Hai, nama pengguna! Setiap hari kita dihadapkan dengan pencarian berbagai data. Hampir setiap situs web dengan banyak informasi sekarang memiliki pencarian. Pencarian ada di komputer rumah, di ponsel, di berbagai jenis perangkat lunak. Tentu saja, jika Anda bertanya kepada pengembang apa pun tentang pencarian dalam hal teknologi, elasticsearch, lucene atau sphinx akan segera muncul di benak Anda. Hari ini saya ingin melihat dengan Anda "di bawah tenda" dari pencarian teks lengkap dan mencari tahu perkiraan pertama cara kerjanya, menggunakan contoh hh.ru.
 Penafian: artikel ini bukan satu-satunya sudut pandang yang benar dan hanya berfungsi sebagai titik pengantar untuk pengenalan awal dengan pekerjaan pencarian teks dan beberapa opsi untuk mengimplementasikan bagian-bagiannya masing-masing.
Penafian: artikel ini bukan satu-satunya sudut pandang yang benar dan hanya berfungsi sebagai titik pengantar untuk pengenalan awal dengan pekerjaan pencarian teks dan beberapa opsi untuk mengimplementasikan bagian-bagiannya masing-masing.Jika Anda melihat detail pencarian, maka selain bagian yang jelas dalam bentuk string pencarian, Anda dapat melihat lebih banyak:
- petunjuk (dia menyarankan)
- penghitung hasil pencarian (counter),
- berbagai jenis penyortiran (sort),
- segi - karakteristik dokumen yang dikelompokkan, misalnya, metro tempat lowongan berada, juga melakukan fungsi filter (filter),
- sinonim
- pagination
- snippet (snippet) - deskripsi kecil dokumen dalam penerbitan,
- dll.

Dan semua ini melayani satu tujuan - untuk memenuhi kebutuhan pengguna untuk menemukan informasi yang tepat secepat dan se relevan mungkin. Misalnya, pemfilteran penting untuk mempersempit hasil pencarian, dalam kasus kami mungkin merupakan pemfilteran berdasarkan pengalaman, lokasi, atau pekerjaan kandidat. Aspek berguna untuk menampilkan berapa banyak lowongan di setiap rentang gaji. Penting juga untuk melengkapi pertanyaan dan dokumen dengan sinonim sehingga atas permintaan "pengembang java" mereka dapat menemukan dokumen "pengembang java".
Selain pencarian itu sendiri, selalu ada banyak komponen yang membuat hidup lebih mudah bagi pengguna: wali yang bertanggung jawab untuk memperbaiki kesalahan, atau sajest yang meminta kueri yang lebih cocok ketika Anda berinteraksi dengan bilah pencarian. Dalam beberapa kasus, penting untuk dapat merumuskan kembali permintaan. Misalnya, pindahkan sebagian permintaan untuk memfilter: dari permintaan "programmer Moskow" Moskow dapat dikeluarkan ke dalam filter menurut kota.
1. Dasar
Sekarang to the point. Pencarian itu sendiri dibagi menjadi dua tahap besar:
- indeksasi (pemrosesan dokumen dan meletakkannya sesuai dengan struktur indeks khusus, sehingga Anda dapat dengan cepat melakukan pencarian itu sendiri),
- cari (menerapkan filter, pencarian Boolean, peringkat, dll.)
1.1. Pengindeksan
Penyimpangan liris sedikit. Selanjutnya saya akan memperkenalkan konsep istilah - karena biasanya memanggil unit minimum pengindeksan dan permintaan. Ini adalah unit yang akan disimpan dalam kamus indeks. Ini dapat berupa kata yang direduksi menjadi bentuk atau basis kata normal, angka, email, huruf n-gram atau yang lainnya. Biasanya, istilah mencakup bidang yang diindeks atau di mana pencarian dilakukan.
Pertama, Anda perlu mengubah dokumen input menjadi seperangkat istilah dan menyaring kata-kata berhenti. Kata-kata tersebut dapat berupa kata-kata yang sering muncul - preposisi, kata sambung, kata seru, dan hal-hal lain, misalnya, karakter khusus yang tidak ingin kami cari. Agar pencarian bekerja dengan bentuk kata yang berbeda, selama proses pengindeksan kami biasanya membawa semua kata ke kondisi dasar. Biasanya salah satu dari dua prosedur digunakan: baik membendung - proses mengisolasi basis kata (development-> development), atau lemmatization - proses membawa kata ke bentuk normal (skill-> skill).
1.2 Struktur Indeks
Cara paling populer untuk merepresentasikan indeks adalah indeks terbalik. Sebenarnya, ini adalah semacam tabel hash, di mana kuncinya adalah istilah, dan nilainya adalah daftar dokumen (biasanya daftar id dokumen yang disebut daftar posting) di mana istilah ini hadir. Biasanya indeks terbalik terdiri dari dua bagian - kamus (istilah kamus) dan daftar dokumen untuk setiap istilah (daftar posting):

Selain itu, indeks dapat berisi informasi tentang posisi istilah dalam dokumen (indeks posisi), yang akan berguna ketika mencari istilah pada jarak tertentu, khususnya dengan permintaan frase, tentang frekuensi istilah, yang akan membantu dalam menentukan peringkat dan membangun rencana permintaan. Tetapi lebih lanjut tentang itu di bawah ini.
1.2.1 Kamus istilah
Kamus menyimpan semua istilah yang ada dalam indeks, dan dirancang untuk dengan cepat menemukan tautan ke daftar dokumen. Ada beberapa opsi untuk menyimpan kamus:
- Tabel hash, di mana istilahnya adalah kuncinya, dan nilainya adalah tautan ke daftar dokumen istilah ini.
- Daftar terurut dimana Anda dapat mencari berdasarkan pencarian biner.
- Pohon awalan (trie).
Cara paling optimal adalah opsi terakhir, karena Ini memiliki beberapa keunggulan. Pertama, pada sejumlah besar istilah, pohon awalan akan menempati lebih sedikit memori, karena bagian berulang awalan akan disimpan hanya sekali. Kedua, kami segera mendapatkan kesempatan untuk membuat permintaan awalan. Dan ketiga, pohon seperti itu dapat dikompresi dengan menggabungkan bagian yang tidak bercabang.
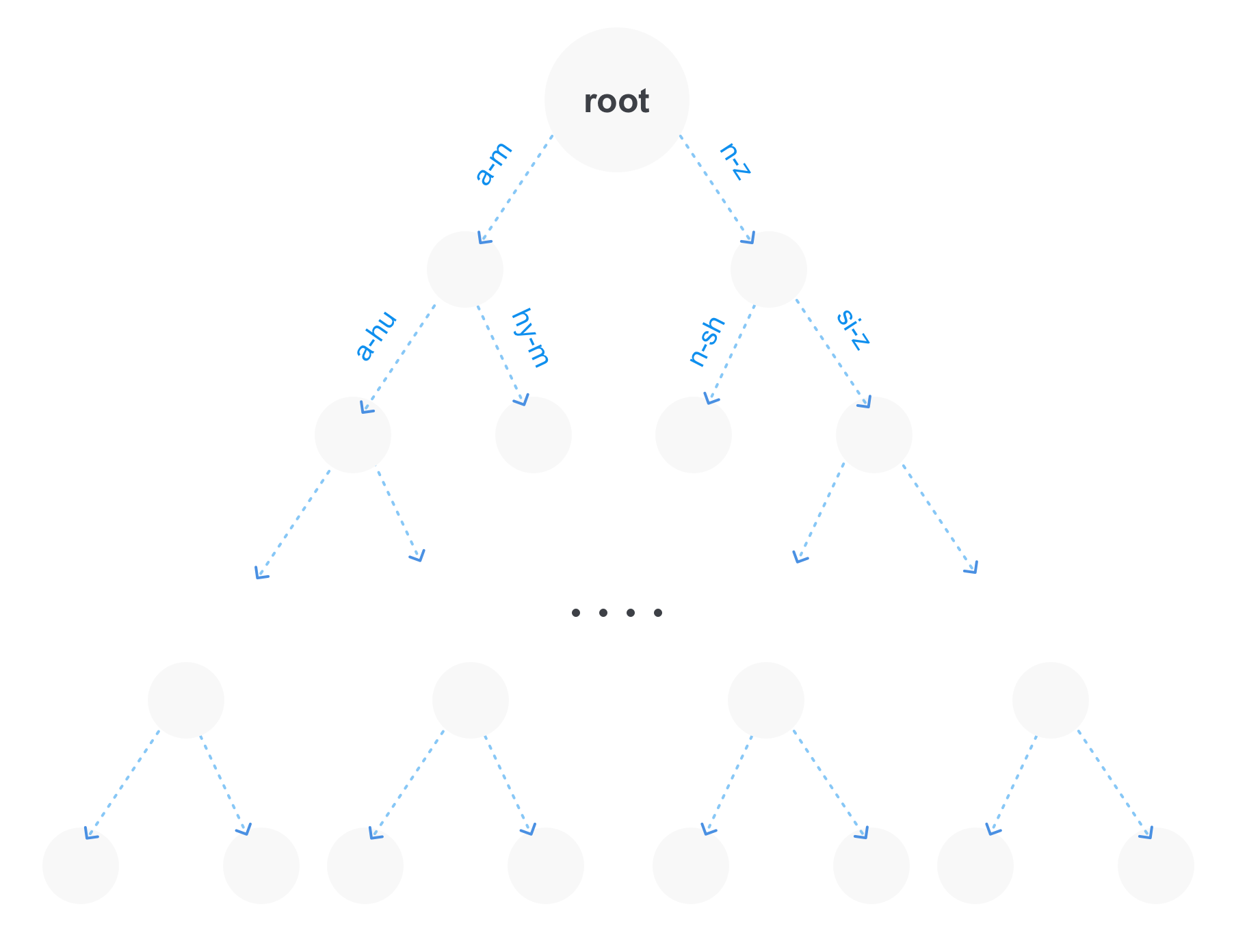
Tentu saja, pohon awalan mungkin bukan satu-satunya struktur untuk menyimpan istilah dalam indeks. Misalnya, pohon sufiks juga mungkin ada di dekatnya, yang pada gilirannya akan lebih optimal untuk kueri dengan pelawak (kueri bentuk po * sql).
1.2.2 Daftar posting
Daftar dokumen adalah daftar pengidentifikasi dokumen yang dipesan, yang memungkinkan dilakukannya beberapa optimasi. Biasanya ia menyimpan dalam dirinya sendiri tidak hanya daftar dokumen di mana istilah tersebut muncul, tetapi juga posisi (posting) di mana ia muncul. Ini memecahkan beberapa masalah sekaligus: kita segera tahu berapa kali suatu kata telah terjadi dalam suatu dokumen, kita dapat membuat frasa dan pertanyaan dengan jarak tertentu di antara istilah, melintasi beberapa daftar dokumen sekaligus, dan melihat posisi istilah tersebut.

Misalnya, dalam daftar ini dengan istilah
scala dalam dokumen ke-6 dalam
judul kata tersebut muncul 4 kali, pada posisi 2, 15, 18 dan 25.
1.2.3 Dokumen dengan berbagai bidang
Sebagian besar dokumen terdiri dari beberapa bidang, setidaknya dari nama dokumen dan tubuhnya. Ini membantu ketika mencari bagian-bagian tertentu dari dokumen dan ketika istilahnya signifikan ketika peringkat (misalnya, istilah yang terjadi dalam judul dapat dianggap lebih signifikan).
Plus, dalam indeks, biasanya tidak hanya bidang teks yang disimpan, tetapi juga tanda-tanda dokumen, beberapa nilai numerik, dll dapat disimpan. Penyimpanan dalam indeks biasanya berupa {field-term}.

Misalnya, jika Anda mengambil lowongan, maka itu akan memiliki beberapa bidang sekaligus: nama, deskripsi, perusahaan, penggajian, kota dan pengalaman yang diperlukan. Ini diperlukan agar pengguna dapat dengan mudah mencari tidak hanya dengan nama dan teks perusahaan, tetapi juga dapat menyaring berdasarkan gaji dan pengalaman, melihat berapa banyak lowongan di kotanya dan di kota-kota tetangga, atau bahkan mencari lowongan untuk perusahaan tertentu.
1.3 Kompresi dan Optimasi Indeks
Kecepatan kerja penting untuk pencarian, oleh karena itu, sebagian besar operasi pencarian indeks biasanya dilakukan dalam RAM. Untuk melakukan ini, sangat penting untuk menerapkan sejumlah optimasi pada indeks, yang akan menyesuaikannya dengan ukuran memori yang terbatas. Selain itu, sejumlah optimasi biasanya diterapkan, yang memungkinkan Anda untuk bergerak di sekitar indeks dengan kecepatan yang lebih tinggi saat mencari, melompati potongan yang tidak perlu.
1.3.1 Kompresi Delta
Karena kita ingat bahwa daftar dokumen berdasarkan istilah (alias postingan daftar) dipesan, ide pertama bagaimana mengompresnya adalah membuat daftar dengan offset id dokumen, bukan daftar dengan dokumen id. Pada daftar spesifik 6 pengidentifikasi, akan terlihat seperti ini:

Jadi, dengan menelusuri daftar, kami akan selalu menghitung pengidentifikasi saat ini dari nilai sebelumnya yang diperoleh. Misalnya, pada offset kedua 3, kita menambahkan nilai pertama 2 dan mendapatkan id 5, ke yang ketiga kita tambahkan 5, dan dapatkan 9 dan seterusnya. Dengan sejumlah besar dokumen, ini bekerja dengan sangat baik, terutama dalam hubungannya dengan metode kompresi lain - merekam nomor format variabel.
1.3.2 VarByte dan VarInt
Ini adalah cara untuk menyimpan setiap item daftar individu dalam memori sehingga membutuhkan ruang minimum. Misalnya, jika tiga offset pertama hanya cocok dalam 1 byte, maka tidak perlu lagi mengambil lebih banyak. Menimbang bahwa daftar kami tidak mengandung dokumen id, tetapi delta, kompresi akan sangat efektif. Dalam representasi angka-angka ini, bit pertama dari setiap byte adalah bendera apakah representasi dari angka saat ini berakhir pada byte ini.

Jika bit pertama dari byte 0 adalah byte terakhir dari angka tersebut, jika 1 tidak.
1.3.3 Daftar Lewati / Tabel lompat
Daftar lewati adalah salah satu struktur untuk dengan cepat menelusuri daftar dokumen istilah tertentu, melewatkan bagian yang tidak perlu dari daftar. Idenya adalah untuk menyimpan tautan ke elemen-elemen yang jauh dari daftar pada disk di depan daftar itu sendiri, karena setelah kompresi kita tidak dapat mengatakan di mana tepatnya dokumen 100 atau 200 akan berada. Sebagai contoh, ini nyaman ketika ada permintaan dua istilah, di mana satu istilah akan sering ditemukan, dan yang kedua, sebaliknya, akan langka, dan daftar dokumen akan dimulai hanya dengan id dokumen ke-200. Kemudian, jika ada daftar dengan pass untuk daftar pertama, kita dapat menghemat waktu untuk bergerak dan langsung melewati blok pengidentifikasi yang tidak perlu.

1.4 Permintaan
1.4.0 Permintaan istilah
Jenis permintaan paling sederhana di mana kita hanya perlu menemukan daftar dokumen yang sesuai dan menerbitkan dokumen yang diurutkan setelah diperingkat.
Sebagai contoh, dengan cara ini kami menemukan daftar posisi untuk
java :

1.4.1 Kueri Boolean (dan, atau, tidak)
Pencarian Boolean adalah salah satu bagian terpenting dalam pencarian informasi yang kami temukan di mana-mana. Seluruh pencarian Boolean didasarkan pada kombinasi dari AND, OR, dan NOT. Misalnya, ketika kita mencari kueri dalam dua kata:
java android , maka sebenarnya, dalam pencarian sederhana, itu akan dikonversi ke
java AND android . Dan ini berarti kami ingin menemukan semua dokumen yang mengandung kedua kata tersebut.
Layak disebutkan bagaimana Anda bergerak di sekitar daftar dokumen. Karena daftar dokumen untuk setiap istilah diurutkan, biasanya ada dua cara untuk menelusuri daftar: berpindah melalui dokumen secara berurutan, meneruskannya satu per satu, atau segera pindah ke dokumen tertentu, melewatkan yang tidak diperlukan (misalnya, ketika daftar pertama jauh lebih kecil , dan kami tidak perlu melalui blok besar dokumen di daftar kedua). Dalam hal ini, pertama-tama kita menggunakan pointer dari skip pointer untuk daftar kedua untuk bergerak sedekat mungkin ke id dokumen yang diinginkan, dan kemudian pindah ke sana secara linear.
Pada saat pencarian, terjadi hal berikut: dalam indeks untuk istilah java dan android adalah daftar dokumen, maka persimpangan dibuat pada mereka - yaitu, kami menemukan dokumen yang mengandung kedua istilah. Dengan pencarian ini, kedua metode untuk menelusuri daftar digunakan untuk persimpangan yang lebih cepat.

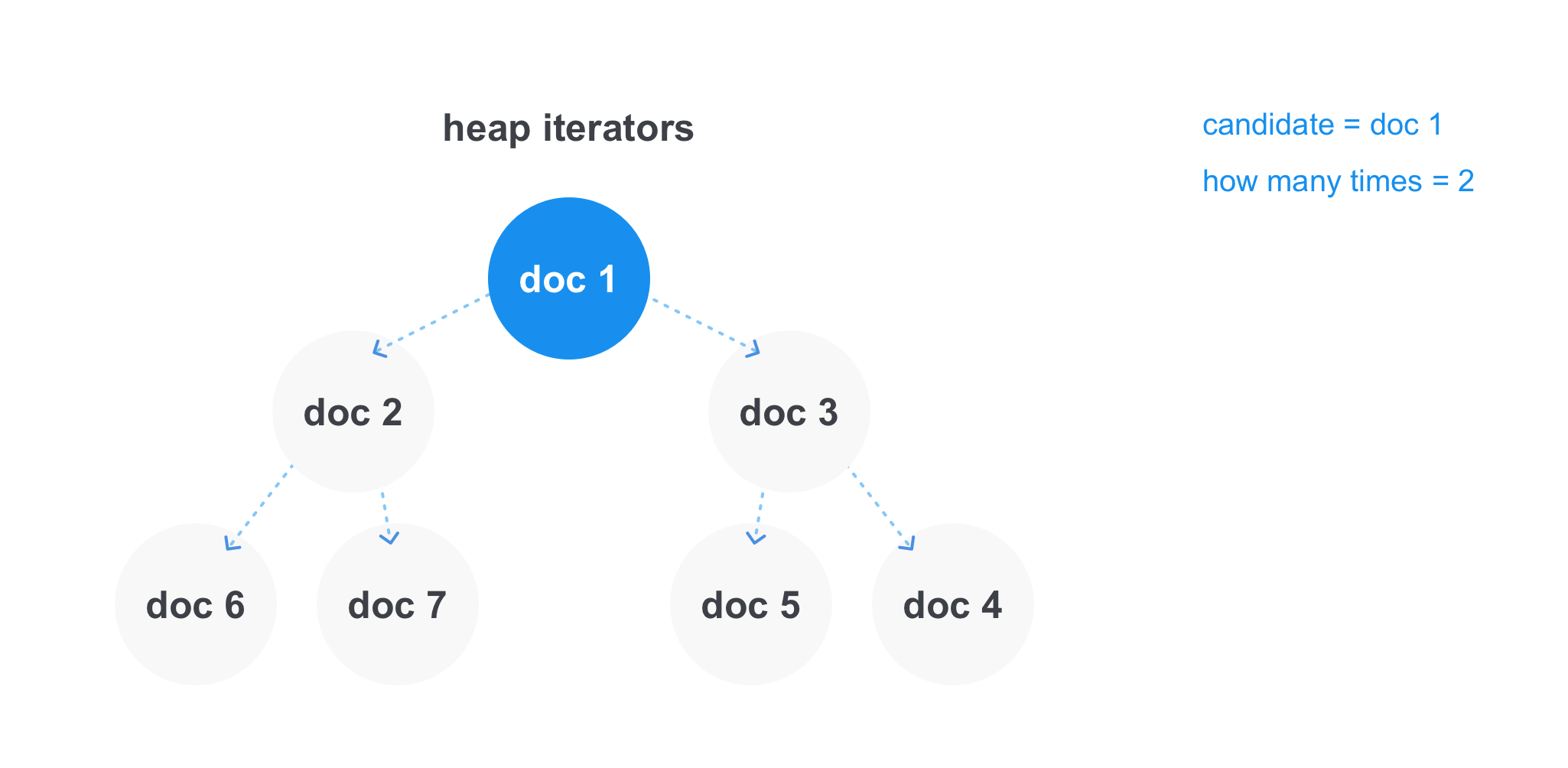
Dengan ATAU kueri dari bentuk java ATAU scala, di mana kita perlu menemukan semua dokumen yang berisi setidaknya satu syarat, situasinya berbeda - di sini kita tidak perlu istilah itu ada di semua daftar dokumen sekaligus. Tetapi ada kueri dengan beberapa operator ATAU, dan kemudian kondisi untuk jumlah kecocokan minimum dapat terjadi, misalnya, mungkin ada kueri java ATAU scala ATAU cotlin ATAU clojure dengan setidaknya dua kecocokan, dan kemudian kita harus memperlihatkan semua dokumen yang mengandung setidaknya dua kata dari kueri .
Dalam hal ini, tumpukan bekerja paling efisien. Kita dapat menyimpan di dalamnya tautan ke setiap daftar dari iterator dan mendapatkan elemen minimum untuk waktu yang konstan. Setelah kami mengambil elemen minimum, kami menghapus iterator dari heap, mengambil langkah maju dan menambahkannya ke heap lagi. Anda dapat secara terpisah menyimpan kandidat saat ini untuk ditambahkan ke hasil dan konter, berapa kali dia bertemu, dan pada saat ketika kandidat akan berbeda dari elemen minimum di heap, lihat apakah kita melewati jumlah minimum kecocokan dalam operasi. Dan tambahkan ke daftar hasil akhir, atau buang dokumen.
1.4.2 Awalan / Pelawak
Terkadang kami ingin menemukan semua dokumen yang berisi kata yang diawali dengan awalan tertentu. Dalam kasus seperti itu, permintaan awalan akan membantu kami, yang akan terlihat seperti
jav * . Permintaan awalan bekerja dengan sangat baik ketika kamus diimplementasikan pada pohon awalan, dan kemudian kita langsung ke sarang awalan dan mengambil semua istilah yang ada di bawah ini.
1.4.3 Kueri pada frasa dan kueri dekat
Ada saat-saat ketika Anda perlu menemukan seluruh frasa, misalnya, "pengembang java", atau menemukan kata-kata di mana tidak akan ada lebih dari beberapa kata, misalnya, "java" dan "pengembang", di antaranya tidak lebih dari 2 kata, sehingga Anda dapat menemukan dokumen yang mengandung pengembang android java kotlin. Untuk ini, daftar posisi kata di setiap dokumen juga digunakan.

Pada saat melintasi daftar dokumen semuanya sama dengan operasi DAN. Tetapi setelah dokumen ditemukan di kedua daftar, pemeriksaan tambahan dilakukan - bahwa persyaratan berada pada jarak yang tepat satu sama lain, dengan perbedaan posisi (posisi).
1.4.4 Rencana Permintaan
Biasanya, sebelum eksekusi permintaan itu sendiri, rencananya dibangun. Ini terjadi untuk mengoptimalkan eksekusi permintaan dan membuat optimasi seperti daftar dengan kelalaian untuk daftar dokumen berfungsi.
Cara termudah untuk mengoptimalkan kueri Anda adalah dengan melintasi daftar dokumen agar ukurannya bertambah. Dengan demikian, kami tidak akan membuang-buang dokumen dari daftar besar yang tidak ada dalam daftar kecil.
Misalnya, mari kita uraikan
kueri Android AND java AND sql . Katakanlah ada 10 dokumen dalam daftar android, dalam sql - 20, dan di java - 100. Dalam hal ini, yang terbaik adalah melewati daftar terkecil terlebih dahulu, dan kueri yang dioptimalkan akan terlihat seperti
(android DAN sql) DAN java .
Dalam kasus OR, yang paling sederhana adalah menghitung jumlah dokumen di persimpangan sebagai jumlah dari dua daftar yang berpotensi berpotongan.
1.4.5 Ekstensi Kueri - Sinonim
Selain apa yang dimasukkan pengguna ke bilah pencarian, biasanya pencarian mencoba memperluas kueri itu sendiri untuk menemukan dokumen yang lebih relevan. Banyak yang dapat digunakan untuk memperluas pencarian: riwayat permintaan pengguna, beberapa data pribadi tentang dia, dan banyak lagi. Namun selain semua ini, ada juga cara universal untuk memperluas permintaan - sinonim.
Dalam hal ini, saat menulis dokumen ke indeks, istilah tersebut diganti dengan "tautan" dalam kamus sinonim:
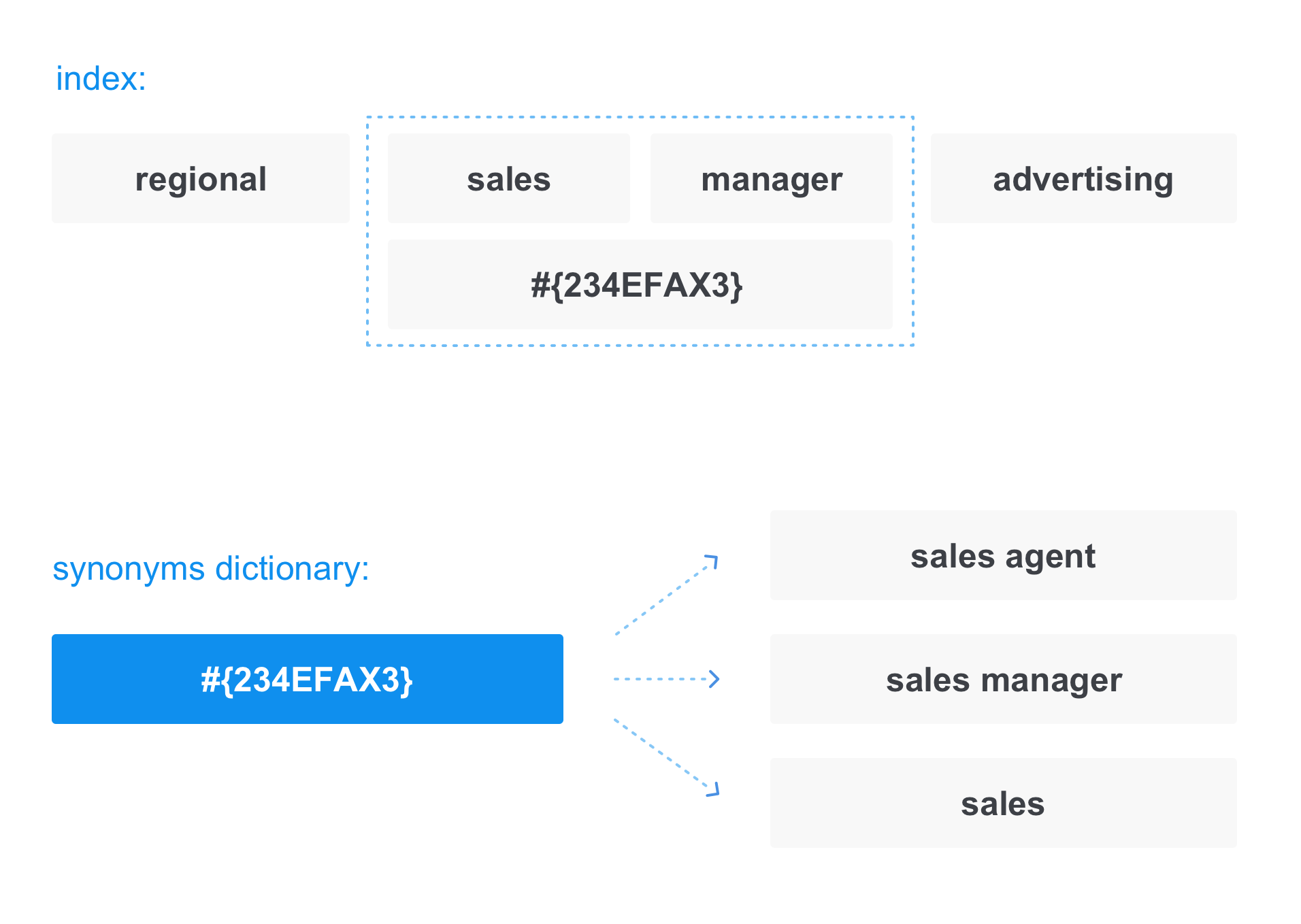
Hal yang sama terjadi ketika mengonversi permintaan. Misalnya, ketika kami meminta
manajer penjualan , permintaan tersebut sebenarnya terlihat seperti:

Dengan demikian, dalam respons kami tidak hanya akan menerima dokumen yang berisi manajer penjualan, tetapi juga yang berisi agen penjualan dan penjualan.
1.5 Penyaringan
1.5.1 Filter rentang cepat
Terkadang kami ingin memfilter sesuatu berdasarkan serangkaian nilai, misalnya berdasarkan pengalaman selama bertahun-tahun. Misalkan kita ingin menemukan semua lowongan dengan pengalaman yang diperlukan dari 3 hingga 11 tahun. Keputusan pertama adalah membuat permintaan dengan semua opsi dari kisaran, menggabungkannya melalui OR. Tetapi masalahnya adalah mungkin ada terlalu banyak nilai. Salah satu cara untuk mengatasi masalah ini adalah mencatat nilai dengan beberapa presisi sekaligus:

Dalam hal ini, kami akan menyimpan 5 nilai akurasi: setahun (kami akan menganggap ini sebagai nilai awal), dua, empat, delapan, dan enam belas.
Kemudian, saat merekam, hal-hal berikut akan terjadi: misalnya, saat merekam dokumen dengan persyaratan pengalaman 6 tahun, kami segera mencatat nilainya dalam semua akurasi:

Saat memfilter “dari 3 hingga 11 tahun”, hal berikut terjadi: kami memilih hanya nilai yang kami butuhkan dalam akurasi yang diperlukan, dan kami hanya mendapatkan 3 nilai alih-alih 8 dan kami mendapatkan kueri
(nilai riil == 3) ATAU (presisi 4 == 4) ATAU (presisi) 4 == 8)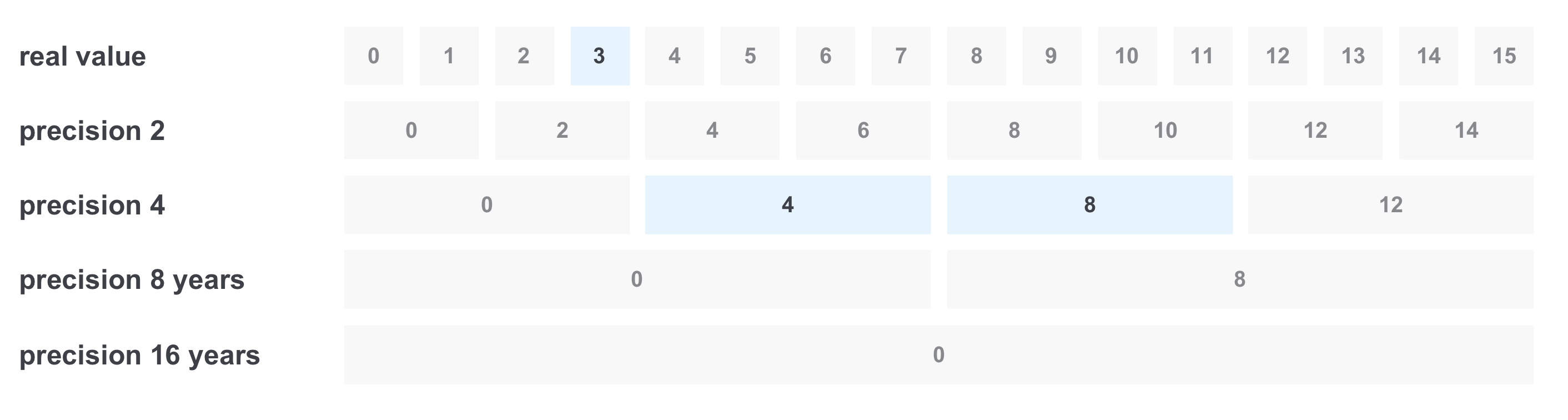
1.5.2 Topeng bit
Topeng bit merupakan bagian integral dari indeks. Penggunaan yang paling penting adalah memfilter dokumen yang dihapus. Ketika Anda menghapus dokumen dari indeks, penghapusan fisik tidak segera terjadi. Struktur khusus ditulis di sebelah indeks, di mana setiap bit berarti id dokumen dalam indeks, dan ketika dihapus, bit dinaikkan, dan selama pencarian, dokumen-dokumen ini disaring dan tidak masuk ke dalam output.
Anda juga dapat menggunakan topeng bit untuk menetapkan izin bagi setiap pengguna ke dokumen tertentu dan untuk meng-cache filter populer individu. Maka biasanya bit mask disimpan secara terpisah dari indeks.
Misalnya, kami memiliki filter populer: kota Moskow, hanya paruh waktu, tanpa pengalaman kerja. Kemudian, sebelum permintaan, kita bisa mendapatkan topeng bit yang sudah disimpan untuk dokumen-dokumen ini, menambahkannya, dan mendapatkan topeng bit terakhir - dokumen mana yang melewati ketiga filter ini, sehingga menghemat waktu dalam pemfilteran.

2. Peringkat
Seperti yang kita ingat, tugas utama pencarian adalah untuk mendapatkan informasi yang paling relevan dalam waktu minimum. Dan dalam hal ini kami akan dibantu oleh pemeringkatan dokumen setelah kami memfilter dokumen berdasarkan permintaan teks dan menerapkan filter dan hak yang diperlukan.
Cara termudah dan termurah untuk melakukan pemeringkatan adalah dengan mengurutkan dokumen berdasarkan tanggal. Dalam beberapa sistem, ini sebelumnya dilakukan, misalnya, dalam berita atau pengumuman real estat, sehingga pengguna pertama kali ditunjukkan dokumen terbaru.
Terkadang model peringkat dengan jumlah kata yang ditemukan dalam dokumen dapat digunakan, misalnya, ketika tidak ada begitu banyak dokumen, dan kami ingin menemukan semua dokumen di mana setidaknya satu dari kata-kata permintaan ditemukan. Dalam hal ini, dokumen-dokumen di mana semua kata dari permintaan atau lebih dari mereka ditemukan akan lebih relevan.
Tentu saja, saat ini, metode-metode ini telah menjadi tidak relevan, dan mereka lebih mungkin dikaitkan dengan sejarah masalah ini.
2.1 TF-IDF
TF-IDF (frekuensi istilah - frekuensi dokumen terbalik) adalah salah satu formula peringkat paling dasar dan paling banyak digunakan. Inti dari rumus ini adalah untuk membuat lebih sedikit istilah yang digunakan di mana-mana, misalnya, preposisi dan interjeksi, dan membuat istilah yang lebih bermakna yang jarang, sehingga menunjukkan dokumen pertama dengan istilah yang lebih jarang dan lebih bermakna dari kueri. Sekarang mari kita pisahkan rumus menjadi beberapa bagian:
TF (istilah frekuensi) adalah frekuensi istilah yang muncul dalam dokumen. Ini dihitung secara sederhana:
Istilah TF `java` = jumlah istilah` java` dalam dokumen / nomor semua istilah dalam dokumen
IDF (frekuensi dokumen terbalik) - kebalikan dari frekuensi kata tersebut muncul dalam kumpulan dokumen. Membantu mengurangi bobot kata yang umum digunakan.
IDF (`java`) = log (jumlah dokumen dalam koleksi / jumlah dokumen di mana terdapat istilah` java`)Selanjutnya, untuk mendapatkan TF-IDF dari istilah java, kita hanya perlu mengalikan nilai TF dan IDF yang diperoleh. , , . , , developer , , java developer .
2.2
, , . , , , .
2.3 BM25 BM*
BM25 (Okapi best match 25) TF-IDF . BM25F, ( ).
2.4
, :
- DFR (divergence from randomness),
- IBS (information-based models),
- LM Dirichlet,
- Jelinek-Mercer.
2.5
, , . ,
.
2.6 Top k
, . , , .
, .
top k .
— . k, k
* . heap. n*log(n) k.
. , , , 10 12, score 10 score . , n — (n*page size) .
3.
3.1
— . , .
, : , , . , . . ( , ). (merge).
, , :

. , , , - .
3.2 (megre)
— . «» — . , , ( ).

, , , . :
4.
, , . , - (, . .). , , , .

4.1
(, hh , ), . .
, , . -, , . -, , , .
4.2
, . , .
, hh,
, , - :
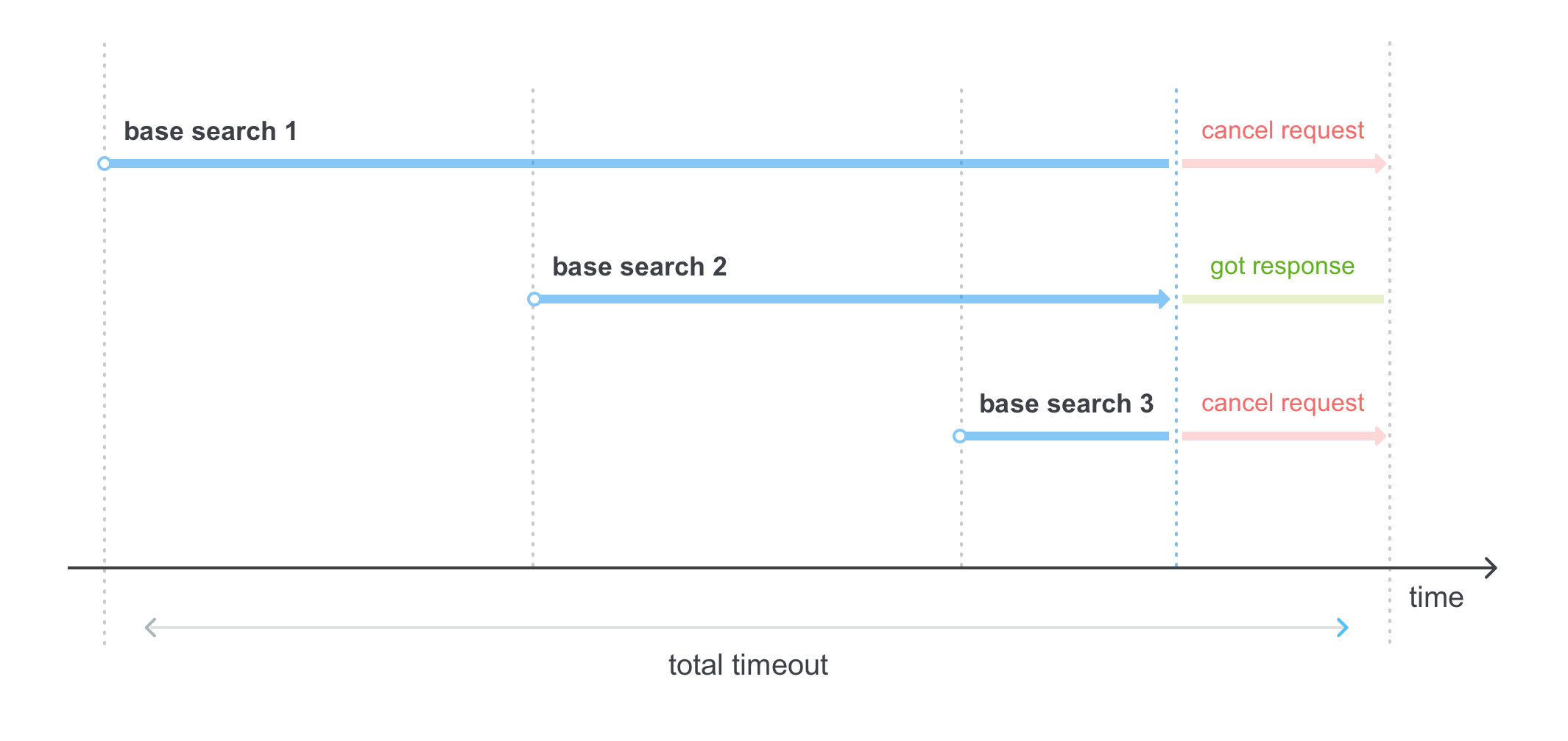
5. …
, , , . , : , , , , , (highlight), . , , , top k .
:
Sekian, terima kasih atas perhatiannya, menarik mendengar komentar dan pertanyaan Anda.PS
Saya ingin mengucapkan terima kasih kepada gdanschin karena membantu saya menulis artikel ini.