DBMS yang dikolomasikan secara aktif dikembangkan dalam nol tahun, saat ini mereka telah menemukan niche mereka dan secara praktis tidak bersaing dengan sistem huruf kecil tradisional. Di bawah potongan, penulis memahami apakah solusi universal itu mungkin dan seberapa praktisnya.
"Ada kemajuan dalam segala hal ... jangan takut bahwa mereka akan memanggil Anda ke kantor dan berkata:" Kami berkonsultasi di sini, dan besok Anda akan dipotong atau dibakar atas pilihan Anda sendiri. "Itu akan menjadi pilihan yang sulit. Saya pikir dia akan bingung oleh banyak dari kita. "
Yaroslav Hasek. Petualangan prajurit pemberani Schweik.
Latar belakang
Berapa banyak database yang ada, begitu banyak konfrontasi ideologis ini. Karena penasaran, penulis menemukan sebuah buku karya J. Martin dari IBM [1] di nampan pada tahun 1975 dan segera menemukan kata-kata (p. 183): “Hubungan biner digunakan dalam karya [...], mis. hubungan hanya dua domain. Diketahui bahwa hubungan biner memberikan fleksibilitas terbesar ke pangkalan. Namun, dalam tugas-tugas komersial, hubungan dari berbagai tingkatan sangat nyaman. ” Hubungan dipahami di sini sebagai hubungan relasional. Dan karya-karya yang disebutkan tertanggal 1967 ... 1970.
Biarkan Sybase IQ adalah kolom DBMS industri pertama yang digunakan, tetapi setidaknya pada tingkat ide, semuanya diucapkan 25 tahun sebelumnya.
Saat ini, DBMS berikut ini didukung dalam kolom atau sedikit banyak (ini terutama diambil di
sini ):
Komersial
Sumber gratis & terbuka
Perbedaan
Relasional relasional adalah kumpulan tupel, pada dasarnya tabel dua dimensi. Oleh karena itu, ada dua opsi penyimpanan - baris-bijaksana atau kolom-bijaksana. Pemisahan agak buatan, logis. Pengembang basis data telah lama berhenti merencanakan
drum dan melacak catatan. Ini adalah tugas administrator DBMS untuk secara optimal menguraikan data DBMS ke dalam sistem file, tetapi bagaimana sistem file mengatur data pada disk fisik diketahui terutama untuk pengembang sistem file.
Adalah logis untuk membiarkan DBMS memutuskan untuk menyimpan data. Di sini kita berbicara tentang beberapa DBMS hipotetis yang mendukung kedua opsi untuk mengatur penyimpanan data dan memiliki kemampuan untuk menetapkan tabel ke salah satu dari mereka. Kami tidak mempertimbangkan opsi yang cukup populer untuk mendukung dua basis data - satu untuk pekerjaan, yang kedua untuk analitik / laporan. Serta kolom indeks ala Microsoft SQL Server. Bukan karena itu buruk, tetapi untuk menguji hipotesis bahwa ada beberapa cara yang lebih elegan.
Sayangnya, tidak ada DBMS hipotetis yang dapat memilih cara terbaik untuk menyimpan data. Karena tidak memiliki pemahaman tentang bagaimana kami akan menggunakan data ini. Dan tanpa ini, tidak mungkin untuk membuat pilihan, meskipun itu sangat penting.
Kualitas DBMS yang paling berharga adalah kemampuan untuk dengan cepat memproses data (dan persyaratan
ACID , tentu saja). Kecepatan DBMS terutama ditentukan oleh jumlah operasi disk. Dua kasus ekstrem muncul dari ini:
- Data cepat diubah / ditambahkan, Anda harus punya waktu untuk menulis. Solusi yang jelas - garis (tuple), jika mungkin, terletak di satu halaman, itu tidak dapat dilakukan lebih cepat.
- Perubahan data sangat jarang atau tidak berubah sama sekali, kami membaca data berkali-kali, dan hanya sejumlah kecil kolom yang terlibat dalam satu waktu. Dalam situasi ini, logis untuk menggunakan varian penyimpanan kolom-bijaksana, maka ketika membaca jumlah halaman minimum yang mungkin akan naik.
Tetapi ini adalah kasus-kasus ekstrem, dalam kehidupan semuanya tidak begitu jelas.
- Jika Anda ingin membaca seluruh tabel, maka dari sudut pandang jumlah halaman, data tidak penting baris demi baris atau dalam kolom. Yaitu ada beberapa perbedaan, tentu saja, dalam versi kolom-bijaksana kami memiliki kemampuan untuk kompres informasi yang lebih baik, tetapi saat ini ini tidak penting.
- Namun dalam hal kinerja, ada perbedaan karena dengan perekaman baris demi baris, pembacaan dari disk akan terjadi lebih linier. Semakin sedikit hard drive yang maju, terasa semakin cepat dibaca. Pembacaan file yang lebih mudah diprediksi selama perekaman baris demi baris memungkinkan sistem operasi (OS) menggunakan cache disk lebih efisien. Ini penting bahkan untuk drive SSD, karena memuat dengan asumsi ( baca terus ) sering kali membawa kesuksesan.
- Pembaruan tidak selalu mengubah seluruh catatan. Misalkan kasus umum adalah perubahan dalam dua kolom. Maka akan lebih baik jika data kolom ini akan ada di satu halaman, karena Anda hanya perlu satu halaman mengunci per record, bukan dua. Di sisi lain, jika data tersebar di halaman, ini memungkinkan transaksi yang berbeda untuk mengubah data satu baris tanpa konflik.
Ini dia lihat lebih dekat. Pilihan hipotetis adalah membuat tabel menjadi huruf kecil atau berbentuk kolom, DBMS harus dibuat pada saat penciptaannya. Tetapi untuk membuat pilihan ini akan menyenangkan untuk mengetahui, misalnya, bagaimana kita akan mengubah tabel ini. Mungkin Anda harus melempar koin?
- Misalkan kita menggunakan struktur pohon (mis: indeks berkerumun) untuk penyimpanan. Dalam hal ini, menambahkan data atau bahkan mengubahnya dapat menyebabkan penyeimbangan kembali pohon atau bagiannya. Di penyimpanan baris, ada (setidaknya satu) kunci tulis, yang dapat memengaruhi sebagian besar tabel. Dalam versi kolom, cerita-cerita seperti itu terjadi jauh lebih sering, tetapi tidak terlalu merusak hanya memperhatikan kolom tertentu.
- Pertimbangkan pemfilteran menurut indeks. Misalkan sampel cukup jarang. Maka rekaman baris demi baris memiliki preferensi, karena dalam hal ini rasio informasi yang berguna untuk dibaca bagi perusahaan lebih baik.
- Jika penyaringan memberikan aliran yang lebih padat dan hanya sebagian kecil dari kolom yang dibutuhkan, versi kolom-bijaksana menjadi lebih murah. Di mana kesenjangan antara kasus-kasus ini, bagaimana cara menentukannya?
Dengan kata lain, dalam keadaan apa pun DBMS hipotetis kami tidak akan bertanggung jawab memilih antara opsi penyimpanan baris demi baris dan berdasarkan kolom, ini harus dilakukan oleh perancang basis data.
Namun, mengingat hal di atas, perancang basis data juga akan berada dalam pilihan yang sangat sulit. Dia akan membingungkan banyak dari kita.
Bagaimana jika
Intinya, baik varian kolom-bijaksana dan garis-bijaksana - kasus ekstrim dari satu ide - memotong tabel menjadi "pita" dan menyimpan data baris demi baris di dalam setiap rekaman. Hanya dalam satu kasus pita itu adalah satu, di sisi lain pita itu merosot menjadi satu kolom.
Jadi mengapa tidak mengizinkan opsi perantara - jika data dari beberapa kolom datang / baca bersama, bahkan jika mereka berada di rekaman yang sama. Dan jika tidak ada data (NULL) dalam rekaman itu, maka tidak ada yang perlu disimpan. Pada saat yang sama, masalah ukuran baris maksimum dihapus - Anda dapat membagi tabel ketika ada risiko bahwa baris tidak akan muat pada satu halaman.
Gagasan ini tidak begitu orisinal, penulis berkesempatan melihat hal yang sama dan menerapkannya sendiri. Elemen kebaruan adalah untuk memungkinkan perancang basis data untuk menentukan bagaimana tabelnya akan dibagi menjadi beberapa bagian dan dalam bentuk apa data akan masuk ke disk.
Kami melakukannya untuk diri sendiri sebagai berikut:
- saat membuat tabel, informasi tentang preferensi kami diteruskan ke prosesor SQL menggunakan pragma
- awalnya, saat membuat tabel, diasumsikan bahwa seluruh baris akan terletak pada satu halaman B-tree
- namun, Anda dapat menggunakan - - #pragma page_break
untuk memberi tahu prosesor SQL bahwa kolom berikut akan ditempatkan di halaman lain (di pohon lain) - penggunaan - - #pragma column_based
memungkinkan kita untuk secara singkat mengatakan bahwa kolom yang melangkah lebih jauh masing-masing terletak di pohonnya sendiri - - - #pragma row_based
batalkan aksi berbasis kolom - dengan demikian, tabel terdiri dari satu atau lebih pohon-B, elemen kunci pertama yang merupakan bidang IDENTITAS tersembunyi. Diyakini bahwa urutan di mana catatan dibuat (mungkin berkorelasi dengan urutan di mana catatan dibaca) juga penting dan tidak boleh diabaikan. Kunci utama adalah pohon yang terpisah, namun ini tidak berlaku untuk topik.
Bagaimana ini bisa terlihat dalam praktek?
Misalnya, seperti ini:
CREATE TABLE twomass_psc ( ra double precision, decl double precision, …
Sebagai contoh, tabel utama atlas
2MASS diambil, legenda di
sini dan di
sini .
J ,
H ,
K - sub-band inframerah, masuk akal untuk menyimpan data pada mereka bersama-sama, karena dalam penelitian mereka diproses bersama. Di sini,
misalnya :
Gambar pertama yang muncul.
Atau di
sini , bahkan lebih indah:
Sudah waktunya untuk mengkonfirmasi bahwa ini masuk akal praktis.
Hasil
Di bawah ini disajikan:
- diagram fase (nomor-X dari halaman yang direkam, nomor-Y dari yang terakhir direkam sebelumnya) dari prosedur untuk menulis halaman (angka-angka logis) ke disk ketika membuat tabel dalam dua versi
- dalam sebuah kolom, itu ditunjuk oleh_1
- dan untuk tabel yang dipotong menjadi 16 kolom, itu ditunjuk sebagai by_16
- total kolom 181

Mari kita lihat lebih dekat bagaimana cara kerjanya:
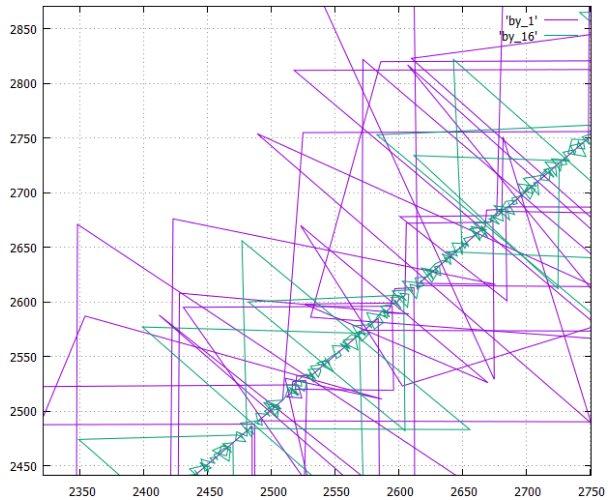
- Opsi by_16 terasa lebih kompak, yang logis, yang paling - opsi garis hanya akan memberikan garis lurus (dengan outlier).
- Pencilan segitiga - merekam halaman perantara B-tree.
- Catatan data ditampilkan, jelas, bacaan akan terlihat seperti ini.
- Dikatakan di atas bahwa semua opsi merekam jumlah informasi yang sama dan aliran yang perlu dikurangi kira-kira sama (± efisiensi kompresi).
Tetapi di sini sangat jelas ditunjukkan bahwa dalam versi kolom-bijaksana pohon-pohon tumbuh dengan kecepatan yang berbeda karena spesifikasi data (dalam satu kolom mereka sering mengulangi dan mengompres dengan sangat baik, di kolom lain - suara dari sudut pandang kompresor). Akibatnya, beberapa pohon berjalan di depan, yang lain terlambat, ketika membaca, kita secara objektif mendapatkan mode membaca "sobek" yang sangat tidak menyenangkan untuk sistem file. - Jadi, by_16 jauh lebih disukai untuk membaca daripada kolom-bijaksana, hampir sama nyamannya dengan garis-bijaksana.
- Tetapi pada saat yang sama, varian by_16 memiliki kelebihan utama dari varian kolom-bijaksana dalam hal ketika sejumlah kecil kolom diperlukan. Terutama jika Anda tidak membagi meja secara mekanik untuk 16 buah, tetapi bermakna, setelah menganalisis probabilitas penggunaan bersama mereka.
Sumber
[1] J. Martin. Organisasi basis data dalam sistem komputasi. Dunia, 1978
[2]
Indeks kolom, fitur penggunaan[3] Daniel J. Abadi, Samuel Madden, Nabil Hachem.
ColumnStores vs. RowStores: Seberapa Bedanya Mereka? , Prosiding Konferensi Internasional ACM SIGMOD tentang Pengelolaan Data, Vancouver, BC, Kanada, Juni 2008
[4] Michael Stonebraker, Uğur Çetintemel.
“One Size Fits All”: Sebuah Ide yang Tiba Saatnya dan Hilang , 2005