Sistem
Anti-Plagiarisme adalah mesin pencari khusus. Seperti layaknya mesin pencari, dengan mesin sendiri dan indeks pencarian. Indeks terbesar kami dalam hal jumlah sumber, tentu saja, di Internet berbahasa Rusia. Sudah lama sekali, kami memutuskan bahwa kami akan memasukkan ke dalam indeks ini semua yang berupa teks (dan bukan gambar, musik atau video), ditulis dalam bahasa Rusia, memiliki ukuran lebih besar dari 1 kb dan bukan "hampir duplikat" dari sesuatu yang sudah ada dalam indeks.
Pendekatan ini baik karena tidak memerlukan pra-pemrosesan yang rumit dan meminimalkan risiko “percikan air anak” - melewatkan dokumen yang berpotensi dipinjam teks. Di sisi lain, sebagai hasilnya, kita hanya tahu sedikit dokumen mana yang akhirnya ada dalam indeks.
Ketika indeks Internet tumbuh - dan sekarang, untuk sesaat, ini sudah lebih dari 300 juta dokumen
hanya dalam bahasa Rusia - muncul pertanyaan yang sangat alami: apakah benar-benar ada banyak dokumen berguna dalam dump ini.
Dan karena kita (
yury_chekhovich dan
Andrey_Khazov ) mengambil refleksi ini, lalu mengapa kita tidak sekaligus menjawab beberapa pertanyaan lagi. Berapa banyak dokumen ilmiah yang diindeks, dan berapa banyak yang tidak ilmiah? Apa bagian dari artikel ilmiah di antara diploma, artikel, abstrak? Apa distribusi dokumen berdasarkan subjek?

Karena kita berbicara tentang ratusan juta dokumen, maka perlu menggunakan sarana analisis data otomatis, khususnya, teknologi pembelajaran mesin. Tentu saja, dalam kebanyakan kasus, kualitas evaluasi ahli lebih unggul daripada metode mesin, tetapi akan terlalu mahal untuk menarik sumber daya manusia untuk menyelesaikan tugas yang begitu luas.
Jadi, kita perlu menyelesaikan dua masalah:
- Buat filter "ilmiah", yang, di satu sisi, memungkinkan Anda untuk secara otomatis membuang dokumen yang tidak ada dalam struktur dan konten, dan di sisi lain menentukan jenis dokumen ilmiah. Segera buat reservasi yang di bawah "ilmiah" sama sekali tidak mengacu pada signifikansi ilmiah atau keandalan hasil. Tugas filter adalah memisahkan dokumen yang berbentuk artikel ilmiah, disertasi, diploma, dll. dari jenis teks lain, yaitu fiksi, artikel jurnalistik, artikel berita, dll.
- Menerapkan suatu alat untuk menggulung dokumen ilmiah yang menghubungkan dokumen dengan salah satu spesialisasi ilmiah (misalnya, Fisika dan Matematika , Ekonomi , Arsitektur , Studi Budaya , dll.).
Pada saat yang sama, kita perlu menyelesaikan masalah ini dengan bekerja secara eksklusif dengan dukungan tekstual dokumen, tidak menggunakan metadata mereka, informasi tentang lokasi blok teks dan gambar di dalam dokumen.
Mari kita ilustrasikan dengan sebuah contoh. Pandangan sekilas saja sudah cukup untuk membedakan
artikel ilmiah
dari, misalnya,
dongeng anak-anak .

Tetapi jika hanya ada lapisan teks (untuk contoh yang sama), Anda harus membaca kontennya.
Filter ilmiah dan penyortiran berdasarkan jenis
Kami menyelesaikan tugas secara berurutan:
- Pada tahap pertama, kami memfilter dokumen non-ilmiah;
- Pada tahap kedua, semua dokumen yang telah diidentifikasi sebagai ilmiah, diklasifikasikan berdasarkan jenis: artikel, disertasi kandidat, abstrak doktoral, diploma, dll.
Itu terlihat seperti ini:
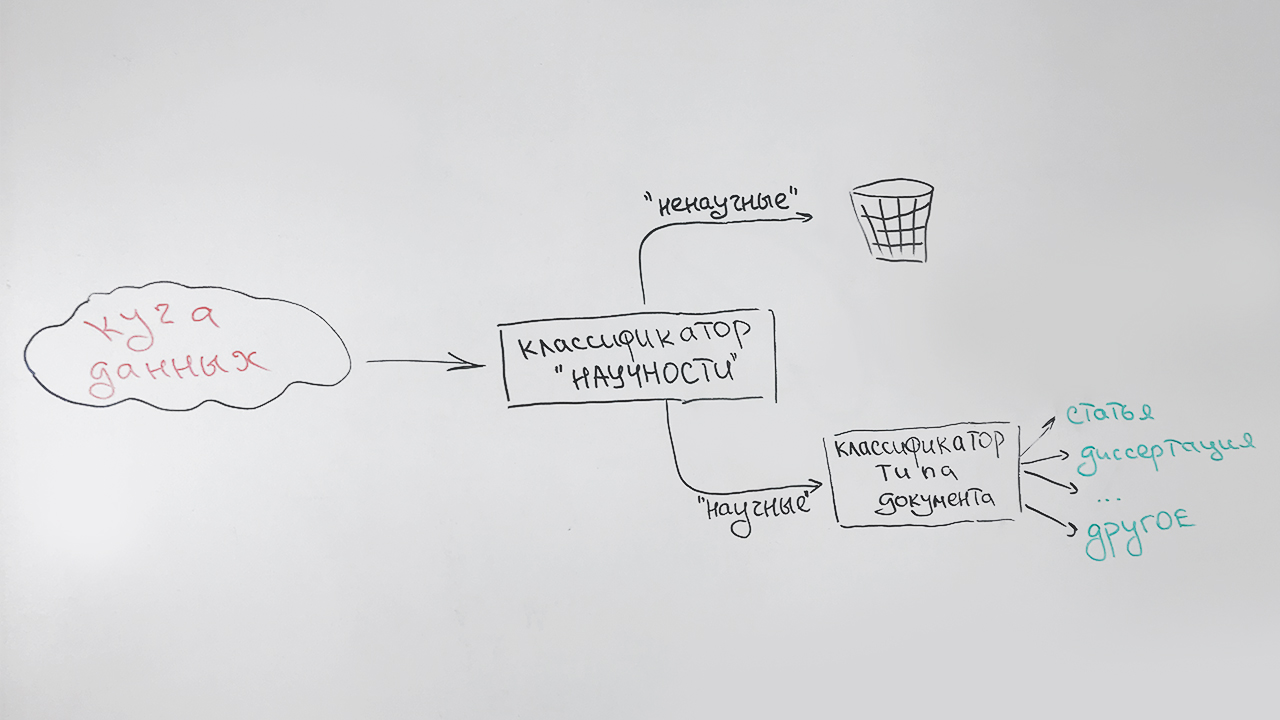
Jenis khusus (tidak terdefinisi) ditugaskan untuk dokumen yang tidak dapat secara andal dikaitkan dengan salah satu jenis (ini terutama dokumen pendek - halaman situs ilmiah, abstrak abstrak). Misalnya, publikasi ini akan dikaitkan dengan jenis ini, yang memiliki beberapa tanda keilmuan, tetapi tidak mirip dengan yang di atas.
Ada keadaan lain yang harus diperhitungkan. Ini adalah algoritma dengan kecepatan tinggi dan kebutuhan sumber daya yang rendah - namun, tugas kami adalah tambahan. Oleh karena itu, kami menggunakan deskripsi indikatif dokumen yang sangat kecil:
- panjang rata-rata kalimat dalam sebuah teks;
- bagian dari kata-kata penghentian dalam kaitannya dengan semua kata dalam teks;
- indeks keterbacaan ;
- persentase tanda baca dalam kaitannya dengan semua karakter teks;
- jumlah kata dari daftar ("abstrak", "disertasi", "diploma", "sertifikasi", "spesialisasi", "monograf", dll.) di bagian awal teks (atribut bertanggung jawab untuk halaman judul);
- jumlah kata dari daftar ("daftar", "literatur", "bibliografi", dll.) di bagian terakhir teks (atribut bertanggung jawab atas daftar literatur);
- proporsi huruf dalam teks;
- panjang kata rata-rata;
- jumlah kata unik dalam teks.
Semua tanda-tanda ini baik karena mereka cepat dihitung. Sebagai pengklasifikasi, kami menggunakan algoritma hutan acak (
Random forest ), metode klasifikasi populer dalam pembelajaran mesin.
Dengan penilaian kualitas tanpa adanya sampel yang ditandai oleh para ahli, sulit, oleh karena itu kami membiarkan penggolong ke dalam koleksi artikel oleh perpustakaan elektronik ilmiah
Elibrary.ru . Kami berasumsi bahwa semua artikel akan diidentifikasi sebagai ilmiah.
Hasil 100%? Tidak ada yang sejenis - hanya 70%. Mungkin kami membuat algoritma yang buruk? Kami melihat-lihat artikel yang difilter. Ternyata banyak teks tidak ilmiah diterbitkan dalam jurnal ilmiah: editorial, selamat atas peringatan, obituari, resep, dan bahkan horoskop. Melihat secara selektif artikel-artikel yang dianggap sebagai klasifikasi ilmiah tidak mengungkapkan kesalahan, oleh karena itu, kami mengakui klasifikasi tersebut sesuai.
Sekarang kita mengambil tugas kedua. Di sini Anda tidak dapat melakukannya tanpa materi berkualitas untuk pelatihan. Kami meminta penilai untuk menyiapkan sampel. Kami mendapatkan sedikit lebih dari 3,5 ribu dokumen dengan distribusi berikut:
| Jenis dokumen | Jumlah dokumen dalam sampel |
|---|
| Artikel | 679 |
| Tesis PhD | 250 |
| Abstrak tesis PhD | 714 |
| Koleksi konferensi ilmiah | 75 |
| Disertasi doktoral | 159 |
| Abstrak disertasi doktoral | 189 |
| Monograf | 107 |
| Panduan belajar | 403 |
| Tesis | 664 |
| Jenis tidak terdefinisi | 514 |
Untuk mengatasi masalah klasifikasi multi-kelas, kami menggunakan hutan Acak yang sama dan fitur yang sama agar tidak menghitung sesuatu yang istimewa.
Kami mendapatkan kualitas klasifikasi berikut:
| Akurasi | Kelengkapan | F-ukur |
|---|
| 81% | 76% | 79% |
Hasil penerapan algoritma terlatih untuk data yang diindeks terlihat dalam diagram di bawah ini. Gambar 1 menunjukkan bahwa lebih dari setengah koleksi terdiri dari dokumen ilmiah, dan di antaranya, lebih dari separuh dokumen adalah artikel.
 Fig. 1. Distribusi dokumen oleh "ilmiah"
Fig. 1. Distribusi dokumen oleh "ilmiah"Gambar 2 menunjukkan distribusi dokumen ilmiah berdasarkan tipe, kecuali tipe “artikel”. Dapat dilihat bahwa jenis dokumen ilmiah kedua yang paling populer adalah buku teks, dan jenis yang paling langka adalah disertasi doktoral.
 Fig. 2. Distribusi dokumen ilmiah lainnya berdasarkan jenis
Fig. 2. Distribusi dokumen ilmiah lainnya berdasarkan jenisSecara umum, hasilnya sesuai dengan harapan. Dari classifier "kasar" cepat kita tidak lagi membutuhkan.
Menentukan subjek suatu dokumen
Kebetulan bahwa pengelompokan karya ilmiah terpadu yang diakui secara universal belum dibuat. Yang paling populer saat ini adalah judul
VAK ,
GRNTI ,
UDC . Untuk jaga-jaga, kami memutuskan untuk mengelompokkan dokumen secara tematis di bawah masing-masing kategori ini.
Untuk membangun classifier tematik, kami menggunakan pendekatan berdasarkan
pemodelan topik , cara statistik membangun model untuk kumpulan dokumen teks, di mana untuk setiap dokumen probabilitas milik topik tertentu ditentukan. Sebagai alat untuk membangun model tematik, kami menggunakan perpustakaan terbuka
BigARTM . Kami telah menggunakan perpustakaan ini sebelumnya dan kami tahu itu sangat bagus untuk pemodelan tematik koleksi besar dokumen teks.
Namun, ada satu kesulitan. Dalam pemodelan tematik, menentukan komposisi dan struktur topik adalah hasil dari penyelesaian masalah pengoptimalan dalam kaitannya dengan kumpulan dokumen tertentu. Kami tidak dapat memengaruhi mereka secara langsung. Tentu saja, tema yang dihasilkan dari penyetelan ke koleksi kami tidak akan sesuai dengan salah satu pengklasifikasi target.
Oleh karena itu, untuk mendapatkan nilai akhir yang tidak diketahui dari rubrik dokumen permintaan tertentu, kita perlu melakukan satu konversi lagi. Untuk melakukan ini, di ruang topik BigARTM, menggunakan algoritma tetangga terdekat (
k-NN ), kami mencari beberapa dokumen yang paling mirip dengan kueri dengan rubrik yang dikenal, dan, berdasarkan ini, kami menetapkan kelas yang paling relevan untuk dokumen kueri.
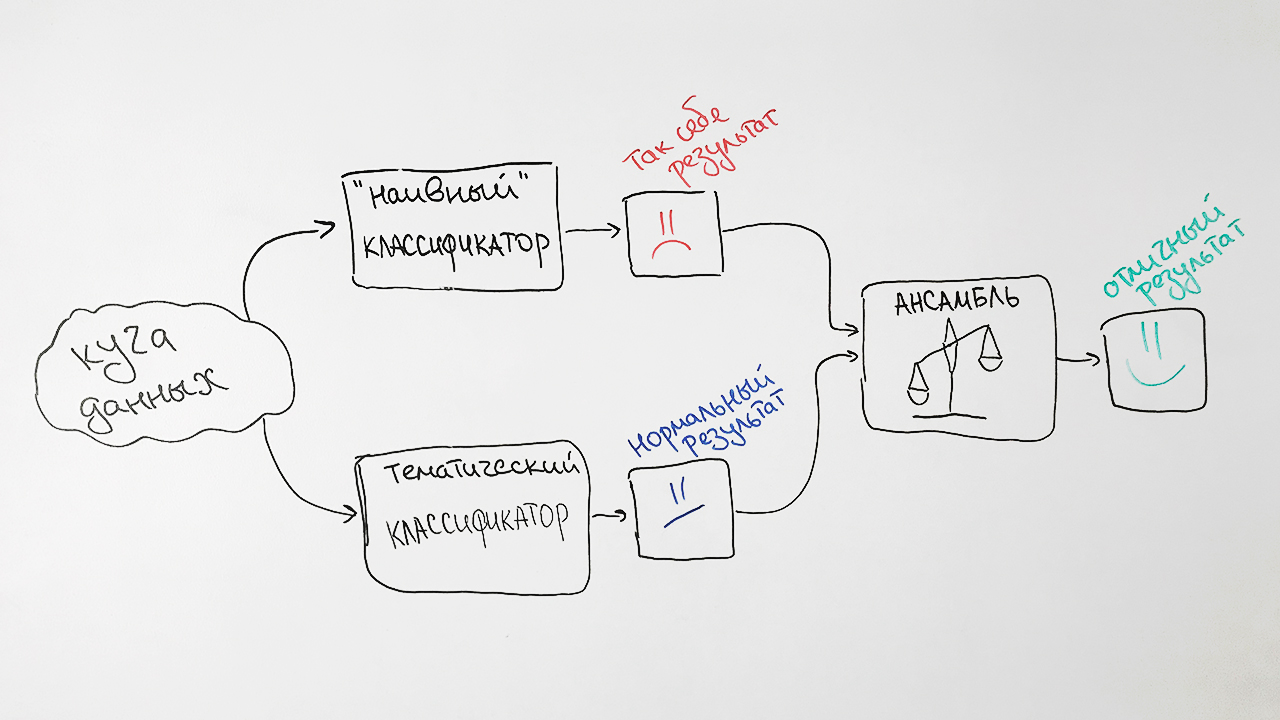
Dalam bentuk yang disederhanakan, algoritme ditunjukkan pada gambar:

Untuk melatih model, kami menggunakan dokumen dari sumber terbuka, serta data yang disediakan oleh Elibrary.ru dengan spesialisasi terkenal dari Komisi Pengesahan Tinggi, SRSTI, UDC. Kami menghapus dari dokumen koleksi yang terkait dengan posisi rubrik yang sangat umum, misalnya,
Masalah umum dan kompleks dari ilmu alam dan eksakta , karena dokumen tersebut akan sangat mengganggu klasifikasi akhir.
Koleksi terakhir berisi sekitar 280 ribu dokumen untuk pelatihan dan 6 ribu dokumen untuk pengujian untuk masing-masing rubrik.
Untuk keperluan kita, cukup bagi kita untuk memprediksi nilai-nilai dari pos tingkat pertama. Misalnya, untuk teks dengan nilai
GRNTI 27.27.24: Fungsi harmonik dan generalisasi mereka, prediksi bagian
27: Matematika benar.
Untuk meningkatkan kualitas dari algoritma yang dikembangkan, kami menambahkan beberapa pendekatan berdasarkan classifier
Naif Bayes tua yang baik. Sebagai tanda, ia menggunakan frekuensi kata-kata yang paling khas untuk setiap dokumen dengan nilai spesifik dari judul HAC.
Kenapa begitu sulit? Sebagai hasilnya, kami mengambil prediksi dari kedua algoritma, menimbangnya dan menghasilkan prediksi rata-rata untuk setiap permintaan. Teknik ini dalam pembelajaran mesin disebut
ensembling . Pendekatan semacam itu memberi kita peningkatan kualitas yang nyata. Misalnya, untuk spesifikasi SRSTI, akurasi algoritma asli adalah 73%, akurasi classifier naif Bayes adalah 65%, dan asosiasi mereka adalah 77%.
Hasilnya, kami mendapatkan skema klasifikasi seperti itu:
Kami mencatat dua faktor yang mempengaruhi hasil pengklasifikasi. Pertama, dokumen apa pun dapat diberikan lebih dari satu nilai rubrik sekaligus. Misalnya, nilai-nilai dari judul Komisi Pengesahan Tinggi 25.00.24 dan 08.00.14 (
Ekonomi ,
sosial dan politik geografi dan
ekonomi Dunia ). Dan itu tidak akan menjadi kesalahan.
Kedua, dalam praktiknya, nilai-nilai rubrik ditempatkan secara ahli, yaitu secara subjektif. Contoh yang mencolok adalah topik yang tampaknya berbeda seperti
Teknik Mesin dan
Pertanian dan Kehutanan . Algoritme kami mengklasifikasikan artikel dengan judul
"Mesin untuk menipiskan hutan" dan
"Prasyarat untuk pengembangan serangkaian traktor berukuran standar untuk kondisi zona barat laut" untuk teknik mesin, dan sesuai dengan tata letak aslinya, mereka merujuk tepatnya ke pertanian.
Oleh karena itu, kami memutuskan untuk menampilkan 3 nilai teratas yang paling mungkin dari masing-masing kategori. Misalnya, untuk artikel
"Toleransi guru profesional (pada contoh aktivitas seorang guru Rusia di sekolah multietnis)", probabilitas nilai-nilai dari judul Komisi Pengesahan Tinggi didistribusikan sebagai berikut:
| Nilai rubrikator | Kemungkinan |
|---|
| Ilmu pedagogis | 47% |
| Ilmu-ilmu psikologi | 33% |
| Ilmu budaya | 20% |
Keakuratan algoritma yang dihasilkan adalah:
| Rubrikator | 3 akurasi teratas |
|---|
| SRSTI | 93% |
| VAK | 92% |
| UDC | 94% |
Diagram menunjukkan hasil studi tentang distribusi topik dokumen dalam indeks Internet berbahasa Rusia untuk semua (Gambar 3) dan hanya untuk dokumen ilmiah (Gambar 4). Dapat dilihat bahwa sebagian besar dokumen berkaitan dengan humaniora: spesifikasi yang paling sering adalah ekonomi, hukum dan pedagogi. Selain itu, di antara hanya dokumen ilmiah, bagiannya bahkan lebih besar.
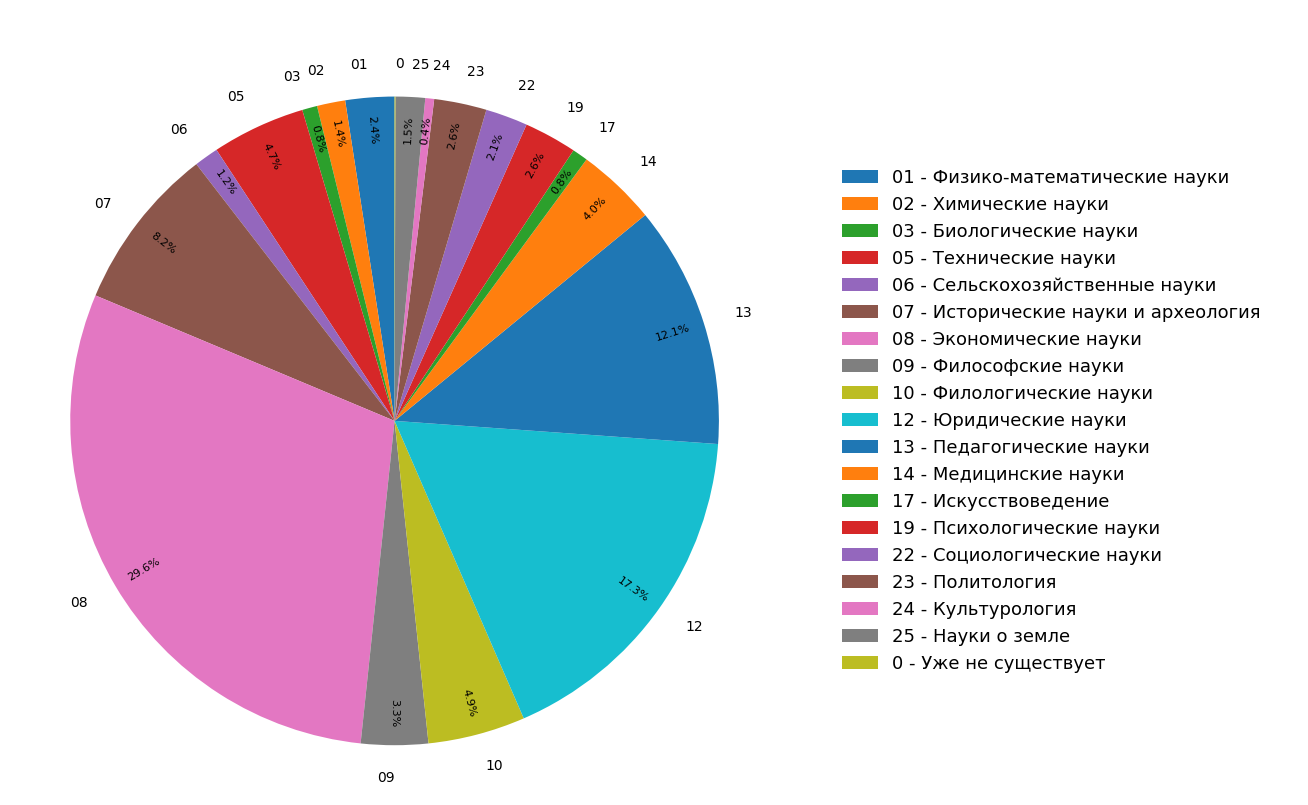 Fig. 3. Distribusi topik di seluruh modul pencarian
Fig. 3. Distribusi topik di seluruh modul pencarian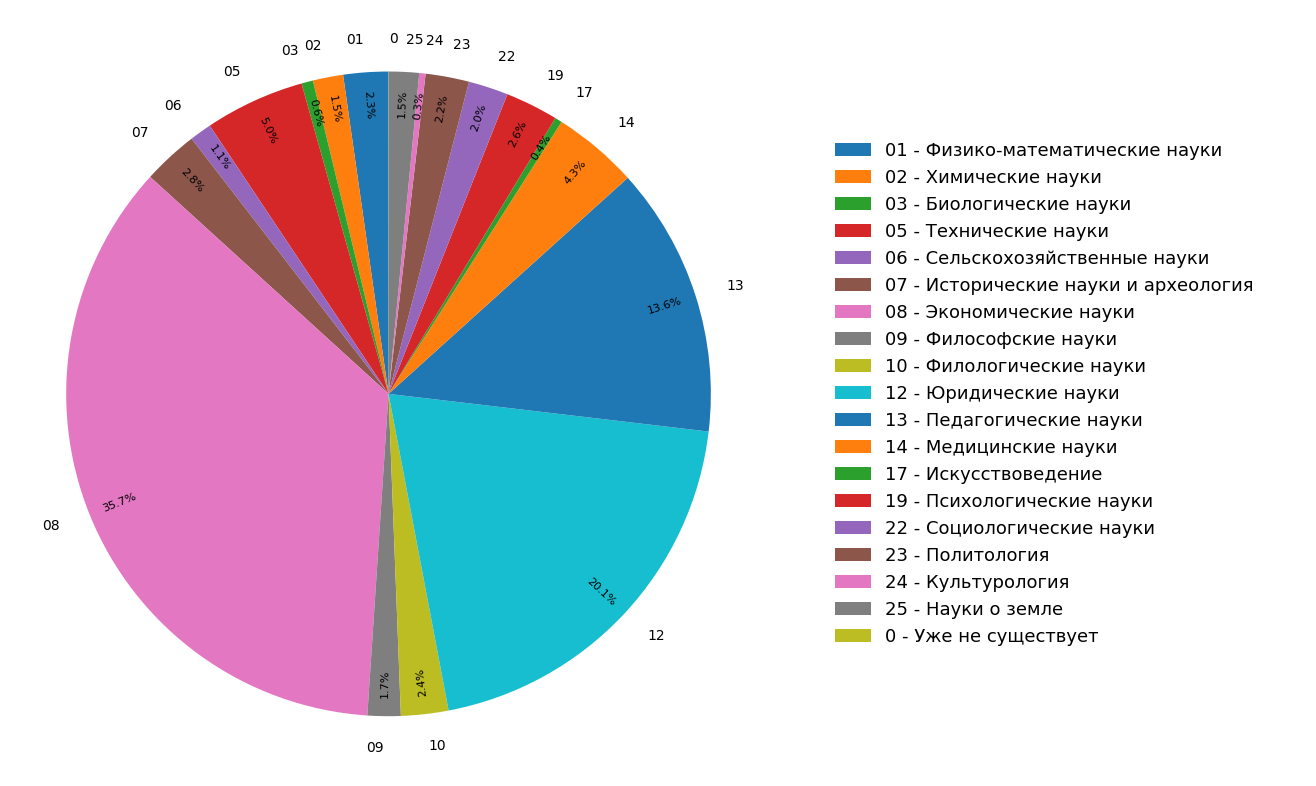 Fig. 4. Distribusi topik dokumen ilmiah.
Fig. 4. Distribusi topik dokumen ilmiah.Sebagai hasilnya, kami benar-benar dari materi yang ada tidak hanya mempelajari struktur tematik dari Internet yang diindeks, tetapi juga membuat fungsionalitas tambahan yang dengannya Anda dapat "mengklasifikasikan" sebuah artikel atau dokumen ilmiah lainnya ke dalam tiga kategori tematis sekaligus.

Fungsi yang dijelaskan di atas sekarang sedang aktif diimplementasikan dalam sistem Anti-Plagiarisme dan akan segera tersedia untuk pengguna.