Tren NoSQL sudah hampir 10 tahun, dan Anda dapat dengan aman menarik kesimpulan dan generalisasi. Kami akan melakukan ini dan berbicara tentang pengembangan NoSQL.
Ingat bagaimana NoSQL lahir. Mari kita lihat apa yang baik dan apa yang buruk di dalamnya, dan apa yang telah bertahan dalam ujian waktu. Mari kita menganalisis fitur-fitur yang sudah ada dalam SQL, dan yang sekarang muncul di NoSQL DBMS. Kami menyoroti nilai-nilai unik NoSQL, dan melihat sedikit ke depan pada apa yang akan terjadi di pasar besok.
Dan Konstantin Osipov (
@kostja ), pengembang dan arsitek Tarantool DBMS, yang berbicara tentang tren NewSQL dalam laporannya di RIT ++ 2017, akan membantu kami dalam hal ini, karena arsitek seharusnya memahami apa yang terjadi di dunia basis data sehingga setidaknya menemukan kembali roda.
Tentang pembicara : Sekarang Konstantin Osipov bekerja di Tarantool, tetapi sebelumnya berpartisipasi dalam pengembangan MySQL, dan ketika Konstantin mulai bekerja pada database baru, ia sangat bingung mengapa ini harus dilakukan sama sekali, mengapa database berikutnya diperlukan. Secara khusus, sikap terhadap NoSQL sangat skeptis, seperti "under-SQL".
Namun, pengembangan terus berlanjut, beberapa prinsip asli mati, dan, pada saat yang sama, database NoSQL mengambil alih kemampuan dari SQL klasik. Berdasarkan hasil transformasi cepat selama beberapa tahun ini, sangat mungkin untuk menggambar hasil antara dan membiarkan diri Anda membuat beberapa prediksi untuk masa depan.
Rencanakan
- Latar belakang Ingat bagaimana NoSQL lahir, apa yang baik dan apa yang buruk di dalamnya.
- Mari kita lihat bagaimana NoSQL telah teruji oleh waktu .
- NoSQL SQL : N1QL dan CQL. Mari kita menganalisis fitur-fitur yang sudah ada dalam SQL, dan yang sekarang muncul di NoSQL DBMS.
- NoSQL sudah mati, dan NewSQL belum lahir: betapa hangatnya, tabung SQL berbeda dari SQL di NoSQL.
- Nilai unik dari NoSQL . Kita akan melihat apa yang baik terjadi dalam 10 tahun upaya dan apa yang akan terjadi selanjutnya.
- Database Multi-Model dan NewSQL . Mari kita melihat sedikit ke depan pada apa yang akan ada di pasar besok.
Prinsip NoSQL
Banyak orang berusaha untuk tetap menggunakan istilah NoSQL sekarang, tetapi secara luas diadopsi pada tahun 2009 ketika
tagar #nosql muncul. Pengembang dari Last.FM menemukan tag ini untuk mitap database terdistribusi.
Setelah itu, tag mulai mendapatkan popularitas di Twitter, dan NoSQL menjadi saluran pembuangan atau corong untuk frustrasi, seperti saya menyebutnya - frustrasi yang telah terakumulasi selama bertahun-tahun bekerja dengan database tradisional.
NoSQL adalah jalan keluar untuk frustrasi, sebuah tag yang setiap orang yang belum memiliki cukup fitur SQL telah disesuaikan untuk dirinya sendiri.
Rasa frustrasi ini perlu disusun dan ditentukan dengan cara tertentu yang paling sering orang tidak sukai dalam DBMS tradisional. Kita dapat membedakan 3 blok besar tugas untuk solusi yang NoSQL dibuat:
- penskalaan horizontal;
- model data baru;
- model baru konsistensi.
Mari kita lihat apa blok-blok ini. Ambil, misalnya, basis data nilai-kunci. Gagasan utama dari model data Key-value adalah bahwa databasenya sederhana, tetapi dapat diskalakan. Sejumlah besar masalah jatuh di pundak pengembang, tetapi ia memiliki jaminan ketat bahwa basis datanya akan
terukur tak terhingga . Tapi skalabilitas tanpa batas bukanlah sihir. Jaminan skalabilitas dicapai karena
semantik yang sangat sederhana dari operasi yang didukung: dalam database nilai kunci, operasi apa pun memengaruhi secara ketat satu simpul gugus.
Awalnya, sangat sulit bagi masyarakat untuk memisahkan model data dari model skala. Jika Anda melihat Cassandra yang sama, pada versi awal model datanya disebut Wide Column Store - basis data kolom yang luas. Jika ada satu indeks dalam nilai kunci DBMS, dengan kunci, maka di toko kolom luas dua indeks selalu dibuat secara otomatis: dengan kunci dan oleh Keluarga Kolom.
Selain itu, indeks menurut kunci dapat shardable, dan indeks oleh Keluarga Kolom adalah lokal untuk simpul data tertentu. Karena ini, kami mencapai penskalaan horizontal, tetapi pada saat yang sama mendapat kesempatan untuk melakukan kueri lokal pada keluarga kolom. Old-timer ingat bahwa fitur serupa diimplementasikan di Oracle, sambil mempertahankan model relasional, dan disebut tabel gabungan. Fitur ini memungkinkan untuk menentukan lokasi fisik dari dua tabel dalam formulir bergabung. Toko kolom luas di Cassandra - mengimplementasikan tabel gabungan dengan distribusi otomatis di seluruh cluster.
Penggabungan model data dan model skala persis masalah yang diselesaikan dengan menggunakan model relasional. Selamat datang di tahun 70an.
Selain model data baru, NoSQL telah menerapkan model konsistensi baru. Ya, ya, lagi
teorema CAP yang terkenal ini. Berbicara tentang teorema CAP menghibur saya sepanjang waktu - siapa yang membutuhkannya? Karena tidak ada penguatan dari kesegaran kedua, maka tidak ada jawaban lain untuk pertanyaan tentang konsistensi data kecuali satu:
database harus menjamin konsistensi ini . Karena itu, model konsistensi baru juga, menurut pendapat saya, merupakan tren yang sedang sekarat.
NoSQL hari ini
Tesis yang ingin saya ungkapkan pertama-tama adalah bahwa seluruh gerakan NoSQL selamat:
- penskalaan horizontal;
model data baru model dokumen data dan grafik;model baru konsistensi.
Dari tesis tentang model data baru, hampir satu setengah selamat dan tesis tentang model konsistensi benar-benar mati.
Topi kematian
Mengapa beberapa model konsistensi tidak bertahan?
●
Konsistensi akhirnya: inflasi jangkaSiapa yang menggunakan database yang memiliki jam vektor yang berfungsi dan logika bisnis dari aplikasi diarahkan ini? - tidak seorangpun. Siapa yang menggunakan basis data yang memiliki CRDT (tipe data yang direplikasi bebas konflik)? Siapa yang menggunakan Riak? - tidak seorangpun. Apa yang digunakan orang? Lebih sering PostgreSQL, lebih jarang basis lainnya, misalnya, MongoDB.
●
MongoDB: atom diganti dengan terisolasi, transaksi ditambahkan dalam 3.xxBasis data ini memiliki replikasi asinkron. Ini adalah hal yang sangat mudah dimengerti, meskipun, pada kenyataannya,
ada 4 jenis replikasi asinkron . Replikasi data transaksi dapat terjadi setelah transaksi dilakukan secara lokal; sebelum transaksi dilakukan secara lokal.
Artinya, komit ke database utama dapat dikorelasikan dengan komit ke replika dengan berbagai cara juga.
Entri ke log lokal sudah dibuat, tetapi belum diterbangkan ke replika. Misalkan Anda ingin menunggunya untuk setidaknya terbang ke replika. Terbang - tidak berarti terbang. Tiba - ini tidak berarti bahwa itu ditulis ke jurnal lokal di replika.
Awalnya, MongoDB memiliki mode: permintaan tiba di server, database menjawab OK - itu bahkan belum sampai ke disk, atau ke buku log - tidak pergi ke mana-mana. Karena ini, semuanya bekerja sangat cepat, tetapi kemudian mereka mulai mengkritik MongoDB untuk ini, dan secara default di rilis kemudian 3+, setelah semua, pertama-tama mulai menulis transaksi ke log, dan hanya setelah itu mengirim konfirmasi kepada klien.
Artinya, bahkan replikasi asinkron adalah jurang model semantik. Oleh karena itu,
model konsistensi terlalu rumit untuk dipahami oleh kalangan pengembang yang luas, dan transaksi serta replikasi sinkron menggantikan bermacam-macam model eksotis .
Terhadap latar belakang kematian model konsistensi, masih ada tren yang menarik dalam pengembangan konsistensi yang sebenarnya lebih ketat. Ada transaksi di Redis, meskipun saya tidak akan menyebutnya transaksi, tetapi dengan mengorbankan apa transaksi nyata, ada kontroversi tanpanya.
Mari kita lihat sejarah transaksi di NoSQL. Awalnya, MongoDB menerapkan atomisitas tingkat dokumen. Kemudian mode eksekusi terisolasi ditambahkan untuk memungkinkan pengembang, jika mereka benar-benar ingin, memperbarui beberapa dokumen secara atom.
●
Redis transaksiPada awal NoSQL, pengembang ditawari untuk menempatkan seluruh kasus bisnis dalam satu keranjang dokumen. Keseluruhan aliran muncul yang disebut desain berbasis domain, yang meningkatkan penyimpangan ini ke peringkat pola desain. Memang, jika semuanya disimpan dalam satu dokumen, atomicity dicapai hanya: Anda melakukan satu transaksi, satu proses bisnis dan Anda memiliki satu perubahan atom dalam satu dokumen.
Tapi ternyata ini tidak berhasil. Data perlu dinormalisasi untuk menghindari redudansi penyimpanan. Mereka perlu dinormalisasi untuk pertanyaan analitis. Pada akhirnya, model data berkembang - dan dokumen yang kemarin dapat menyimpan semua informasi yang diperlukan untuk skenario bisnis saat ini perlu diperluas dan ditambah.
Apakah masalah atomisitas menunjukkan? seberapa dekat model data terkait dengan model konsistensi - munculnya transaksi dan replikasi sinkron membuat sebagian besar model di NoSQL tidak perlu.
Model data
Sekarang mari kita bicara tentang kisah selanjutnya - kisah dengan model data.
Kelompok model data ditemukan setelah SQL:
- Nilai Kunci
- Dokumenter
- Toko Kolom Lebar;
- Server struktur data (untuk Redis);
- Database grafik.
Keren! Kami memiliki begitu banyak model data! Dan seberapa baik skala mereka?
Ini adalah tesis, terutama terkait dengan apa yang disebut hiper-konvergensi, ketika semua proyek modern menggunakan server server tunggal murah dan bisnis berhenti membeli mesin yang skalabilitasnya vertikal.
Hyperconvergence telah datang ke dalam kehidupan kita secara menyeluruh sehingga hari ini bahkan di dalam mesin skala vertikal, jika ada, sudah ada perangkat lunak yang dapat diskalakan secara horizontal - lihat bagaimana PureStorage bekerja atau, jika Anda ingat, pada malam hari, Nutanix. Tentu saja, mereka menjual lemari kepada orang-orang, tetapi lemari ini diatur di dalam seperti rak biasa di penyedia hosting.
Artinya, penskalaan horizontal adalah tren yang memberi tekanan pada semua orang, termasuk para penemu model data baru. Jadi model data mana yang bagus untuk penskalaan horizontal, dan mana yang buruk?
Apakah baik atau buruk untuk penskalaan horizontal? Jawabannya, sebenarnya, cukup kontroversial, kami akan kembali lagi nanti.
Redis
Ketika Redis menambahkan cluster Redis, ternyata tidak semua skala operasi model data normal secara horizontal.

Ini adalah kutipan dari dokumentasi di mana mereka menulis bahwa sesuatu bekerja untuk mereka di beling tertentu, dan sesuatu yang benar-benar berfungsi seperti di cluster nyata.
Masalah mendasar dari pendekatan ini adalah sama seperti di MySQL, yang kami ambil dan berjabat tangan. Artinya, pengembang memiliki dua model data:
- Dalam satu, ia berpikir dalam kerangka aljabar relasional.
- Kemudian, ketika dia berpikir tentang sharding independen, dia berpikir dalam model data aljabar shard-relational.
Model data yang baik harus bersifat universal . Apa yang indah tentang aljabar relasional - hasil proyeksi adalah relasi, hasil dari operator mana pun adalah relasi. Dan segera setelah kita secara manual mulai sharding MySQL ke cluster, kita kehilangan itu.
Namun, Redis menambahkan cluster Redis karena
semua orang ingin skala secara horizontal .
Database grafik
Database grafik adalah contoh yang baik yang membantu
memisahkan konsep skala horisontal komputasi dan penyimpanan . Informasi selalu dapat dibagi dengan sejumlah node. Tetapi jika database pada dasarnya dirancang untuk memproses data yang disimpannya, dan perhitungan ini tidak diskalakan secara horizontal, maka masalah muncul dari penyimpanan horisontal yang efektif yang memungkinkan perhitungan bekerja.
Mari kita lihat masalah penskalaan grafik DBMSs - SQL DBMSs menghadapi hambatan skala yang sangat mirip.
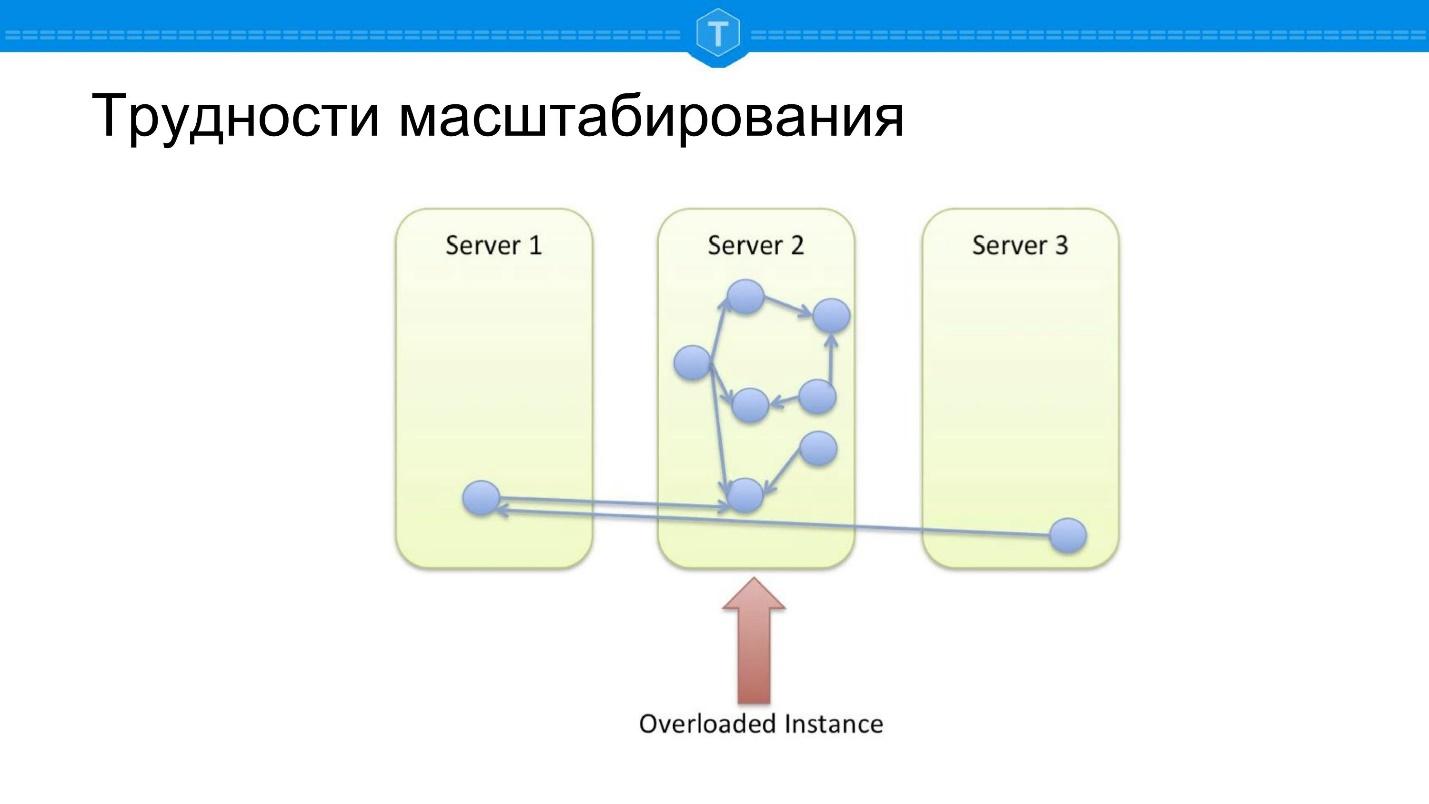
Ambil basis data lokal tempat grafik disimpan. Cepat atau lambat, satu node terisi, dan kita mulai menggunakan node lain. Segera setelah kami menggunakan lebih dari satu simpul, simpul pusat menjadi kelebihan beban, karena lokalitas permintaan hilang. Beberapa pertanyaan pada grafik dipaksa untuk mengikuti beberapa node fisik, yaitu penundaan jaringan muncul.
Misalkan kita melakukan sesuatu yang berbeda - mereka mengambil dan menghancurkan segalanya dengan fungsi sharding yang baik. Kami menghitung hash tertentu, menyebarkan semua data di cluster kami secara acak - dan kami mendapatkan masalah lain.

Jika dalam skema sebelumnya setidaknya beberapa kueri berfungsi dengan baik, maka
100% kueri itu bodoh di sini , karena sebagian besar kueri basis data terhubung dengan grafik
traversal . Setiap jalan memutar dari node harus pergi ke suatu tempat, dan paling sering, untuk menghitung permintaan, Anda harus pergi ke node lain.

Gagasan muncul sekitar beling, seperti yang ditunjukkan pada diagram di atas: temukan cluster dan letakkan di node Anda: himpunan bagian yang terhubung erat ditempatkan bersama-sama, himpunan bagian yang terhubung lemah diberi jarak.
Ini adalah beberapa opsi ideal, tetapi
opsi ideal hanya ada dalam teori . Data langsung tidak cocok dengan partisi statis. Untuk menerapkan pendekatan ini, kita harus secara otomatis mendeteksi cluster pada set yang berubah secara dinamis, terus-menerus memindahkan node tergantung pada ikatan yang muncul dan menghilang.
Oleh karena itu, pada umumnya Neo4j diskalakan seperti database SQL klasik. Mereka telah bekerja pada sharding selama beberapa waktu, mencoba menyelesaikan masalah yang dijelaskan.
Tesis yang saya kemukakan adalah bahwa
penskalaan horizontal memberikan
tekanan pada semua orang , dan semua model data cepat atau lambat akan dipaksa untuk mengimplementasikannya. Tetapi beberapa model akan tetap bersama kami, sementara beberapa tidak.
Jadi, misalnya, jika kita mempertimbangkan database Key-Value dan Dokumen dalam bentuk murni, maka pernyataan saya adalah bahwa mereka tidak akan. Jika Anda melihat basis data grafik, mereka sudah menempati segmen yang signifikan, tetapi berada di bawah tekanan penskalaan horizontal.
Apakah basis data grafik akan hilang? Kemungkinan besar
kolom, seperti dokumen, akan dimasukkan dalam semua produk . Tren ini disebut database multi-model, dan nanti dalam laporan ini saya akan memberikan contoh bagaimana ini bisa bekerja dalam praktiknya. Tetapi untuk sekarang, sebagai ilustrasi lain dari tren database multi-model, mari kita lihat JSON.
Json
Di bawah ini adalah contoh bagaimana tren yang menjadi semua mencakup bekerja.
Saya berpendapat bahwa setiap basis data yang bahkan mampu mendukung JSON dengan cara apa pun akan mendukung JSON.
Mungkin beberapa database untuk komputasi matriks tidak akan mendukung JSON. Tapi kemungkinan besar itu akan berguna. Dan yang lainnya pasti.
| MySQL
| PostgreSQL
| Redis
| Couchbase
| Cassandra
| Neo4j
|
Penyimpanan JSON
| Ya
| Ya
| Ya
| Ya
| Ya
| Ya!
|
Ops bidang JSON
| Ya
| Ya
| Ya
| Ya
| Tidak
| Tidak
|
Permintaan json
| Ya
| Ya
| Tidak
| Ya
| Ya
| Tidak
|
Indeks sekunder JSON
| Ya
| Ya
| Tidak
| Ya
| Tidak
| Tidak
|
Tabel ini memungkinkan Anda untuk melihat secara visual apa yang terjadi dengan model data. Database relasional dalam dukungan mereka untuk JSON bahkan di depan yang non-relasional dari Cassandra yang sama. Itu tidak memiliki kunci sekunder untuk bidang JSON. Dan bahkan basis data grafik juga mulai memasukkan JSON, karena
semua orang membutuhkan JSON .
Dengan demikian, database multi-model, dan khususnya JSON sebagai tipe data yang ditemukan di hampir semua produk, adalah apa yang akan tetap dari NoSQL dengan serius dan untuk waktu yang lama.
Tetapi jika semua database mendukung JSON, mengapa Anda membutuhkan database NoSQL sama sekali?Hanya ada satu cerita yang tersisa - penskalaan horisontal. Kami ingin skala secara horizontal, dan itulah mengapa kami menggunakan sesuatu selain MySQL atau PostgreSQL.

Ini adalah keynote dari Thomas Ulin, VP MySQL Engineering di Oracle, yang berbicara tentang masa depan MySQL. Hal yang sama terjadi di komunitas Postgres dan produk relasional lainnya. Tekanan penskalaan horizontal memengaruhi 100% produk karena transisi ke hiper-konvergensi dan komputasi awan.
Thomas mengatakan visi mereka adalah satu produk dengan ketersediaan tinggi dan skalabilitas di luar kotak. Kita berbicara tentang ketersediaan tinggi terutama InnoDB Cluster, ini replikasi grup + InnoDB. Database seperti itu tidak pernah mati, bahkan jika dipukul dengan palu.
Kemudian Thomas menulis "
fitur penskalaan yang dipanggang di " - "kami memanggang semua fitur ini." Intinya adalah bahwa melalui rilis x (saya pikir x = 2, 3) mereka akan menerima MySQL Cluster dalam bentuk murni, yang akan mendukung SQL pada cluster, penyimpanan JSON dalam cluster.
Sudah hari ini
MySQL memiliki protokol X yang sangat mirip dengan MongoDB dan dirancang untuk bekerja dengan JSON.
SQL dalam NoSQL
Sekarang mari kita lihat pergerakan dari sisi lain. Untuk menyatakan kematian, Anda perlu melihat tidak hanya pada bagaimana SQL mengadopsi prinsip-prinsip NoSQL, tetapi juga sebaliknya.
| Mongodb
| Couchbase
| Cassandra
| Redis
|
Skema data
| Ya *
| Tidak
| Ya
| Tidak
|
Nilai NULLs / Absen
| Ya *
| Ya
| Ya
| Tidak
|
Bergabung
| Ya
| Ya
| Tidak
| Tidak
|
Kunci sekunder
| Ya *
| Ya
| Ya, tapi ...
| Tidak
|
KELOMPOK OLEH
| Ya *
| Ya
| Tidak
| Tidak
|
JDBC / ODBC
| Tidak
| Ya
| Tidak
| Tidak
|
Di sini, sebenarnya, ada juga wawasan yang menarik. Menurut pendapat saya, saya mengambil para pemimpin. Saya setuju bahwa tidak semuanya ada di sini, misalnya, Elastic juga merupakan pemimpin NoSQL. Tapi Elastic masih merupakan solusi utama untuk pencarian teks lengkap, jadi saya tidak memasukkannya dalam tabel.
Times Series Databases sebagai tren yang tidak saya sentuh. Ada tesis di antara serangkaian gerakan yang mengatakan bahwa ini adalah ceruk yang terpisah, mirip dengan basis data grafik, tetapi jika Anda menggali lebih dalam, Postgres duduk di bawah tenda.
Couchbase
Menurut pendapat saya, Couchbase memiliki berbagai kemungkinan dari dunia SQL. Semua orang tahu bahwa
Couchbase adalah Memcached . Dormando (
Alan Kasindorf ), salah satu pengembang Memcached memiliki visi produk yang sama sekali berbeda, yang tidak melibatkan penskalaan horizontal. Oleh karena itu, Memcache bercabang untuk skala secara horizontal. Itu berjalan dengan baik dan mulai melakukan bisnis di sekitarnya, kemudian bergabung dengan CouchDB dan seterusnya dan seterusnya.
Couchbase awalnya mengatakan pada dirinya sendiri bahwa mereka adalah
database schemaless . Memcache pada awalnya merupakan nilai kunci yang sangat sederhana. Sekarang mari kita lihat bagaimana identifikasi diri ini berubah seiring waktu.
Sebagai contoh, Couchbase memiliki kunci sekunder, dan
kunci sekunder sebenarnya adalah awal dari skema . Jika Anda mengatakan bahwa Anda memiliki beberapa bidang yang digunakan untuk membuat indeks, maka Anda sudah berbicara tentang skema dokumen data yang Anda simpan.
Selain itu, karena Couchbase secara bertahap memotong seluruh cerita tentang masa lalu Memcache dari dokumentasi hari ini, mereka juga akan memotong cerita tentang konsistensi akhirnya besok, meskipun hari ini masih ada banyak cerita tentang kurangnya konsistensi baca - kunci sekunder akhirnya konsisten.
Tetapi yang menarik adalah bahwa Couchbase memiliki JDBC / ODBC. , Tableau ClickView — , CQL SQL.
— SQL., .

, - , , , - — , SQL.
, IS MISSING — , IS NULL?
JDBC, ODBC SQL ? 30-40 , SQL- SQL , , : look-in, , ..
, .
, , ., Couchbase JDBC/ODBC — . , — .
Secondary keys
, NoSQL — , — , . OrientDB, , , .
SQL- , ( , ), NoSQL, .
NoSQL- secondary keys. secondary keys?
( — ):
- , , . , range-, SQL . range- map/reduce .
- . index notes, . range- .., .
, , , , , . , .
. , NoSQL- SQL, , , .
: CockroachDB? :
, . , MySQL — legacy. , , ..
, NoSQL- legacy 10 . , , . SQL- , PostgreSQL, , MySQL Couchbase , True NewSQL.
, secondary keys. MongoDB SQL, . , JOINs, , .
Redis No, . Redis , — . , , , .
, Redis — , - . , Redis-, SQL. , Redis SQLite, — storage — Redis', in memory.
NoSQL , , ?
, NoSQL . , , , SQL . SQL .
schemaless , , , waterfall : agile, - . , , CREATE TABLE, .
, online alter table. Oracle , .
SQL , .
MongoDB — , .
MongoDB , schemaless. . , , strict. validation level validation action. Validation level , .
, , - . , , . validation action reject, warn: warning, validation action.
. , MongoDB ( Tarantool), .
Cassandra JSON, . — , . , , NoSQL, .
-, NoSQL SQL .

eventually consistent , , ,
. , — . .
?
, , . BigQuery , , Vertica, .
NoSQL . , SELECT LTP, LTP - Key-value.
, NoSQL- .
SELECT JOIN , , ,
— ..
NoSQL:
,
, , .
domain-specific languages .
NoSQL DSL. —
RethinkDB ReQL . , — domen specific language. Python, JavaScript .. — . SQL , .
ReQL, . ReQL , , — . RethinkDB, , , , , .
:
- Elasticsearch Query Language:
- MIN/MAX/AVG;
- derivative/percentiles/histogram/cumulative sum/serial diff;
- JSONIQ;
- GraphQL;
- SparQL;
- Pregel.
, , SQL, .
- SQL!SQL — OLTP , GROUP BY, Window Functions, (recursive). SQL , . ! , , .
, , . , , , , .
, , Pregel — . : , / . - , . , , .
- SQL, , , .
, ,
, , . .
-
, , . .

ArangoDB, - : , , ( ), , .

, , . . : , .
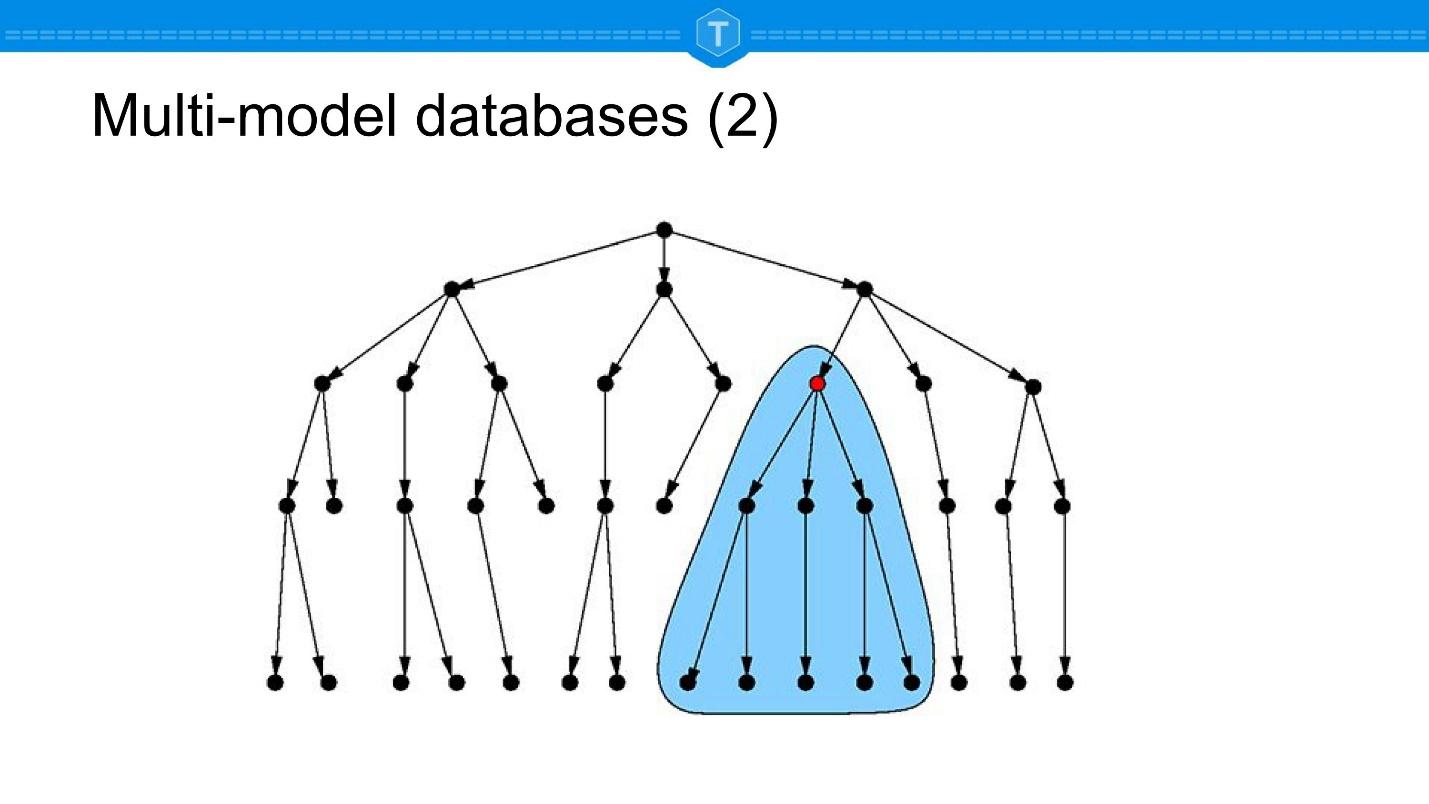
, , . , , , , . .
. , , relations. , relation , , relations ..
UPSERT:
Ini bukan sepenuhnya tentang NoSQL, tetapi ini adalah tren yang tampaknya sangat penting bagi saya - ini adalah
penyimpanan tulis yang dioptimalkan - yang, menurut pendapat saya, akan tetap bersama kami dengan serius dan untuk waktu yang lama.
SQL atau NoSQL tidak memiliki pernyataan yang hanya menulis secara alami. Bahkan absen, yang ada di MongoDB, dalam sejumlah kasus juga membaca data. Sisipan juga merupakan operasi baca, karena jika ID sudah ditentukan dalam dokumen, maka Anda perlu memeriksa bahwa tidak ada ID tersebut.
Anda katakan - jika ada indeks, maka kita harus membaca. Tetapi
bahkan jika ada indeks, maka membaca tidak selalu diperlukan . Idenya adalah ini - Anda tidak ingin membaca dalam hal apapun, Anda tidak perlu melakukan ini, Anda tidak peduli dengan hasil membaca. Anda ingin menambahkan data ke basis data jika belum ada di sana. Jika ada, misalkan Anda mengganti versi lama dengan yang baru atau menjalankan semacam perintah penggabungan. Artinya, Anda harus menciptakan
semantik baru agar tidak membaca.
Menurut pendapat saya, tidak ada satu pun database yang menyediakan ini sekarang, tetapi daya tarik dari algoritma yang dioptimalkan sangat besar sehingga saya benar-benar menginginkan kemungkinan ini. Karena berkat menulis penyimpanan yang dioptimalkan, pohon-pohon LSM (RocksDB, LevelDB dan lain-lain)
menulis kinerja tanpa membaca adalah 2 urutan lebih tinggi daripada kinerja menulis dengan membaca . Alih-alih 10 ribu permintaan per detik, mungkin ada satu juta pada satu simpul.
Itulah sebabnya Database Time Series sekarang menang karena mereka tidak memiliki celah semantik ini. Aliran data yang tiba di dalamnya secara jelas didefinisikan sebagai rangkaian waktu dan ditulis dengan sangat cepat dan kompak ke dalam basis data, khususnya. karena Anda tidak perlu memverifikasi keunikan. Ini adalah urutan besarnya lebih cepat hanya karena dalam database tradisional tidak ada operasi semantik yang hanya akan menulis.
Saya pikir itu akan muncul.

Ke mana semua ini selanjutnya? Jika Anda melihat sangat jauh, inovasi tidak berhenti di NoSQL dan NewSQL. Pemahaman kita tentang informasi terus berkembang.
Salah satu tren paling penting di masa depan, menurut saya, adalah kita akan semakin sedikit menghapus informasi.
Untuk ini, serangkaian produk lahir, yang disebut basis data temporal.
Setelah NewSQL: basis data temporal
Di bawah ini adalah tangkapan layar dari Microsoft SQL Server. Ini adalah basis data yang memungkinkan Anda mengajukan pertanyaan ke titik waktu: ada SELECT untuk kondisi saat ini, tetapi masih memungkinkan untuk membuat SELECT untuk beberapa tanggal di masa lalu.

Ini memunculkan sejumlah aplikasi basis data baru. Pertama, Anda dapat melacak sejarah suatu objek. Kedua, Anda dapat secara otomatis menghitung grup, laporan berdasarkan titik. Anda tidak perlu membuat tabel terpisah untuk ini - Anda memiliki representasi alami dalam satu tabel: satu entitas - satu tabel.
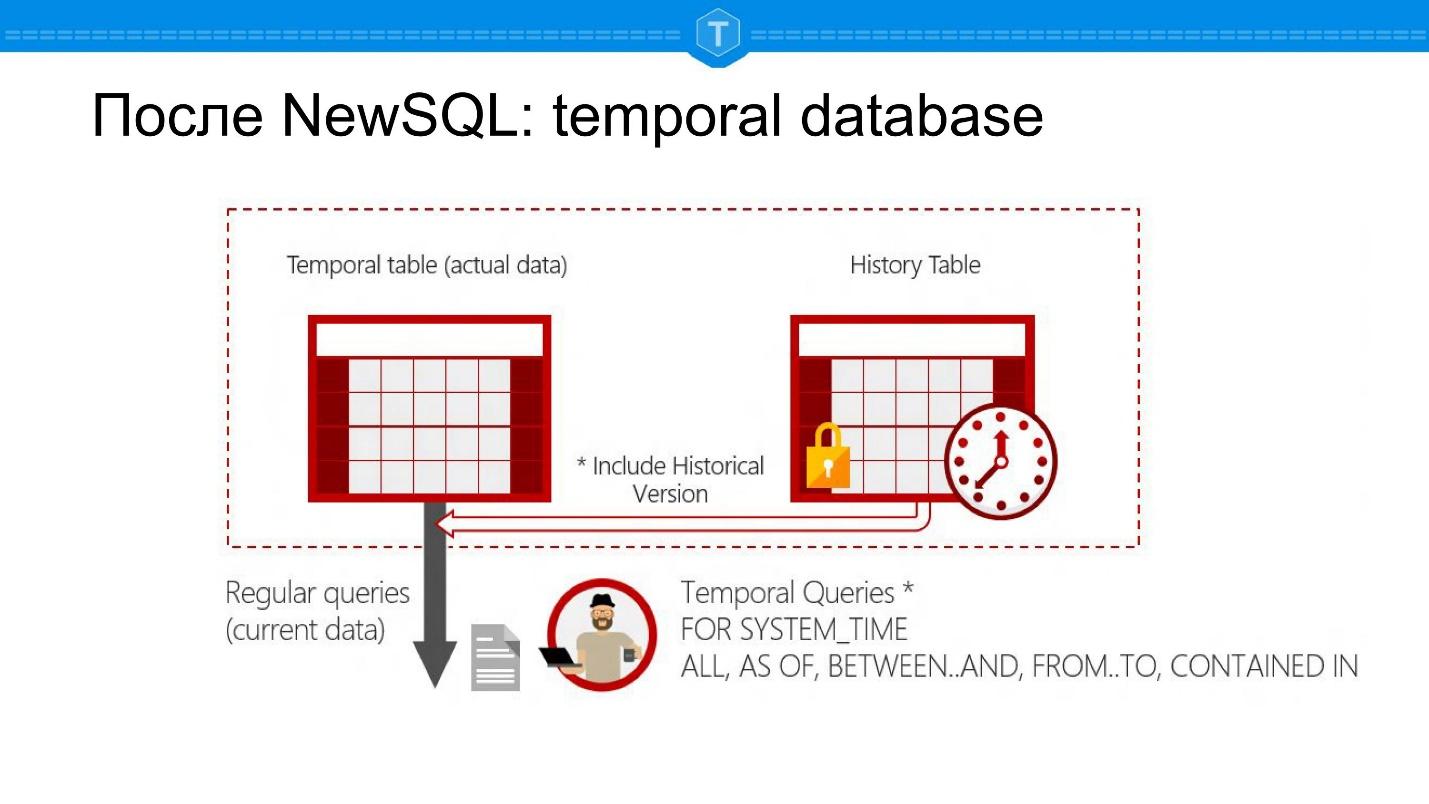
Dari sudut pandang struktur internal, ini sebenarnya adalah tabel utama dan tabel dengan sejarah. Setiap baris dikaitkan dengan dua kali diketahui sistem. Ini bukan hanya dua kolom yang Anda tambahkan, tetapi data yang didukung sistem secara otomatis:
- waktu catatan ditambahkan ke database,
- waktu acara.
Ini adalah waktu yang berbeda, tidak peduli seberapa lucu.
Misalkan Ivan Ivanovich meninggal pada 17 November, dan catatan ini dimasukkan ke dalam basis data pada 20 November - kedua kali ini disimpan dalam database seperti itu.
Menurut saya, ini juga salah satu tren mendasar. Mengapa saya berpikir demikian? Jika kita kembali ke kunci sekunder dan konsistensi akhirnya, maka menyimpan semuanya benar-benar hanya memungkinkan Anda untuk menyelesaikan masalah ini dengan elegan.
Jika kita tidak perlu menghapus apapun dari database sama sekali, maka database kita selalu konsisten - cerita yang sangat menarik!
Tautan yang bermanfaat
Faq- Apakah ada perkembangan dalam pembuatan database baru yang tidak akan berlaku untuk MySQL, PostgreSQL, MongoDB, dll?
Dalam cara yang baik, pertanyaannya adalah: apakah akan ada database baru, startup? Saya pikir mereka akan semakin jarang terlihat. Badai telah mereda, dan sekarang kita akan lebih cepat melihat keberangkatan daripada kedatangan, CockroachDB adalah salah satu yang terakhir tiba.
Mari kita langsung ke intinya. Profesor saya di universitas mengatakan bahwa DBMS adalah area hijau abadi. Karena itu, kita akan selalu melihat semacam gerakan. Tapi saya pikir dalam waktu dekat produk yang berbeda secara fundamental tidak akan muncul, akan ada konvergensi, bukan booming.
- Bukan pertanyaan, melainkan tambahan: SQL sering mencoba untuk membuat indeks yang meliputi sehingga hasil query SQL tidak menyangkut tingkat penyimpanan, tetapi langsung diperoleh dari indeks. Indeks itu sendiri sebenarnya adalah kasus khusus dari grafik. Jadi, mungkin tren seluruh database secara bertahap mengalir ke indeks grafik curam?
Ini adalah kisah yang luar biasa yang disukai oleh semua perwakilan database grafik untuk memberi tahu pelanggan mereka - itu tidak berhasil! Karena ada banyak cara untuk memperbarui indeks, dan ada banyak opsi pengindeksan, tetapi tidak semua orang memiliki grafik! Mari kita tenang - sama seperti tidak semuanya relasional, jadi tidak semua orang adalah grafik.
- Menurut Anda, kemana elastis dan sejenisnya akan pergi? Saya berbicara tentang fakta bahwa dia mulai memecahkan masalah yang sangat aneh - dia mencoba untuk berpura-pura time series dan basis analitik untuk bekerja dengan log. Tampaknya tidak ada yang menggunakannya untuk pencarian teks.
Elastis tidak harus bergerak ke mana pun karena elastis terasa hebat. Ini memecahkan masalah bisnis tertentu - ini adalah pencarian yang efektif dan segala sesuatu yang berkaitan dengan ekosistem ini.
Saya pikir semuanya terutama berasal dari fakta bahwa Elastic mencoba menjadi segalanya. Tapi di sini pertanyaannya adalah dari tugas, tugas Elastis sangat mirip dengan tugas deret waktu, oleh karena itu dibenarkan. Elastis bagus untuk mencari melalui array besar dari log yang sama, dll.
Ada kasus yang lebih sempit - ini hanya pencarian teks lengkap, tetapi Anda tidak akan menghasilkan banyak dari itu. Lebih banyak yang perlu dilakukan untuk membedakan dari pesaing di tempat pertama. Karena itu, ini semua terjadi.
Tetapi saya tidak berpikir bahwa Elastis akan melakukan transaksi perbankan besok. Semuanya berjalan ke titik di mana Couchbase, misalnya, akan - jika bukan transaksi perbankan, tetapi sesuatu yang sangat cepat.
Berita
Segera, pada tanggal 21 Juni, Konferensi Tarantool akan berlangsung di Moskow - atau secara singkat T + Conf - sebuah konferensi tidak hanya tentang Tarantool itu sendiri, tetapi juga tentang penggunaan komputasi dalam memori secara umum .
- Konstantin Osipov berencana untuk membuat laporan di mana ia akan memeriksa arsitektur Vinyl, kemampuannya dan, yang paling penting, mekanisme tuning dan pemantauan kinerja khusus untuk mesin ini secara konsisten dan sedetail mungkin.
- Vladimir Perepelitsa dalam format tutorial, ingin menunjukkan bahwa Tarantool adalah basis data yang memiliki potensi besar untuk digunakan sebagai server aplikasi.
- Vladislav Zaitsev dari pergi untuk mendekati topik ini dari sisinya - dari sisi Internet hal dan mengatakan , khususnya, mengapa sistem kontrol IoT.