Kita masing-masing mengerjakan tugas. Semua orang menulis kode boilerplate. Mengapa Bukankah lebih baik untuk mengotomatisasi proses ini dan hanya bekerja pada tugas yang menarik? Baca artikel ini jika Anda ingin komputer melakukan pekerjaan seperti itu untuk Anda.
 Artikel ini didasarkan pada transkrip dari laporan oleh Zack Sweers, pengembang aplikasi seluler Uber, yang berbicara pada konferensi MBLT DEV pada 2017.
Artikel ini didasarkan pada transkrip dari laporan oleh Zack Sweers, pengembang aplikasi seluler Uber, yang berbicara pada konferensi MBLT DEV pada 2017.
Uber memiliki sekitar 300 pengembang aplikasi seluler. Saya bekerja di tim yang disebut "platform seluler". Pekerjaan tim saya adalah menyederhanakan dan meningkatkan proses pengembangan aplikasi seluler sebanyak mungkin. Kami terutama bekerja pada kerangka kerja internal, perpustakaan, arsitektur, dan sebagainya. Karena staf yang besar, kami harus melakukan proyek skala besar yang akan dibutuhkan oleh teknisi kami di masa depan. Mungkin besok, atau mungkin bulan depan atau bahkan setahun.
Pembuatan kode untuk otomatisasi
Saya ingin menunjukkan nilai dari proses pembuatan kode, serta mempertimbangkan beberapa contoh praktis. Prosesnya sendiri terlihat seperti ini:
FileSpec.builder("", "Presentation") .addComment("Code generating your way to happiness.") .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", "Zac Sweers") .useSiteTarget(FILE) .build()) .build()
Ini adalah contoh penggunaan Kotlin Poet. Kotlin Poet adalah perpustakaan dengan API yang bagus yang menghasilkan kode Kotlin. Jadi apa yang kita lihat di sini?
- FileSpec.builder membuat file yang disebut " Presentation ".
- .addComment () - Menambahkan komentar ke kode yang dihasilkan.
- .addAnnotation () - Menambahkan anotasi tipe Author .
- .addMember () - menambahkan variabel " nama " dengan parameter, dalam kasus kami adalah " Zac Sweers ". % S - tipe parameter.
- .useSiteTarget () - Menginstal SiteTarget.
- .build () - melengkapi deskripsi kode yang akan dihasilkan.
Setelah pembuatan kode, berikut ini diperoleh:
Presentation.kt // Code generating your way to happiness. @file:Author(name = "Zac Sweers")
Hasil pembuatan kode adalah file dengan nama, komentar, anotasi, dan nama penulis. Pertanyaan segera muncul: "Mengapa saya perlu membuat kode ini jika saya bisa melakukannya dalam beberapa langkah sederhana?" Ya, Anda benar, tetapi bagaimana jika saya memerlukan ribuan file ini dengan opsi konfigurasi yang berbeda? Apa yang terjadi jika kita mulai mengubah nilai dalam kode ini? Bagaimana jika kita memiliki banyak presentasi? Bagaimana jika kita memiliki banyak konferensi?
conferences .flatMap { it.presentations } .onEach { (presentationName, comment, author) -> FileSpec.builder("", presentationName) .addComment(comment) .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", author) .useSiteTarget(FILE) .build()) .build() }
Sebagai hasilnya, kita akan sampai pada kesimpulan bahwa tidak mungkin untuk mempertahankan sejumlah file secara manual - perlu untuk diotomatisasi. Oleh karena itu, keuntungan pertama pembuatan kode adalah menghilangkan pekerjaan rutin.
Pembuatan kode bebas kesalahan
Keuntungan penting kedua dari otomatisasi adalah operasi bebas kesalahan. Semua orang membuat kesalahan. Ini sering terjadi terutama ketika kita melakukan hal yang sama. Komputer, sebaliknya, melakukan pekerjaan seperti itu dengan sempurna.
Pertimbangkan contoh sederhana. Ada kelas Person:
class Person(val firstName: String, val lastName: String)
Misalkan kita ingin menambahkan serialisasi ke dalam JSON. Kami akan melakukan ini menggunakan perpustakaan
Moshi , karena cukup sederhana dan bagus untuk demonstrasi. Buat PersonJsonAdapter dan mewarisi dari JsonAdapter dengan parameter tipe Person:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { }
Selanjutnya, kami menerapkan metode fromJson. Ini menyediakan pembaca untuk membaca informasi yang akhirnya akan dikembalikan ke Orang. Lalu kami mengisi kolom dengan nama depan dan belakang dan mendapatkan nilai Person yang baru:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String return Person(firstName, lastName) } }
Selanjutnya, kita melihat data dalam format JSON, periksa dan masukkan di bidang yang diperlukan:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() } } return Person(firstName, lastName) } }
Akankah ini berhasil? Ya, tetapi ada nuansa: objek yang kita baca harus terkandung di dalam JSON. Untuk memfilter data berlebih yang mungkin berasal dari server, tambahkan baris kode lain:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() else -> reader.skipValue() } } return Person(firstName, lastName) } }
Pada titik ini, kami berhasil menghindari area kode rutin. Dalam contoh ini, hanya dua bidang nilai. Namun, kode ini memiliki banyak bagian berbeda di mana Anda mungkin tiba-tiba mogok. Tiba-tiba kami membuat kesalahan dalam kode?
Pertimbangkan contoh lain:
class Person(val firstName: String, val lastName: String) class City(val name: String, val country: String) class Vehicle(val licensePlate: String) class Restaurant(val type: String, val address: Address) class Payment(val cardNumber: String, val type: String) class TipAmount(val value: Double) class Rating(val numStars: Int) class Correctness(val confidence: Double)
Jika Anda memiliki setidaknya satu masalah setiap 10 model atau lebih, maka ini berarti Anda pasti akan mengalami kesulitan di bidang ini. Dan ini adalah kasus ketika pembuatan kode benar-benar dapat membantu Anda. Jika ada banyak kelas, Anda tidak akan dapat bekerja tanpa otomatisasi, karena semua orang mengizinkan kesalahan ketik. Dengan bantuan pembuatan kode, semua tugas akan dilakukan secara otomatis dan tanpa kesalahan.
Ada manfaat lain untuk pembuatan kode. Misalnya, ini memberikan informasi tentang kode atau memberi tahu Anda jika ada masalah. Pembuatan kode akan bermanfaat selama fase pengujian. Jika Anda menggunakan kode yang dihasilkan, Anda dapat melihat bagaimana kode kerja akan benar-benar terlihat. Anda bahkan dapat menjalankan pembuatan kode selama pengujian untuk menyederhanakan pekerjaan Anda.
Kesimpulan: perlu mempertimbangkan pembuatan kode sebagai solusi yang mungkin untuk menghilangkan kesalahan.
Sekarang mari kita lihat alat perangkat lunak yang membantu pembuatan kode.
Alat-alatnya
- Perpustakaan JavaPoet dan KotlinPoet untuk Java dan Kotlin, masing-masing. Ini adalah standar pembuatan kode.
- Polaisasi. Contoh templating untuk Java yang populer adalah Apache Velocity , dan untuk iOS Handlebars .
- SPI - Antarmuka Prosesor Layanan. Itu dibangun ke Jawa dan memungkinkan Anda untuk membuat dan menerapkan antarmuka dan kemudian mendeklarasikannya dalam JAR. Saat program dijalankan, Anda bisa mendapatkan semua implementasi antarmuka yang siap pakai.
- Compile Testing adalah pustaka dari Google yang membantu dengan pengujian kompilasi. Dalam hal pembuatan kode, ini berarti: "Inilah yang saya harapkan, tetapi inilah yang akhirnya saya dapatkan." Kompilasi akan dimulai di memori, dan kemudian sistem akan memberi tahu Anda apakah proses ini selesai atau kesalahan apa yang terjadi. Jika kompilasi telah selesai, Anda akan diminta untuk membandingkan hasilnya dengan harapan Anda. Perbandingan didasarkan pada kode yang dikompilasi, jadi jangan khawatir tentang hal-hal seperti pemformatan kode atau apa pun.
Alat Pembuat Kode
Ada dua alat utama untuk membangun kode:
- Pemrosesan Anotasi - Anda dapat menulis anotasi dalam kode dan meminta program untuk informasi tambahan tentangnya. Kompiler akan memberikan informasi bahkan sebelum selesai bekerja dengan kode sumber.
- Gradle adalah sistem rakitan aplikasi dengan banyak kait (kait - intersepsi panggilan fungsi) dalam siklus masa pakai perakitan kode. Ini banyak digunakan dalam pengembangan Android. Ini juga memungkinkan Anda untuk menerapkan pembuatan kode ke kode sumber, yang independen dari sumber saat ini.
Sekarang perhatikan beberapa contoh.
Pisau mentega
Butter Knife adalah perpustakaan yang dikembangkan oleh Jake Wharton. Dia adalah tokoh terkenal di komunitas pengembang. Perpustakaan sangat populer di kalangan pengembang Android karena membantu menghindari sejumlah besar pekerjaan rutin yang dihadapi hampir semua orang.
Biasanya kami menginisialisasi tampilan dengan cara ini:
TextView title; ImageView icon; void onCreate(Bundle savedInstanceState) { title = findViewById(R.id.title); icon = findViewById(R.id.icon); }
Dengan Butterknife, akan terlihat seperti ini:
@BindView(R.id.title) TextView title; @BindView(R.id.icon) ImageView icon; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
Dan kita dapat dengan mudah menambahkan sejumlah tampilan, sementara metode onCreate tidak akan menumbuhkan kode boilerplate:
@BindView(R.id.title) TextView title; @BindView(R.id.text) TextView text; @BindView(R.id.icon) ImageView icon; @BindView(R.id.button) Button button; @BindView(R.id.next) Button next; @BindView(R.id.back) Button back; @BindView(R.id.open) Button open; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
Alih-alih melakukan pengikatan secara manual ini setiap kali, Anda cukup menambahkan anotasi @BindView ke bidang ini, serta pengidentifikasi (ID) yang ditugaskan kepadanya.
Hal paling keren dari Butter Knife adalah ia akan menganalisis kode dan menghasilkan semua bagian yang serupa dengan Anda. Ini juga memiliki skalabilitas yang sangat baik untuk data baru. Karena itu, jika data baru muncul, tidak perlu menerapkan onCreate lagi atau melacak sesuatu secara manual. Perpustakaan ini juga bagus untuk menghapus data.
Jadi, seperti apa sistem ini dari dalam? Tampilan dicari oleh pengenalan kode, dan proses ini dilakukan pada tahap pemrosesan anotasi.
Kami memiliki bidang ini:
@BindView(R.id.title) TextView title;
Dilihat oleh data ini, mereka digunakan dalam FooActivity tertentu:
Dia memiliki maknanya sendiri (R.id.title), yang bertindak sebagai target. Harap dicatat bahwa selama pemrosesan data objek ini menjadi nilai konstan di dalam sistem:
Ini normal. Lagipula inilah yang harus diakses oleh Knife Butter. Ada komponen TextView sebagai tipe. Bidang itu sendiri disebut judul. Jika, misalnya, kami membuat kelas kontainer dari data ini, kami mendapatkan sesuatu seperti ini:
ViewBinding( target = "FooActivity", id = 2131361859, name = "title", type = "field", viewType = TextView.class )
Jadi, semua data ini dapat dengan mudah diperoleh selama pemrosesan mereka. Ini juga sangat mirip dengan apa yang dilakukan Butter Knife di dalam sistem.
Akibatnya, kelas ini dihasilkan di sini:
public final class FooActivity_ViewBinding implements Unbinder { private FooActivity target; @UiThread public FooActivity_ViewBinding(FooActivity target, View source) { this.target = target; target.title = Utils.findRequiredViewAsType(source, 2131361859,
Di sini kita melihat bahwa semua data ini dikumpulkan bersama. Sebagai hasilnya, kami memiliki kelas target ViewBinding dari perpustakaan java Underscore. Di dalam, sistem ini diatur sedemikian rupa sehingga setiap kali Anda membuat turunan kelas, ia segera melakukan semua pengikatan ini dengan informasi (kode) yang Anda hasilkan. Dan semua ini sebelumnya dihasilkan secara statis selama pemrosesan anotasi, yang berarti secara teknis benar.
Mari kita kembali ke saluran perangkat lunak kami:
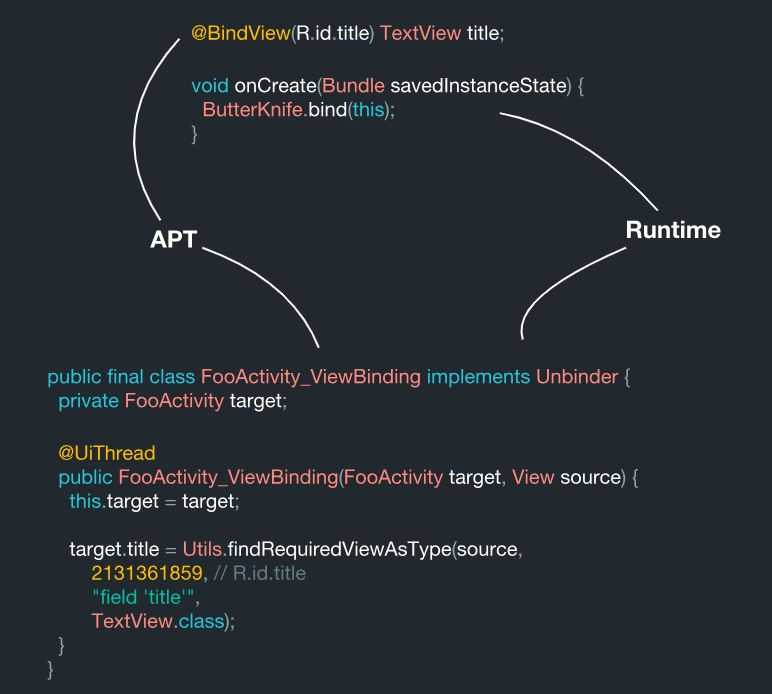
Selama pemrosesan anotasi, sistem membaca anotasi ini dan menghasilkan kelas ViewBinding. Dan kemudian selama metode bind, kita melakukan pencarian yang identik untuk kelas yang sama dengan cara yang sederhana: kita mengambil namanya dan menambahkan ViewBinding pada akhirnya. Dengan sendirinya, bagian dengan ViewBinding selama pemrosesan ditimpa dalam area yang ditentukan menggunakan JavaPoet.
Rxbindings
RxBindings sendiri tidak bertanggung jawab untuk pembuatan kode. Itu tidak menangani anotasi dan bukan plugin Gradle. Ini adalah perpustakaan biasa. Ini menyediakan pabrik statis berdasarkan prinsip pemrograman reaktif untuk API Android. Ini berarti bahwa, misalnya, jika Anda telah menetapkan OnClickListener, maka metode klik akan muncul yang akan mengembalikan aliran peristiwa (Dapat Diamati). Karena berfungsi sebagai jembatan (pola desain).
Tetapi sebenarnya ada pembuatan kode di RxBinding:
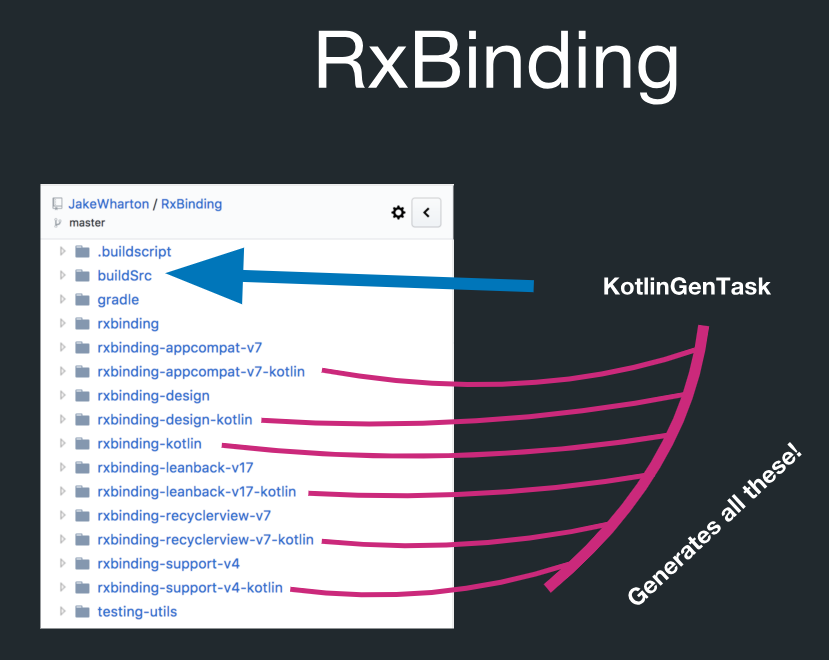
Dalam direktori ini disebut buildSrc ada tugas Gradle yang disebut KotlinGenTask. Ini berarti bahwa semua ini sebenarnya dibuat oleh pembuatan kode. RxBinding memiliki implementasi Java. Dia juga memiliki artefak Kotlin yang berisi fungsi ekstensi untuk semua jenis target. Dan semua ini sangat ketat tunduk pada aturan. Misalnya, Anda dapat membuat semua fungsi ekstensi Kotlin, dan Anda tidak harus mengontrolnya satu per satu.
Seperti apa bentuknya?
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
Berikut ini adalah metode RxBinding yang benar-benar klasik. Objek yang dapat diamati dikembalikan di sini. Metode ini disebut klik. Bekerja dengan acara klik terjadi "di bawah tenda". Kami menghilangkan fragmen kode tambahan untuk menjaga keterbacaan contoh. Di Kotlin, tampilannya seperti ini:
fun View.clicks(): Observable<Object> = RxView.clicks(this)
Fungsi ekstensi ini mengembalikan objek yang bisa diamati. Dalam struktur internal program, program ini secara langsung memanggil antarmuka Java biasa untuk kita. Di Kotlin, Anda harus mengubahnya ke tipe Unit:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Artinya, di Jawa, tampilannya seperti ini:
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
Dan begitu juga kode Kotlin:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Kami memiliki kelas RxView yang berisi metode ini. Kita dapat mengganti potongan data terkait dalam atribut target, dalam atribut nama dengan nama metode dan dalam tipe yang kita kembangkan, serta dalam tipe nilai pengembalian. Semua informasi ini akan cukup untuk mulai menulis metode ini:
BindingMethod( target = "RxView", name = "clicks", type = View.class, returnType = "Observable<Unit>" )
Sekarang kita dapat langsung mengganti fragmen-fragmen ini ke dalam kode Kotlin yang dihasilkan di dalam program. Inilah hasilnya:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Gen layanan
Kami sedang mengerjakan Service Gen di Uber. Jika Anda bekerja di perusahaan dan berurusan dengan karakteristik umum dan antarmuka perangkat lunak umum untuk sisi backend dan klien, maka terlepas dari apakah Anda sedang mengembangkan aplikasi Android, iOS atau web, tidak masuk akal untuk secara manual membuat model dan layanan untuk kerja tim.
Kami menggunakan pustaka
AutoValue Google untuk model objek. Ia memproses anotasi, menganalisis data, dan menghasilkan kode hash dua baris, metode equals (), dan implementasi lainnya. Dia juga bertanggung jawab untuk mendukung ekstensi.
Kami memiliki objek tipe Rider:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
Kami memiliki garis dengan ID, nama depan, nama belakang dan alamat. Untuk bekerja dengan jaringan, kami menggunakan pustaka Retrofit dan OkHttp, dan JSON sebagai format data. Kami juga menggunakan RxJava untuk pemrograman reaktif. Seperti inilah tampilan layanan API kami:
interface UberService { @GET("/rider") Rider getRider() }
Kita dapat menulis semua ini secara manual, jika kita mau. Dan untuk jangka waktu yang lama, kami melakukannya. Tetapi butuh banyak waktu. Pada akhirnya, biayanya banyak dalam hal waktu dan uang.
Apa dan bagaimana Uber lakukan hari ini
Tugas terakhir tim saya adalah membuat editor teks dari awal. Kami memutuskan untuk tidak lagi menulis kode secara manual yang kemudian mengenai jaringan, jadi kami menggunakan
Thrift . Itu adalah sesuatu seperti bahasa pemrograman dan protokol pada saat yang bersamaan. Uber menggunakan barang bekas sebagai bahasa untuk spesifikasi teknis.
struct Rider { 1: required string uuid; 2: required string firstName; 3: required string lastName; 4: optional Address address; }
Dalam hemat, kami mendefinisikan kontrak API antara backend dan sisi klien, dan kemudian hanya menghasilkan kode yang sesuai. Kami menggunakan pustaka
hemat untuk mengurai data, dan JavaPoet untuk pembuatan kode. Pada akhirnya, kami membuat implementasi menggunakan AutoValue:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
Kami melakukan semua pekerjaan di JSON. Ada ekstensi yang disebut
AutoValue Moshi , yang dapat ditambahkan ke kelas AutoValue menggunakan metode jsonAdapter statis:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); static JsonAdapter<Rider> jsonAdapter(Moshi moshi) { return new AutoValue_Rider.JsonAdapter(moshi); } }
Thrift juga membantu dalam pengembangan layanan:
service UberService { Rider getRider() }
Kami juga harus menambahkan beberapa metadata di sini untuk memberi tahu kami hasil akhir yang ingin kami capai:
service UberService { Rider getRider() (path="/rider") }
Setelah pembuatan kode, kami akan menerima layanan kami:
interface UberService { @GET("/rider") Single<Rider> getRider(); }
Tapi ini hanya salah satu hasil yang mungkin. Satu model. Seperti yang kita ketahui dari pengalaman, tidak ada yang pernah menggunakan hanya satu model. Kami memiliki banyak model yang menghasilkan kode untuk layanan kami:
struct Rider struct City struct Vehicle struct Restaurant struct Payment struct TipAmount struct Rating
Saat ini kami memiliki sekitar 5-6 aplikasi. Dan mereka memiliki banyak layanan. Dan semua orang melewati pipa perangkat lunak yang sama. Menulis semua ini dengan tangan akan gila.
Dalam serialisasi di JSON, "adaptor" tidak perlu terdaftar di Moshi, dan jika Anda menggunakan JSON, maka Anda tidak perlu mendaftar di JSON. Juga diragukan untuk menyarankan karyawan untuk melakukan deserialisasi dengan menulis ulang kode melalui grafik DI.
Tapi kami bekerja dengan Java, jadi kami bisa menggunakan pola Factory, yang kami hasilkan melalui perpustakaan
Fractory . Kami dapat membuat ini karena kami tahu tentang jenis ini sebelum kompilasi terjadi. Fractory menghasilkan adaptor seperti ini:
class ModelsAdapterFactory implements JsonAdapter.Factory { @Override public JsonAdapter<?> create(Type type, Set<? extends Annotation> annotations, Moshi moshi) { Class<?> rawType = Types.getRawType(type); if (rawType.isAssignableFrom(Rider.class)) { return Rider.adapter(moshi); } else if (rawType.isAssignableFrom(City.class)) { return City.adapter(moshi); } else if (rawType.isAssignableFrom(Vehicle.class)) { return Vehicle.adapter(moshi); }
Kode yang dihasilkan tidak terlihat sangat bagus. Jika sakit mata, dapat ditulis ulang secara manual.
Di sini Anda dapat melihat jenis yang disebutkan sebelumnya dengan nama layanan. Sistem akan secara otomatis menentukan adaptor mana yang akan dipilih dan memanggil mereka. Tapi di sini kita dihadapkan dengan masalah lain. Kami memiliki 6000 adapter ini. Bahkan jika Anda membaginya di dalam template yang sama, model "Eats" atau "Driver" akan jatuh ke dalam model "Rider" atau akan ada dalam aplikasinya. Kode akan terentang. Setelah titik tertentu, itu bahkan tidak dapat masuk ke file .dex. Karena itu, Anda perlu memisahkan adaptor:

Pada akhirnya, kami akan menganalisis kode terlebih dahulu dan membuat proyek yang berfungsi untuk itu, seperti di Gradle:

Dalam struktur internal, dependensi ini menjadi dependensi Gradle. Elemen yang menggunakan aplikasi Rider sekarang bergantung padanya. Dengan itu, mereka akan membentuk model yang mereka butuhkan. Akibatnya, tugas kita akan terpecahkan, dan semua ini akan diatur oleh sistem perakitan kode di dalam program.
Tapi di sini kita dihadapkan dengan masalah lain: sekarang kita memiliki n-number model pabrik. Semuanya dikompilasi menjadi berbagai objek:
class RiderModelFactory class GiftCardModelFactory class PricingModelFactory class DriverModelFactory class EATSModelFactory class PaymentsModelFactory
Dalam proses pemrosesan anotasi, tidak mungkin untuk hanya membaca anotasi untuk dependensi eksternal dan melakukan pembuatan kode tambahan hanya pada mereka.
Solusi: kami memiliki beberapa dukungan di perpustakaan Fractory, yang membantu kami dalam satu cara yang rumit. Itu terkandung dalam proses pengikatan data. Kami memperkenalkan metadata menggunakan parameter classpath di arsip Java untuk penyimpanan lebih lanjut:
class RiderModelFactory // -> json // -> ridermodelfactory-fractory.bin class MyAppGlobalFactory // Delegates to all discovered fractories
Sekarang, setiap kali Anda perlu menggunakannya dalam aplikasi, kita masuk ke filter direktori classpath dengan file-file ini, dan kemudian kita ekstrak dari sana dalam format JSON untuk mengetahui dependensi mana yang tersedia.
Bagaimana semuanya cocok
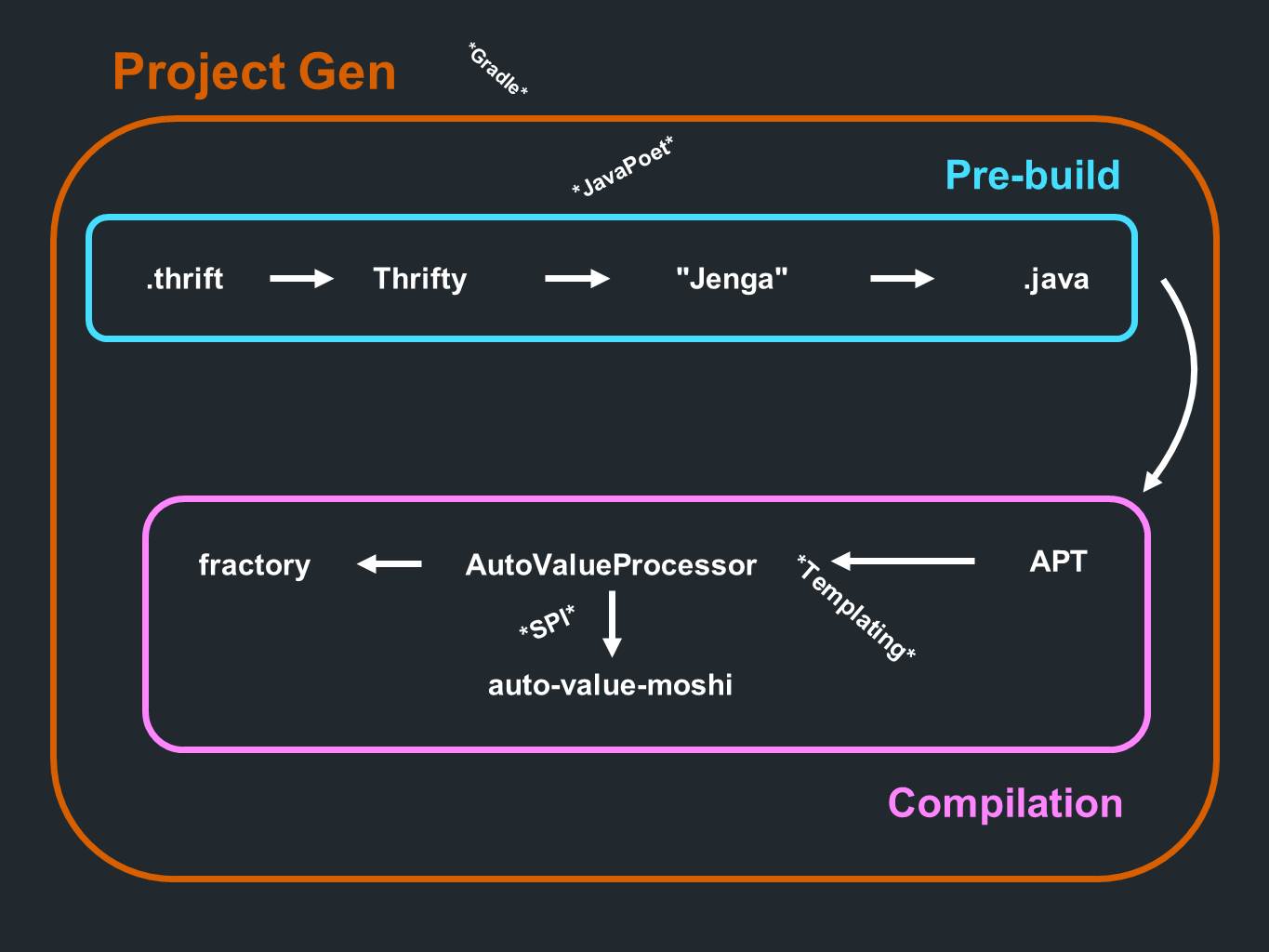
Kami memiliki barang
bekas . Data dari sana pergi ke
Hemat dan melewati parsing. Mereka kemudian pergi melalui program pembuatan kode yang kita sebut
Jenga . Ini menghasilkan file dalam format Java. Semua ini terjadi bahkan sebelum tahap awal pemrosesan atau sebelum kompilasi. Dan selama proses kompilasi, anotasi diproses. Sekarang
giliran AutoValue untuk menghasilkan implementasi. Itu juga memanggil
AutoValue Moshi untuk memberikan dukungan JSON.
Fractory juga
terlibat . Semuanya terjadi selama proses kompilasi. Proses ini didahului oleh komponen untuk membuat proyek itu sendiri, yang terutama menghasilkan sub proyek
Gradle .
Sekarang setelah Anda melihat gambaran lengkapnya, Anda mulai memperhatikan alat-alat yang disebutkan sebelumnya. Jadi, misalnya, ada Gradle, membuat templat, AutoValue, JavaPoet untuk pembuatan kode. Semua alat tidak hanya berguna sendiri, tetapi juga dalam kombinasi satu sama lain.Kontra pembuatan kode
Penting untuk menceritakan tentang jebakan. Minus yang paling jelas adalah membengkak kode dan kehilangan kendali. Misalnya, Belati membutuhkan sekitar 10% dari semua kode dalam aplikasi. Model menempati bagian yang jauh lebih besar - sekitar 25%.Di Uber, kami mencoba menyelesaikan masalah dengan membuang kode yang tidak perlu. Kami harus melakukan beberapa analisis statistik kode dan memahami bidang mana yang benar-benar terlibat dalam pekerjaan. Ketika kita mengetahuinya, kita dapat membuat beberapa transformasi dan melihat apa yang terjadi.Kami berharap dapat mengurangi jumlah model yang dihasilkan sekitar 40%. Ini akan membantu mempercepat instalasi dan pengoperasian aplikasi, serta menghemat uang kita.Bagaimana pembuatan kode memengaruhi jadwal pengembangan proyek
Pembuatan kode, tentu saja, mempercepat pengembangan, tetapi waktunya tergantung pada alat yang digunakan tim. Misalnya, jika Anda bekerja di Gradle, kemungkinan besar Anda melakukannya dengan kecepatan yang terukur. Faktanya adalah bahwa Gradle menghasilkan model sekali sehari, dan tidak ketika pengembang menginginkannya.Pelajari lebih lanjut tentang pengembangan di Uber dan perusahaan top lainnya.
Pada 28 September, Konferensi Internasional Pengembang Mobile ke-5 MBLT DEV dimulai di Moskow . 800 peserta, pembicara top, kuis dan teka-teki bagi mereka yang tertarik dengan pengembangan Android dan iOS. Penyelenggara konferensi adalah e-Legion dan RAEC. Anda dapat menjadi peserta atau mitra MBLT DEV 2018 di situs web konferensi .
Laporkan video