Blog ini biasanya didedikasikan untuk pengenalan plat nomor. Namun, saat mengerjakan tugas ini, kami sampai pada solusi menarik yang dapat dengan mudah diterapkan pada berbagai tugas penglihatan komputer. Kami akan membicarakan ini sekarang: bagaimana membuat sistem pengakuan yang tidak akan mengecewakan Anda. Dan jika Anda gagal, Anda bisa memberi tahu dia di mana kesalahannya, melatih kembali dan memiliki solusi yang sedikit lebih andal dari sebelumnya. Selamat datang di kucing!

Apa yang terjadi
Bayangkan, Anda menghadapi tugas: mencari pizza di foto dan menentukan jenis pizza itu.
Mari kita lewati jalur standar yang sering kita lalui. Mengapa Untuk memahami bagaimana melakukan ... tidak perlu.
Langkah 1: ambil pangkalan
 Langkah 2:
Langkah 2: untuk keandalan pengakuan, dapat dicatat bahwa ada pizza dan apa latar belakangnya (jadi kami akan menyertakan jaringan saraf segmentasi dalam prosedur pengakuan, tetapi seringkali sepadan):
 Langkah 3:
Langkah 3: kami membawanya ke "bentuk dinormalisasi" dan mengklasifikasikan menggunakan jaringan saraf convolutional lain:

Hebat! Sekarang kami memiliki basis pelatihan. Rata-rata, ukuran pangkalan pelatihan bisa beberapa ribu gambar.
Kami mengambil 2 jaringan konvolusi, misalnya, Unet dan VGG. Yang pertama dilatih pada gambar input, kemudian kita menormalkan gambar dan melatih VGG untuk klasifikasi. Ini berfungsi dengan baik, kami mentransfernya ke pelanggan dan mempertimbangkan uang yang diperoleh dengan jujur.
Itu tidak bekerja seperti itu!
Sayangnya, hampir tidak pernah. Ada beberapa masalah serius yang muncul selama implementasi:
- Variabilitas input data. Kami mempelajari satu contoh, pada kenyataannya, semuanya ternyata berbeda. Ya, hanya selama operasi, ada yang salah.
- Sangat sering, akurasi pengenalan tetap tidak memadai. Saya ingin 99,5%, tetapi naik dari 60% menjadi 90% di hari yang baik. Tetapi mereka ingin, secara otomatis, mengotomatisasi solusi yang berfungsi dengan baik, dan bahkan lebih baik daripada orang!
- Tugas-tugas semacam itu sering kali diserahkan kepada pihak luar, yang berarti bahwa kontrak sudah ditutup, tindakannya ditandatangani dan pemilik bisnis harus memutuskan apakah akan berinvestasi dalam revisi atau mengabaikan keputusan sama sekali.
- Ya, itu hanya mulai menurun seiring waktu, seperti dalam sistem yang kompleks, jika Anda tidak melibatkan spesialis yang berpartisipasi dalam penciptaan, atau tingkat kualifikasi yang sama.
Akibatnya, bagi banyak orang yang telah menyentuh semua mekanik ini dengan tangan mereka, menjadi jelas bahwa segala sesuatu harus terjadi dengan cara yang sama sekali berbeda. Sesuatu seperti ini:
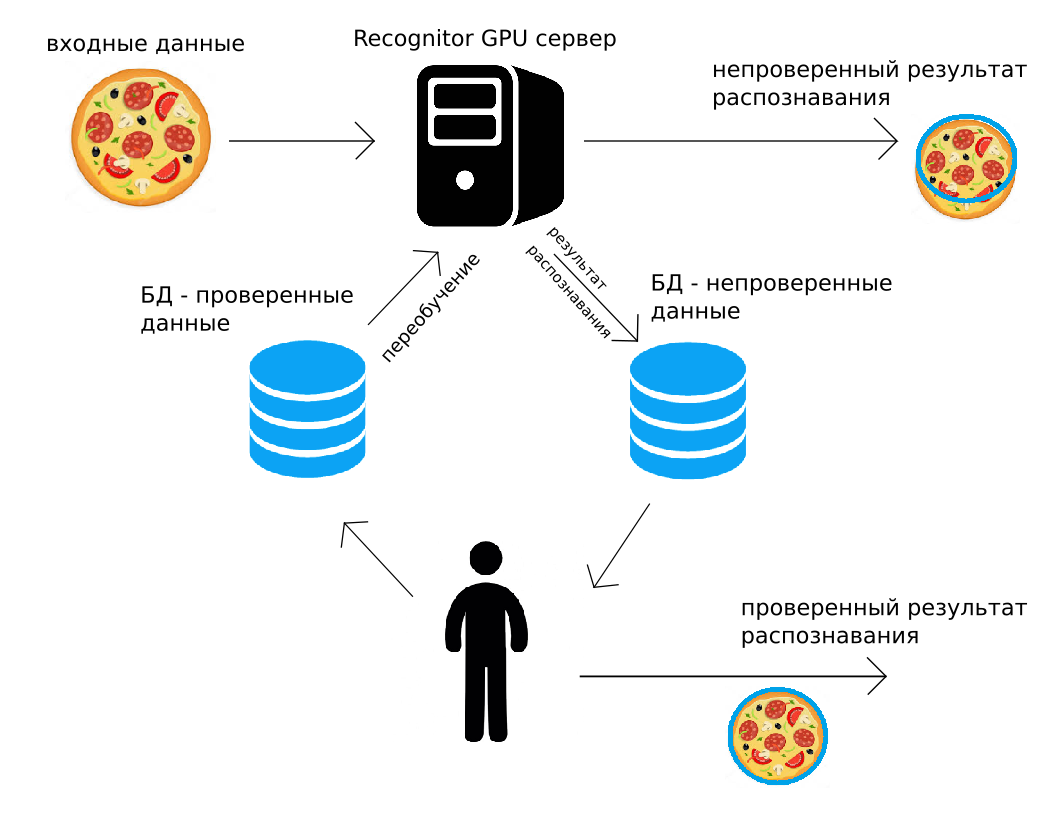
Data dikirim ke server kami (melalui http POST, atau menggunakan API Python), server GPU akan mengenalinya "sebagaimana mestinya", segera mengembalikan hasilnya. Sepanjang jalan, hasil pengenalan yang sama bersama dengan gambar ditambahkan ke arsip. Seseorang kemudian mengendalikan semua data atau bagian acak darinya, memperbaikinya. Hasil yang diperbaiki dimasukkan ke arsip kedua. Dan kemudian, ketika akan mudah untuk melakukan ini (misalnya, pada malam hari), semua jaringan saraf convolutional yang digunakan untuk pengakuan akan dilatih ulang, menggunakan data yang dikoreksi orang tersebut.
Sirkuit pengenalan, pengawasan manusia, dan pelatihan lanjutan seperti itu memecahkan banyak masalah yang disebutkan di atas. Selain itu, dalam solusi yang membutuhkan akurasi tinggi, output yang diverifikasi manusia dapat digunakan. Tampaknya penggunaan data yang diverifikasi manusia ini terlalu mahal, tetapi lebih jauh kami akan menunjukkan bahwa itu hampir selalu masuk akal secara ekonomi.
Contoh nyata
Kami telah menerapkan prinsip yang dijelaskan dan berhasil menerapkannya pada beberapa tugas nyata. Salah satunya adalah pengakuan angka pada gambar kontainer di terminal kereta api yang diambil dari tablet. Cukup mudah - arahkan tablet ke wadah, dapatkan nomor yang dikenal dan operasikan dengan itu di program tablet.
Contoh potret umum:

Pada gambar, jumlahnya hampir sempurna, hanya banyak noise visual. Tapi bayangan yang keras, salju, tata letak huruf yang tidak terduga, kemiringan atau perspektif serius terjadi saat memotret.
Dan sepertinya itu adalah sekumpulan halaman web tempat semua "keajaiban" terjadi:
1) Mengunggah file ke server (tentu saja, ini bisa dilakukan bukan dari halaman html, tetapi menggunakan Python atau bahasa pemrograman lainnya):
2) Server mengembalikan hasil pengenalan:
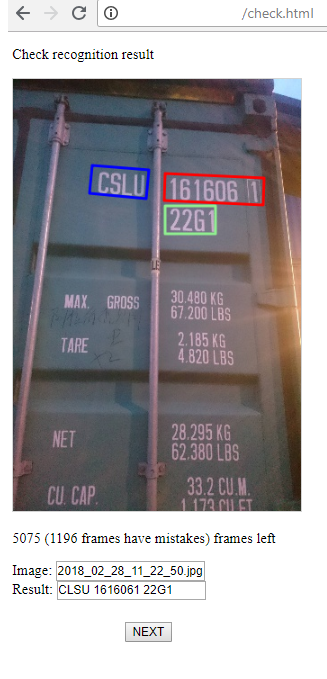
3) Dan ini adalah halaman untuk operator yang memantau keberhasilan pengakuan dan, jika perlu, mengoreksi hasilnya. Ada 2 tahap: pencarian area kelompok simbol, pengakuannya. Operator dapat memperbaiki semua ini jika ia melihat kesalahan.
4) Berikut ini adalah halaman sederhana di mana Anda dapat memulai pelatihan untuk setiap tahap pengenalan, dan, dengan berlari, lihat kehilangan saat ini.
Minimalis yang keras, tetapi berhasil dengan baik!
Bagaimana ini terlihat dari sisi perusahaan yang berencana menggunakan pendekatan yang dijelaskan (atau server pengalaman dan Pengenal kami)?
- Jaringan saraf canggih dipilih. Jika semuanya didasarkan pada solusi debug yang ada, maka Anda dapat memulai server dan mengkonfigurasi markup dalam seminggu.
- Aliran data (lebih disukai tanpa akhir) diatur pada server, beberapa ratus frame ditandai.
- Pelatihan dimulai. Jika semuanya "cocok", maka hasilnya adalah 60-70% pengakuan sukses, yang sangat membantu dalam penandaan lebih lanjut.
- Kemudian mulailah pekerjaan sistematis menyajikan semua situasi yang mungkin, memeriksa hasil pengakuan, mengedit, melatih kembali. Ketika Anda belajar, menanamkan sistem dalam proses bisnis menjadi lebih dan lebih hemat biaya.
Siapa lagi yang melakukan ini?
Tema loop tertutup bukanlah hal baru. Banyak perusahaan menawarkan sistem pemrosesan data dari satu jenis atau lainnya. Tetapi paradigma kerja dapat dibangun dengan cara yang sangat berbeda:
- Nvidia Digit adalah beberapa model yang cukup bagus dan kuat yang dibungkus dengan GUI intuitif di mana pengguna perlu melampirkan gambar dan JSON mereka. Plus utama - pengetahuan minimum pemrograman dan administrasi memberi Anda solusi yang baik. Minus - solusi ini bisa jauh dari optimal (misalnya, tidak mungkin untuk mencari nomor mobil melalui SSD dengan baik). Dan untuk memahami bagaimana mengoptimalkan solusi, pengguna tidak memiliki pengetahuan yang cukup. Jika dia memiliki pengetahuan yang cukup, dia tidak membutuhkan DIGIT. Minus kedua - Anda harus memiliki peralatan Anda sendiri untuk mengkonfigurasi dan menggunakan semuanya.
- Layanan markup seperti Mechanical Turk, Toloka, Supervise.ly. Dua yang pertama memberi Anda alat markup, serta orang-orang yang dapat menandai data. Yang terakhir ini menyediakan alat yang hebat, tetapi tanpa orang. Melalui layanan, Anda dapat mengotomatisasi kerja manusia, tetapi Anda harus menjadi ahli dalam mengatur tugas.
- Perusahaan yang sudah dilatih dan memberikan solusi tetap (Microsoft, Google, Amazon). Baca lebih lanjut tentang mereka di sini (https://habr.com/post/312714/). Keputusan mereka tidak fleksibel, tidak selalu "di bawah tudung" akan menjadi keputusan terbaik yang diperlukan dalam kasus Anda. Secara umum, hampir selalu tidak membantu.
- Perusahaan yang bekerja secara khusus dengan data Anda, misalnya ScaleAPI (https://www.scaleapi.com/). Mereka memiliki API yang bagus, bagi pelanggan itu akan menjadi kotak hitam. Input data - hasil keluaran. Sangat mungkin bahwa di dalam ada semua solusi otomatisasi terbaik, tetapi itu tidak masalah bagi Anda. Solusi yang cukup mahal dalam satu bingkai, tetapi jika data Anda benar-benar berharga - mengapa tidak?
- Perusahaan yang memiliki alat untuk melakukan siklus hampir lengkap dengan tangan mereka sendiri. Misalnya, PowerAI dari IBM . Ini hampir seperti DIGIT, tetapi Anda hanya perlu menandai set data. Plus, tidak ada yang mengoptimalkan jaringan dan solusi saraf. Tetapi banyak kasus telah diselesaikan. Model jaringan saraf yang dihasilkan digunakan untuk Anda dan akan diberikan akses http. Ada kelemahan yang sama di sini seperti di Digit - Anda perlu memahami apa yang harus dilakukan. Ini adalah kasus Anda yang mungkin "tidak bertemu" atau hanya membutuhkan pendekatan yang tidak biasa untuk pengakuan. Secara umum, solusinya sempurna jika Anda memiliki tugas yang cukup standar, dengan objek yang dapat dipisahkan dengan baik yang perlu diklasifikasikan.
- Perusahaan yang memecahkan masalah Anda dengan alat mereka. Tidak banyak perusahaan seperti itu. Pada kenyataannya, saya hanya akan merujuk CrowdFlower kepada mereka. Di sini untuk uang yang masuk akal mereka akan menempatkan pencakar langit, mengalokasikan manajer, menyebarkan server mereka, di mana model Anda akan diluncurkan. Dan untuk uang yang lebih serius mereka akan dapat mengubah atau mengoptimalkan keputusan mereka untuk tugas Anda.
Perusahaan besar bekerja dengan mereka - ebay, oracle, tesco, adobe. Dilihat dari keterbukaan mereka, mereka berhasil berinteraksi dengan perusahaan kecil.
Bagaimana ini berbeda dari pengembangan kustom yang EPAM lakukan, misalnya? Fakta bahwa semuanya sudah siap di sini. 99% dari solusi tidak ditulis, tetapi dikumpulkan dari modul yang sudah jadi: markup data, pemilihan jaringan, pelatihan, pengembangan. Perusahaan yang berkembang sesuai pesanan tidak memiliki kecepatan, dinamika pengembangan solusi, dan infrastruktur yang selesai. Kami percaya bahwa tren dan pendekatan yang diidentifikasi CrowdFlower adalah benar.
Untuk apa tugas ini dilakukan?
Mungkin 70% tugas diotomatisasi dengan cara ini. Tugas yang paling cocok adalah pengenalan beragam bidang yang mengandung teks. Misalnya, plat registrasi mobil, yang sudah kita
bicarakan , nomor kereta (di
sini adalah contoh kita dua tahun lalu ), tulisan pada wadah.

Banyak informasi teknis simbolis diakui di pabrik-pabrik untuk menjelaskan produk dan kualitasnya.
Pendekatan ini sangat membantu ketika mengenali produk di rak toko dan label harga, meskipun solusi pengenalan yang cukup rumit harus dibuat di sana.

Tetapi, Anda dapat melarikan diri dari tugas dengan informasi teknis. Semantik apa pun, baik berupa segmentasi instan, dengan deteksi mobil, argali, moose, dan anjing laut berbulu juga akan jatuh pada pendekatan ini.

Arah yang sangat menjanjikan adalah menjaga komunikasi dengan orang-orang dalam bot obrolan suara dan teks. Akan ada cara yang agak tidak biasa untuk menandai: konteks, jenis frasa, "mengisi" nya. Tetapi prinsipnya sama: kita bekerja dalam mode otomatis, seseorang mengendalikan kebenaran pemahaman dan jawaban. Anda dapat menggunakan bantuan operator jika nada suara klien tidak puas atau terganggu. Ketika data menumpuk, kami melatih ulang.
Bagaimana cara bekerja dengan video?
Jika Anda atau dalam perusahaan Anda telah mengembangkan kompetensi yang diperlukan (sedikit pengalaman dalam Pembelajaran Mesin, bekerja dengan Kebun Binatang, offline dan online), maka tidak akan ada kesulitan dalam menyelesaikan masalah penglihatan komputer yang sederhana: segmentasi, klasifikasi, pengenalan teks dan lainnya
Namun untuk videonya, semuanya tidak begitu mulus. Bagaimana Anda menandai jumlah data yang tak ada habisnya ini? Sebagai contoh, itu mungkin berubah bahwa setiap beberapa detik sekali suatu objek (atau beberapa objek) muncul dalam bingkai yang perlu ditandai. Sebagai hasilnya, semua ini dapat berubah menjadi tampilan bingkai demi bingkai dan menghabiskan begitu banyak sumber daya sehingga seseorang bahkan tidak perlu membicarakan kontrol tambahan oleh seseorang setelah meluncurkan solusi. Tapi ini bisa diatasi jika Anda menyajikan video dengan cara yang benar untuk menyorot bingkai dengan bidang yang diminati.
Sebagai contoh, kami menemukan seri video besar di mana perlu untuk menyoroti satu objek spesifik - penggabungan platform kereta api. Dan itu benar-benar tidak mudah. Ternyata semuanya tidak begitu menakutkan, jika Anda membawa monitor lebih lebar, pilih frame rate, misalnya 10FPS, dan letakkan 256 frame pada satu gambar, mis. 25,6 dalam satu gambar:

Mungkin terlihat menakutkan. Namun pada kenyataannya, dibutuhkan sekitar 15-an untuk mengklik satu frame, memilih pusat kopling mobil pada frame. Dan bahkan satu orang dalam satu atau dua hari dapat menandai setidaknya 10 jam video. Dapatkan lebih dari 30 ribu contoh untuk pelatihan. Selain itu, lewatnya platform di depan kamera dalam hal ini bukanlah proses yang berkelanjutan (melainkan jarang, harus dicatat), itu cukup realistis bahkan dalam waktu yang hampir nyata untuk memperbaiki mesin pengenalan, mengisi kembali basis pelatihan! Dan jika pengakuan terjadi dalam kebanyakan kasus dengan benar, maka satu jam video dapat diatasi dalam beberapa menit. Dan kemudian mengabaikan kontrol total oleh orang tersebut, sebagai suatu peraturan, tidak menguntungkan secara ekonomi.
Masih lebih mudah jika video perlu ditandai "ya / tidak" daripada pelokalan objek. Lagipula, acara sering "macet bersama," dan dengan satu gesekan mouse, Anda dapat menandai hingga 16 bingkai sekaligus.
Satu-satunya hal, sebagai aturan, Anda harus menggunakan 2 tahap dalam analisis video: mencari "bingkai atau bidang yang menarik", dan kemudian bekerja dengan masing-masing bingkai tersebut (atau urutan bingkai) oleh algoritma lain.
Ekonomi mesin-manusia
Berapa biaya pemrosesan data visual dapat dioptimalkan? Dengan satu atau lain cara, sangat penting untuk memiliki seseorang untuk mengontrol pengenalan data. Jika kontrol ini selektif, maka biayanya dapat diabaikan. Tetapi jika kita berbicara tentang kontrol total, maka seberapa besar manfaatnya? Ternyata ini masuk akal hampir selalu, jika sebelum seseorang melakukan tugas yang sama tanpa bantuan mesin.
Mari kita ambil bukan contoh terbaik di awal: mencari pizza di gambar, markup dan pemilihan jenis (dan pada kenyataannya, sejumlah karakteristik lainnya). Meskipun, tugasnya tidak sintetis seperti kelihatannya. Kontrol terhadap penampilan produk jaringan waralaba pada kenyataannya memang ada.
Misalkan pengenalan menggunakan server GPU membutuhkan waktu mesin 0,5 detik, untuk seseorang yang benar-benar menandai bingkai selama sekitar 10 detik (pilih jenis pizza dan kualitasnya sesuai sejumlah parameter), dan untuk memeriksa apakah semuanya terdeteksi dengan benar oleh komputer, Anda perlu 2 detik. Tentu saja, akan ada tantangan dalam seberapa mudahnya menyajikan data ini, tetapi waktu seperti itu cukup sebanding dengan praktik kami.
Kami membutuhkan lebih banyak input untuk biaya tata letak manual dan penyewaan server GPU. Sebagai aturan, Anda tidak harus bergantung pada server yang memuat penuh. Memungkinkan pemuatan 100.000 frame per hari (akan membutuhkan 60% daya pemrosesan satu GPU) dengan perkiraan biaya sewa server bulanan 60.000 rubel. Ternyata 2 sen untuk analisis satu frame pada GPU. Analisis manual dengan biaya 30.000r selama 40 jam waktu kerja akan dikenakan biaya 26 kopeck per frame.
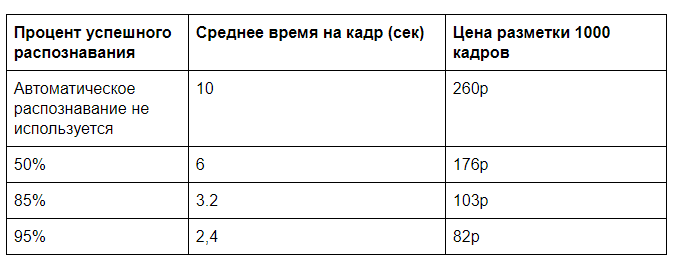
Dan jika Anda kemudian menghapus kontrol total, Anda akan dapat mencapai harga hampir 20 rubel per 1000 frame. Jika ada banyak input data, maka dimungkinkan untuk mengoptimalkan algoritma pengenalan, bekerja pada transfer data dan mencapai efisiensi yang lebih besar.
Dalam praktiknya, membongkar muatan seseorang saat sistem pengenalan mempelajari memiliki arti penting lainnya - membuatnya lebih mudah untuk mengukur skala produk Anda. Peningkatan signifikan dalam jumlah data memungkinkan Anda untuk melatih server pengenalan dengan lebih baik, keakuratannya meningkat. Dan jumlah karyawan yang terlibat dalam proses pengolahan data akan meningkat tidak proporsional dengan volume data, yang secara signifikan akan menyederhanakan pertumbuhan perusahaan dari sudut pandang organisasi.
Sebagai aturan, semakin banyak teks dan garis besar yang harus Anda masukkan secara manual, semakin menguntungkan penggunaan pengenalan otomatis.
Dan apakah semuanya berubah?
Tentu tidak semuanya. Tetapi sekarang beberapa bidang bisnis tidak segila sebelumnya.
Ingin membuat layanan offline tanpa orang di fasilitas itu? Tanam operator dari jarak jauh dan monitor
pada kamera untuk setiap klien? Ini akan menjadi sedikit lebih buruk daripada orang hidup di tempat. Ya, dan operator membutuhkan lebih banyak. Dan jika Anda menurunkan operator setiap 5 kali? Ini bisa menjadi salon kecantikan tanpa resepsi, dan kontrol di pabrik, dan sistem keamanan. Akurasi 100% tidak diperlukan - Anda sepenuhnya dapat mengecualikan operator dari rantai.
Dimungkinkan untuk mengatur sistem akuntansi yang agak rumit untuk layanan yang ada untuk meningkatkan efisiensinya: kontrol penumpang, kendaraan, waktu layanan, di mana ada risiko “mem-bypass” kantor tiket, dll.
Jika tugasnya berada pada level pengembangan visi komputer saat ini dan tidak memerlukan solusi yang sepenuhnya baru, maka ini tidak akan memerlukan investasi serius dalam pengembangan.