 Level Permainan Revenge Atari Montezuma
Level Permainan Revenge Atari MontezumaDeepMind
menunjukkan proses belajar AI (bentuk lemah) untuk melewati game di Atari. Pelatihan dilakukan dengan mendemonstrasikan sistem passing video game dari YouTube. Metode ini digunakan oleh banyak pemain manusia yang, karena satu dan lain alasan, tidak bisa melewati beberapa jenis permainan.
Biasanya, untuk mengatasi masalah ini, perlu menggunakan apa yang disebut metode
pembelajaran penguatan . Teknik ini cukup populer, karena memungkinkan Anda untuk melatih bot untuk melakukan berbagai tugas tertentu. Segera setelah sistem mencapai hasil apa pun, ia menerima hadiah kecil.
Pengembang membuat algoritma dan model yang dapat mengevaluasi lingkungan permainan, termasuk kemungkinan hadiah untuk penyelesaian (poin, bonus, dll.). Sistem semacam itu mempelajari permainan langkah demi langkah, secara bertahap bergerak ke final.
Metode baru yang dikembangkan di DeepMind berbeda dari yang lainnya. Spesialis perusahaan mampu melatih AI untuk bermain game di bawah Atari seperti Montezuma's Revenge, Pitfall dan Private Eye. Pada saat yang sama, penekanan pada poin dan hadiah tidak dilakukan - pelatihan berlanjut dengan tutorial dari YouTube. Dan ini memungkinkan kami untuk mencapai hasil yang tidak biasa untuk AI.
Faktanya adalah bahwa game seperti Revenge Montezuma yang sama sulit untuk mesin untuk "mengerti". Tidak ada tugas yang jelas, tidak jelas ke mana harus pergi, barang apa yang harus dikumpulkan dan apa yang harus dilakukan dengan mereka di masa depan. Mesin hilang begitu saja, karena dalam proses promosi tidak menerima hadiah dan pelatihan dengan bala bantuan di sini menjadi tidak berguna atau hampir tidak berguna.
Dalam game yang dimaksud, Anda perlu mengontrol karakter bernama Panama Joe. Pada akhirnya, ia harus pergi ke perbendaharaan di kuil lama. Menurut legenda, harta ini milik Montezuma. Pertama, Anda perlu menemukan item penting pertama untuk melewati permainan - kunci emas. Untuk mendeteksinya, Anda harus melalui sekitar 100 langkah. Tetapi ini jika Anda tahu apa yang harus dilakukan. Jika tidak, ada sejumlah besar kemungkinan 100 dari
18 tindakan awal. Ini terlalu banyak untuk AI apa pun yang diciptakan oleh manusia. Nah, Anda tidak akan mendapatkan hadiah di sini, semuanya sangat, sangat spesifik.
Salah satu cara untuk memberi tahu komputer apa yang harus dilakukan adalah dengan menunjukkan skenario bagian ini. Sebenarnya, tidak hanya mobil, tetapi juga orang belajar melakukan berbagai tugas dengan contoh. Menari, tindakan artis, menyolder - semua ini paling baik dilihat 1 kali, dan tidak 100 kali mendengar bagaimana melakukannya.
DeepMind sampai pada kesimpulan bahwa ini adalah cara terbaik untuk menunjukkan kepada komputer bagaimana menyelesaikan tugas dengan hasil yang tersirat. Teknologi yang diciptakan oleh para ahli sangat membantu. Dua metode yang digunakan untuk mengajar contoh: TDC (klasifikasi jarak temporal) dan CDC (cross-modal temporal distance distance).
Dalam kasus pertama, AI dilatih untuk menentukan jarak di lingkungan game, untuk melihat perbedaan antara dua frame yang berbeda. AI juga “memahami” apa yang perlu dilakukan untuk berpindah dari satu tempat ke tempat lain. Untuk pelatihan di YouTube, video dialokasikan pasangan bingkai dalam urutan acak.
Dalam kasus kedua, "pemahaman" iringan suara juga ditambahkan. Suara di hampir semua game sesuai dengan kinerja tindakan tertentu. Misalnya, melompat, mendapatkan barang, dll. Dengan demikian, komputer dilatih untuk memahami suara sebagai elemen permainan yang penting. Video + sound memungkinkan komputer melakukan cukup baik dalam proses melewati permainan.
Berikut adalah tindakan AI terlatih dalam Pembalasan Montezuma. Bagian dari dua game lain yang disebutkan di awal ada di
sini .
Benar, itu tidak mungkin untuk sepenuhnya meninggalkan peran hadiah - sampai sekarang, AI tergantung pada poin yang sama. Tetapi metode pengajaran sistem yang biasa, yang digunakan sebelumnya, tidak memungkinkan untuk mendapatkan setidaknya kunci emas, yang diberikan seratus poin pertama. Jadi AI, seperti anak kucing buta, menyodok ke segala arah, tidak mengerti apa yang harus dilakukan. Benar, sistem "penguatan" juga dimodifikasi.
Dalam proses melewati setiap frame video ke-16 dari catatan kelulusan game AI, itu dibandingkan dengan frame video yang melewati game oleh orang-orang. Jika perbandingan menunjukkan tingkat kesamaan yang tinggi, maka AI menerima hadiah. Seiring waktu, AI mulai melakukan urutan tindakan yang sama dengan seseorang, untuk mendapatkan kerangka yang sama.
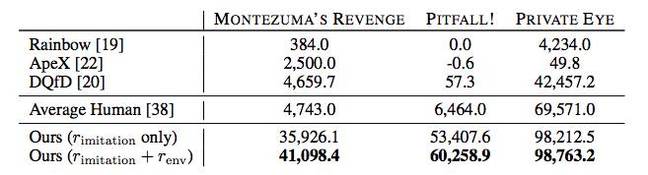
Selain itu, AI dalam banyak kasus menunjukkan hasil yang lebih baik daripada pemain manusia atau algoritma passing lainnya, termasuk Rainbow, ApeX, dan DQfD.
Pada prinsipnya, semua ini mengesankan, tetapi sejauh ini manfaat praktis dari pencapaian DeepMind tidak jelas. Apakah mungkin untuk menggunakan metode pengajaran AI yang diusulkan oleh perusahaan di mana saja selain melewati game lama? Tetapi mengetahui pencapaian DeepMind di bidang AI, tidak ada keraguan bahwa dalam satu atau lain cara semua ini dapat digunakan untuk tujuan praktis - tidak mungkin bahwa para ahli akan mulai bekerja pada masalah ini demi "kesenangan."