
Netflix terobsesi dengan ketersediaan layanan. Kami telah memeriksanya di blog kami lebih dari sekali dan memberi tahu bagaimana kami mengelola untuk mencapai tujuan kami. Kami menggunakan pemutus sirkuit, batas konkurensi, pengujian kekacauan, dan banyak lagi. Hari ini kami menghadirkan kepada Anda pendekatan inovatif lain yang secara signifikan meningkatkan stabilitas aplikasi di bawah beban ekstrem dan menghindari kegagalan layanan cascading - batas adaptif untuk koneksi paralel. Tidak ada lagi upaya yang diperlukan untuk menentukan batas-batas koneksi paralel, yang memungkinkan sistem mempertahankan waktu respons yang singkat. Sebagai bagian dari pengumuman ini, kami juga memposting di domain publik perpustakaan Java sederhana dengan kemampuan integrasi untuk servlet, program kontrol, dan gRPC.
Mari kita mulai dengan dasar-dasarnya
Batas koneksi paralel adalah jumlah maksimum permintaan yang dapat diproses oleh sistem pada titik waktu tertentu. Biasanya, jumlah ini tergantung pada sumber daya yang terbatas, seperti kekuatan pemrosesan prosesor pusat. Biasanya, batas koneksi paralel dari suatu sistem dihitung menurut hukum Little, yang terdengar seperti ini: untuk sistem yang stabil, jumlah maksimum koneksi paralel sama dengan produk dari rata-rata waktu yang dihabiskan untuk memproses permintaan dan intensitas rata-rata permintaan yang masuk (L = λW). Setiap permintaan yang melebihi batas koneksi paralel tidak dapat segera diproses oleh sistem, sehingga permintaan tersebut akan antri atau ditolak. Mengantri adalah fungsi penting yang memungkinkan Anda untuk sepenuhnya menggunakan sistem dalam kasus di mana permintaan diterima secara tidak rata dan memerlukan waktu proses yang berbeda.
Jika tidak ada batasan untuk antrian, crash sistem dapat terjadi, misalnya, jika untuk waktu yang lama intensitas permintaan lebih tinggi dari kecepatan pemrosesan mereka. Saat antrian bertambah, demikian juga dengan penundaan, yang mengarah ke waktu tunggu permintaan yang berlebih. Ini berlanjut sampai memori bebas habis, setelah itu sistem crash. Jika Anda tidak melacak peningkatan waktu tunda, itu akan mulai berdampak negatif pada layanan panggilan dan menyebabkan kegagalan sistem kaskade.

Penggunaan batas koneksi paralel adalah praktik standar, tetapi kesulitannya terletak pada menentukannya untuk sistem terdistribusi dinamis yang besar, di mana parameter seperti waktu tunda dan kemungkinan jumlah koneksi paralel terus berubah. Inti dari solusi kami adalah kemampuan untuk secara dinamis menentukan batas koneksi paralel. Batas ini dapat direpresentasikan sebagai jumlah permintaan masuk (dieksekusi secara paralel dan antri) yang dapat diproses oleh sistem hingga kinerjanya mulai berkurang (dan waktu tunda meningkat).
Solusi
Sebelumnya, karyawan Netflix menentukan batas koneksi konkuren manual melalui pengujian dan pembuatan profil kinerja yang memakan waktu. Angka yang dihasilkan benar untuk periode waktu tertentu, tetapi segera topologi sistem mulai berubah karena kegagalan parsial, penskalaan otomatis, atau pengenalan kode tambahan yang memengaruhi waktu tunda. Akibatnya, batas kedaluwarsa. Kami tahu bahwa kami mampu melakukan lebih, bahwa tidak lagi cukup bagi kami untuk hanya menentukan batas koneksi secara statis. Kami membutuhkan cara untuk secara otomatis menentukan batas yang melekat dalam sistem itu sendiri. Pada saat yang sama, kami menginginkan metode ini:
- tidak membutuhkan pekerjaan manual;
- tidak memerlukan koordinasi pusat;
- dapat menentukan batas tanpa informasi tentang perangkat keras atau topologi sistem;
- Diadaptasi untuk perubahan topologi sistem;
- sederhana dalam hal implementasi dan perhitungan yang diperlukan.
Untuk mengatasi masalah ini, kami beralih ke algoritme pelacakan kemacetan TCP yang terbukti. Algoritma ini menentukan jumlah paket data yang dapat ditransmisikan secara paralel (mis., Ukuran jendela overflow) tanpa meningkatkan waktu tunda atau melebihi waktu tunggu. Algoritma ini menggunakan berbagai indikator untuk menentukan batas paket yang dikirimkan secara bersamaan dan mengubah ukuran jendela overflow.

Warna biru pada gambar menunjukkan batas yang tidak diketahui untuk koneksi paralel ke sistem. Pertama, klien mengirim sejumlah kecil permintaan bersamaan, dan kemudian mulai memeriksa sistem secara berkala untuk melihat apakah ia dapat menangani lebih banyak permintaan dengan meningkatkan jendela overflow sampai ini menyebabkan peningkatan penundaan. Ketika penundaan masih meningkat, pengirim memutuskan bahwa ia telah mencapai batas dan sekali lagi mengurangi ukuran jendela melimpah. Pengujian terus menerus atas batas tersebut tercermin dalam grafik yang Anda lihat di atas.
Algoritme kami bergantung pada algoritme pelacakan kemacetan dalam protokol TCP, yang mempertimbangkan hubungan antara waktu tunda minimum (skenario terbaik di mana antrian tidak digunakan) dan waktu tunda, yang diukur secara berkala saat permintaan dieksekusi. Rasio ini memungkinkan untuk menentukan bahwa antrian telah terbentuk yang memicu peningkatan penundaan. Rasio ini memberi kita gradien atau besarnya perubahan waktu tunda:
gradient = (RTTnoload / RTTactual) . Jika nilainya sama dengan satu, maka kami memahami bahwa tidak ada antrian dan batasnya dapat ditingkatkan. Nilai kurang dari satu menunjukkan bahwa antrian penuh dan batas perlu dikurangi. Dengan setiap pengukuran baru waktu tunda, batas disesuaikan berdasarkan rasio di atas, dan dengan itu ukuran antrian yang diijinkan berubah sesuai dengan rumus sederhana ini:
_ = _ × + _
Untuk beberapa iterasi, algoritma menghitung batas yang memungkinkan tidak hanya untuk mempertahankan waktu tunda pada level rendah, tetapi juga untuk membentuk antrian permintaan yang diperlukan jika terjadi wabah aktivitas. Ukuran antrian yang valid dapat dikonfigurasi. Ini digunakan untuk menentukan seberapa cepat batas concurrency dapat meningkat. Sebagai ukuran default, kami memilih akar kuadrat dari nilai batas saat ini. Pilihan ini adalah karena sifat yang berguna dari akar kuadrat: pada nilai yang kecil, itu akan cukup besar dibandingkan dengan batas untuk memastikan pertumbuhan yang cepat, tetapi pada nilai yang besar, sebaliknya, nilai relatifnya akan lebih sedikit, yang akan meningkatkan stabilitas sistem.
Batas adaptif dalam aksi
Batas adaptif di sisi server menolak permintaan berlebihan dan mempertahankan latensi rendah, yang memungkinkan instance sistem melindungi dirinya sendiri dan layanan yang menjadi sandarannya. Sebelumnya, ketika tidak mungkin untuk menolak permintaan yang berlebihan, setiap peningkatan yang stabil dalam jumlah permintaan per detik atau waktu tunda menyebabkan peningkatan yang lebih besar dalam waktu ini dan, pada akhirnya, jatuhnya seluruh sistem. Saat ini, layanan dapat menghilangkan beban kerja yang tidak perlu dan mempertahankan latensi rendah saat bekerja dengan alat stabilisasi lainnya, seperti penskalaan otomatis.
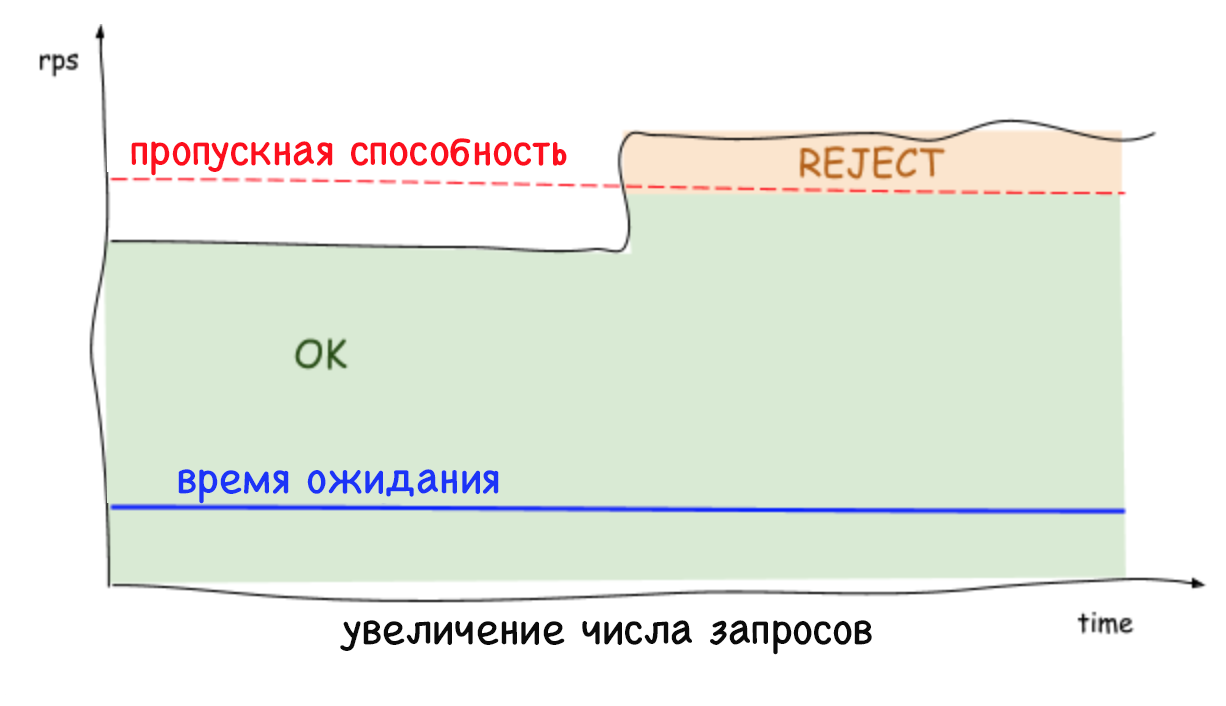
Penting untuk diingat bahwa batasan ditetapkan pada tingkat server (dan tanpa koordinasi apa pun), bahwa lalu lintas ke setiap server dapat turun dan meningkat tajam. Oleh karena itu, tidak mengherankan bahwa batas yang terdeteksi dan jumlah koneksi bersamaan dapat berbeda tergantung pada server. Ini terutama benar dalam lingkungan cloud multi-klien. Akibatnya, situasi dapat muncul ketika satu server kelebihan beban, meskipun sisanya akan gratis. Pada saat yang sama, ketika menyeimbangkan beban di sisi klien, hanya satu permintaan berulang yang akan mencapai server dengan sumber daya gratis di hampir 100% kasus. Dan bukan itu saja: tidak ada lagi alasan untuk khawatir bahwa permintaan berulang akan memicu serangan DDOS, karena layanan dapat dengan cepat (dalam waktu kurang dari satu milidetik) menolak lalu lintas dengan dampak minimal pada kinerja.
Kesimpulan
Penggunaan batas adaptif untuk koneksi paralel menghilangkan kebutuhan untuk menentukan secara manual bagaimana dan dalam hal apa layanan kami harus menolak lalu lintas. Selain itu, ini juga meningkatkan keandalan dan ketersediaan keseluruhan ekosistem layanan-mikro kami.
Kami senang berbagi dengan Anda metode implementasi kami dan integrasi keseluruhan dari solusi ini, yang dapat Anda temukan di perpustakaan umum di
github.com/Netflix/concurrency-limits . Kami berharap bahwa kode kami akan membantu pengguna melindungi layanan mereka dari kegagalan dan masalah dengan meningkatnya latensi, serta meningkatkan ketersediaannya.