Atau bagaimana saya berakhir di tim pemenang kompetisi permusuhan Machines Can See 2018.
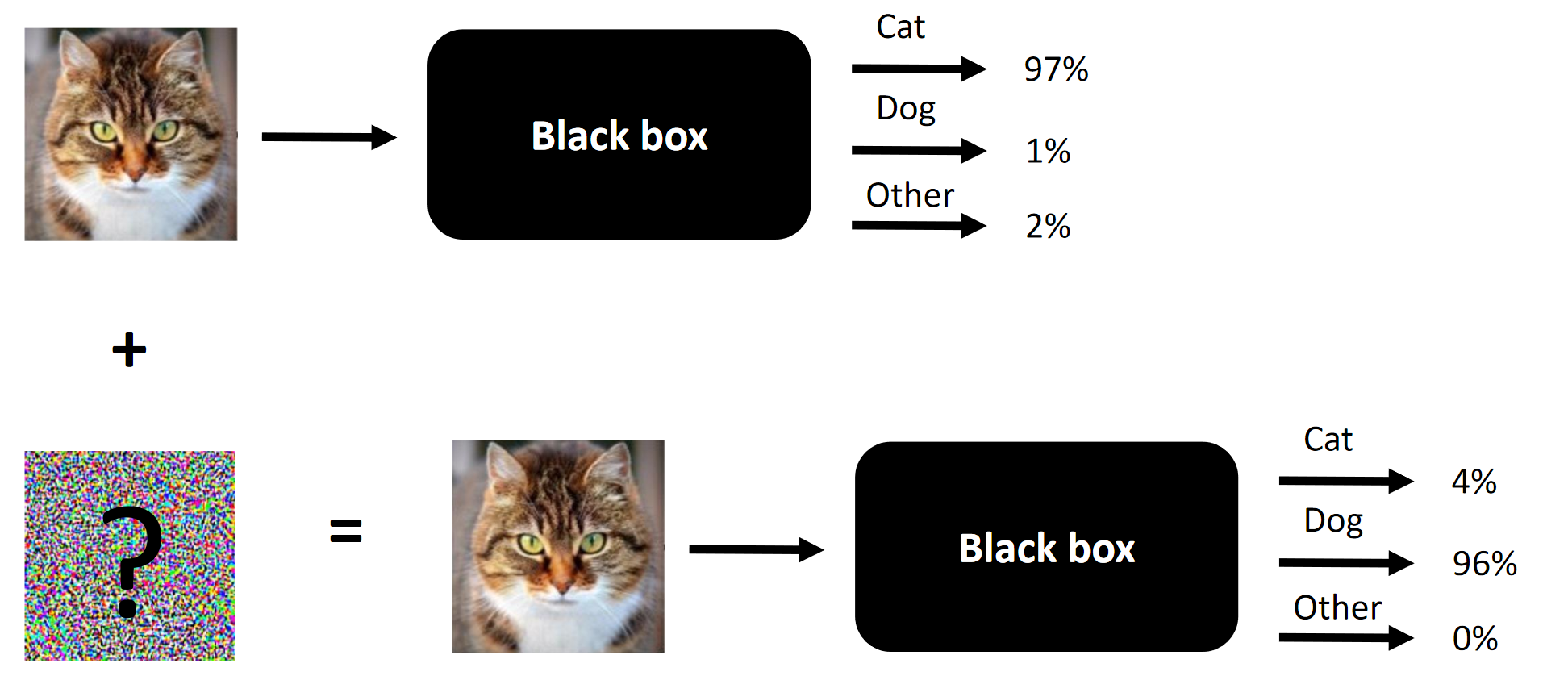 Inti dari setiap serangan kompetitif adalah contohnya.
Inti dari setiap serangan kompetitif adalah contohnya.Kebetulan saya kebetulan berpartisipasi dalam kompetisi Machines Can See 2018. Saya bergabung dengan kompetisi saya agak terlambat (sekitar seminggu sebelum akhir), tetapi akhirnya berakhir di tim yang terdiri dari 4 orang, di mana kontribusi kami bertiga (termasuk saya) adalah diperlukan untuk kemenangan (menghapus satu komponen - dan kami akan menjadi orang luar).
Tujuan dari kompetisi ini adalah untuk mengubah wajah orang-orang sehingga jaringan saraf convolutional, yang disajikan sebagai kotak hitam oleh penyelenggara, tidak dapat membedakan wajah sumber dari wajah target. Jumlah perubahan yang diizinkan dibatasi oleh
SSIM .
Artikel asli diposting di
sini .
Catatan Terjemahan canggung terminologi atau ketidakhadirannya ditentukan oleh kurangnya terminologi yang mapan dalam bahasa Rusia. Anda dapat menyarankan opsi Anda di komentar. Inti dari kompetisi adalah mengubah wajah di pintu masuk sehingga kotak hitam tidak dapat membedakan antara dua wajah (setidaknya dari sudut pandang jarak L2 / Euclidean)
Inti dari kompetisi adalah mengubah wajah di pintu masuk sehingga kotak hitam tidak dapat membedakan antara dua wajah (setidaknya dari sudut pandang jarak L2 / Euclidean)Apa yang berhasil dalam serangan kompetitif dan apa yang berhasil dalam kasus kami:
- Metode Tanda Gradien Cepat (FGSM). Menambahkan heuristik menjadikannya SEDIKIT lebih baik;
- Metode Nilai Gradien Cepat (FGVM). Menambahkan heuristik membuatnya SANGAT lebih baik;
- Evolusi diferensial genetik ( artikel hebat tentang metode ini) + serangan piksel demi piksel;
- Ensemble model (solusi top-end ... 6 "ditumpuk" ResNet34);
- Pemintas cerdas kombinasi gambar target;
- Pada dasarnya, berhenti lebih awal selama serangan FGVM;
Apa yang tidak berhasil dalam kasus kami:
- Menambahkan "momen inersia" ke FGVM (walaupun ini bekerja untuk tim yang berperingkat lebih rendah, jadi apakah mungkin ensemble + heuristik bekerja lebih baik daripada menambahkan momen?);
- Serangan C&W (pada dasarnya serangan ujung ke ujung yang ditujukan pada log model kotak putih) - berfungsi untuk kotak putih (BY), tidak berfungsi untuk kotak hitam (CN);
- Suatu pendekatan berdasarkan Siamese LinkNet (arsitektur yang mirip dengan UNet, tetapi berbasis pada ResNet). Juga bekerja hanya untuk BY;
Apa yang tidak kami coba (tidak punya waktu, tidak punya cukup usaha atau terlalu malas):
- Tes augmentasi interpretatif untuk pembelajaran siswa (saya harus menceritakan deskriptor juga - itu mudah, tetapi ide sederhana seperti itu tidak langsung datang);
- Augmentasi selama serangan - misalnya, "mirror" gambar dari kiri ke kanan;
Tentang kompetisi secara umum:
- Dataset itu "terlalu kecil" (1000 5 + 5 kombinasi);
- Kumpulan data pelatihan siswa relatif besar (1 juta gambar);
- CE disajikan sebagai satu set model yang dikompilasi pada Caffe (secara alami, di lingkungan kami, mereka pertama kali mengeluarkan bug). Ini juga memperkenalkan beberapa kompleksitas, karena QW tidak menerima gambar dengan batch;
- Kompetisi memiliki garis dasar yang sangat baik (solusi dasar), yang tanpanya, menurut saya, hanya sedikit yang akan terlibat secara langsung;
Sumber:
1. Ikhtisar Mesin Dapat Melihat 2018 kompetisi dan bagaimana saya masuk ke dalamnya
Persaingan dan Pendekatan
Sejujurnya, saya tertarik dengan bidang baru yang menarik, Edisi Pendiri GTX 1080Ti dalam hadiah, dan kompetisi yang relatif rendah (yang tidak mungkin dibandingkan dengan 4000 orang di setiap kompetisi di Kaggle melawan seluruh ODS dengan 20 GPU per tim).
Seperti disebutkan di atas, tujuan kompetisi adalah untuk menipu model CE sehingga yang terakhir tidak dapat membedakan antara dua orang yang berbeda (dalam arti jarak L2-norma / Euclidean). Yah, karena itu kotak hitam, kami harus menyaring jaringan Student pada data yang disediakan dan berharap bahwa gradien QW dan BYW akan cukup mirip untuk melakukan serangan.
Jika Anda membaca ulasan artikel (misalnya,
di sana -
sini , meskipun artikel tersebut tidak benar-benar mengatakan apa yang berhasil dalam praktiknya) dan mengkompilasi apa yang telah dicapai oleh tim-tim top, maka Anda dapat menjelaskan secara singkat praktik terbaik tersebut:
- Serangan paling sederhana dalam implementasi melibatkan OLEH atau pengetahuan tentang struktur internal jaringan saraf convolutional (atau arsitektur sederhana) yang digunakan untuk melakukan serangan;
- Seseorang dalam obrolan menyarankan untuk melacak waktu kesimpulan pada CE dan mencoba menebak arsitekturnya;
- Memiliki akses ke jumlah data yang cukup, Anda dapat meniru QW dengan QW yang terlatih
- Mungkin metode yang paling canggih adalah:
- Serangan C&W dari ujung ke ujung (tidak berhasil dalam kasus ini);
- Ekstensi FGSM cerdas (mis. Momen inersia + ensemble rumit);
Jujur, kami masih bingung dengan kenyataan bahwa dua pendekatan ujung ke ujung yang sama sekali berbeda, dilaksanakan secara independen oleh dua orang yang berbeda dari tim, bodohnya tidak bekerja untuk CH. Pada dasarnya, ini bisa berarti bahwa dalam penafsiran kami tentang pernyataan masalah di suatu tempat ada kebocoran data yang tidak kami sadari (atau tangan yang bengkok). Dalam banyak tugas penglihatan komputer modern, solusi ujung-ke-ujung (misalnya, transfer gaya, aliran air yang dalam, pembuatan gambar, pembersihan dari kebisingan dan artefak, dll.) Jauh lebih baik daripada semua yang sebelumnya, atau tidak bekerja sama sekali. Ah.
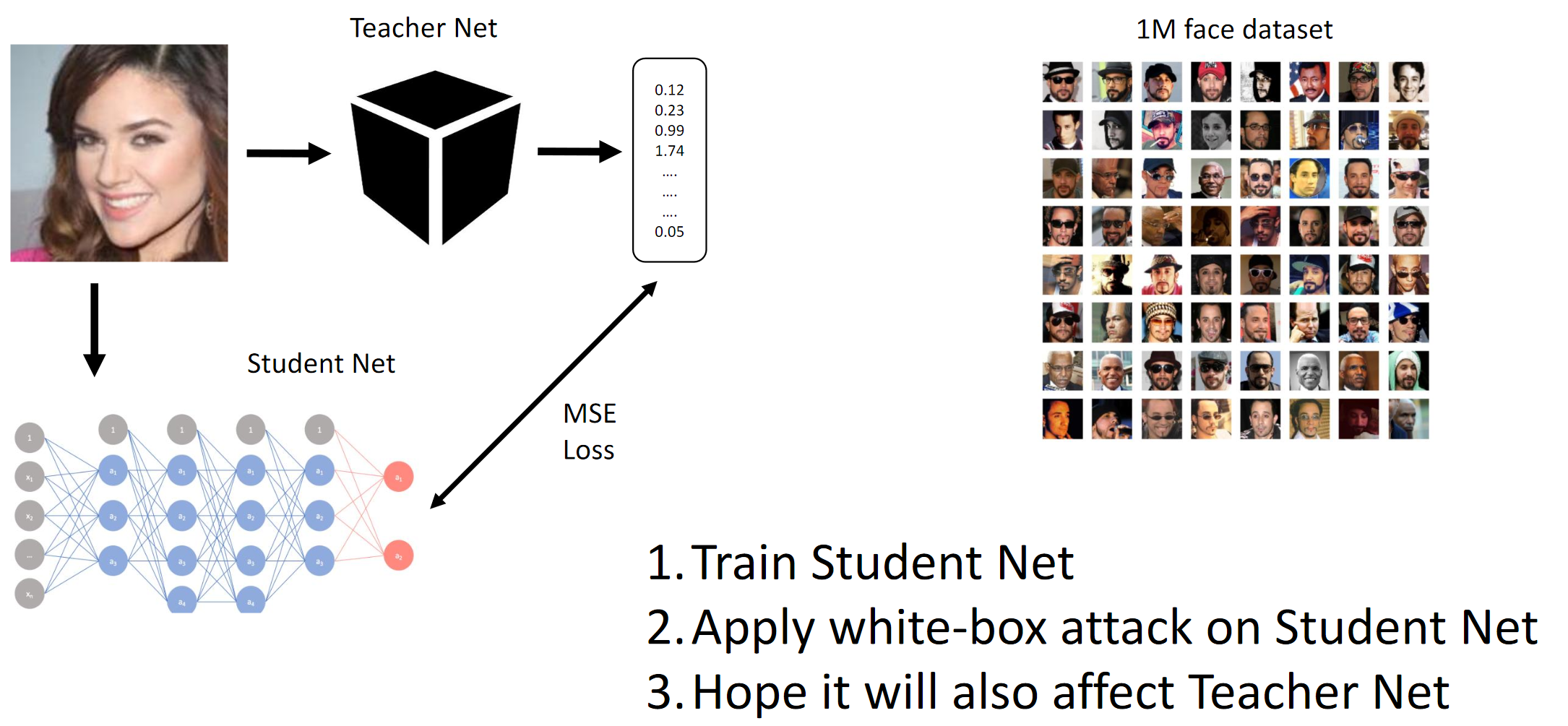 1. Latih Jaring Pelajar. 2. Terapkan dengan serangan BY di Student Net. 3. Semoga serangan Net Guru menyebar jugaCara kerja metode gradien
1. Latih Jaring Pelajar. 2. Terapkan dengan serangan BY di Student Net. 3. Semoga serangan Net Guru menyebar jugaCara kerja metode gradien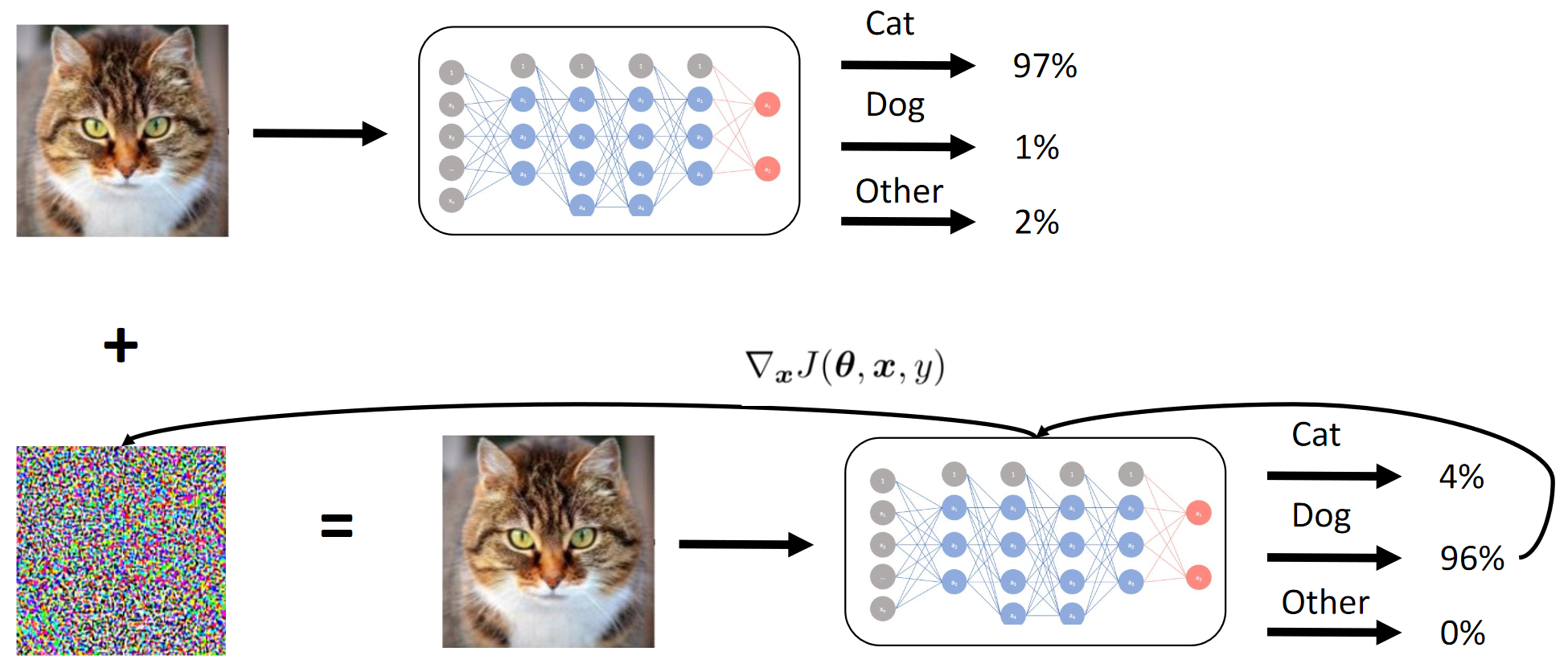
Kami pada dasarnya mencapai dengan distilasi bahwa BY adalah meniru BY. Kemudian gradien dari gambar input relatif terhadap output dari model dipertimbangkan. Rahasianya, seperti biasa, terletak pada heuristik.
Metrik Target
Metrik target adalah norma L2 rata-rata (jarak Euclidean) antara semua 25 kombinasi sumber dan gambar target (5 * 5 = 25).
Karena keterbatasan platform (CodaLab), ada kemungkinan bahwa skor pribadi (dan penggabungan tim) dihitung secara manual, yang akan menjadi cerita seperti itu.

Tim
Saya bergabung dengan tim setelah saya melatih grid Siswa, lebih baik daripada orang lain di papan peringkat (sejauh yang saya tahu), dan setelah sedikit diskusi dengan
Atmyre (dia membantu dengan QW yang disusun dengan benar, karena dia sendiri menghadapi hal yang sama). Kemudian kami membagikan skor lokal kami tanpa berbagi pendekatan dan kode, dan sebenarnya, 2-3 hari sebelum garis finish, hal berikut terjadi:
- Model berkelanjutan saya gagal (ya, dalam hal ini juga);
- Saya memiliki model siswa terbaik;
- Mereka (tim) memiliki variasi heuristik terbaik untuk FGVM (kode mereka didasarkan pada garis dasar);
- Saya baru saja mencoba model dengan gradien dan mencapai kecepatan lokal sekitar 1,1 - awalnya saya tidak ingin menggunakan garis dasar dari preferensi pribadi saya (saya menantang diri saya sendiri);
- Mereka tidak memiliki kekuatan komputasi yang cukup pada waktu itu;
- Pada akhirnya, kami mencoba keberuntungan kami dan bergabung - saya menginvestasikan kekuatan komputasi saya / jaringan saraf convolutional / serangkaian tes ablasi. Tim memasukkan basis kode mereka, yang mereka poles selama beberapa minggu;
Sekali lagi, saya ingin mengucapkan terima kasih atas saran dan keterampilan organisasi yang sangat berharga.
Komposisi tim:
github.com/atmyre - berdasarkan aksi, adalah kapten tim pada awalnya. Menambahkan serangan evolusi diferensial genetik dalam pengiriman akhir;
github.com/mortido - implementasi terbaik serangan FGVM dengan heuristik yang sangat baik + 2 model terlatih menggunakan kode baseline;
github.com/snakers4 - selain tes apa pun untuk mengurangi jumlah opsi dalam menemukan solusi, saya melatih 3 model Siswa dengan metrik terbaik + daya komputasi yang diberikan + membantu dalam fase pengiriman akhir dan presentasi hasil;
github.com/stalkermustang;Sebagai hasilnya, kami semua belajar banyak dari satu sama lain, dan saya senang bahwa kami mencoba keberuntungan kami di kompetisi ini. Tidak adanya setidaknya satu kontribusi dari tiga akan menyebabkan kekalahan.
2. Mahasiswa Penyulingan CNN
Saya berhasil mendapatkan kecepatan terbaik saat melatih model-model Student, karena saya menggunakan kode saya sendiri daripada kode baseline.
Poin-poin penting / apa yang berhasil:- Pemilihan regimen pelatihan untuk setiap arsitektur secara terpisah;
- Pelatihan pertama dengan pembusukan Adam + LR;
- Pemantauan yang hati-hati atas kekurangan dan kelebihan kapasitas dan kapasitas model;
- Penyesuaian manual mode pelatihan. Jangan sepenuhnya mempercayai skema otomatis: skema itu dapat bekerja, tetapi jika Anda menyetel pengaturan dengan baik, waktu untuk pelatihan dapat dikurangi 2-3 kali. Ini sangat penting dengan model berat seperti DenseNet;
- Arsitektur berat berkinerja lebih baik daripada arsitektur ringan, tidak termasuk VGG;
- Pelatihan dengan kehilangan L2 bukan MSE juga bekerja, tetapi sedikit lebih buruk;
Apa yang tidak berhasil:- Arsitektur berbasis inception (tidak cocok karena pengambilan sampel turun tinggi dan resolusi input lebih tinggi). Meskipun tim di tempat ketiga mampu entah bagaimana menggunakan gambar Inception-v1 dan full-cut (~ 250x250);
- Arsitektur berbasis VGG (over-fitting);
- Arsitektur ringan (SqueezeNet / MobileNet - underfitting);
- Augmentasi gambar (tanpa memodifikasi deskriptor - meskipun tim entah bagaimana menariknya dari tempat ketiga);
- Bekerja dengan gambar ukuran penuh;
- Juga pada akhir jaringan saraf yang disediakan oleh penyelenggara kompetisi adalah lapisan norma-batch. Ini tidak membantu kolega saya, dan saya menggunakan kode saya, karena saya tidak begitu mengerti mengapa lapisan ini ada di sana;
- Menggunakan peta arti-penting dengan serangan berbasis piksel. Saya kira ini lebih berlaku untuk gambar ukuran penuh (hanya membandingkan 112x112x search_space dan 299x299x search_space);
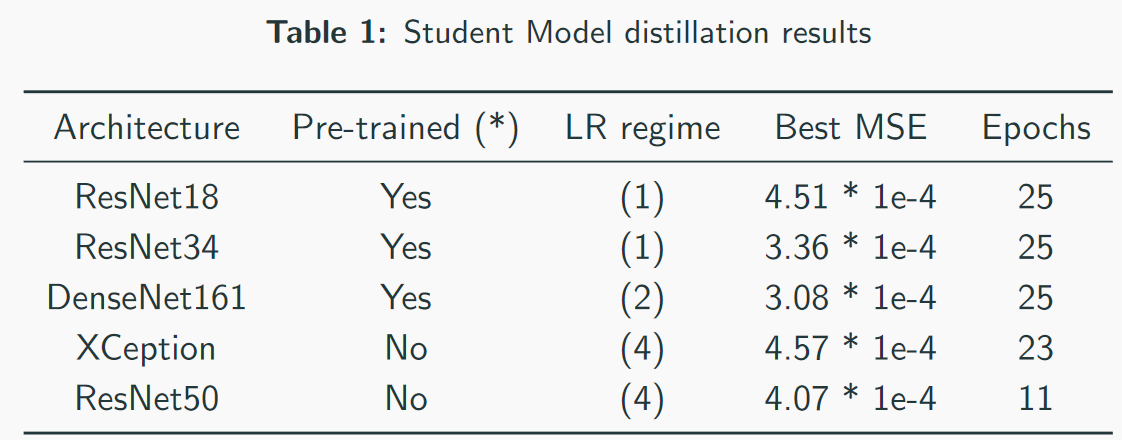 Model terbaik kami - perhatikan bahwa kecepatan terbaik adalah 3 * 1e-4. Dilihat oleh kompleksitas model, orang dapat membayangkan bahwa QW adalah ResNet34. Dalam pengujian saya, ResNet50 + berkinerja lebih buruk daripada ResNet34.
Model terbaik kami - perhatikan bahwa kecepatan terbaik adalah 3 * 1e-4. Dilihat oleh kompleksitas model, orang dapat membayangkan bahwa QW adalah ResNet34. Dalam pengujian saya, ResNet50 + berkinerja lebih buruk daripada ResNet34.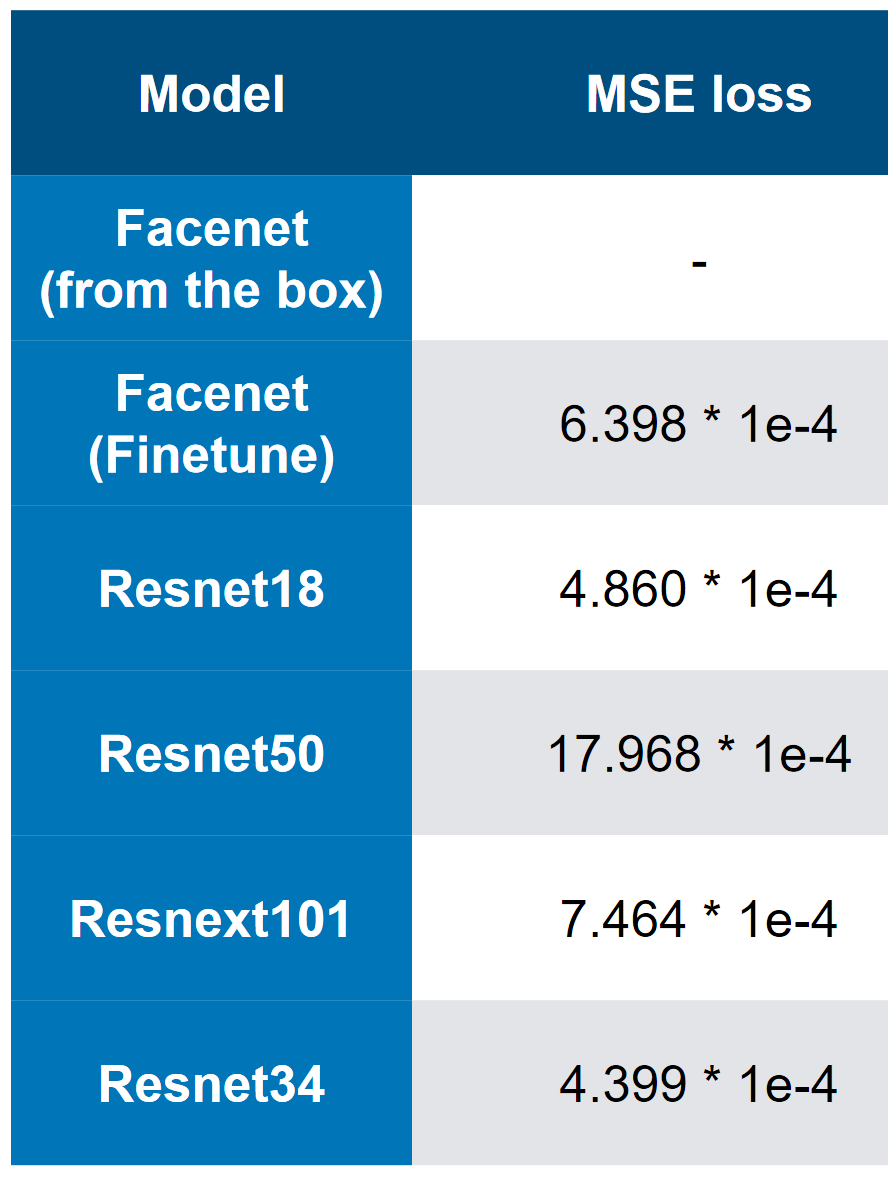 MSE kehilangan tempat pertama
MSE kehilangan tempat pertama3. Analisis kecepatan akhir dan "ablasi"
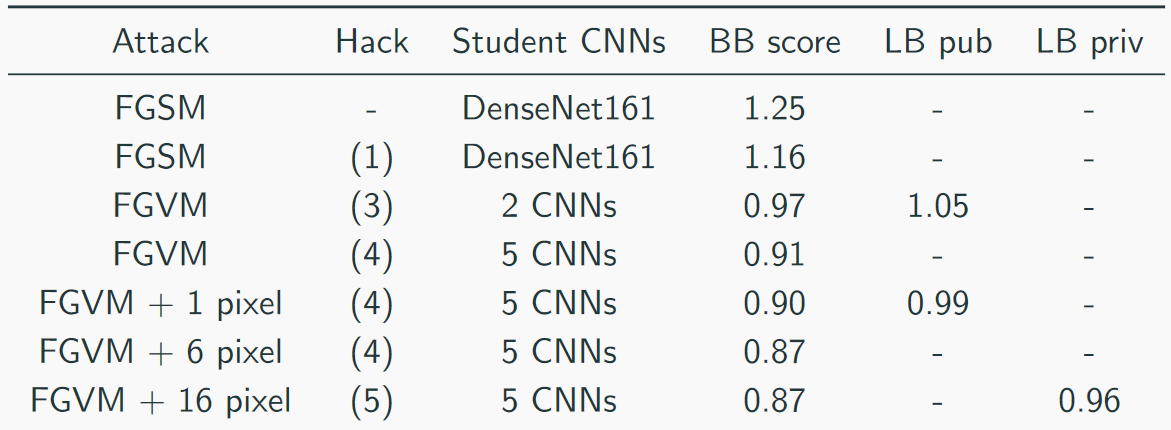
Kami mengumpulkan kecepatan kami seperti ini:
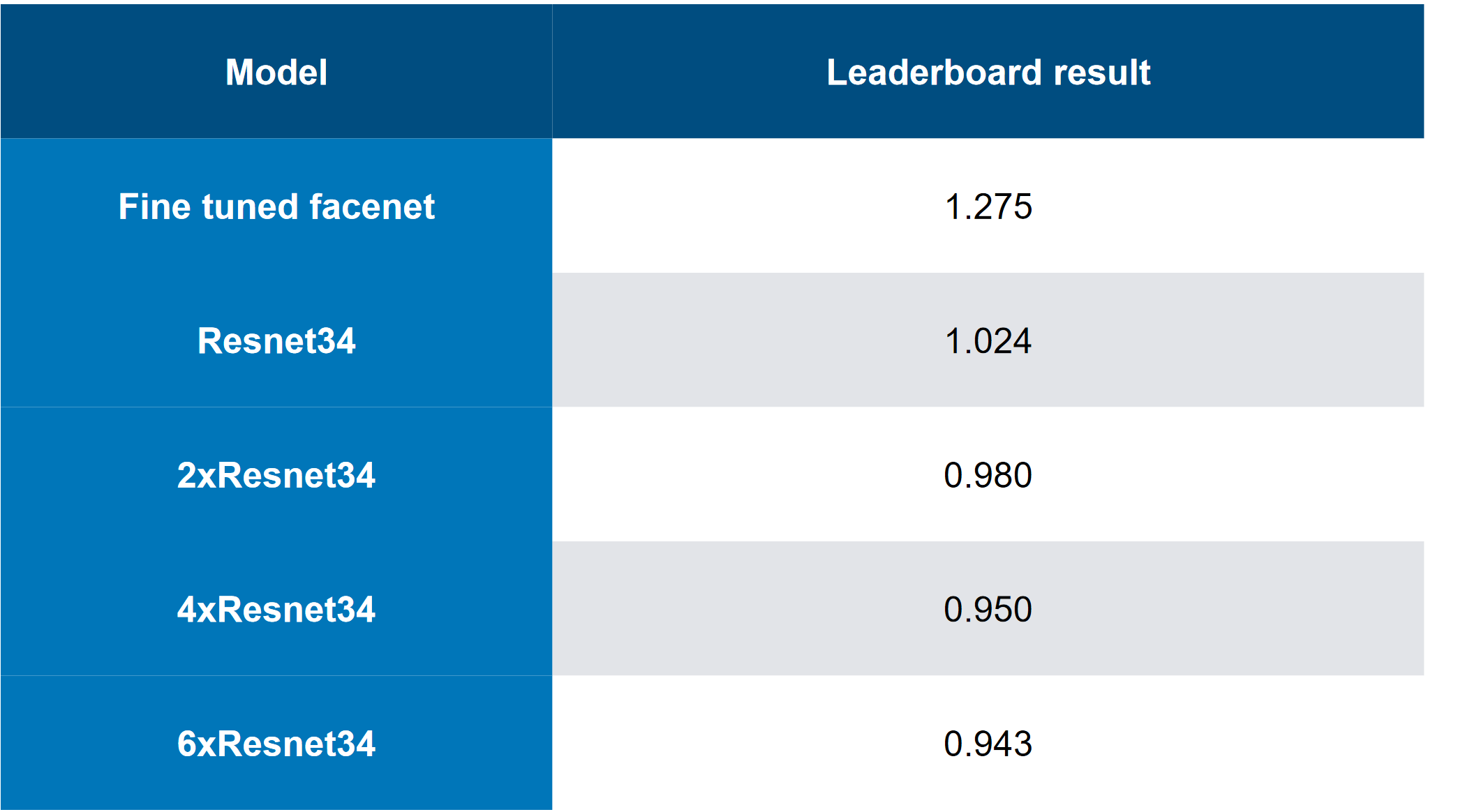
Solusi teratas tampak seperti ini (ya, ada lelucon tentang fakta bahwa hanya menumpuk pembantaian, Anda dapat menebak bahwa CH adalah pembantaian):
Pendekatan berguna lainnya dari tim lain:
- Parameter adaptif epsilon;
- Augmentasi Data
- Momen inersia;
- Momen Nesterov ;
- Gambar cermin;
- “Retas” datanya sedikit - hanya ada 1000 gambar unik dan 5000 kombinasi gambar => dimungkinkan untuk menghasilkan lebih banyak data (bukan 5 target, tetapi 10, karena gambar diulang);
Heuristik yang berguna untuk FGVM:
- Generasi kebisingan menurut aturan: Noise = eps * clamp (grad / grad.std (), -2, 2);
- Sebuah ensemble dari beberapa CNN dengan menimbang gradien mereka;
- Simpan perubahan hanya jika mereka mengurangi kerugian rata-rata;
- Gunakan kombinasi target untuk penargetan yang lebih konsisten
- Gunakan hanya gradien yang lebih tinggi dari rata-rata + std (untuk FGSM);
Sammari Pendek:
- Pertama-tama adalah keputusan yang lebih "canggung"
- Kami memiliki solusi yang paling beragam;
- Di tempat ketiga adalah solusi yang paling "elegan";
Solusi ujung ke ujung
Bahkan jika mereka gagal, mereka patut dicoba lagi di masa depan dengan tugas-tugas baru. Lihat detail dalam repositori, tetapi sebenarnya kami mencoba yang berikut:
- Serangan C&W;
- Siamese LinkNet;
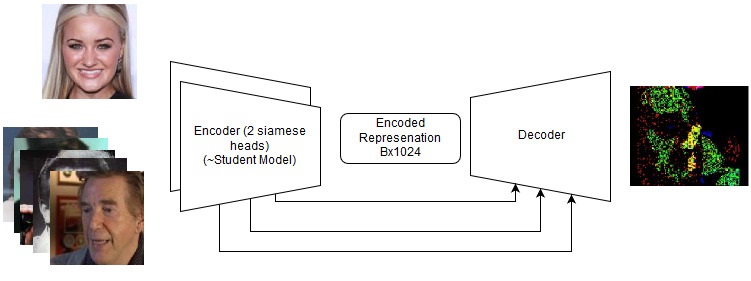 Model ujung ke ujung
Model ujung ke ujung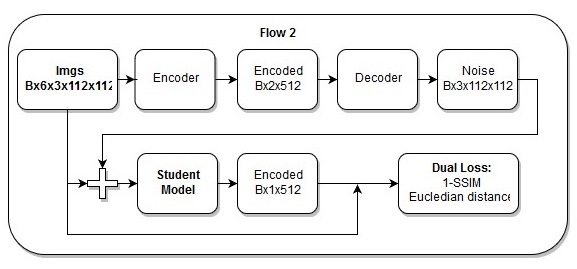 Urutan tindakan dalam model ujung ke ujung
Urutan tindakan dalam model ujung ke ujungSaya juga berpikir bahwa
kehilangan saya hanya indah.
5. Referensi dan bahan bacaan tambahan
- Halaman kompetisi ;
- Repositori kami;
- Serangkaian artikel tentang VAE adalah topik serupa;
- Sumber Daya SSIM
- Sumber daya untuk evolusi diferensial
- Presentasi
- 2 artikel paling berguna:
- 2 ulasan artikel "di atas":