Ditambahkan oleh: diskusi yang baik tentang Berita PeretasDavid Yu di GitHub telah mengembangkan
tes kinerja yang menarik untuk panggilan fungsi melalui berbagai antarmuka eksternal (Foreign Function Interfaces,
FFI ).
Dia menciptakan file objek bersama (
.so ) dengan satu fungsi C. sederhana. Kemudian dia menulis kode untuk berulang kali memanggil fungsi ini melalui masing-masing FFI dengan dimensi waktu.
Untuk C "FFI," ia menggunakan tautan dinamis standar, bukan
dlopen() . Perbedaan ini sangat penting, karena sangat mempengaruhi hasil tes. Anda bisa berdebat seberapa jujur perbandingan ini dengan FFI yang sebenarnya, tetapi masih menarik untuk diukur.
Hasil benchmark paling mengejutkan adalah bahwa FFI
LuaJIT secara signifikan lebih cepat daripada C. Ini sekitar 25% lebih cepat dari panggilan C asli untuk fungsi objek bersama. Bagaimana bahasa scripting yang lemah dan dinamis dapat mengambil alih dalam benchmark C? Apakah hasilnya akurat?
Sebenarnya, ini cukup logis. Tes berjalan di Linux, jadi penundaan berasal dari Tabel Tautan Prosedur (PLT). Saya menyiapkan percobaan yang sangat sederhana untuk menunjukkan efek dalam C lama:
https://github.com/skeeto/dynamic-function-benchmarkBerikut adalah hasil dari Intel i7-6700 (Skylake):
plt: 1.759799 ns/call
ind: 1.257125 ns/call
jit: 1.008108 ns/callAda tiga jenis panggilan fungsi:
- Melalui PLT.
- Panggilan fungsi tidak langsung (via
dlsym(3) ) - Panggilan fungsi langsung (melalui fungsi yang dikompilasi JIT)
Seperti yang Anda lihat, yang terakhir adalah yang tercepat. Biasanya tidak digunakan dalam program C, tetapi ini adalah pilihan alami di hadapan kompiler JIT, termasuk, tentu saja, LuaJIT.
Dalam tolok ukur saya, fungsi
empty() disebut:
void empty(void) { }
Kompilasi ke objek bersama:
$ cc -shared -fPIC -Os -o empty.so empty.c
Seperti dalam
perbandingan PRNG sebelumnya, benchmark sebanyak mungkin memanggil fungsi ini sebelum alarm berbunyi.
Tabel Tata Letak Prosedur
Ketika suatu program atau pustaka memanggil suatu fungsi di objek lain yang dibagikan, kompiler tidak bisa tahu di mana fungsi ini akan berada dalam memori. Informasi ditemukan hanya pada saat runtime ketika program dan dependensinya dimuat ke dalam memori. Biasanya fungsi ini terletak di tempat acak, misalnya, sesuai dengan pengacakan ruang alamat (Address Space Layout Randomization, ASLR).
Bagaimana mengatasi masalah seperti itu? Nah, ada beberapa opsi.
Salah satunya adalah menandai setiap panggilan dalam metadata biner. Pembangun runtime dinamis kemudian
memasukkan alamat yang benar pada setiap panggilan. Mekanisme spesifik tergantung pada
model kode yang digunakan selama kompilasi.
Kelemahan dari pendekatan ini adalah memperlambat loading, meningkatkan ukuran file biner dan mengurangi
pertukaran halaman kode antara proses yang berbeda. Pengunduhan diperlambat karena semua rekan panggilan dinamis perlu ditambal dengan alamat yang benar sebelum memulai program. Biner membengkak karena setiap entri membutuhkan tempat di tabel. Dan kurangnya berbagi dikaitkan dengan perubahan halaman kode.
Di sisi lain, overhead dari menjalankan fungsi dinamis dapat dihilangkan, yang memberikan kinerja seperti JIT, seperti yang ditunjukkan dalam benchmark.
Opsi kedua adalah untuk merutekan semua panggilan dinamis melalui tabel. Rekan panggil asli merujuk ke rintisan dalam tabel ini, dan dari sana ke fungsi dinamis yang sebenarnya. Dengan pendekatan ini, kode tidak perlu ditambal, yang mengarah ke
pertukaran sepele antara proses. Untuk setiap fungsi dinamis, Anda perlu menambal hanya satu catatan di tabel. Selain itu, koreksi ini dapat dilakukan dengan
malas , pada panggilan fungsi pertama, yang mempercepat pemuatan lebih.
Pada sistem biner ELF, tabel ini disebut Tabel Tautan Prosedur (PLT). PLT itu sendiri tidak benar-benar diperbaiki - ini ditampilkan sebagai hanya-baca untuk sisa kode. Sebagai gantinya, Global Offset Table (GOT) diperbaiki. Rintisan PLT mengambil alamat fungsi dinamis dari GOT dan
secara tidak langsung melompat ke alamat itu. Untuk malas memuat alamat fungsi, entri GOT ini diinisialisasi dengan alamat fungsi yang menemukan karakter target, memperbarui GOT dengan alamat itu, dan kemudian beralih ke fungsi. Panggilan selanjutnya menggunakan alamat yang terdeteksi malas.
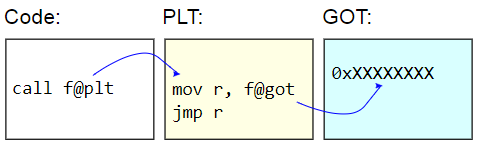
Kerugian dari PLT adalah biaya tambahan tambahan untuk menjalankan fungsi dinamis, yang muncul dalam benchmark. Karena tolok ukur
hanya mengukur pemanggilan fungsi, perbedaannya tampak cukup signifikan, tetapi dalam praktiknya biasanya mendekati nol.
Inilah patokannya:
volatile sig_atomic_t running; static long plt_benchmark(void) { long count; for (count = 0; running; count++) empty(); return count; }
Karena
empty() dalam objek bersama, panggilan melewati PLT.
Panggilan Dinamis Tidak Langsung
Cara lain untuk memanggil fungsi secara dinamis adalah dengan menelusuri PLT dan mendapatkan alamat fungsi target dalam program, misalnya, melalui
dlsym(3) .
void *h = dlopen("path/to/lib.so", RTLD_NOW); void (*f)(void) = dlsym("f"); f();
Jika alamat fungsi diterima, maka biayanya kurang dari panggilan fungsi melalui PLT. Tidak ada fungsi antara rintisan dan akses ke GOT. (Perhatian: jika program memiliki catatan PLT untuk fungsi ini, maka
dlsym(3) sebenarnya dapat mengembalikan alamat rintisan).
Tetapi ini masih merupakan tantangan
tidak langsung . Pada arsitektur konvensional, panggilan fungsi
langsung menerima alamat relatif langsungnya. Maksudnya, tujuan dari panggilan itu adalah beberapa offset kode-keras dari titik panggilan. CPU dapat mengetahui ke mana panggilan akan pergi jauh lebih awal.
Panggilan tidak langsung memiliki lebih banyak overhead. Pertama, alamat perlu disimpan di suatu tempat. Bahkan jika itu hanya sebuah register, penggunaannya meningkatkan defisit register. Kedua, panggilan tidak langsung memprovokasi prediktor cabang di CPU, memaksakan beban tambahan pada prosesor. Dalam skenario terburuk, panggilan bahkan dapat menyebabkan pipa berhenti.
Inilah patokannya:
volatile sig_atomic_t running; static long indirect_benchmark(void (*f)(void)) { long count; for (count = 0; running; count++) f(); return count; }
Fungsi yang diteruskan ke tolok ukur ini diekstraksi menggunakan
dlsym(3) , sehingga kompiler tidak dapat
melakukan sesuatu yang rumit , seperti mengubah panggilan tidak langsung ini kembali ke langsung.
Jika loop body cukup kompleks untuk menyebabkan defisit register dan dengan demikian memberikan alamat ke stack, maka tolok ukur ini juga tidak dapat secara jujur dibandingkan dengan tolok ukur PLT.
Panggilan fungsi langsung
Dua jenis panggilan fungsi dinamis yang pertama adalah sederhana dan mudah digunakan. Panggilan
langsung untuk fungsi dinamis lebih sulit untuk diatur, karena mereka memerlukan perubahan kode selama eksekusi. Dalam benchmark saya, saya mengumpulkan
kompiler JIT kecil untuk menghasilkan panggilan langsung.
Kuncinya adalah bahwa pada transisi eksplisit x86-64 terbatas pada kisaran 2 GB karena operan yang ditandatangani 32-bit (langsung ditandatangani). Ini berarti bahwa kode JIT harus ditempatkan hampir di sebelah fungsi target,
empty() . Jika kode JIT harus memanggil dua fungsi dinamis yang berbeda, dibagi lebih dari 2 GB, maka tidak mungkin untuk membuat dua panggilan langsung.
Untuk menyederhanakan situasi, tolok ukur saya tidak khawatir tentang pilihan yang tepat atau sangat hati-hati dari alamat kode JIT. Setelah menerima alamat fungsi target, itu hanya mengurangi 4 MB, membulatkannya ke halaman terdekat, mengalokasikan sedikit memori dan menulis kode untuk itu. Jika semuanya dilakukan sebagaimana mestinya, maka untuk menemukan tempat Anda perlu memeriksa representasi Anda sendiri dari program dalam memori, dan ini tidak dapat dilakukan dengan cara yang bersih dan portabel. Linux
membutuhkan parsing file virtual di bawah / proc .
Ini adalah bagaimana alokasi memori JIT saya terlihat. Ini mengasumsikan
perilaku yang wajar untuk casting uintptr_t :
static void jit_compile(struct jit_func *f, void (*empty)(void)) { uintptr_t addr = (uintptr_t)empty; void *desired = (void *)((addr - SAFETY_MARGIN) & PAGEMASK); unsigned char *p = mmap(desired, len, prot, flags, fd, 0); }
Dua halaman menonjol di sini: satu untuk menulis, dan yang lainnya dengan kode yang tidak dapat ditulis. Seperti di
perpustakaan saya
untuk penutupan , di sini halaman bawah dapat ditulisi dan berisi variabel yang
running yang disetel ulang ke alarm. Halaman ini harus di sebelah kode JIT untuk memberikan akses yang efektif mengenai RIP, sebagai fungsi dalam dua tolok ukur lainnya. Halaman atas berisi kode rakitan ini:
jit_benchmark: push rbx xor ebx, ebx .loop: mov eax, [rel running] test eax, eax je .done call empty inc ebx jmp .loop .done: mov eax, ebx pop rbx ret
call empty adalah satu-satunya instruksi yang dihasilkan secara dinamis, perlu untuk mengisi alamat relatif dengan benar (minus 5 ditunjukkan relatif ke
akhir instruksi):
// call empty uintptr_t rel = (uintptr_t)empty - (uintptr_t)p - 5
Jika fungsi
empty() tidak dalam objek umum, tetapi dalam file biner yang sama, maka ini pada dasarnya adalah panggilan langsung yang akan dihasilkan oleh kompiler untuk
plt_benchmark() , dengan asumsi bahwa karena alasan tertentu ia tidak dibangun di
empty() .
Ironisnya, memanggil kode yang dikompilasi JIT membutuhkan panggilan tidak langsung (misalnya, melalui pointer fungsi), dan tidak ada cara lain untuk mengatasi hal ini. Apa yang bisa saya lakukan di sini, mengkompilasi JIT fungsi lain untuk panggilan langsung? Untungnya, ini tidak masalah karena hanya panggilan langsung yang diukur dalam satu lingkaran.
Bukan rahasia
Mengingat hasil ini, menjadi jelas mengapa LuaJIT menghasilkan panggilan yang lebih efisien untuk fungsi dinamis daripada PLT,
bahkan jika mereka tetap panggilan tidak langsung . Dalam patokan saya, panggilan tidak langsung tanpa PLT 28% lebih cepat daripada dengan PLT, dan panggilan langsung tanpa PLT 43% lebih cepat daripada dengan PLT. Keuntungan kecil dari program JIT ini dibandingkan dengan program asli lama yang sederhana dicapai karena penolakan mutlak pertukaran kode antara proses.