
Musim panas lalu,
kompetisi di situs kaggle, yang didedikasikan untuk klasifikasi citra satelit hutan Amazon, berakhir. Tim kami mengambil tempat ke-7 dari 900+ peserta. Terlepas dari kenyataan bahwa kompetisi telah berakhir sejak lama, hampir semua metode solusi kami masih berlaku, dan tidak hanya untuk kompetisi, tetapi juga untuk pelatihan jaringan saraf untuk dijual. Untuk detail di bawah kucing.
tldr.pyimport kaggle from ods import albu, alno, kostia, n01z3, nizhib, romul, ternaus from dataset import x_train, y_train, x_test oof_train, oof_test = [], [] for member in [albu, alno, kostia, n01z3, nizhib, romul, ternaus]: for model in member.models: model.fit_10folds(x_train, y_train, config=member.fit_config) oof_train.append(model.predict_oof_tta(x_train, config=member.tta_config)) oof_test.append(model.predict_oof_tta(x_test, config=member.tta_config)) for model in albu.second_level: model.fit(oof_train) y_test = model.predict_proba(oof_test) y_test = kostia.bayes_f2_opt(y_test) kaggle.submit(y_test)
Deskripsi tugas
Planet menyiapkan satu set gambar satelit dalam dua format:
- TIF - 16 bit RGB + N, di mana N - Near Infra Red
- JPG - 8bit RGB, yang berasal dari TIF dan yang disediakan untuk mengurangi ambang untuk memasuki tugas, serta untuk menyederhanakan visualisasi. Dalam kompetisi sebelumnya di Kaggle, perlu untuk bekerja dengan gambar multispektral. non-visual, yaitu inframerah, serta saluran dengan panjang gelombang yang lebih lama, sangat meningkatkan kualitas prediksi, baik metode jaringan maupun tanpa pengawasan.
Secara geografis, data diambil dari wilayah cekungan Amazon, dan dari wilayah negara-negara Brazil, Peru, Uruguay, Kolombia, Venezuela, Guyana, Bolivia dan Ekuador, di mana area permukaan yang menarik dipilih, gambar-gambar dari mana ditawarkan kepada para peserta.
Setelah membuat jpg dari tif, semua adegan dipotong menjadi ukuran kecil 256x256. Dan menurut jpg yang diterima oleh karyawan Planet dari kantor Berlin dan San Francisco, serta melalui platform Crowd Flower, penandaan dilakukan.
Para peserta ditugaskan untuk memprediksi setiap ubin 256x256 salah satu dari tanda cuaca yang saling eksklusif:
Berawan, Berawan sebagian, Haze, Clear
Dan juga 0 atau lebih cuaca buruk: Pertanian, Primer, Penebangan Selektif, Tempat Tinggal, Air, Jalan, Budidaya Pergeseran, Blooming, Penambangan Konvensional
Sebanyak 4 cuaca dan 13 non-cuaca, cuaca saling eksklusif, tetapi tidak ada cuaca, tetapi jika gambarnya mendung, maka seharusnya tidak ada tag lain.

Keakuratan model diperkirakan oleh metrik F2:
Selain itu, semua label memiliki bobot yang sama dan F2 pertama dihitung untuk setiap gambar, dan kemudian ada rata-rata umum. Biasanya mereka melakukannya sedikit berbeda, yaitu, metrik tertentu dihitung untuk setiap kelas, dan kemudian dirata-rata. Logikanya adalah bahwa opsi terakhir lebih dapat ditafsirkan, karena memungkinkan Anda untuk menjawab pertanyaan tentang bagaimana model berperilaku pada setiap kelas tertentu. Dalam hal ini, penyelenggara berjalan sesuai dengan opsi pertama, yang, tampaknya, terkait dengan kekhasan bisnis mereka.
Ada 40 ribu sampel di kereta. Dalam tes 40k. Karena ukuran dataset yang kecil, tetapi ukuran gambar yang besar, kita dapat mengatakan bahwa ini adalah "MNIST on steroid"
Penyimpangan lirisSeperti yang dapat Anda lihat dari deskripsi, tugasnya cukup dimengerti dan solusinya bukan rasa roket: Anda hanya perlu mengajukan kisi. Dan dengan mempertimbangkan spesifik dari cuggle, Anda juga dapat menumpuk banyak model di atas. Namun, untuk mendapatkan medali emas, Anda tidak perlu hanya melatih banyak model. Sangat penting untuk memiliki banyak model beragam dasar, yang masing-masing dengan sendirinya menunjukkan hasil yang luar biasa. Dan sudah di atas model ini Anda dapat berakhir menumpuk dan hack lainnya.
| anggota | bersih | 1crop | Tta | diff,% |
|---|
| alno | densenet121 | 0,9278 | 0,9294 | 0,1736 |
| nizhib | densenet169 | 0,9243 | 0,9277 | 0,3733 |
| Romul | vgg16 | 0,9266 | 0,9267 | 0,0186 |
| ternaus | densenet121 | 0,9232 | 0,9241 | 0,0921 |
| albu | densenet121 | 0,9294 | 0,9312 | 0,1933 |
| kostia | resnet50 | 0,9262 | 0,9271 | 0,0907 |
| n01z3 | resnext50 | 0,9281 | 0,9298 | 0,1896 |
Tabel menunjukkan model skor F2 dari semua peserta untuk tanaman tunggal dan TTA. Seperti yang Anda lihat, perbedaannya kecil untuk penggunaan nyata, tetapi penting untuk mode kompetisi.
Interaksi timAlexander Buslaev
albuPada saat berpartisipasi dalam kompetisi, ia memimpin seluruh arah ml di Geoscan. Tetapi sejak itu ia menyeret banyak kompetisi, menjadi bapak dari semua ODS di segmentasi semantik dan pergi ke Minsk, mendayung di Mapbox, tentang
artikel yang
diterbitkanAlexey Noskov
jugaUniversal ml fighter. Bekerja di Mars Jahat. Sekarang berguling ke Yandex.
Konstantin Lopukhin
kostialopuhinBekerja dan terus bekerja di Scrapinghub. Sejak itu, Kostya berhasil mendapatkan beberapa medali lagi dan tanpa 5 menit Kaggle Grandmaster
Arthur Cousin
n01z3Pada saat berpartisipasi dalam kompetisi ini, saya bekerja di Avito. Tetapi sekitar tahun baru, startup
Dbrain's Lead Data Scientist berguling ke blockchain. Saya berharap bahwa kami akan segera menyenangkan komunitas dengan kompetisi kami dengan buruh pelabuhan dan lampu.
Evgeny Nizhibitsky
@nizhibLead Data Scientist di Rambler & Co. Dari kompetisi ini, Eugene menemukan kemampuan rahasia untuk menemukan wajah di kompetisi gambar. Apa yang membantunya untuk menyeret beberapa kompetisi di platform Topcoder. Saya
berbicara tentang salah satunya.
Ruslan
Baykulov romulTerlibat dalam pelacakan acara olahraga di Constanta.
Vladimir Iglovikov
ternausAnda bisa diingat untuk
artikel penuh aksi tentang pelecehan oleh intelijen Inggris. Dia bekerja di TrueAccord, tetapi kemudian meluncur ke Lyft pemuda yang trendi. Di mana Computer Vision bekerja untuk mobil Mengemudi Mandiri. Terus menyeret kompetisi dan baru-baru ini menerima Grandmaster Kaggle.
Asosiasi dan format partisipasi kami dapat disebut tipikal. Keputusan untuk bersatu adalah karena fakta bahwa kami semua memiliki hasil yang dekat di papan peringkat. Dan masing-masing dari kami menggergaji pipa independen kami sendiri, yang merupakan solusi yang sepenuhnya otonom dari awal hingga akhir. Juga, setelah merger, beberapa peserta terlibat dalam penumpukan.
Hal pertama yang kami lakukan adalah berbagi lipatan. Kami memastikan bahwa distribusi kelas di setiap lipatan sama dengan di seluruh dataset. Untuk ini, kelas yang paling langka pertama kali dipilih, dikelompokkan berdasarkan itu, karena gambar yang tersisa dikelompokkan berdasarkan kelas paling populer kedua, dan seterusnya sampai tidak ada gambar yang tersisa.
Histogram kelas lipatan:
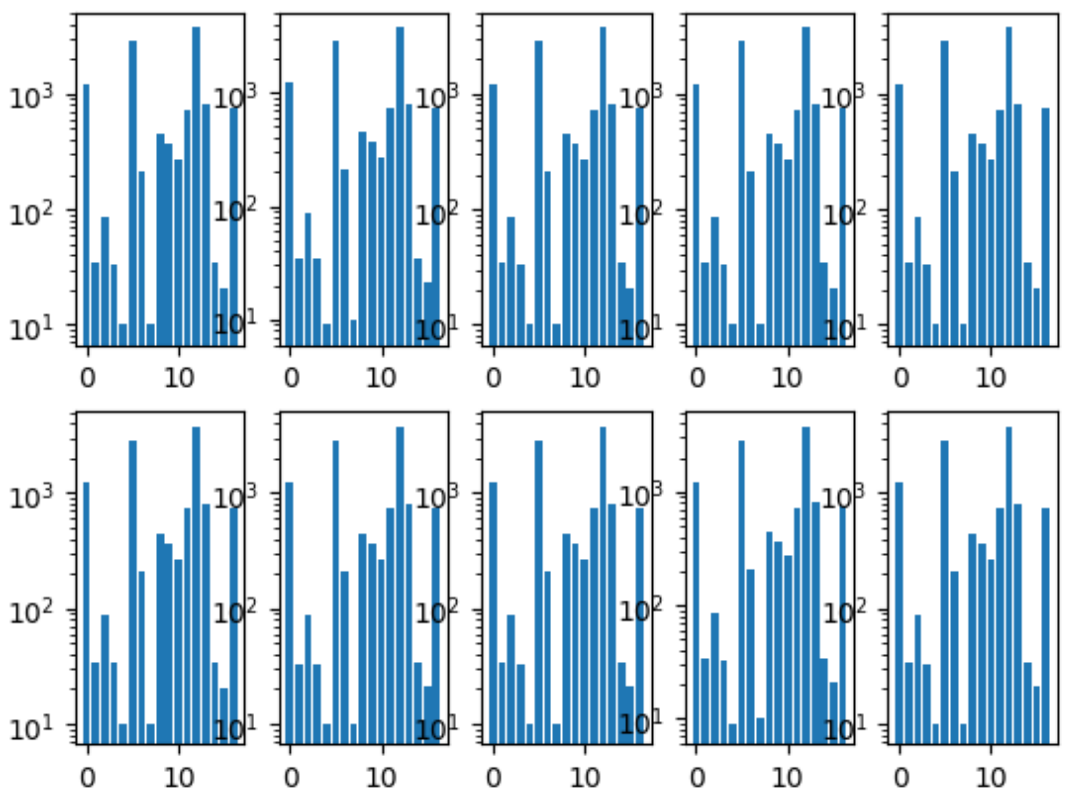
Kami juga memiliki repositori bersama, di mana setiap anggota tim memiliki foldernya sendiri, di mana ia mengatur kodenya sesuai keinginannya.
Dan kami juga menyetujui format prediksi, karena ini adalah satu-satunya titik interaksi untuk menggabungkan model kami.
Pelatihan jaringan sarafKarena masing-masing dari kami memiliki jalur pipa independen, kami adalah contoh grid dari proses pembelajaran optimal yang diparalelkan dengan orang.
Pendekatan umum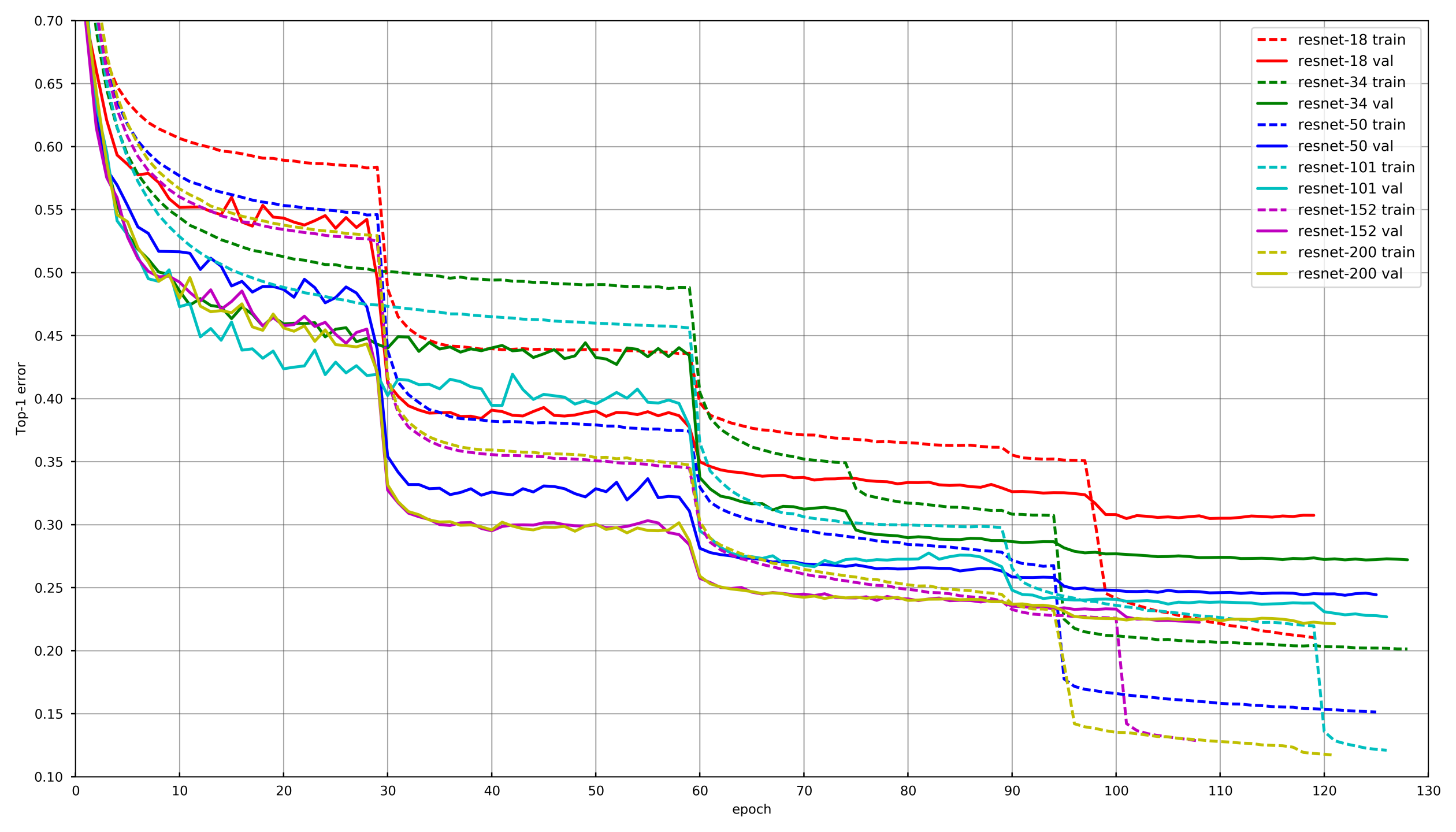
Gambar dari
github.com/tornadomeet/ResNetProses pembelajaran yang khas disajikan pada jadwal pelatihan jaringan saraf Resnet pada imagenet. Mereka mulai dari bobot yang diinisialisasi secara acak dengan SGD (lr. 0,1 Nesterov Momentum 0,0001 WD 0,9) dan kemudian setelah 30 menghapus lebih rendah tingkat belajar sebesar 10 kali.
Secara konseptual, masing-masing dari kita menggunakan pendekatan yang sama, agar tidak menjadi tua saat setiap jaringan sedang dilatih, penurunan LR terjadi jika validasi tidak menjatuhkan kerugian selama 3-5 era berturut-turut. Atau, beberapa peserta hanya mengurangi jumlah era pada setiap kerusakan LR dan menurunkan sesuai jadwal.
AugmentasiMemilih augmentasi yang tepat sangat penting ketika melatih jaringan saraf. Augmentasi harus mencerminkan variabilitas sifat data. Secara konvensional, augmentasi dapat dibagi menjadi dua jenis: yang memberikan bias dalam data, dan yang tidak. Secara bias, seseorang dapat memahami berbagai statistik tingkat rendah, seperti histogram warna atau ukuran karakteristik. Dalam hal ini, katakanlah, penambahan dan skala HSV memperkenalkan offset, tetapi pemangkasan acak tidak.
Pada tahap pertama pelatihan jaringan, Anda bisa melangkah terlalu jauh dengan augmentasi dan menggunakan perangkat yang sangat sulit. Namun, menjelang akhir pelatihan, Anda harus mematikan augmentasi atau hanya menyisakan augmentasi. Ini memungkinkan jaringan saraf untuk berpakaian sedikit di bawah kereta dan menunjukkan hasil yang sedikit lebih baik pada validasi.
Pembekuan lapisanDalam sebagian besar tugas, tidak masuk akal untuk melatih jaringan saraf dari awal, jauh lebih efisien untuk mengutak-atik jaringan pra-terlatih, kata dengan Imagenet. Namun, Anda dapat melangkah lebih jauh dan tidak hanya mengubah lapisan yang sepenuhnya terhubung di bawah lapisan dengan jumlah kelas yang diinginkan, tetapi pertama-tama latihlah dengan membekukan semua konvolusi. Jika Anda tidak membekukan konvolusi dan segera melatih seluruh jaringan dengan bobot yang diinisialisasi secara acak dari lapisan yang terhubung penuh, maka bobot konvolusi akan rusak dan kinerja akhir dari jaringan saraf akan lebih rendah. Pada tugas ini, ini terutama terlihat karena ukuran sampel pelatihan yang kecil. Dalam kompetisi lain dengan sejumlah besar data seperti cdiscount, dimungkinkan untuk tidak membekukan seluruh jaringan saraf, tetapi kelompok konvolusi dari akhir. Dengan cara ini, pelatihan bisa sangat dipercepat, karena gradien tidak dipertimbangkan untuk lapisan beku.
Anil siklikProses ini terlihat seperti ini. Setelah selesainya proses pelatihan dasar jaringan saraf, bobot terbaik diambil dan proses pelatihan diulang. Tapi itu dimulai dengan tingkat Belajar yang lebih rendah dan terjadi dalam waktu singkat, katakanlah 3-5 era. Ini memungkinkan jaringan saraf untuk turun ke minimum lokal yang lebih rendah dan menunjukkan kinerja yang lebih baik. Kampanye stabil ini meningkatkan hasil dalam sejumlah besar kontes.
Lebih detail tentang dua resepsi
di siniAugmentasi waktu tesKarena ini adalah kompetisi dan kami tidak memiliki batasan resmi mengenai waktu inferensi, Anda dapat menggunakan augmentasi selama tes. Sepertinya gambar itu terdistorsi dengan cara yang sama seperti yang terjadi selama pelatihan. Katakanlah, itu dipantulkan secara vertikal, horizontal, diputar oleh sudut, dll. Setiap augmentasi memberikan gambar baru dari mana kita mendapatkan prediksi. Kemudian prediksi distorsi seperti itu dari satu gambar dirata-ratakan (sebagai aturan dengan cara geometris). Itu juga memberi untung. Di kompetisi lain, saya juga bereksperimen dengan augmentasi acak. Katakanlah, Anda dapat menerapkan tidak satu per satu, tetapi cukup mengurangi amplitudo untuk belokan acak, kontras dan augmentasi warna hingga setengahnya, perbaiki seed dan buat beberapa gambar yang terdistorsi secara acak. Ini juga memberi peningkatan.
Ensembling Foto (Multicheckpoint TTA)Gagasan tentang anil dapat dikembangkan lebih lanjut. Pada setiap tahap anil, jaringan saraf terbang ke minima lokal yang sedikit berbeda. Dan ini berarti bahwa ini adalah model yang sedikit berbeda yang dapat dirata-ratakan. Dengan demikian, selama prediksi tes, Anda dapat mengambil tiga pos pemeriksaan terbaik dan rata-rata prediksi mereka. Saya juga mencoba untuk tidak mengambil tiga yang terbaik, tetapi tiga yang paling beragam dari 10 pos pemeriksaan teratas - itu lebih buruk. Nah, untuk produksi trik seperti itu tidak berlaku dan saya mencoba untuk rata-rata berat model. Ini memberikan peningkatan yang sangat tidak signifikan tetapi tetap.
 Pendekatan masing-masing anggota tim
Pendekatan masing-masing anggota timOleh karena itu, pada tingkat tertentu, setiap anggota tim kami menggunakan kombinasi berbeda dari teknik di atas.
| nick | Konv bekukan,
zaman | Pengoptimal | Strategi | Agustus | Tta |
|---|
| albu | 3 | SGD | 15 zaman pembusukan LR,
Lingkaran 13 zaman | D4,
Skala,
Offset
Distorsi
Kontras
Kabur | D4 |
|---|
| alno | 3 | SGD | Pembusukan | D4,
Skala,
Offset
Distorsi
Kontras
Kabur
Geser
Pengganda saluran | D4 |
|---|
| n01z3 | 2 | SGD | Drop LR, pasien 10 | D4,
Skala,
Distorsi
Kontras
Kabur | D4, 3 pos pemeriksaan |
|---|
| ternaus | - | Adam | Cyclic LR (1e-3: 1e-6) | D4,
Skala,
Tambah saluran
Kontras | D4,
tanaman acak |
|---|
| nizhib | - | Adam | StepLR, 60 zaman, 20 per peluruhan | D4,
RandomSizedCrop | D4,
4 sudut,
pusat
skala |
|---|
| kostia | 1 | Adam | | D4,
Skala,
Distorsi
Kontras
Kabur | D4 |
|---|
| Romul | - | SGD | base_lr: 0,01 - 0,02
lr = base_lr * (0,33 ** (zaman / 30))
Zaman: 50 | D4, Skala | D4, Pangkas tengah,
Tanaman pojok |
|---|
Susun dan retasKami melatih setiap model dengan setiap set parameter pada 10 lipatan. Dan kemudian pada prediksi out of fold (OOF) kami mengajarkan model tingkat kedua: Pohon Ekstra, Regresi Linier, Jaringan Saraf Tiruan dan model rata-rata sederhana.
Dan sudah di OOF, prediksi model tingkat kedua mengambil bobot untuk pencampuran. Anda dapat membaca lebih lanjut tentang menumpuk di
sini dan di
sini .
Dalam produksi nyata, anehnya, pendekatan ini juga terjadi. Misalnya, ketika ada data multimodal (gambar, teks, kategori, dll.) Dan Anda ingin menggabungkan prediksi model. Anda cukup meratakan probabilitas, tetapi melatih model tingkat kedua memberikan hasil terbaik.
Optimasi Ba F2Juga, prediksi akhir sedikit disetel menggunakan optimasi Bayesian. Misalkan kita memiliki probabilitas ideal, maka F2 dengan mat harapan terbaik (yaitu tipe optimal) diperoleh dengan rumus berikut:
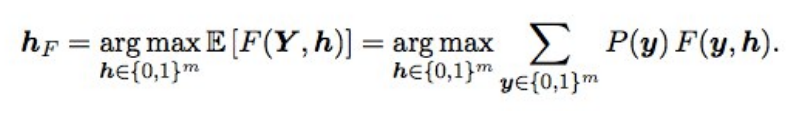
Apa artinya ini? Kita perlu memilah-milah semua kombinasi (mis., Untuk setiap label 0 dan 1), menghitung probabilitas setiap kombinasi, dan mengalikannya dengan F2 - kita mendapatkan F2 yang diharapkan. Kombinasi mana yang lebih baik, dan akan memberikan F2 yang optimal. Peluang dianggap hanya penggandaan dari probabilitas masing-masing label (jika labelnya 0, kita ambil 1 - p), dan agar tidak memilah 2 hingga 17 pilihan, hanya label dengan probabilitas 0,05 hingga 0,5 yang terhuyung-huyung - ada 3-7 dari mereka secara berurutan, sehingga pilihan tersebut sedikit (pengiriman dilakukan dalam beberapa menit). Secara teori, akan lebih baik untuk mendapatkan probabilitas kombinasi label, tidak hanya mengalikan probabilitas individu (karena label tidak independen), tetapi tidak berhasil.
apa yang dia berikan? ketika model menjadi baik, pemilihan ambang batas setelah ansambel berhenti bekerja, dan hal ini memberikan peningkatan yang kecil namun stabil dalam validasi dan publik / swasta.
Kata penutupSebagai hasilnya, kami melatih 48 model yang berbeda, masing-masing pada 10 lipatan, yaitu 480 model tingkat pertama. Gridchurch manusia seperti itu memungkinkan saya untuk mencoba teknik yang berbeda ketika melatih jaringan saraf convolutional yang mendalam, yang masih saya gunakan dalam pekerjaan dan kompetisi.
Apakah mungkin untuk melatih lebih sedikit model dan mendapatkan hasil yang sama atau lebih baik? Ya cukup. Rekan sebangsa kami dari tempat ke-3, Stanislav
stasg7 Semenov dan Roman
ZFTurbo Soloviev, menghabiskan biaya lebih sedikit untuk model tingkat pertama dan mengimbangi 250+ model tingkat kedua. Tentang solusinya, Anda dapat
melihat analisis dan
membaca posting.
Tempat pertama pergi ke pertandingan misterius yang terbaik. Secara umum, orang ini sangat keren, dan sekarang dia telah menjadi peringkat 1 Keggle teratas, setelah menarik banyak kompetisi gambar. Dia tetap anonim untuk waktu yang lama, sampai Nvidia memecahkan sampulnya dengan
mewawancarainya . Di mana ia mengakui bahwa 200 bawahan akan melapor kepadanya ... Ada juga
pos tentang keputusan itu.
Satu lagi yang menarik: dikenal luas di kalangan sempit
Jeremy Howard , ayah
fastai jadi 22m. Dan jika Anda berpikir bahwa dia hanya mengirim beberapa kiriman untuk penggemarnya, maka Anda tidak menebaknya. Dia berpartisipasi dalam tim dan mengirim 111 paket.
Juga, mahasiswa pascasarjana Stanford yang mengambil kursus CS231n legendaris pada waktu itu, dan yang diizinkan untuk menggunakan tugas ini sebagai proyek kursus, menyelesaikan seluruh tim di tengah-tengah papan peringkat.
Sebagai bonus, saya
berbicara di Mail.ru dengan materi posting ini dan berikut adalah
presentasi lain
dari Vladimir Iglovikov dari sebuah pertemuan di Valley.