gagal, Akka menyediakan mekanisme khusus yang secara otomatis menanggapi situasi seperti itu: dalam kasus kami, aktor klien dapat diciptakan kembali pada mesin yang tersedia di cluster, dan statusnya akan dibaca kembali dari repositori.
Utas terpisah tidak dibuat untuk aktor - ini memungkinkan untuk mendukung puluhan ribu aktor dalam JVM tunggal. Pada saat yang sama, aktor menjamin bahwa setiap permintaan akan diproses secara terpisah (!) Dalam urutan penerimaan permintaan. Jaminan ini secara otomatis menghilangkan kemungkinan kondisi balapan saat memproses permintaan. Anda dapat memahami prototipe sistem secara lebih rinci dengan membuka kodenya menggunakan tautan di GitHub. Setiap sub proyek menunjukkan implementasi tahap paling kompleks dalam membangun prototipe:
tawon.
Catatan semua laporan akan muncul online dalam beberapa minggu. Saya harap artikel ini akan membantu Anda menentukan urutan tontonan, terutama karena saya pikir layak menonton pertunjukan.