"Meneliti Pasar Lowongan Analis" adalah tugas yang sangat nyata dari seorang analis terkemuka yang sangat nyata dari perusahaan besar atau kecil. Parser mengarsipkan puluhan deskripsi pekerjaan dengan hh secara manual, menyebarkannya sesuai dengan keterampilan yang diminta dan meningkatkan penghitung di kolom spreadsheet yang sesuai.
Saya melihat dalam tugas ini bidang yang bagus untuk otomatisasi dan memutuskan untuk mencoba mengatasinya dengan lebih sedikit darah, dengan mudah dan sederhana.
Saya tertarik pada masalah berikut yang diangkat dalam penelitian ini:
- gaji rata-rata untuk analis bisnis dan sistem,
- keterampilan dan kualitas pribadi yang paling dituntut dalam posisi ini,
- ketergantungan (jika ada) antara keterampilan tertentu dan tingkat gaji.
Spoiler: itu tidak berhasil dengan mudah dan sederhana.
Persiapan data
Jika kami ingin mengumpulkan banyak data tentang lowongan, maka masuk akal jika tidak dibatasi. Namun, untuk kemurnian percobaan kesederhanaan, kita mulai dengan sumber ini.
Koleksi
Untuk mengumpulkan data, kami akan menggunakan pencarian kerja melalui API jam.
Saya akan mencari menggunakan kueri teks sederhana "analis sistem", "analis bisnis" dan "pemilik produk", karena aktivitas dan bidang tanggung jawab di posisi ini, sebagai aturan, tumpang tindih.
Untuk melakukan ini, buat permintaan formulir https://api.hh.ru/vacancies?text="systems+analyst" dan uraikan JSON yang diterima.
Untuk mendapatkan lowongan yang paling relevan dalam sampel, kami hanya akan mencari di header lowongan dengan menambahkan parameter search_field=name ke kueri.
Di sini Anda dapat melihat bidang kekosongan mana yang dikembalikan untuk permintaan ini. Saya memilih yang berikut ini:
- jabatan
- kota
- tanggal publikasi
- gaji - batas atas dan bawah
- mata uang di mana gaji ditunjukkan
- kotor - T / F
- perusahaan
- tanggung jawab
- persyaratan untuk kandidat
Selain itu, saya ingin menganalisis lebih lanjut keterampilan yang ditunjukkan di bagian Keterampilan Kunci, tetapi bagian ini hanya tersedia dalam uraian tugas lengkap. Oleh karena itu, saya juga akan menyimpan tautan ke lowongan yang ditemukan, untuk kemudian mendapatkan daftar keterampilan untuk masing-masing.
Lihat kode # :) library(jsonlite) library(curl) library(dplyr) library(ggplot2) library(RColorBrewer) library(plotly) hh.getjobs <- function(query, paid = FALSE) { # Makes a call to hh API and gets the list of vacancies based on the given search queries df <- data.frame( query = character() # , URL = character() # , id = numeric() # id , Name = character() # , City = character() , Published = character() , Currency = character() , From = numeric() # . , To = numeric() # . , Gross = character() , Company = character() , Responsibility = character() , Requerement = character() , stringsAsFactors = FALSE ) for (q in query) { for (pageNum in 0:99) { try( { data <- fromJSON(paste0("https://api.hh.ru/vacancies?search_field=name&text=\"" , q , "\"&search_field=name" , "&only_with_salary=", paid ,"&page=" , pageNum)) df <- rbind(df, data.frame( q, data$items$url, as.numeric(data$items$id), data$items$name, data$items$area$name, data$items$published_at, data$items$salary$currency, data$items$salary$from, data$items$salary$to, data$items$salary$gross, data$items$employer$name, data$items$snippet$responsibility, data$items$snippet$requirement, stringsAsFactors = FALSE)) }) print(paste0("Downloading page:", pageNum + 1, "; query = \"", q, "\"")) } } names <- c("query", "URL", "id", "Name", "City", "Published", "Currency", "From", "To", "Gross", "Company", "Responsibility", "Requirement") colnames(df) <- names return(df) }
Dalam fungsi hh.getjobs() , input menerima vektor permintaan pencarian yang menarik bagi kami dan penyempurnaan, kami hanya tertarik pada lowongan dengan gaji yang ditentukan atau semuanya dalam satu baris (secara default kami mengambil opsi kedua). Frame dafa kosong dibuat, dan kemudian fungsi fromJSON() dari paket fromJSON() jsonlite , yang mengambil URL input dan mengembalikan daftar terstruktur. Selanjutnya, dari node dalam daftar ini, kami mendapatkan data yang kami minati dan mengisi bidang bingkai data yang sesuai.
Secara default, data diberikan halaman demi halaman, dengan 20 elemen pada setiap halaman. Untuk maksimal 2.000 lowongan pekerjaan. Semua data yang kami terima dicatat dalam df .
Retas seumur hidup 1: Sama sekali bukan fakta bahwa atas permintaan kami akan ada 2.000 lowongan, dan mulai pada titik tertentu kami akan menerima halaman kosong. Dalam hal ini, R bersumpah dan melompat keluar dari loop. Karenanya, kami dengan hati-hati membungkus isi loop dalam dengan try() .
Life hack 2: masuk akal untuk menambahkan output dari status pengumpulan data saat ini ke konsol dalam loop internal, karena ini bukan bisnis yang cepat. Saya melakukan ini:
print(paste0("Downloading page:", pageNum + 1, "; query = \"", query, "\""))
Setelah mengisi data, kolom diubah namanya sehingga nyaman untuk bekerja dengannya, dan frame data yang dihasilkan dikembalikan.
Saya akan menyimpan ini dan fungsi tambahan lainnya dalam fungsi yang terpisah. File R agar tidak mengacaukan skrip utama, yang sejauh ini terlihat seperti ini:
source("functions.R") # Step 1 - get data # 1.1 get vacancies (short info) jobdf <- hh.getjobs(query = c("business+analyst" , "systems+analyst" , "product+owner"), paid = FALSE)
Sekarang kita akan mendapatkan experience dan key_skills dari deskripsi pekerjaan lengkap .
hh.getxp meneruskan bingkai data ke fungsi hh.getxp , menelusuri tautan yang disimpan ke lowongan, dan dari uraian lengkap kami mendapatkan nilai pengalaman kerja yang diperlukan. Nilai yang dihasilkan disimpan dalam kolom baru.
Lihat kode hh.getxp <- function(df) { df$experience <- NA for (myURL in df$URL) { try( { data <- fromJSON(myURL) df[df$URL == myURL, "experience"] <- data$experience$name } ) print(paste0("Filling in ", which(df$URL == myURL, arr.ind = TRUE), "from ", nrow(df))) } return(df) }
Deskripsi fungsi pembantu baru dikirim ke functions.R , dan skrip utama sekarang mengaksesnya:
# s.1.2 get experience (from full info) jobdf <- hh.getxp(jobdf) # 1.3 get skills (from full info) all.skills <- hh.getskills(jobdf$URL)
Dalam fragmen di atas, kami juga membentuk bingkai data baru all.skills bentuk "job id - skill":
Lihat kode hh.getskills <- function(allurls) { analyst.skills <- data.frame( id = character(), # id skill = character() # ) for (myURL in allurls) { data <- fromJSON(myURL) if (length(data$key_skills) > 0) analyst.skills <- rbind(analyst.skills, cbind(data$id, data$key_skills)) print(paste0("Filling in " , which(allurls == myURL, arr.ind = TRUE) , " out of " , length(allurls))) } names(analyst.skills) <- c("id", "skill") analyst.skills$skill <- tolower(analyst.skills$skill) return(analyst.skills) }
Preprocessing
Mari kita lihat berapa banyak data yang berhasil kami kumpulkan:
> length(unique(jobdf$id)) [1] 1478 > length(jobdf$id) [1] 1498
Hampir satu setengah ribu pekerjaan! Itu terlihat bagus. Dan ternyata, beberapa lowongan masuk ke hasil pencarian dua kali - untuk permintaan yang berbeda. Oleh karena itu, langkah pertama adalah hanya meninggalkan entri unik: jobdf <- jobdf[unique(jobdf$id),] .
Untuk membandingkan gaji para analis pasar tenaga kerja, saya perlu
1) memastikan bahwa semua data gaji yang tersedia disajikan dalam mata uang tunggal,
2) pilih dalam kerangka data terpisah lowongan-lowongan yang untuknya gaji ditunjukkan.
Kami mempertimbangkan masing-masing subtugas lebih terinci. Sebelumnya, Anda dapat mengetahui mata uang apa yang ditemukan dalam data kami menggunakan table(jobdf$Currency) . Dalam kasus saya, selain rubel, dolar, euro, hryvnias, tenge Kazakhstan, dan bahkan jumlah Uzbek muncul.
Untuk mengonversi nilai gaji menjadi rubel, Anda perlu mengetahui nilai tukar saat ini. Kami akan mencari tahu dari Bank Sentral :
Lihat kode quotations.update <- function(currencies) { # Parses the most up-to-date qutations data provided by the Central Bank of Russia # and returns a table with currency rate against RUR doc <- XML::xmlParse("http://www.cbr.ru/scripts/XML_daily.asp") quotationsdf <- XML::xmlToDataFrame(doc, stringsAsFactors = FALSE) quotationsdf <- select(quotationsdf, -Name) quotationsdf$NumCode <- as.numeric(quotationsdf$NumCode) quotationsdf$Nominal <- as.numeric(quotationsdf$Nominal) quotationsdf$Value <- as.numeric(sub(",", ".", quotationsdf$Value)) quotationsdf$Value <- quotationsdf$Value / quotationsdf$Nominal quotationsdf <- quotationsdf %>% select(CharCode, Value) return(quotationsdf) }
Untuk memastikan bahwa program diproses dengan benar dalam R, Anda perlu memastikan bahwa bagian desimal dipisahkan oleh titik. Selain itu, Anda harus memperhatikan kolom Nominal: di suatu tempat itu 1, di suatu tempat 10 atau 100. Ini berarti bahwa satu pound sterling berharga ~ 85 rubel, dan, katakanlah, untuk seratus drum Armenia Anda dapat membeli ~ 13 rubel. Untuk kenyamanan pemrosesan lebih lanjut, saya mengurangi nilai ke nominal 1 relatif terhadap rubel.
Sekarang Anda bisa menerjemahkan. Script kami melakukan ini menggunakan fungsi convert.currency() . Nilai tukar saat ini diambil dari tabel quotations , tempat kami menyimpan data dari XML yang disediakan oleh Bank Sentral. Juga, fungsi input menerima mata uang target untuk konversi (secara default RUR) dan tabel dengan lowongan, nilai-nilai garpu gaji di mana perlu untuk mengarah ke mata uang tunggal. Fungsi mengembalikan tabel dengan angka gaji yang diperbarui (sudah tanpa kolom Mata Uang, jika tidak perlu).
Saya harus mengotak-atik rubel Belarusia: setelah menerima data yang sangat aneh dalam beberapa pendekatan, saya melakukan penelitian kecil dan menemukan bahwa sejak 2016 mata uang baru telah digunakan di Belarus, yang tidak hanya berbeda dalam nilai tukar, tetapi juga dalam singkatan (sekarang bukan BYR, tetapi BYN) . Dalam direktori hh, singkatan BYR masih digunakan, yang XML dari Bank Sentral tidak tahu apa-apa. Oleh karena itu, dalam fungsi convert.currency() I tidak dengan cara yang paling elegan Pertama, saya mengganti singkatan dengan yang sekarang, dan baru kemudian langsung menuju konversi.
Ini terlihat seperti ini:
Lihat kode convert.currency <- function(targetCurrency = "RUR", df, quotationsdf) { cond <- (!is.na(df$Currency) & df$Currency == "BYR") df[cond, "Currency"] <- "BYN" currencies <- unique(na.omit(df$Currency[df$Currency != targetCurrency])) # ( ) if (!is.null(df$From)) { for (currency in currencies) { condition <- (!is.na(df$From) & df$Currency == currency) try( df$From[condition] <- df$From[condition] * quotationsdf$Value[quotationsdf$CharCode == currency] ) } } # ( ) if (!is.null(df$To)) { for (currency in currencies) { condition <- !is.na(df$To) & df$Currency == currency try( df$To[condition] <- df$To[condition] * quotationsdf$Value[quotationsdf$CharCode == currency] ) } } return(df %>% select(-Currency)) }
Anda juga dapat mempertimbangkan bahwa beberapa data gaji disajikan dalam nilai kotor, yaitu, karyawan akan menerima sedikit lebih sedikit di tangan. Untuk menghitung gaji bersih untuk penduduk Federasi Rusia, 13% harus dikurangkan dari angka-angka ini (30% dikurangkan untuk bukan penduduk).
Lihat kode gross.to.net <- function(df, resident = TRUE) { if (resident == TRUE) coef <- 0.87 else coef <- 0.7 if (!is.null(df$Gross)) { if (!is.null(df$From)) # ( ) { index <- na.omit(as.numeric(rownames(df[!is.na(df$From) & df$Gross == TRUE,]))) df$From[index] <- df$From[index] * coef } if (!is.null(df$To)) # ( ) { index <- na.omit(as.numeric(rownames(df[!is.na(df$To) & df$Gross == TRUE,]))) df$To[index] <- df$To[index] * coef } df <- df %>% select(-Gross) } return(df) }
Tentu saja, saya tidak akan melakukan ini, karena dalam hal ini perlu mempertimbangkan pajak di berbagai negara, dan tidak hanya di Rusia, atau menambahkan filter menurut negara dalam permintaan pencarian awal.
Langkah terakhir sebelum analisis adalah untuk membagi lowongan yang ditemukan menjadi tiga kategori: Juni, Tengah dan Senior, dan tulis posisi yang diterima di kolom baru. Posisi senior akan mencakup orang-orang yang mengatasnamakan kata "senior" dan sinonimnya. Demikian pula, kami akan menemukan posisi awal untuk kata kunci "junior" dan sinonim, dan di antara middles kami menyertakan semua di antaranya:
get.positions <- function(df) { df$lvl <- NA df[grep(pattern = "lead|senior|||", x = df$Name, ignore.case = TRUE), "lvl"] <- "senior" df[grep(pattern = "junior|||", x = df$Name, ignore.case = TRUE), "lvl"] <- "junior" df[is.na(df$lvl), "lvl"] <- "middle" return(df) }
Tambahkan blok persiapan data ke skrip utama.
Ditambahkan # Step 2 - prepare data # 2.1. Convert all currencies to target currency # 2.1.1 get up-to-date currency rates quotations <- quotations.update() # 2.1.2 convert to RUR jobdf <- convert.currency(df = jobdf, quotationsdf = quotations) # 2.2 convert Gross to Net # jobdf <- gross.to.net(df = jobdf) # 2.3 define segments jobdf <- get.positions(jobdf)
Analisis
Seperti yang disebutkan di atas, saya akan menganalisis aspek-aspek berikut dari data yang diperoleh:
- gaji rata-rata BA / SA,
- keterampilan dan kualitas pribadi yang paling dituntut dalam posisi ini,
- ketergantungan (jika ada) antara keterampilan tertentu dan tingkat gaji.
Pendapatan BA / SA rata-rata
Ternyata, perusahaan enggan untuk menunjukkan batas gaji yang lebih tinggi atau lebih rendah.
Dalam kerangka kerja data data kami jobdf nilai-nilai ini masing-masing berada di kolom Ke dan Dari. Saya ingin menemukan rata-rata dan menuliskannya ke kolom gaji baru.
Untuk kasus-kasus di mana gaji ditunjukkan secara penuh, ini dapat dengan mudah dilakukan dengan menggunakan fungsi mean() , menyaring semua catatan lain di mana data pada colokan hilang secara keseluruhan atau sebagian. Tetapi dalam kasus ini, kurang dari 10% akan tetap dari sampel asli kami, yang sudah kecil. Karena itu, saya menghitung koefisien Podgoniana , yang memberi tahu Anda berapa banyak nilai To dan From berbeda secara rata-rata di lowongan tempat garpu penuh ditunjukkan, dan dengan bantuannya saya mengisi data yang hilang jika hanya ada satu nilai yang hilang.
Lihat kode select.paid <- function(df, suggest = TRUE) { # Returns a data frame with average salaries between To and From # optionally, can suggest To or From value in case only one is specified if (suggest == TRUE) { df <- df %>% filter(!is.na(From) | !is.na(To)) magic.coefficient <- # shows the average difference between max and min salary round(mean(df$To/df$From, na.rm = TRUE), 1) df[is.na(df$To),]$To <- df[is.na(df$To),]$From * magic.coefficient df[is.na(df$From),]$From <- df[is.na(df$From),]$To / magic.coefficient } else { df <- na.omit(df) } df$salary <- rowMeans(x = df %>% select(From, To)) df$salary <- ceiling(df$salary / 10000) * 10000 return(df %>% select(-From, -To)) }
Ini adalah pemfilteran data "lunak", yang diatur dalam fungsi select.paid() dengan suggest = TRUE parameter suggest = TRUE . Atau, kita dapat menentukan suggest = FALSE saat memanggil fungsi dan cukup memotong semua baris di mana data gaji setidaknya tidak ada sebagian. Namun, menggunakan pemfilteran lembut dan koefisien ajaib, saya berhasil menyimpan hampir seperempat dari data asli yang ditetapkan dalam sampel.
Kami beralih ke bagian visual:

Pada grafik ini, Anda dapat secara visual menilai kepadatan distribusi gaji BA / SA di dua ibukota dan di daerah. Tetapi bagaimana jika kita menentukan permintaan dan membandingkan berapa banyak yang didapatkan oleh pria menengah dan senior di ibukota?
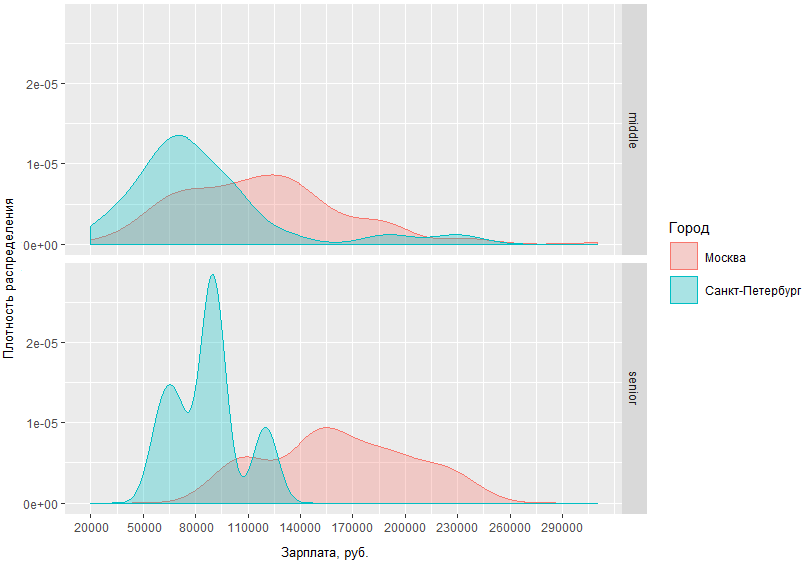
Dari grafik yang diperoleh jelas bahwa perbedaan dalam situasi gaji antara pria menengah dan senior di Moskow dan St. Petersburg tidak terlalu berbeda. Jadi, di St. Petersburg, middles mendapat, sebagai aturan, di wilayah 70 tr, sementara di Moskow puncak kepadatan jatuh pada ~ 120 tr, dan perbedaan pendapatan spesialis tingkat senior di Moskow dan St. Petersburg berbeda dengan rata-rata 60 ribu.
Kita juga dapat melihat, misalnya, gaji analis Moskow berdasarkan posisi:

Dapat disimpulkan bahwa a) hari ini di Moskow ada permintaan yang jauh lebih besar untuk para analis tingkat pemula, dan b) pada saat yang sama, ambang batas gaji tertinggi untuk para spesialis semacam itu jauh lebih terbatas daripada para perantara dan manula.
Pengamatan lain: sn rata-rata spesialis Moskow tingkat menengah dan tinggi memiliki area persimpangan yang agak besar. Ini mungkin menunjukkan bahwa pasar memiliki batas yang agak kabur antara dua langkah ini.
Kode lengkap untuk bagan di bawah potongan.
Lihat # Step 3 - analyze salaries # 3.1 get paid jobs (with salaries specified) jobs.paid <- select.paid(jobdf) # 3.2 plot salaries density by region ggplotly(ggplot(jobs.paid, aes(salary, fill = region, colour = region)) + geom_density(alpha=.3) + scale_fill_discrete(guide = guide_legend(reverse=FALSE)) + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + scale_y_continuous(name = " ") + theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10))) # 3.3 compare salaries for middle / senior in capitals ggplot(jobs.paid %>% filter(region %in% c("", "-"), lvl %in% c("senior", "middle")), aes(salary, fill = region, colour = region)) + facet_grid(lvl ~ .) + geom_density(alpha = .3) + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + scale_y_continuous(name = " ") + scale_fill_discrete(name = "") + scale_color_discrete(name = "") + guides(fill=guide_legend( keywidth=0.1, keyheight=0.1, default.unit="inch") ) + theme(legend.spacing = unit(1,"inch"), axis.title = element_text(size=10)) # 3.4 plot salaries in Moscow by position ggplotly(ggplot(jobs.paid %>% filter(region == ""), aes(salary, fill = lvl, color = lvl)) + geom_density(alpha=.4) + scale_fill_brewer(palette = "Set2") + scale_color_brewer(palette = "Set2") + theme_light() + scale_y_continuous(name = " ") + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10)))
Analisis keterampilan utama
Kami beralih ke tujuan utama penelitian ini - untuk mengidentifikasi keterampilan yang paling dicari untuk BA / SA. Untuk melakukan ini, kami akan menganalisis data yang secara eksplisit ditunjukkan dalam bidang khusus kekosongan-ketrampilan kunci.
Keterampilan paling populer
Sebelumnya, kami menerima kerangka data all.skills terpisah, di mana kami merekam pasangan "id pekerjaan - keterampilan". Menemukan keterampilan yang paling umum mudah dengan fungsi table() :
tmp <- as.data.frame(table(all.skills$skill), col.names = c("Skill", "Freq")) htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),]), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")
Anda mendapatkan sesuatu seperti berikut:

Di sini Frek adalah jumlah lowongan di bidang "key_skills" di mana keterampilan yang sesuai dari kolom Keterampilan ditunjukkan.
"Tapi itu belum semuanya!" (C) Sangat jelas bahwa keterampilan yang sama dapat dengan mudah ditemukan di lowongan yang berbeda dalam istilah yang sama.
Saya menyusun kamus kecil sinonim untuk nama-nama keterampilan dan membaginya menjadi beberapa kategori.
Kamus adalah file csv dengan kolom kategori - salah satu dari yang berikut: Kegiatan, Alat, Pengetahuan, Standar dan Pribadi; skill - nama utama skill, yang akan saya gunakan alih-alih semua sinonim yang ditemukan; syn1, syn2, ... syn13 - sebenarnya variasi yang mungkin untuk setiap skill. Beberapa baris mungkin berisi kolom sinonim kosong.
category;skill;syn1;syn2;syn3;syn4;syn5;syn6;syn7;syn8;syn9;syn10;syn11;syn12;syn13 tools;axure;;;;;;;;;;;;; tools;lucidchart;;;;;;;;;;;;; standards;archimate;;;;;;;;;;;;; standards;uml;activity diagram;use case diagram;ucd;class diagram;;;;;;;;; personal;teamwork;team player; ;;;;;;;;;;; activities;wireframing;mockup;mock-up;;-;wireframe;;ui;ux/;/ux;;;;
Pertama, impor kamus, dan kemudian bagikan kembali keterampilan tersebut berdasarkan pada kesetaraan yang ada:
# Analyze skills # 4.1 import dictionary dict <- read.csv(file = "competencies.csv", header = TRUE, stringsAsFactors = FALSE, sep = ";", na.strings = "", encoding = "UTF-8") # 4.2 match skills with dictionary all.skills <- categorize.skills(all.skills, dict)
Di bawah potongan, Anda dapat melihat isian fungsi categorize.skills() .
mereka sangat nyali! categorize.skills <- function(analyst_skills, dictionary) { analyst_skills$skill.group <- NA analyst_skills$category <- NA for (myskill in dictionary$skill) { category <- dictionary[dictionary$skill == myskill, "category"] mypattern <- paste0(na.omit(t(dictionary %>% filter(skill == myskill) %>% select(starts_with("syn")))), collapse = "|") if (nchar(mypattern) > 1) mypattern <- paste0(c(myskill, mypattern), collapse = "|") else mypattern <- myskill try( { analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"skill.group"] <- myskill analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"category"] <- category } ) } return(analyst_skills) }
Saya menambahkan kategori dan kolom keterampilan ke bingkai data keterampilan asli. grup - untuk kategori dan nama umum keahlian, masing-masing. Lalu saya pergi ke kamus yang diimpor dan membuat pola untuk fungsi grep() dari setiap baris sinonim. Dengan menambahkan setiap nilai kolom yang tidak kosong ke baris, saya memisahkannya dengan tanda hubung untuk mendapatkan kondisi "atau". Jadi, untuk semua keterampilan dari tabel sumber, yang mencakup uml|activity diagram|use case diagram|ucd|class diagram , saya akan menulis nilai "uml" di kolom skill.group. Dan begitu juga dengan semua orang! .. keterampilan dari bingkai data asli.
Dengan meminta kembali keahlian paling populer, Anda dapat melihat bahwa penyelarasan kekuatan agak berubah:
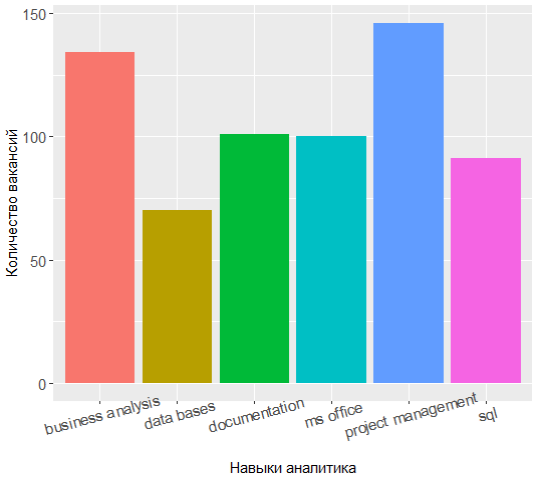
Tiga pemimpin sekarang memiliki manajemen proyek, analisis dan dokumentasi bisnis, dan pengetahuan tentang UML telah bergeser dari 7 teratas.
Sangat menarik untuk menelusuri kategori dan mencari tahu keterampilan mana yang paling dibutuhkan di masing-masing kategori.
Misalnya, untuk kategori Pengetahuan, situasinya adalah sebagai berikut:
Lihat kode tmp <- merge(x = all.skills, y = jobdf %>% select(id, lvl), by = "id", sort = FALSE) tmp <- na.omit(tmp) ggplot(as.data.frame(table(tmp %>% filter(category == "knowledge") %>% select(skill.group)))) + geom_bar(colour = "#666666", stat = "identity", aes(x = reorder(Var1, Freq), y = Freq, fill = reorder(Var1, -Freq))) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()

Grafik menunjukkan bahwa permintaan terbesar adalah untuk pengetahuan di bidang basis data, metodologi pengembangan perangkat lunak, dan 1C. Selanjutnya datang pengetahuan di bidang CRM, sistem ERP dan dasar-dasar pemrograman.
Sejauh menyangkut standar, pengetahuan tentang SQL dan UML benar-benar diminati, notasi ARIS segera muncul, tetapi GOST hanya menempati posisi keenam.
Ini kodenya ggplot(as.data.frame(table(tmp %>% filter(category == "standards") %>% select(skill.group)))) + geom_bar(colour = "#666666", stat = "identity", aes(x = reorder(Var1, Freq), y = Freq, fill = Var1)) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()

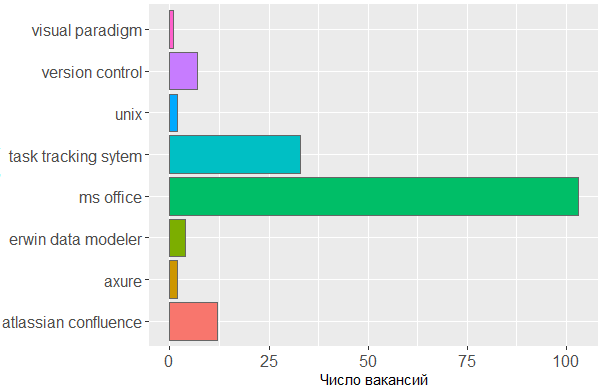
Adapun alat yang digunakan, kami sekali lagi melihat konfirmasi bahwa kepala adalah alat utama analis. Seseorang tidak dapat melakukan tanpa garis MS Office dan sistem pelacakan tugas, tetapi sisanya tidak menjadi perhatian bagi editor di mana analis membuat skema sendiri atau sketsa model antarmuka.
Ini kodenya ggplot(tmp %>% filter(category == "tools")) + geom_histogram(colour = "#666666", stat = "count", aes(skill.group, fill = skill.group)) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()
Dampak keterampilan terhadap pendapatan
, , . , , , .
jobs.paid all.skills , data frame.
# 4.4 vizualize paid skills tmp <- na.omit(merge(x = all.skills, y = jobs.paid %>% select(id, salary, lvl, City), by = "id", sort = FALSE))
:
> head(tmp) id skill skill.group category salary lvl City 2 25781585 android mobile os knowledge 90000 middle 3 25781585 project management activities 90000 middle 5 25781585 project management activities 90000 middle 6 25781585 ios mobile os knowledge 90000 middle 7 25750025 aris aris standards 70000 middle 8 25750025 - business analysis activities 70000 middle
, .. . :
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, salary)) + coord_flip() + geom_count(aes(size = ..n.., color = City)) + scale_fill_discrete(name = "") + scale_y_continuous(name = ", .") + scale_size_area(max_size = 11) + theme(legend.position = "bottom", axis.title = element_blank(), axis.text.y = element_text(size=10, angle=10)))

, BA/SA .
:
ggplot(tmp %>% filter(category == "personal", City %in% c("", "-")), aes(tools::toTitleCase(skill), salary)) + coord_flip() + geom_count(aes(size = ..n.., color = skill.group)) + scale_y_continuous(breaks = round(seq(min(tmp$salary), max(tmp$salary), by = 20000),1), name = ", .") + scale_size_area(max_size = 10) + theme(legend.position = "none", axis.title = element_text(size = 11), axis.text.y = element_text(size=10, angle=0))
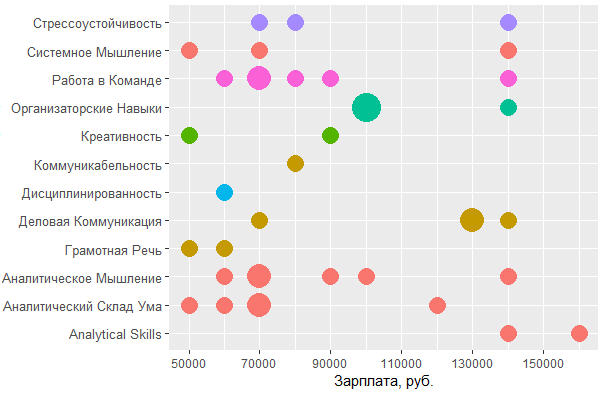
, MS Office , — , - . , , , .
, , : UML ARIS, SQL ( ) , IDEF — , "".
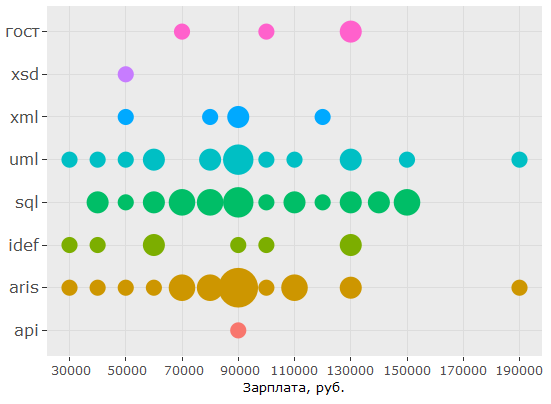
, , , . , 1478 - key_skills. , - .
, data frame:
> jobdf$Responsibility[[1]] [1] "Training course in business analysis. ● Define needs of the user/client, understand the problem which needs to be solved. ● " > jobdf$Requirement[[1]] [1] "At least 6 months' experience in business analysis. ● Knowledge of qualitative methods such as usability testing, interviewing, focus groups. ● "
, , . URL' , .
hh.get.full.desrtion <- function(df) { df$full.description <- NA for (myURL in df$URL) { try( { data <- fromJSON(myURL) if (length(data$description) > 0) { df$full.description[which(df$URL == myURL, arr.ind = TRUE)] <- data$description } print(paste0("Filling in " , which(df$URL == myURL, arr.ind = TRUE) , " out of " , length(df$URL))) } ) } df$full.description <- tolower(df$full.description) return(df) }
- , html- ., gsub :
remove.Html <- function(htmlString) { #remove html tags return(gsub("<.*?>", "", htmlString)) }
, , , , . data frame ( df), , df "id, skill.group, category".
skills.from.desc <- function(df, dictionary) { sk <- data.frame( id = numeric() , skill.group = character() , category = character() ) for (myskill in dictionary$skill) { category <- dictionary[dictionary$skill == myskill, "category"] mypattern <- paste0(na.omit(t(dictionary %>% filter(skill == myskill) %>% select(starts_with("syn")))), collapse = "|") if (nchar(mypattern) > 1) { mypattern <- paste0(c(myskill, mypattern), collapse = "|") } else { mypattern <- myskill } cond = grep(x = df$full.description, pattern = mypattern) tmp <- data.frame( id = df[cond, "id"], skill.group = rep(myskill, length(cond)), category = rep(category, length(cond)) ) sk <- rbind(sk, tmp) } return(sk) }
# 5 text analysis # 5.1 get full descriptions jobdf <- hh.get.full.description(jobdf) jobdf$full.description <- remove.Html(tolower(jobdf$full.description)) sk.from.desc <- skills.from.desc(jobdf, dict)
, ?
> head(sk.from.desc) id skill.group category 1 25638419 axure tools 2 24761526 axure tools 3 25634145 axure tools 4 24451152 axure tools 5 25630612 axure tools 6 24985548 axure tools > tmp <- as.data.frame(table(sk.from.desc$skill.group), col.names = c("Skill", "Freq")) > htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),], 20), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")
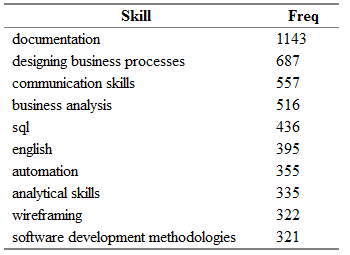
, ! Project management, key_skills, ( ).
, , key_skills -5.
, . 1478 , , key_skills, , .
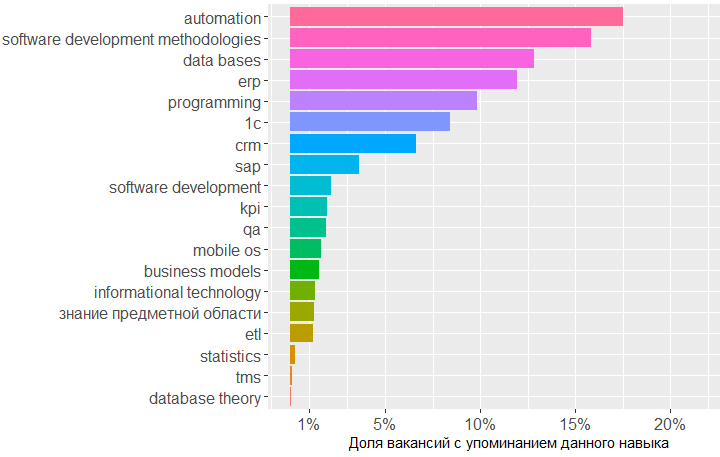
, , BA , - .
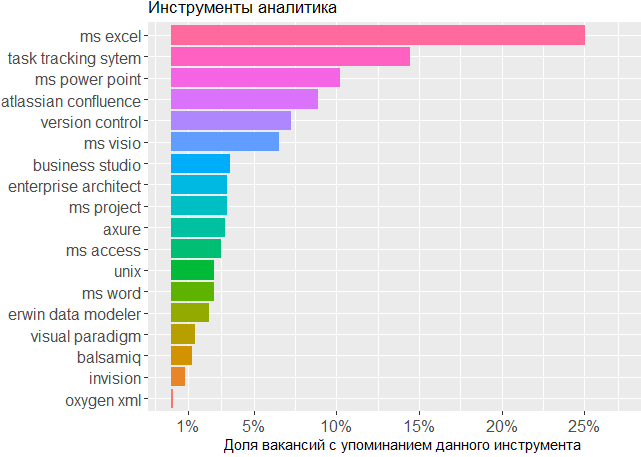
, .
data frame , , . , -.
tmp <- na.omit(merge(x = sk.from.desc, y = jobs.paid %>% filter(City %in% c("", "-")) %>% select(id, salary, lvl, City), by = "id", sort = FALSE))
> head(tmp) id skill.group category salary lvl City 1 25243346 uml standards 160000 middle 2 25243346 requirements management activities 160000 middle 3 25243346 designing business processes activities 160000 middle 4 25243346 communication skills personal 160000 middle 5 25243346 mobile os knowledge 160000 middle 6 25243346 ms visio tools 160000 middle
, , , .
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, lvl)) + geom_count(aes(color = salary, size = ..n..)) + scale_size_area(max_size = 13) + theme(legend.position = "right", legend.title = element_text(size = 10), axis.title = element_blank(), axis.text.y = element_text(size=10)) + coord_flip() + scale_color_continuous(labels = function(x) format(x, scientific = FALSE), breaks = round(seq(min(tmp$salary), max(tmp$salary), by = 70000),1), low = "blue", high = "red", name = ", ."))
?
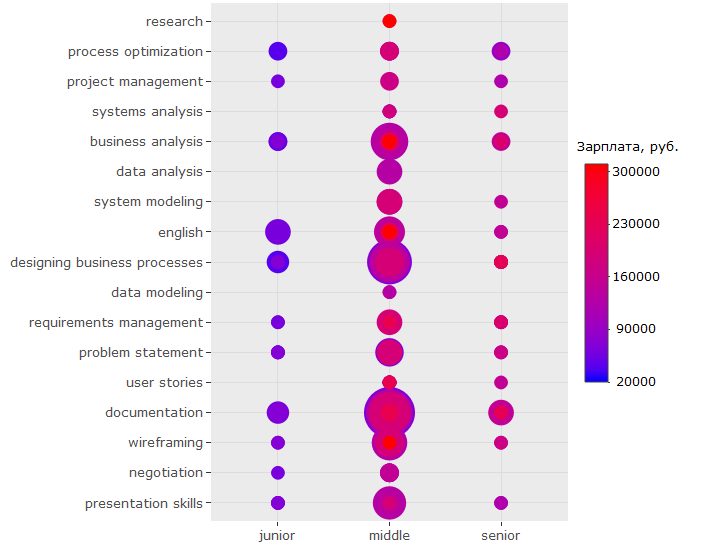
-, , - . ( , , , .)
-, , "" -, .
, key_skills.
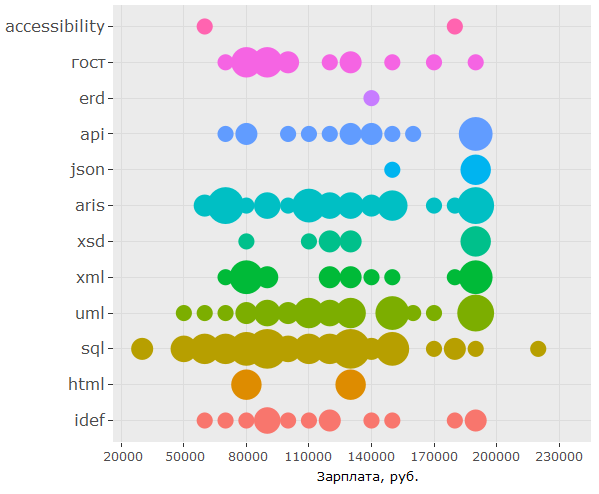
, , 150 .. UML ARIS, IDEF, , — .
:

, - , , key_skills , . , 150 .. , .
?
, - :

, , , ? , . , , . , ó ( )
, - :

-
BA/SA ,
- . , ;
- ( ) 200 .. , , ;
- ;
- — - ( , , )
key_skills hh , ;- , , , (!) ;
- , -, UX ;
- . , - 150 ..;
- , , SQL, UML & ARIS. , .. . , , ,
wordcloud2::wordcloud2(data = table(sk.from.desc$skill.group), rotateRatio = 0.3, color = 'random-dark')
