
Dalam satu proyek yang terkait dengan keamanan sistem Linux, kami perlu mencegat panggilan ke fungsi-fungsi penting di dalam kernel (seperti membuka file dan menjalankan proses) untuk memberikan kemampuan untuk memantau aktivitas dalam sistem dan secara preventif memblokir aktivitas proses yang mencurigakan.
Selama proses pengembangan, kami berhasil menemukan pendekatan yang cukup bagus, yang memungkinkan kami untuk dengan mudah mencegat fungsi apa pun di kernel dengan nama dan mengeksekusi kode kami di sekitar panggilannya. Interceptor dapat diinstal dari modul GPL yang dapat dimuat, tanpa membangun kembali kernel. Pendekatan ini mendukung kernel versi 3.19+ untuk arsitektur x86_64.
(Gambar Penguin di atas: © En3l dengan DeviantArt .)Pendekatan yang Dikenal
API Keamanan Linux
Yang paling benar adalah dengan menggunakan
Linux Security API - antarmuka khusus yang dibuat khusus untuk keperluan ini. Di tempat-tempat penting dari kode kernel, panggilan ke fungsi keamanan berada, yang, pada gilirannya, memanggil panggilan balik yang diatur oleh modul keamanan. Modul keamanan dapat memeriksa konteks operasi dan membuat keputusan apakah diizinkan atau ditolak.
Sayangnya, Linux Security API memiliki beberapa batasan penting:
- modul keamanan tidak dapat dimuat secara dinamis, merupakan bagian dari kernel dan memerlukan pembangunan kembali
- hanya ada satu modul keamanan dalam sistem (dengan beberapa pengecualian)
Jika posisi pengembang kernel tidak jelas mengenai banyaknya modul, maka larangan pemuatan dinamis sangat mendasar: modul keamanan harus menjadi bagian dari kernel untuk memastikan keamanan terus-menerus, sejak saat pemuatan.
Jadi, untuk menggunakan API Keamanan, Anda harus menyediakan rakitan kernel Anda sendiri, serta mengintegrasikan modul add-on dengan SELinux atau AppArmor, yang digunakan oleh distribusi populer. Pelanggan tidak ingin berlangganan kewajiban tersebut, sehingga rute ini ditutup.
Karena alasan ini, API Keamanan tidak cocok untuk kami, jika tidak, itu akan menjadi pilihan ideal.
Modifikasi tabel panggilan sistem
Pemantauan diperlukan terutama untuk tindakan yang dilakukan oleh aplikasi pengguna, sehingga pada prinsipnya itu dapat diimplementasikan pada tingkat panggilan sistem. Seperti yang Anda ketahui, Linux menyimpan semua penangan panggilan sistem di tabel
sys_call_table . Substitusi nilai dalam tabel ini mengarah ke perubahan perilaku seluruh sistem. Dengan demikian, dengan menjaga nilai-nilai lama dari handler dan mengganti handler kita sendiri di dalam tabel, kita dapat memotong panggilan sistem apa pun.
Pendekatan ini memiliki kelebihan tertentu:
- Kontrol penuh atas semua panggilan sistem - satu-satunya antarmuka ke kernel untuk aplikasi pengguna. Dengan menggunakannya, kami dapat memastikan bahwa kami tidak akan melewatkan tindakan penting yang dilakukan oleh proses pengguna.
- Overhead minimum. Ada investasi modal satu kali saat memperbarui tabel panggilan sistem. Selain muatan pemantauan yang tak terhindarkan, satu-satunya biaya adalah panggilan fungsi tambahan (untuk memanggil penangan panggilan sistem yang asli).
- Persyaratan kernel minimum. Jika diinginkan, pendekatan ini tidak memerlukan opsi konfigurasi tambahan apa pun di kernel, sehingga secara teori mendukung opsi sistem seluas mungkin.
Namun, ia juga menderita beberapa kekurangan:
- Kompleksitas teknis dari implementasi. Dengan sendirinya, mengganti pointer dalam sebuah tabel tidaklah sulit. Tetapi tugas terkait membutuhkan solusi yang tidak jelas dan kualifikasi tertentu:
- tabel panggilan sistem pencarian
- modifikasi tabel perlindungan memotong
- penggantian atom dan aman
Ini semua adalah hal yang menarik, tetapi membutuhkan waktu pengembangan yang berharga, pertama untuk implementasi, dan kemudian untuk dukungan dan pemahaman.
- Ketidakmampuan untuk mencegat beberapa penangan. Di kernel sebelum versi 4.16, penanganan panggilan sistem untuk arsitektur x86_64 berisi sejumlah optimisasi. Beberapa dari mereka menuntut agar pemanggil panggilan sistem menjadi adaptor khusus yang diterapkan pada assembler. Oleh karena itu, penangan seperti itu terkadang sulit, dan kadang-kadang bahkan tidak mungkin untuk menggantinya dengan Anda sendiri, ditulis dalam C. Selain itu, berbagai optimasi digunakan dalam versi kernel yang berbeda, yang menambah kesulitan teknis celengan.
- Hanya panggilan sistem yang dicegat. Pendekatan ini memungkinkan Anda untuk mengganti penangan panggilan sistem, yang membatasi titik masuk hanya untuk mereka. Semua pemeriksaan tambahan dilakukan baik di awal atau di akhir, dan kami hanya memiliki argumen panggilan sistem dan nilai kembalinya. Terkadang ini mengarah pada kebutuhan untuk menggandakan cek pada kecukupan argumen dan mengakses cek. Kadang-kadang menyebabkan overhead yang tidak perlu ketika Anda perlu menyalin memori proses pengguna dua kali: jika argumen dilewatkan melalui pointer, maka pertama-tama kita harus menyalinnya sendiri, maka pawang yang asli akan menyalin argumen lagi untuk dirinya sendiri. Selain itu, dalam beberapa kasus, panggilan sistem memberikan rincian acara yang terlalu rendah yang harus disaring dari kebisingan.
Awalnya, kami memilih dan berhasil menerapkan pendekatan ini, mengejar manfaat mendukung sejumlah besar sistem. Namun, pada saat itu kami masih belum tahu tentang fitur x86_64 dan pembatasan panggilan yang dicegat. Kemudian ternyata sangat penting bagi kami untuk mendukung panggilan sistem yang terkait dengan memulai proses baru - klon () dan exece () - yang hanya istimewa. Inilah yang membuat kami mencari opsi baru.
Menggunakan kprobes
Salah satu opsi yang dipertimbangkan adalah penggunaan
kprobes : API khusus yang terutama dirancang untuk debugging dan melacak kernel. Antarmuka ini memungkinkan Anda untuk mengatur pra-dan pasca-penangan untuk
setiap instruksi dalam kernel, serta penangan untuk masuk dan kembali dari suatu fungsi. Penangan mendapatkan akses ke register dan dapat mengubahnya. Dengan demikian, kita bisa mendapatkan pemantauan dan kemampuan untuk mempengaruhi jalannya pekerjaan lebih lanjut.
Manfaat menggunakan kprobes untuk mencegat:
- API dewasa. Kprobes telah ada dan membaik sejak jaman dahulu (2002). Mereka memiliki antarmuka yang terdokumentasi dengan baik, sebagian besar jebakan telah ditemukan, pekerjaan mereka telah dioptimalkan sebanyak mungkin, dan sebagainya. Secara umum, segunung keunggulan dibandingkan sepeda buatan eksperimental.
- Intersepsi setiap tempat di inti. Kprobes diimplementasikan menggunakan breakpoints (instruksi int3) yang tertanam dalam kode yang dapat dieksekusi kernel. Ini memungkinkan Anda untuk menginstal kprobes secara harfiah di mana saja dalam fungsi apa pun, jika diketahui. Demikian pula, kretprobes diimplementasikan melalui spoofing alamat kembali pada stack dan memungkinkan Anda untuk mencegat pengembalian dari fungsi apa pun (dengan pengecualian dari mereka yang pada prinsipnya tidak mengembalikan kontrol).
Kerugian dari kprobes:
- Kesulitan teknis. Kprobes hanyalah cara untuk menetapkan breakpoint di mana saja di kernel. Untuk mendapatkan argumen fungsi atau nilai-nilai variabel lokal, Anda perlu tahu di mana register atau di mana di stack mereka berada, dan ekstrak secara mandiri dari sana. Untuk memblokir panggilan fungsi, Anda harus secara manual mengubah keadaan proses sehingga prosesor berpikir bahwa ia telah mengembalikan kontrol dari fungsi.
- Jprobes sudah usang. Jprobes adalah add-on untuk kprobes yang memungkinkan Anda untuk dengan mudah mencegat panggilan fungsi. Ini akan secara mandiri mengekstraksi argumen fungsi dari register atau stack dan memanggil handler Anda, yang harus memiliki tanda tangan yang sama dengan fungsi hooked. Tangkapannya adalah bahwa jprobes sudah usang dan dipotong dari kernel modern.
- Overhead non-sepele. Breakpoints mahal, tapi satu kali. Breakpoints tidak mempengaruhi fungsi lain, tetapi prosesnya relatif mahal. Untungnya, optimisasi lompat diterapkan untuk arsitektur x86_64, yang secara signifikan mengurangi biaya kprobes, tetapi masih tetap lebih dari, misalnya, ketika memodifikasi tabel panggilan sistem.
- Keterbatasan kretprobes. Kretprobes diimplementasikan dengan spoofing alamat pengirim di stack. Karenanya, mereka perlu menyimpan alamat asli di suatu tempat untuk kembali ke sana setelah memproses kretprobe. Alamat disimpan dalam buffer ukuran tetap. Dalam kasus overflow, ketika terlalu banyak panggilan simultan dari fungsi yang dicegat dieksekusi dalam sistem, kretprobes akan melewati operasi.
- Dinonaktifkan Ekstrusi. Karena kprobes didasarkan pada register prosesor interupsi dan juggle, untuk sinkronisasi semua penangan dieksekusi dengan preemption dinonaktifkan. Ini memberlakukan batasan tertentu pada penangan: Anda tidak bisa menunggu di dalamnya - mengalokasikan banyak memori, melakukan I / O, tidur di timer dan semaphore, dan hal-hal lain yang diketahui.
Dalam proses meneliti topik, mata kita tertuju pada kerangka kerja
ftrace , yang dapat menggantikan jprobes. Ternyata, itu berfungsi lebih baik untuk kebutuhan intersepsi panggilan fungsi kami. Namun, jika Anda perlu melacak instruksi spesifik dalam fungsi, maka kprobes tidak boleh diabaikan.
Penyambungan
Demi kelengkapan, perlu juga dijelaskan metode klasik fungsi intersep, yang terdiri dari mengganti instruksi di awal fungsi dengan transisi tanpa syarat yang mengarah ke handler kami. Instruksi asli ditransfer ke tempat lain dan dijalankan sebelum kembali ke fungsi yang dicegat. Dengan bantuan dua transisi kami menanamkan (splice in) kode tambahan kami ke dalam fungsi, oleh karena itu pendekatan ini disebut
splicing .
Ini adalah bagaimana optimasi lompatan untuk kprobes diimplementasikan. Dengan menggunakan splicing, Anda dapat mencapai hasil yang sama, tetapi tanpa biaya tambahan untuk kprobes dan dengan kontrol penuh terhadap situasi.
Manfaat penyambungan sudah jelas:
- Persyaratan kernel minimum. Penyambungan tidak memerlukan opsi khusus apa pun di kernel dan berfungsi di awal fungsi apa pun. Anda hanya perlu tahu alamatnya.
- Overhead minimum. Dua transisi tanpa syarat - itu semua tindakan yang perlu dilakukan oleh kode yang dicegat untuk mentransfer kontrol ke pawang dan sebaliknya. Transisi seperti itu diprediksi dengan sempurna oleh prosesor dan sangat murah.
Namun, kelemahan utama dari pendekatan ini secara serius mengaburkan gambar:
- Kesulitan teknis. Dia berguling. Anda tidak bisa hanya mengambil dan menulis ulang kode mesin. Berikut adalah daftar tugas yang harus diselesaikan:
- sinkronisasi instalasi dan penghapusan intersepsi (bagaimana jika fungsi dipanggil langsung dalam proses mengganti instruksinya?)
- memotong perlindungan pada modifikasi wilayah memori dengan kode
- Pembatalan cache CPU setelah mengganti instruksi
- membongkar instruksi yang dapat diganti untuk menyalinnya secara keseluruhan
- memeriksa tidak adanya transisi di dalam bagian yang diganti
- periksa kemampuan untuk memindahkan potongan yang diganti ke lokasi lain
Ya, Anda dapat memata-matai kprobes dan menggunakan kerangka kerja intranuclear livepatch, tetapi solusi terakhir masih cukup rumit. Menakutkan membayangkan berapa banyak masalah tidur dalam setiap implementasi baru.
Secara umum, jika Anda dapat memanggil iblis ini, mensubordinasi hanya kepada para inisiat, dan siap untuk menanggungnya dalam kode Anda, maka splicing adalah pendekatan yang sepenuhnya berfungsi untuk mencegat panggilan fungsi. Saya memiliki sikap negatif untuk menulis sepeda, jadi opsi ini tetap menjadi cadangan bagi kami seandainya tidak ada kemajuan sama sekali dengan solusi yang sudah jadi lebih mudah.
Pendekatan baru dengan ftrace
Ftrace adalah kerangka kerja penelusuran kernel tingkat fungsi. Ini telah dikembangkan sejak 2008 dan memiliki antarmuka yang fantastis untuk program pengguna. Ftrace memungkinkan Anda untuk melacak frekuensi dan durasi panggilan fungsi, menampilkan grafik panggilan, memfilter fungsi yang menarik berdasarkan templat, dan sebagainya. Anda dapat mulai membaca tentang fitur ftrace
dari sini , lalu ikuti tautan dan dokumentasi resmi.
Ini mengimplementasikan ftrace berdasarkan kunci kompiler
-pg dan
-mfentry , yang memasukkan panggilan ke fungsi jejak khusus mcount () atau __fentry __ () pada awal setiap fungsi. Biasanya, dalam program pengguna, fitur kompiler ini digunakan oleh profiler untuk melacak panggilan ke semua fungsi. Kernel menggunakan fungsi-fungsi ini untuk mengimplementasikan kerangka kerja ftrace.
Memanggil ftrace dari
masing-masing fungsi, tentu saja, tidak murah, jadi optimisasi tersedia untuk arsitektur populer:
dynamic ftrace . Intinya adalah bahwa kernel mengetahui lokasi semua panggilan ke mcount () atau __fentry __ () dan pada tahap awal memuat menggantikan kode mesin mereka dengan
nop - instruksi khusus yang tidak melakukan apa-apa. Ketika penelusuran disertakan dalam fungsi yang diperlukan, panggilan ftrace ditambahkan kembali. Jadi, jika ftrace tidak digunakan, maka dampaknya pada sistem minimal.
Deskripsi fungsi yang diperlukan
Setiap fungsi yang dicegat dapat dijelaskan oleh struktur berikut:
struct ftrace_hook { const char *name; void *function; void *original; unsigned long address; struct ftrace_ops ops; };
Pengguna hanya perlu mengisi tiga bidang pertama: nama, fungsi, asli. Kolom yang tersisa dianggap sebagai detail implementasi. Deskripsi semua fungsi yang dicegat dapat dirakit menjadi sebuah array dan makro dapat digunakan untuk meningkatkan kekompakan kode:
#define HOOK(_name, _function, _original) \ { \ .name = (_name), \ .function = (_function), \ .original = (_original), \ } static struct ftrace_hook hooked_functions[] = { HOOK("sys_clone", fh_sys_clone, &real_sys_clone), HOOK("sys_execve", fh_sys_execve, &real_sys_execve), };
Wrappers over intercepted functions adalah sebagai berikut:
static asmlinkage long (*real_sys_execve)(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp); static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_debug("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_debug("execve() returns: %ld\n", ret); return ret; }
Seperti yang Anda lihat, fungsi yang dicegat dengan kode tambahan minimum. Satu-satunya hal yang membutuhkan perhatian adalah fungsi tanda tangan. Mereka harus cocok satu lawan satu. Tanpa ini, tentu saja, argumen akan dilewatkan secara salah dan semuanya akan menurun. Untuk mencegat panggilan sistem, ini kurang penting, karena penangannya sangat stabil dan, untuk efisiensi, mengambil argumen dalam urutan yang sama dengan panggilan sistem itu sendiri. Namun, jika Anda berencana untuk mencegat fungsi-fungsi lain, Anda harus ingat bahwa
tidak ada antarmuka yang stabil di dalam kernel .
Inisialisasi Ftrace
Pertama, kita perlu menemukan dan menyimpan alamat fungsi yang akan kita sadap. Ftrace memungkinkan Anda untuk melacak fungsi berdasarkan nama, tetapi kami masih perlu mengetahui alamat fungsi asli untuk memanggilnya.
Anda bisa mendapatkan alamat menggunakan
kallsyms - daftar semua karakter di kernel. Daftar ini mencakup
semua karakter, tidak hanya diekspor untuk modul. Mendapatkan alamat dari fungsi yang dikaitkan terlihat seperti ini:
static int resolve_hook_address(struct ftrace_hook *hook) { hook->address = kallsyms_lookup_name(hook->name); if (!hook->address) { pr_debug("unresolved symbol: %s\n", hook->name); return -ENOENT; } *((unsigned long*) hook->original) = hook->address; return 0; }
Selanjutnya, Anda perlu menginisialisasi struktur
ftrace_ops . Itu mengikat
bidang ini hanya
fungsi , menunjukkan panggilan balik, tetapi kita juga perlu
atur beberapa flag penting:
int fh_install_hook(struct ftrace_hook *hook) { int err; err = resolve_hook_address(hook); if (err) return err; hook->ops.func = fh_ftrace_thunk; hook->ops.flags = FTRACE_OPS_FL_SAVE_REGS | FTRACE_OPS_FL_IPMODIFY; }
fh_ftrace_thunk () adalah panggilan balik kami yang akan dipanggil ftrace saat melacak suatu fungsi. Tentang dia nanti. Bendera yang kita atur akan diperlukan untuk menyelesaikan intersepsi. Mereka menginstruksikan ftrace untuk menyimpan dan mengembalikan register prosesor, yang isinya dapat kita ubah dalam panggilan balik.
Sekarang kami siap mengaktifkan intersepsi. Untuk melakukan ini, Anda harus terlebih dahulu mengaktifkan ftrace untuk fungsi yang menarik bagi kami menggunakan ftrace_set_filter_ip (), dan kemudian mengizinkan ftrace untuk memanggil panggilan balik kami menggunakan register_ftrace_function ():
int fh_install_hook(struct ftrace_hook *hook) { err = ftrace_set_filter_ip(&hook->ops, hook->address, 0, 0); if (err) { pr_debug("ftrace_set_filter_ip() failed: %d\n", err); return err; } err = register_ftrace_function(&hook->ops); if (err) { pr_debug("register_ftrace_function() failed: %d\n", err); ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0); return err; } return 0; }
Intersepsi dimatikan dengan cara yang sama, hanya dalam urutan terbalik:
void fh_remove_hook(struct ftrace_hook *hook) { int err; err = unregister_ftrace_function(&hook->ops); if (err) { pr_debug("unregister_ftrace_function() failed: %d\n", err); } err = ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0); if (err) { pr_debug("ftrace_set_filter_ip() failed: %d\n", err); } }
Setelah panggilan ke unregister_ftrace_function () selesai, tidak ada aktivasi dari callback yang terinstal dalam sistem (dan dengan itu pembungkus kami) dijamin. Karena itu, kita dapat, misalnya, dengan aman membongkar modul pencegat, tanpa takut bahwa di suatu tempat dalam sistem fungsi kita masih dilakukan (karena jika hilang, prosesor akan marah).
Melakukan kait fungsi
Bagaimana sebenarnya intersepsi dilakukan? Sangat sederhana. Ftrace memungkinkan Anda untuk mengubah status register setelah keluar dari panggilan balik. Dengan mengubah register% rip - sebuah penunjuk ke instruksi yang dapat dieksekusi berikutnya - kita mengubah instruksi yang dijalankan oleh prosesor - yaitu, kita dapat memaksanya untuk menjalankan transisi tanpa syarat dari fungsi saat ini ke fungsi kita. Jadi kami mengambil kendali.
Callback untuk ftrace adalah sebagai berikut:
static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip, struct ftrace_ops *ops, struct pt_regs *regs) { struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops); regs->ip = (unsigned long) hook->function; }
Dengan menggunakan container_of () makro, kami mendapatkan alamat
struct ftrace_hook di alamat
struct ftrace_hook disematkan di dalamnya, setelah itu kami mengganti nilai register% rip dalam struktur
struct pt_regs dengan alamat penangan kami. Itu saja. Untuk arsitektur selain x86_64, register ini dapat disebut secara berbeda (seperti IP atau PC), tetapi ide ini pada prinsipnya berlaku untuk mereka.
Perhatikan
kualifikasi notrace yang ditambahkan untuk callback. Mereka dapat menandai fitur yang tidak boleh dilacak menggunakan ftrace. Sebagai contoh, ini adalah bagaimana fungsi ftrace itu sendiri yang terlibat dalam proses penelusuran ditandai. Ini membantu mencegah sistem dari pembekuan dalam loop tanpa akhir ketika melacak semua fungsi di kernel (ftrace dapat melakukan ini).
Callback ftback biasanya panggilan dengan ekstrusi dinonaktifkan (seperti kprobes). Mungkin ada pengecualian, tetapi Anda tidak harus bergantung padanya. Namun, dalam kasus kami, batasan ini tidak penting, jadi kami hanya mengganti delapan byte dalam struktur.
Fungsi wrapper, yang dipanggil nanti, akan dieksekusi dalam konteks yang sama dengan fungsi aslinya. Oleh karena itu, di sana Anda dapat melakukan apa yang boleh dilakukan dalam fungsi yang dicegat. Misalnya, jika Anda mencegat penangan interupsi, Anda masih tidak bisa tidur di pembungkus.
Perlindungan Panggilan Rekursif
Ada tangkapan dalam kode di atas: ketika wrapper kami memanggil fungsi asli, itu lagi masuk ke ftrace, yang lagi-lagi memanggil callback kami, yang lagi-lagi mentransfer kontrol ke wrapper. Rekursi yang tak terbatas ini perlu disingkat.Cara paling elegan yang terpikir oleh kami adalah menggunakan parent_ipsalah satu argumen dari callback ftrace, yang berisi alamat pengirim ke fungsi yang disebut fungsi yang dilacak. Biasanya argumen ini digunakan untuk membuat grafik panggilan fungsi. Kita dapat menggunakannya untuk membedakan panggilan pertama dari fungsi yang dicegat dari yang diulang.Memang saat menelepon kembaliparent_ipharus menunjuk ke dalam pembungkus kami, sementara pada awalnya - di suatu tempat di tempat lain di kernel. Kontrol harus ditransfer hanya ketika fungsi pertama kali dipanggil, semua yang lain harus diizinkan untuk menjalankan fungsi aslinya.Pemeriksaan entri dapat dilakukan dengan sangat efisien dengan membandingkan alamat dengan batas-batas modul saat ini (yang berisi semua fungsi kami). Ini bekerja dengan baik jika dalam modul hanya pembungkus memanggil fungsi yang dicegat. Kalau tidak, Anda harus lebih selektif.Secara total, callback ftrace yang benar adalah sebagai berikut: static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip, struct ftrace_ops *ops, struct pt_regs *regs) { struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops); if (!within_module(parent_ip, THIS_MODULE)) regs->ip = (unsigned long) hook->function; }
Fitur / keunggulan khas dari pendekatan ini:- Overhead rendah. Hanya beberapa pengurangan dan perbandingan. Tidak ada spinlocks, daftar berlalu, dan sebagainya.
- . . , .
- . kretprobes , ( ). , .
Mari kita lihat sebuah contoh: Anda mengetik perintah ls di terminal untuk melihat daftar file di direktori saat ini. Shell (katakanlah Bash) menggunakan sepasang fungsi fork () + execve () tradisional dari pustaka standar C untuk memulai proses baru . Secara internal, fungsi-fungsi ini diimplementasikan melalui system call clone () dan execve (), masing-masing. Misalkan kita mencegat panggilan sistem execve () untuk mengontrol awal proses baru.Dalam bentuk grafik, intersepsi fungsi handler terlihat seperti ini: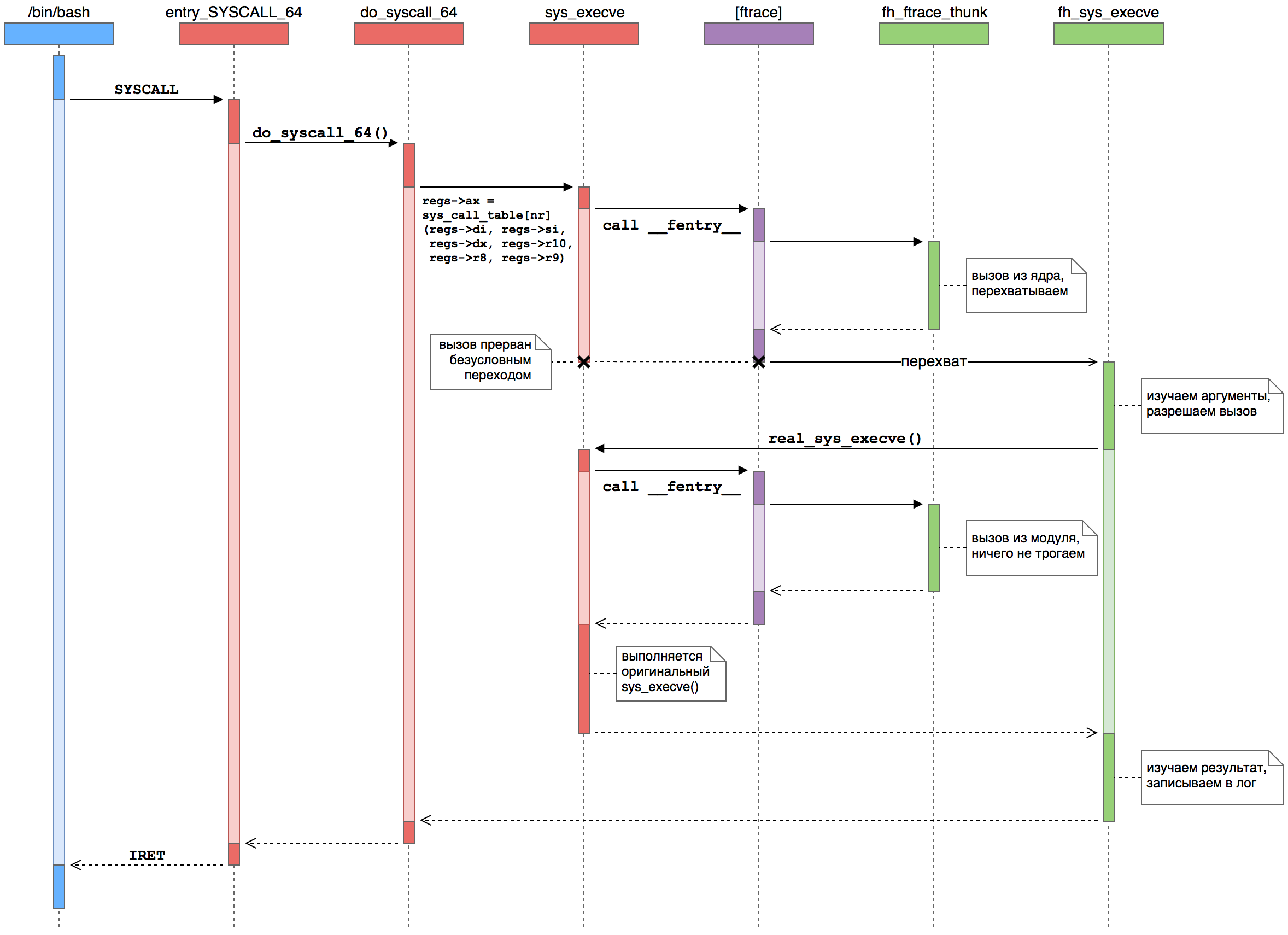 Di sini kita melihat bagaimana proses pengguna ( biru ) membuat panggilan sistem ke kernel ( merah), di mana kerangka kerja ftrace ( ungu ) memanggil fungsi dari modul kami ( hijau ).
Di sini kita melihat bagaimana proses pengguna ( biru ) membuat panggilan sistem ke kernel ( merah), di mana kerangka kerja ftrace ( ungu ) memanggil fungsi dari modul kami ( hijau ).- Proses pengguna menjalankan SYSCALL. Dengan menggunakan instruksi ini, mode kernel ditransfer dan kontrol ditransfer ke pengendali panggilan sistem tingkat rendah - entry_SYSCALL_64 (). Dia bertanggung jawab untuk semua panggilan sistem dari program 64-bit pada kernel 64-bit.
- . , , do_syscall_64 (), .
sys_call_table — sys_execve ().
- ftrace. __fentry__ (), ftrace. , , nop , sys_execve() .
- Ftrace . ftrace , . , %rip, .
- .
parent_ip , do_syscall_64() — sys_execve() — , %rip pt_regs .
- Ftrace . FTRACE_SAVE_REGS, ftrace
pt_regs . ftrace . %rip — — .
- -. - sys_execve() . fh_sys_execve (). , do_syscall_64().
- . . fh_sys_execve() ( ) . . — sys_execve() , real_sys_execve , .
- . sys_execve(), ftrace . , -…
- . sys_execve() fh_sys_execve(), do_syscall_64(). sys_execve() . : ftrace sys_execve() .
- . sys_execve() fh_sys_execve(). . , execve() , , , . .
- Manajemen kembali ke inti. Akhirnya, fh_sys_execve () selesai dan kontrol berpindah ke do_syscall_64 (), yang menganggap bahwa pemanggilan sistem selesai seperti biasa. Inti melanjutkan bisnis nuklirnya.
- Manajemen kembali ke proses pengguna. Akhirnya, kernel mengeksekusi instruksi IRET (atau SYSRET, tetapi untuk execve () selalu IRET), pengaturan register untuk proses pengguna baru dan menempatkan prosesor pusat ke mode eksekusi kode pengguna. Panggilan sistem (dan memulai proses baru) selesai.
Keuntungan dan kerugian
Sebagai hasilnya, kami mendapatkan cara yang sangat mudah untuk mencegat fungsi apa pun di kernel, yang memiliki keuntungan sebagai berikut:- API . . , , . — -, .
- . . - , , , - . ( ), .
- Intersepsi kompatibel dengan penelusuran. Jelas, metode ini tidak bertentangan dengan ftrace, jadi Anda masih dapat mengambil indikator kinerja yang sangat berguna dari kernel. Menggunakan kprobes atau splicing dapat mengganggu mekanisme ftrace.
Apa kerugian dari solusi ini?- Persyaratan konfigurasi kernel. Agar berhasil melakukan kait fungsi menggunakan ftrace, kernel harus menyediakan sejumlah fitur:
- daftar karakter kallsym untuk mencari fungsi berdasarkan nama
- kerangka kerja ftrace secara umum untuk penelusuran
- ftrace opsi intersepsi kritis
. , , , , . , - , .
- ftrace , kprobes ( ftrace ), , , . , ftrace — , «» ftrace .
- . , . , , ftrace . , , .
- Ftrace panggilan ganda. Pendekatan analisis pointer yang dijelaskan di atas
parent_ipmenghasilkan panggilan ftrace lagi untuk fungsi terkait. Ini menambahkan sedikit overhead dan dapat merobohkan jejak lain yang akan melihat panggilan dua kali lebih banyak. Kelemahan ini dapat dihindari dengan menerapkan sedikit ilmu hitam: panggilan ftrace terletak di awal fungsi, jadi jika alamat fungsi asli dipindahkan 5 byte ke depan (panjang instruksi panggilan), maka Anda dapat melompati ftrace.
Pertimbangkan beberapa kelemahan secara lebih rinci.Persyaratan konfigurasi kernel
Sebagai permulaan, kernel harus mendukung ftrace dan kallsyms. Untuk melakukan ini, opsi berikut harus diaktifkan:- CONFIG_FTRACE
- CONFIG_KALLSYMS
Kemudian, ftrace harus mendukung modifikasi register dinamis. Opsi bertanggung jawab untuk ini.- CONFIG_DYNAMIC_FTRACE_WITH_REGS
Selanjutnya, kernel yang digunakan harus didasarkan pada versi 3.19 atau lebih tinggi untuk memiliki akses ke bendera FTRACE_OPS_FL_IPMODIFY. Versi kernel sebelumnya juga dapat mengganti register% rip, tetapi mulai dengan 3.19 ini harus dilakukan hanya setelah mengatur flag ini. Kehadiran sebuah flag untuk kernel lama akan menyebabkan kesalahan kompilasi, dan ketiadaannya untuk kernel baru akan mengarah pada intersepsi kosong.Akhirnya, untuk melakukan intersepsi, lokasi panggilan ftrace sangat penting: panggilan harus ditempatkan di awal, sebelum prolog fungsi (di mana ruang dialokasikan untuk variabel lokal dan bingkai tumpukan dibentuk). Fitur arsitektur ini diperhitungkan oleh opsiArsitektur x86_64 mendukung opsi ini, tetapi i386 tidak. Karena keterbatasan arsitektur i386, kompiler tidak dapat memasukkan panggilan ftrace sebelum fungsi prolog, oleh karena itu, pada saat ftrace dipanggil, tumpukan fungsi sudah dimodifikasi. Dalam hal ini, untuk mencegat, tidak cukup hanya dengan mengubah nilai register% eip - Anda juga harus membalik semua tindakan yang dilakukan dalam prolog yang berbeda dari satu fungsi ke fungsi lainnya.Karena alasan ini, intersepsi ftrace tidak mendukung arsitektur x86 32-bit. Pada prinsipnya, ini dapat diimplementasikan dengan bantuan ilmu hitam tertentu (menghasilkan dan melakukan "anti-prolog"), tetapi kemudian kesederhanaan teknis dari solusi akan menderita, yang merupakan salah satu keuntungan menggunakan ftrace.Kejutan yang tidak terlihat
Selama pengujian, kami menemukan satu fitur menarik : pada beberapa distribusi, fungsi kait menyebabkan sistem macet dengan erat. Tentu, ini hanya terjadi pada sistem selain yang digunakan oleh pengembang. Masalahnya juga tidak mereproduksi pada prototipe intersepsi asli, dengan distribusi dan versi kernel apa pun.Debugging menunjukkan bahwa hang terjadi di dalam fungsi yang dicegat. Untuk beberapa alasan mistik, ketika fungsi asli dipanggil di dalam callback ftrace, alamat parent_ipterus ditentukan dalam kode kernel bukan kode fungsi pembungkus. Karena itu, loop tanpa akhir muncul, karena ftrace memanggil pembungkus kami berulang kali tanpa melakukan tindakan yang bermanfaat.Untungnya, kami memiliki kode yang berfungsi dan rusak yang kami miliki, sehingga menemukan perbedaan itu hanya masalah waktu. Setelah menyatukan kode dan membuang semua yang tidak perlu, perbedaan antara versi dilokalkan ke fungsi wrapper.Opsi ini berfungsi: static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_debug("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_debug("execve() returns: %ld\n", ret); return ret; }
tapi yang ini - mematikan sistem: static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_devel("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_devel("execve() returns: %ld\n", ret); return ret; }
Bagaimana ternyata tingkat logging mempengaruhi perilaku? Sebuah studi yang hati-hati terhadap kode mesin dari kedua fungsi tersebut dengan cepat mengklarifikasi situasi dan menyebabkan perasaan ketika kompiler disalahkan. Biasanya dia ada di daftar tersangka di suatu tempat di dekat sinar kosmik, tetapi tidak kali ini.Masalahnya, ternyata, adalah bahwa panggilan ke pr_devel () diperluas ke kekosongan. Versi makro printk ini digunakan untuk masuk selama pengembangan. Entri log seperti itu tidak menarik selama operasi, oleh karena itu, mereka secara otomatis dikeluarkan dari kode jika makro DEBUG tidak dideklarasikan. Setelah itu, fungsi untuk kompiler berubah menjadi ini: static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { return real_sys_execve(filename, argv, envp); }
Dan di sini optimasi muncul. Dalam kasus ini bekerja disebut ekor panggilan optimasi (ekor panggilan optimasi). Ini memungkinkan kompiler untuk mengganti panggilan fungsi yang jujur dengan lompatan langsung ke tubuhnya jika satu fungsi memanggil yang lain dan segera mengembalikan nilainya. Dalam kode mesin, panggilan jujur terlihat seperti ini: 0000000000000000 <fh_sys_execve>: 0: e8 00 00 00 00 callq 5 <fh_sys_execve+0x5> 5: ff 15 00 00 00 00 callq *0x0(%rip) b: f3 c3 repz retq
dan tidak bekerja - seperti ini: 0000000000000000 <fh_sys_execve>: 0: e8 00 00 00 00 callq 5 <fh_sys_execve+0x5> 5: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax c: ff e0 jmpq *%rax
Pernyataan CALL pertama adalah panggilan __fentry __ () yang sama dengan yang dimasukkan oleh kompiler di awal semua fungsi. Tetapi lebih lanjut dalam kode normal, Anda dapat melihat panggilan ke real_sys_execve (dengan penunjuk dalam memori) melalui instruksi CALL dan kembali dari fh_sys_execve () menggunakan instruksi RET. Kode rusak masuk ke fungsi real_sys_execve () langsung menggunakan JMP.Optimalisasi panggilan ekor memungkinkan Anda menghemat sedikit waktu dalam pembentukan kerangka tumpukan "yang tidak berarti", yang mencakup alamat balik yang disimpan dalam tumpukan dengan instruksi CALL. Namun, bagi kami, kebenaran alamat pengirim memainkan peran penting - kami menggunakannya parent_ipuntuk membuat keputusan tentang intersepsi. Setelah optimasi, fungsi fh_sys_execve () tidak lagi menyimpan alamat pengirim baru di stack, tetap ada yang lama - menunjuk ke kernel. Oleh karena ituparent_ipterus menunjuk ke dalam nukleus, yang akhirnya mengarah pada pembentukan loop tak terbatas.Ini juga menjelaskan mengapa masalah hanya terjadi pada beberapa distribusi. Saat mengkompilasi modul, distribusi yang berbeda menggunakan set flag kompilasi yang berbeda. Dalam distribusi tertekan, optimisasi panggilan ekor diaktifkan secara default.Solusi bagi masalah kami adalah menonaktifkan pengoptimalan panggilan ekor untuk seluruh file dengan fungsi wrapper: #pragma GCC optimize("-fno-optimize-sibling-calls")
Kesimpulan
Apa lagi yang bisa saya katakan ... Mengembangkan kode tingkat rendah untuk kernel Linux itu menyenangkan. Saya berharap publikasi ini menghemat sedikit waktu bagi seseorang dalam pergolakan pilihan, apa yang harus digunakan untuk menulis antivirus terbaik Anda di dunia.Jika Anda ingin bereksperimen dengan intersepsi sendiri, maka kode modul kernel lengkap dapat ditemukan di Github .