
Hai Habr!
Nama saya Alexey Solodky, saya adalah pengembang PHP di Badoo. Dan hari ini saya akan membagikan versi teks dari ceramah saya untuk Pertemuan PHP Badoo pertama. Video tentang ini dan laporan lain dari mitap dapat ditemukan di
sini .
Sistem apa pun yang terdiri dari setidaknya dua komponen (dan jika Anda memiliki PHP dan database, maka ini adalah dua komponen), menghadapi seluruh kelas risiko dalam interaksi antara komponen-komponen ini.
Departemen platform tempat saya bekerja mengintegrasikan layanan internal baru dengan aplikasi kami. Dan menyelesaikan masalah ini, kami telah mengumpulkan pengalaman, yang ingin saya bagikan.
Backend kami adalah monolit PHP yang berinteraksi dengan banyak layanan (saat ini ada sekitar 50 di antaranya). Layanan jarang berinteraksi satu sama lain. Tetapi masalah yang saya bicarakan dalam artikel ini juga relevan untuk arsitektur layanan mikro. Memang, dalam hal ini, layanan berinteraksi sangat aktif satu sama lain, dan semakin banyak interaksi yang Anda miliki, semakin banyak masalah yang Anda miliki.
Pertimbangkan apa yang harus dilakukan ketika layanan macet atau kusam, bagaimana mengatur kumpulan metrik dan apa yang harus dilakukan ketika semua hal di atas tidak menyelamatkan Anda.
Layanan macet
Cepat atau lambat, server tempat layanan Anda diinstal akan jatuh. Itu pasti akan terjadi, dan Anda tidak dapat bertahan melawannya - hanya kurangi kemungkinannya. Anda dapat dikecewakan oleh perangkat keras, jaringan, kode, penerapan yang tidak berhasil - apa pun. Dan semakin banyak server yang Anda miliki, semakin sering ini akan terjadi.
Bagaimana membuat layanan Anda bertahan di dunia di mana server terus-menerus mogok? Pendekatan umum untuk memecahkan kelas masalah ini adalah redundansi.
Redundansi digunakan di mana-mana pada tingkat yang berbeda: dari besi ke seluruh pusat data. Misalnya, RAID1 untuk melindungi dari kegagalan hard drive atau catu daya cadangan untuk server Anda jika terjadi kegagalan yang pertama. Juga, skema ini diterapkan secara luas ke database. Misalnya, Anda dapat menggunakan master-slave untuk ini.
Mari kita pertimbangkan masalah khas dengan redundansi menggunakan skema paling sederhana sebagai contoh:
Aplikasi berkomunikasi secara eksklusif dengan master, sementara di latar belakang, secara tidak sinkron, data ditransfer ke slave. Ketika master crash, kita akan beralih ke slave dan terus bekerja.
Setelah memulihkan master, kita hanya membuat budak baru darinya, dan yang lama berubah menjadi master.
Skema ini sederhana, tetapi bahkan memiliki banyak nuansa karakteristik dari skema yang berlebihan.
Muat
Katakanlah satu server dari contoh di atas dapat menahan sekitar 100k RPS. Sekarang bebannya adalah 60k RPS, dan semuanya bekerja seperti jam.
Namun seiring waktu, beban pada aplikasi, dan karenanya beban pada master, meningkat. Anda mungkin ingin menyeimbangkannya dengan memindahkan sebagian bacaan ke seorang budak.
Terlihat bagus. Menahan beban, server tidak lagi menganggur. Tapi ini ide yang buruk. Penting untuk mengingat mengapa Anda awalnya mengangkat budak - untuk beralih jika terjadi masalah dengan yang utama. Jika Anda mulai memuat kedua server, maka ketika master Anda crash - dan cepat atau lambat crash - Anda harus mengalihkan lalu lintas utama dari master ke server cadangan, dan itu sudah dimuat. Kelebihan seperti itu akan membuat sistem Anda sangat lambat, atau sepenuhnya menonaktifkannya.
Data
Masalah utama saat menambahkan toleransi kesalahan ke layanan adalah keadaan setempat. Jika layanan Anda tidak memiliki kewarganegaraan, mis. Tidak menyimpan data yang dapat berubah, maka mengubah skala itu tidak menimbulkan masalah. Kami hanya meningkatkan sebanyak contoh yang kami butuhkan dan menyeimbangkan permintaan di antara mereka.
Jika layanan ini stateful, kami tidak dapat melakukan ini lagi. Anda perlu memikirkan cara menyimpan data yang sama di semua mesin virtual layanan kami sehingga tetap konsisten.
Untuk mengatasi masalah ini, salah satu dari dua pendekatan digunakan: replikasi sinkron atau asinkron. Dalam kasus umum, saya menyarankan Anda untuk menggunakan opsi asinkron, karena umumnya lebih mudah dan lebih cepat untuk menulis, dan, sesuai dengan keadaan, lihat apakah Anda perlu beralih ke sinkron.
Nuansa penting untuk dipertimbangkan ketika bekerja dengan replikasi asinkron adalah
konsistensi akhirnya . Ini berarti bahwa pada titik waktu tertentu pada budak yang berbeda, data dapat tertinggal di belakang master dengan interval waktu yang tidak terduga dan berbeda.
Oleh karena itu, Anda tidak dapat membaca data setiap kali dari server acak, karena jawaban yang berbeda dapat datang ke permintaan pengguna yang sama. Untuk mengatasi masalah ini, mekanisme
sesi lengket digunakan , yang memastikan bahwa semua permintaan dari satu pengguna masuk ke satu instance.
Keuntungan dari pendekatan sinkron adalah bahwa data selalu dalam keadaan konsisten, dan risiko kehilangan data lebih rendah (karena dianggap dicatat hanya setelah semua server melakukannya). Namun, Anda harus membayar untuk ini dengan kecepatan tulis dan kompleksitas sistem itu sendiri (misalnya, berbagai algoritma kuorum untuk perlindungan terhadap
split-brain ).
Kesimpulan
- Cadangan. Jika data itu sendiri dan ketersediaan layanan tertentu penting, maka pastikan bahwa layanan Anda akan selamat dari kejatuhan mesin tertentu.
- Saat menghitung beban, pertimbangkan jatuhnya beberapa server. Jika cluster Anda memiliki empat server, pastikan bahwa ketika satu jatuh, tiga yang tersisa akan menarik beban.
- Pilih jenis replikasi tergantung pada tugas.
- Jangan menaruh semua telur Anda dalam satu keranjang. Pastikan server Anda terpisah cukup jauh. Tergantung pada kekritisan ketersediaan layanan, server Anda dapat berada di rak yang berbeda di satu pusat data, atau di pusat data yang berbeda di berbagai negara. Itu semua tergantung pada seberapa besar bencana global yang Anda inginkan dan siap untuk bertahan hidup.
Layanan Diam
Pada titik tertentu, layanan Anda mungkin mulai bekerja sangat lambat. Masalah ini dapat terjadi karena berbagai alasan: beban berlebihan, keterlambatan jaringan, masalah perangkat keras, atau kesalahan kode. Sepertinya masalah yang tidak terlalu mengerikan, tetapi sebenarnya itu lebih berbahaya dari yang terlihat.
Bayangkan: pengguna meminta halaman. Kami secara simultan dan berurutan mengakses keempat setan untuk menggambarnya. Mereka merespons dengan cepat, semuanya bekerja dengan baik.
Misalkan kasus ini ditangani menggunakan nginx dengan jumlah tetap pekerja PHP FPM (dengan sepuluh, misalnya). Jika setiap permintaan diproses kurang lebih 20 ms, maka dengan bantuan perhitungan sederhana dapat dipahami bahwa sistem kami mampu memproses sekitar lima ratus permintaan per detik.
Apa yang terjadi ketika salah satu dari empat layanan ini mulai tumpul, dan pemrosesan permintaan untuk itu meningkat dari 20 ms menjadi habisnya 1000 ms? Penting untuk diingat bahwa ketika kita bekerja dengan jaringan, penundaannya bisa sangat besar. Oleh karena itu, Anda harus selalu menetapkan batas waktu (dalam hal ini, sama dengan satu detik).
Ternyata backend dipaksa untuk menunggu batas waktu berakhir dan menerima dan memproses kesalahan dari daemon. Ini berarti bahwa pengguna menerima halaman dalam satu detik, bukan sepuluh milidetik. Lambat, tapi tidak fatal.
Tapi apa masalah sebenarnya di sini? Faktanya adalah ketika kita meminta setiap permintaan diproses per detik, throughputnya secara tragis turun menjadi sepuluh permintaan per detik. Dan pengguna kesebelas tidak akan lagi bisa mendapatkan respons, bahkan jika ia meminta halaman yang sama sekali tidak terkait dengan layanan yang membosankan. Hanya karena kesepuluh pekerja sedang menunggu batas waktu, dan tidak dapat memproses permintaan baru.
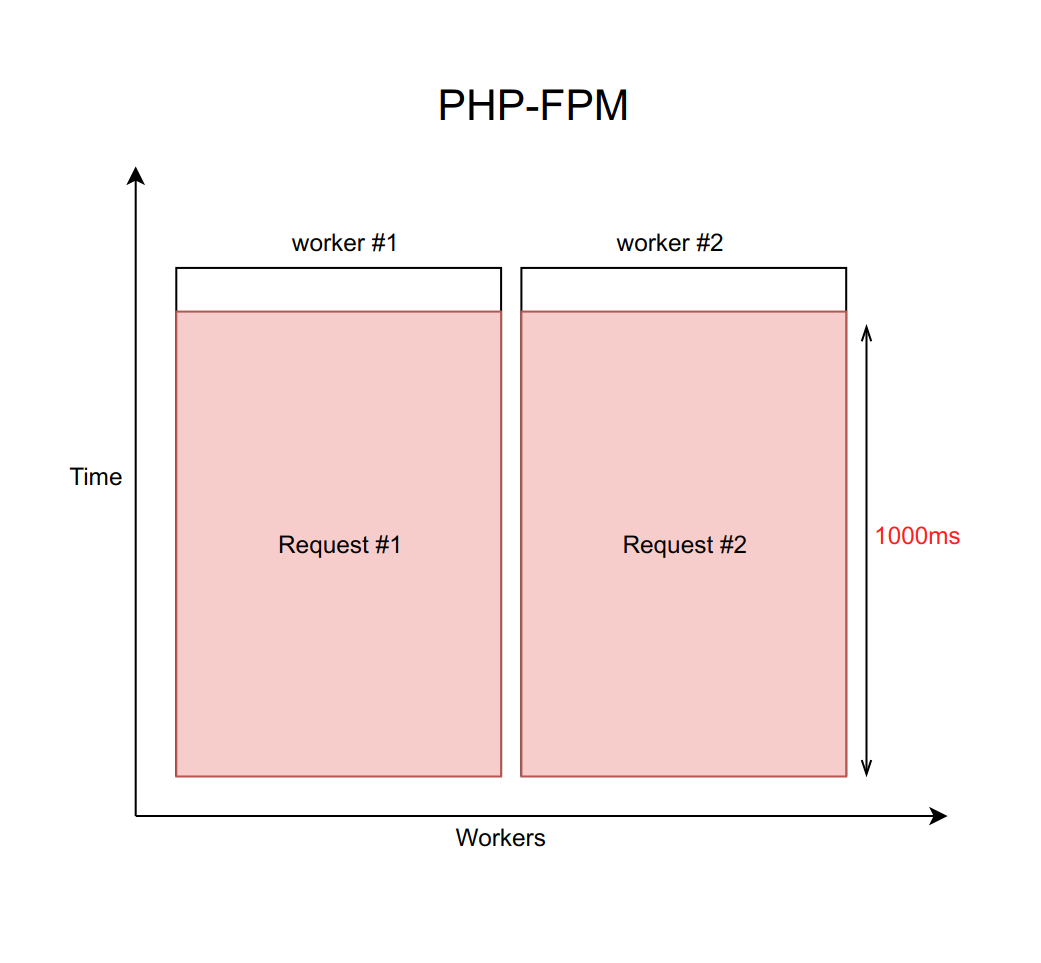
Penting untuk dipahami bahwa masalah ini tidak dapat diselesaikan dengan menambah jumlah pekerja. Bagaimanapun, setiap pekerja memerlukan sejumlah RAM untuk pekerjaannya, bahkan jika dia tidak melakukan pekerjaan nyata, tetapi hanya menunggu untuk waktu tunggu. Karena itu, jika Anda tidak membatasi jumlah pekerja sesuai dengan kemampuan server Anda, maka meningkatkan lebih banyak pekerja baru akan menempatkan seluruh server. Kasus ini adalah contoh kegagalan cascading, ketika jatuhnya salah satu layanan, bahkan jika tidak kritis untuk pengguna, menyebabkan kegagalan seluruh sistem.
Solusi
Ada pola yang disebut
circuit breaker . Tugasnya cukup sederhana: suatu saat ia harus mengurangi layanan yang membosankan. Untuk ini, proxy ditempatkan antara layanan dan pekerja. Ini bisa berupa kode PHP dengan penyimpanan atau daemon di host lokal. Penting untuk dicatat bahwa jika Anda memiliki beberapa instance (layanan Anda direplikasi), maka proxy ini harus secara terpisah melacak masing-masing.
Kami telah menulis implementasi pola ini. Tetapi bukan karena kami suka menulis kode, tetapi karena ketika kami memecahkan masalah ini bertahun-tahun yang lalu, tidak ada solusi yang siap pakai.
Sekarang saya akan menjabarkan secara umum tentang implementasi kami dan bagaimana hal ini membantu untuk menghindari masalah ini. Dan lebih banyak tentang dia dan perbedaannya dari solusi lain dapat didengar
dalam sebuah laporan oleh Mikhail Kurmaev tentang Highload Siberia pada akhir Juni. Transkrip laporannya juga akan ada di blog ini.
Itu terlihat seperti ini:
Ada layanan Sphinx abstrak, yang dihadapi oleh pemutus sirkuit. Pemutus sirkuit menyimpan jumlah koneksi aktif ke daemon tertentu. Segera setelah nilai ini mencapai ambang batas, yang kami tetapkan sebagai persentase dari pekerja FPM yang tersedia di mesin, kami percaya bahwa layanan mulai melambat. Setelah mencapai ambang pertama, kami mengirim pemberitahuan kepada orang yang bertanggung jawab atas layanan ini. Situasi seperti itu merupakan tanda bahwa batas perlu ditinjau, atau pertanda masalah dengan kebodohan.
Jika situasinya memburuk, dan jumlah pekerja yang menghambat mencapai nilai ambang kedua - dalam produksi kami sekitar 10% - kami benar-benar mengurangi host ini. Lebih tepatnya, layanan ini sebenarnya terus berfungsi, tetapi kami berhenti mengirimkan permintaan kepadanya. Browser Sirkuit menolak mereka dan segera memberi pekerja kesalahan, seolah-olah layanan itu bohong.
Dari waktu ke waktu, kami secara otomatis melompati permintaan dari seorang pekerja untuk melihat apakah layanan tersebut menjadi hidup. Jika dia menjawab dengan memadai, maka kita kembali memasukkannya ke dalam pekerjaan.
Semua ini dilakukan untuk mengurangi situasi ke skema replikasi sebelumnya. Alih-alih menunggu sebentar sebelum menyadari bahwa host tidak tersedia, kami segera mendapatkan kesalahan dan pergi ke host cadangan.
Implementasi
Untungnya, Open Source tidak berhenti, dan hari ini Anda dapat mengambil solusi turnkey di Github.
Ada dua pendekatan utama untuk mengimplementasikan pemutus sirkuit: pustaka tingkat kode, dan daemon mandiri yang proksi permintaan melalui dirinya sendiri.
Opsi dengan perpustakaan lebih cocok jika Anda memiliki satu monolit utama di PHP, yang berinteraksi dengan beberapa layanan, dan layanan tersebut hampir tidak saling berkomunikasi. Berikut adalah beberapa implementasi yang tersedia:
Jika Anda memiliki banyak layanan dalam bahasa yang berbeda, dan mereka semua berinteraksi satu sama lain, maka opsi di tingkat kode harus diduplikasi dalam semua bahasa ini. Ini tidak nyaman dalam dukungan, dan pada akhirnya mengarah pada perbedaan dalam implementasi.
Memasukkan satu daemon dalam kasus ini jauh lebih mudah. Dalam hal ini, Anda tidak perlu mengedit kode secara khusus. Setan berusaha membuat interaksi transparan. Namun, opsi ini
jauh lebih rumit secara arsitektur .
Berikut adalah beberapa opsi (fungsinya lebih kaya di sana, tetapi ada pemutus sirkuit juga):
Kesimpulan
- Jangan mengandalkan jaringan.
- Semua permintaan jaringan harus memiliki batas waktu, karena jaringan dapat memberikan waktu yang sangat lama.
- Gunakan pemutus sirkuit jika Anda ingin menghindari aplikasi runtuh karena fakta bahwa satu layanan kecil melambat.
Pemantauan dan telemetri
Apa yang diberikannya
- Prediktabilitas. Penting untuk memperkirakan apa muatannya dan berapa dalam satu bulan untuk meningkatkan jumlah layanan secara tepat waktu. Ini terutama benar jika Anda berurusan dengan infrastruktur besi, karena memesan server baru membutuhkan waktu.
- Investigasi insiden. Cepat atau lambat, sesuatu akan salah, dan Anda harus menyelidikinya. Dan penting untuk memiliki data yang cukup untuk memahami masalah dan dapat mencegah situasi seperti itu di masa depan.
- Pencegahan kecelakaan. Idealnya, Anda harus memahami pola mana yang menyebabkan crash. Penting untuk melacak pola-pola ini dan memberi tahu tim tentang hal itu secara tepat waktu.
Apa yang diukur
Metrik integrasiKarena kita berbicara tentang interaksi antara layanan, kami memantau segala sesuatu yang mungkin terkait dengan komunikasi layanan dengan aplikasi. Sebagai contoh:
- jumlah permintaan;
- meminta waktu pemrosesan (termasuk persentil);
- jumlah kesalahan logika;
- jumlah kesalahan sistem.
Penting untuk membedakan kesalahan logika dari kesalahan sistem. Jika layanan jatuh, ini adalah situasi biasa: kami cukup beralih ke yang kedua. Tapi itu tidak terlalu menakutkan. Jika Anda memulai beberapa jenis kesalahan logika, misalnya, data aneh masuk ke layanan atau meninggalkannya, maka ini sudah perlu diselidiki. Kemungkinan besar, kesalahan terkait dengan bug dalam kode. Dia sendiri tidak akan lulus.
Metrik internalSecara default, layanan ini adalah kotak hitam yang melakukan tugasnya dengan tidak dapat dimengerti. Masih diinginkan untuk memahami dan mengumpulkan data maksimum yang dapat diberikan layanan. Jika layanan adalah basis data khusus yang menyimpan beberapa data dari logika bisnis Anda, catat dengan tepat berapa banyak data, tipe apa itu, dan metrik konten lainnya. Jika Anda memiliki interaksi yang tidak sinkron, penting juga untuk memantau antrian di mana layanan Anda berkomunikasi: kecepatan kedatangan dan keberangkatan mereka, waktu pada tahap yang berbeda (jika Anda memiliki beberapa titik perantara), jumlah acara dalam antrian.
Mari kita lihat metrik apa yang dapat dikumpulkan menggunakan memcached sebagai contoh:
- rasio hit / miss;
- waktu respons untuk berbagai operasi;
- RPS dari berbagai operasi;
- penguraian data yang sama pada kunci yang berbeda;
- kunci yang dimuat atas;
- semua metrik internal yang diberikan oleh perintah statistik.
Bagaimana cara melakukannya
Jika Anda memiliki perusahaan kecil, proyek kecil, dan beberapa server, maka itu adalah solusi yang baik untuk menghubungkan semacam SaaS untuk pengumpulan dan melihat - lebih mudah dan lebih murah. Dalam hal ini, biasanya SaaS memiliki fungsi yang luas, dan tidak perlu khawatir tentang banyak hal. Contoh layanan tersebut:
Atau, Anda selalu dapat menginstal Zabbix, Grafana, atau solusi self-host lainnya di mesin Anda sendiri.
Kesimpulan
- Kumpulkan semua metrik yang Anda bisa. Data tidak berlebihan. Ketika Anda harus menyelidiki sesuatu, Anda akan mengucapkan terima kasih atas pemikiran Anda.
- Jangan lupakan interaksi asinkron. Jika Anda memiliki garis yang mencapai secara bertahap, penting untuk memahami seberapa cepat mereka mencapai, apa yang terjadi pada acara Anda di persimpangan antara layanan.
- Jika Anda menulis layanan Anda, ajarkan untuk memberikan statistik tentang pekerjaan. Bagian dari data dapat diukur pada lapisan integrasi ketika kita berkomunikasi dengan layanan ini. Sisa layanan harus dapat memberikan statistik sesuai dengan perintah kondisional. Misalnya, di semua layanan kami di Go, fungsi ini standar.
- Kustomisasi pemicu. Bagan itu bagus, tetapi hanya saat Anda melihatnya. Penting bahwa Anda memiliki sistem khusus yang akan memberi tahu Anda jika ada masalah.
Memento mori
Dan sekarang sedikit tentang hal-hal yang menyedihkan. Anda mungkin merasa bahwa di atas adalah obat mujarab, dan sekarang tidak ada yang akan jatuh. Tetapi meskipun Anda menerapkan semua yang dijelaskan di atas, bagaimanapun, sesuatu akan pernah jatuh. Penting untuk mempertimbangkan ini.
Banyak alasan untuk jatuh. Misalnya, Anda mungkin memilih skema replikasi paranoid yang tidak cukup. Meteorit jatuh di pusat data Anda, dan kemudian di yang kedua. Atau Anda hanya menggunakan kode dengan kesalahan rumit yang muncul tiba-tiba.
Misalnya, di Badoo ada halaman "Orang-orang terdekat." Di sana, pengguna mencari orang lain di dekatnya untuk mengobrol dengan mereka.

Sekarang, untuk merender halaman, backend melakukan panggilan sinkron ke sekitar tujuh layanan. Untuk kejelasan, kurangi angka ini menjadi dua. Satu layanan bertanggung jawab untuk memberikan blok pusat dengan foto. Yang kedua adalah untuk blok iklan di kiri bawah. Mereka yang ingin menjadi lebih terlihat bisa sampai di sana. Jika kami memiliki layanan yang menampilkan iklan ini, blok itu hilang begitu saja.

Sebagian besar pengguna bahkan tidak tahu tentang fakta ini: tim kami merespons dengan cepat, dan segera blok itu muncul kembali.
Tetapi tidak setiap fungsionalitas dapat kita hapus dengan tenang. Jika kami kehilangan layanan yang bertanggung jawab untuk bagian tengah halaman, ini tidak akan berhasil disembunyikan. Karena itu, penting untuk memberi tahu pengguna dalam bahasanya apa yang terjadi.

Juga diharapkan bahwa kegagalan satu layanan tidak menyebabkan kegagalan berjenjang. Untuk setiap layanan, kode harus ditulis yang menangani kejatuhannya, jika tidak aplikasi akan macet secara keseluruhan.
Tapi itu belum semuanya. Terkadang sesuatu jatuh, tanpanya Anda tidak bisa hidup sama sekali dengan cara apa pun. Misalnya, pusat data atau layanan sesi pusat. Penting untuk menyelesaikannya dengan benar dan menunjukkan kepada pengguna sesuatu yang memadai, entah bagaimana menghiburnya, untuk mengatakan bahwa semuanya terkendali. Pada saat yang sama, penting bahwa semuanya benar-benar terkendali, dan monitor diberitahu tentang masalah tersebut.
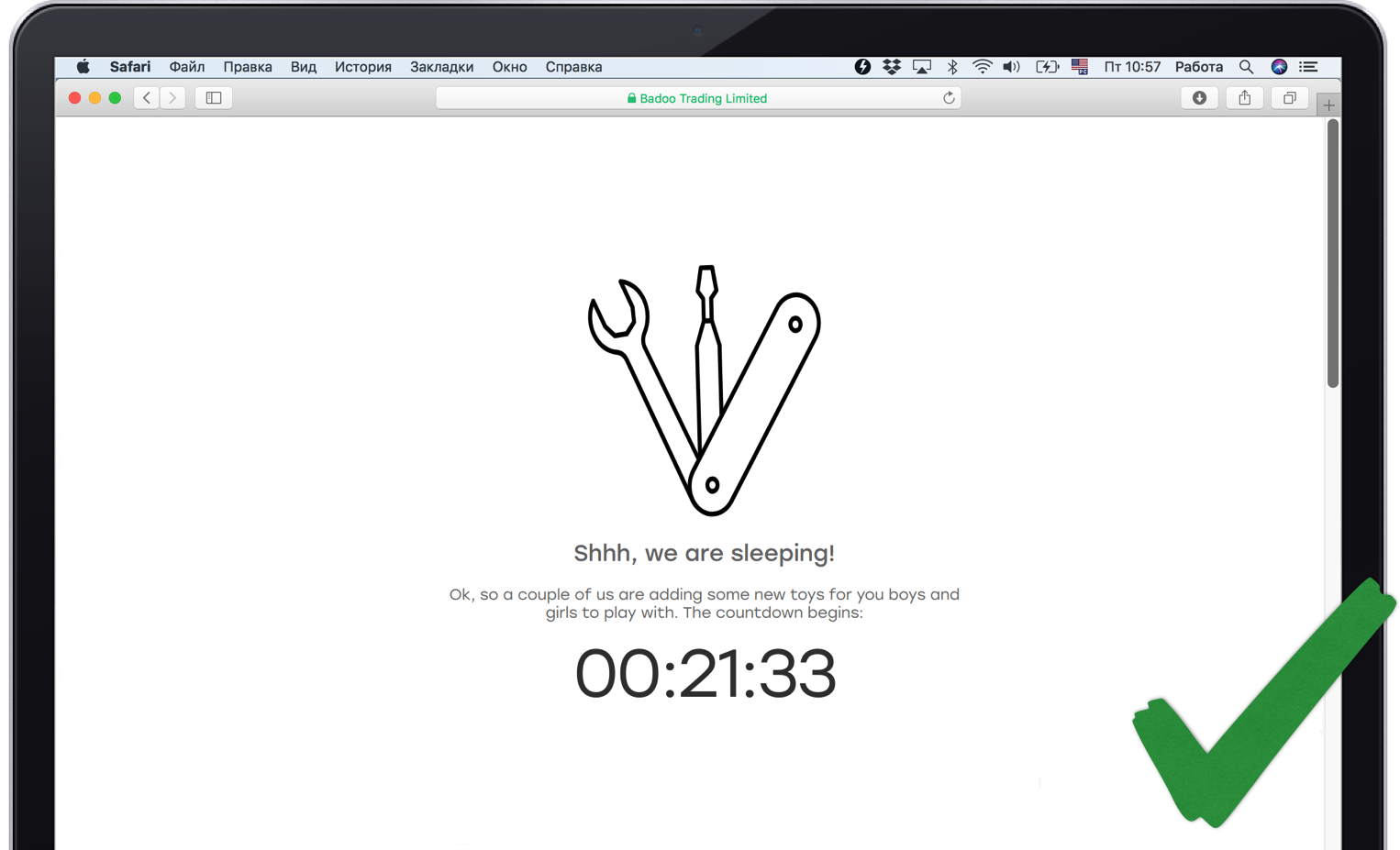
Mati begitu benar
- Bersiaplah untuk musim gugur. Tidak ada peluru perak, jadi selalu sedotan jika layanan turun sepenuhnya, bahkan jika Anda menggunakan redundansi.
- Hindari kegagalan cascading ketika masalah dengan salah satu layanan mematikan seluruh aplikasi.
- Nonaktifkan fungsionalitas pengguna yang tidak kritis. Ini normal. Banyak layanan yang hanya digunakan untuk kebutuhan internal dan tidak memengaruhi fungsionalitas yang disediakan. Misalnya, layanan statistik. Sama sekali tidak masalah bagi pengguna apakah statistik dikumpulkan dari Anda atau tidak. Penting baginya bahwa situs itu berfungsi.
Ringkasan
Untuk mengintegrasikan layanan baru dengan andal ke dalam sistem, kami menulis API pembungkus khusus di sekitarnya di Badoo, yang mengambil tugas-tugas berikut:
- load balancing;
- batas waktu;
- kegagalan logika;
- pemutus sirkuit;
- pemantauan dan telemetri;
- logika otorisasi;
- serialisasi dan deserialisasi data.
Lebih baik memastikan bahwa semua item ini juga tercakup dalam lapisan integrasi Anda. Terutama jika Anda menggunakan klien Open-Source API yang sudah jadi. Penting untuk diingat bahwa lapisan integrasi adalah sumber peningkatan risiko kegagalan aplikasi Anda.
Terima kasih atas perhatian anda!
Sastra