Bagian pertama, "Evaluasi Cavium ThunderX2: Impian Arm Server Menjadi Kenyataan" ada
di siniKonfigurasi Tes dan Metodologi
Untuk ulasan ThunderX2, semua pengujian kami dilakukan pada Ubuntu Server 17.10, Linux 4.13 64 bit kernel. Kami biasanya menggunakan versi LTS, tetapi karena Cavium hadir dengan versi khusus Ubuntu ini, kami tidak mengambil risiko mengubah OS. Distribusi Ubuntu mencakup kompiler GCC 7.2.

Anda akan melihat bahwa jumlah DRAM bervariasi dalam konfigurasi server kami. Alasannya sederhana: Intel memiliki 6 saluran memori, dan Cavium's ThunderX2 memiliki 8 saluran memori.
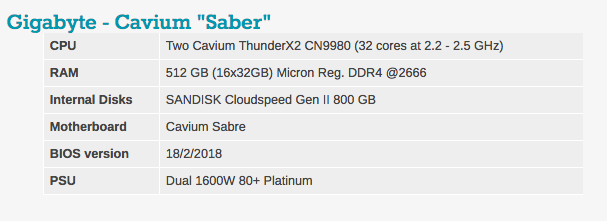
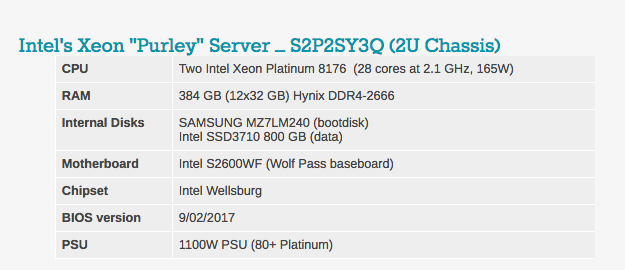
Pengaturan khas BIOS dapat dilihat di bawah ini. Perlu dicatat bahwa teknologi hyperhreading dan Intel virtualisasi disertakan.
Catatan lainKedua server diberi daya sesuai dengan standar Eropa - 230 V (maksimum 16 ampere). Suhu udara dalam ruangan dikendalikan dan dijaga pada suhu 23 ° C oleh instrumen Airwell CRAC kami.
Konsumsi energi
Perlu disebutkan bahwa sistem "Sabre" Gigabyte mengkonsumsi 500 watt jika hanya menjalankan Linux (artinya sebagian besar tidak digunakan). Namun, di bawah beban, sistem mengkonsumsi sekitar 800 W, yang pada prinsipnya memenuhi harapan kami, karena kami memiliki dua chip TDP 180 W di dalamnya. Seperti biasanya dengan sistem pengujian awal, kami tidak dapat membuat perbandingan daya yang akurat.
Bahkan, Cavium mengklaim bahwa sistem saat ini dari HP, Gigabyte dan lainnya akan jauh lebih efisien. Sistem pengujian Sabre yang digunakan memiliki beberapa masalah dengan manajemen daya: kontrol firmware kipas yang tidak tepat, kesalahan BMC dan unit catu daya dengan daya terlalu banyak (1600 W).
Subsistem Memori: Bandwidth
Menggunakan tolok ukur bandwidth Stream John McCalpin pada prosesor terbaru menjadi semakin sulit untuk mengukur potensi penuh bandwidth sistem seiring dengan meningkatnya jumlah saluran inti dan memori. Seperti yang Anda lihat dari hasil di bawah ini, memperkirakan throughput tidak mudah. Hasilnya sangat tergantung pada pengaturan yang dipilih.

Secara teoritis, ThunderX2 memiliki bandwidth 33% lebih banyak dari Intel Xeon, karena SoC memiliki 8 saluran memori dibandingkan dengan enam saluran Intel. Angka-angka throughput tinggi ini hanya dicapai dalam kondisi yang sangat spesifik, dan memerlukan penyetelan untuk menghindari penggunaan memori jarak jauh. Secara khusus, kita harus memastikan bahwa aliran tidak dibawa dari satu soket ke soket lainnya.
Sebagai permulaan, kami mencoba untuk mencapai hasil terbaik pada kedua arsitektur. Dalam kasus Intel, kompiler ICC selalu menghasilkan hasil yang lebih baik dengan beberapa optimasi tingkat rendah dalam loop stream. Dalam kasus Cavium, kami mengikuti instruksi Cavium. Secara kasar, gambar yang dihasilkan adalah gagasan tentang bandwidth yang dapat dicapai prosesor ini pada puncaknya. Jujur dengan Intel, dengan pengaturan ideal (AVX-512) Anda bisa mencapai 200 GB / s.
Namun, jelas bahwa sistem ThunderX2 dapat memberikan bandwidth 15 hingga 28% lebih banyak untuk core prosesornya. Hasilnya adalah 235 GB / s, atau sekitar 120 GB / s per slot. Ini, pada gilirannya, sekitar 3 kali lebih besar dari ThunderX asli.
Subsistem memori: penundaan
Meskipun pengukuran bandwidth hanya berlaku untuk sebagian kecil dari pasar server, hampir setiap aplikasi sangat tergantung pada latensi subsistem memori. Dalam upaya mengukur cache dan latensi memori, kami menggunakan LMBench. Data yang ingin kita lihat sebagai hasilnya adalah "Tunda pada beban acak, langkah = 16 byte". Perhatikan bahwa kami menyatakan latensi L3 dan waktu tunda DRAM dalam nanodetik, karena kami tidak memiliki nilai jam cache L3 yang tepat.
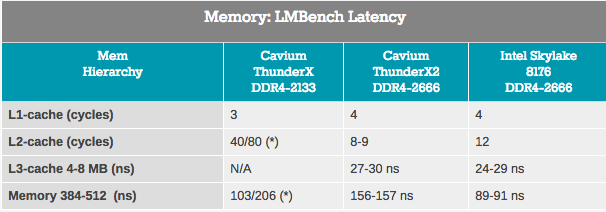
Cache ThunderX2 L2 diakses dengan latensi sangat rendah, dan saat menggunakan aliran tunggal, cache L3 terlihat seperti pesaing untuk cache L3 terintegrasi Intel. Namun, ketika kami sampai di DRAM, Intel menunjukkan latensi yang jauh lebih sedikit.
Subsistem memori: TinyMemBench
Untuk mendapatkan pemahaman yang lebih dalam tentang arsitektur masing-masing, uji open-source TinyMemBench digunakan. Kode sumber dikompilasi menggunakan GCC 7.2, dan tingkat optimisasi ditetapkan ke -O3. Strategi pengujian dijelaskan dengan baik dalam manual benchmark:
Waktu rata-rata diukur untuk akses memori acak dalam buffer dengan berbagai ukuran. Semakin besar buffer, semakin besar kontribusi relatif dari kesalahan cache TLB, L1 / L2, dan akses DRAM. Semua angka mewakili waktu tambahan yang perlu ditambahkan ke latensi cache L1 (4 siklus).
Kami menguji dengan satu dan dua pembacaan acak (tanpa halaman besar), karena kami ingin melihat bagaimana sistem memori menangani beberapa permintaan baca.
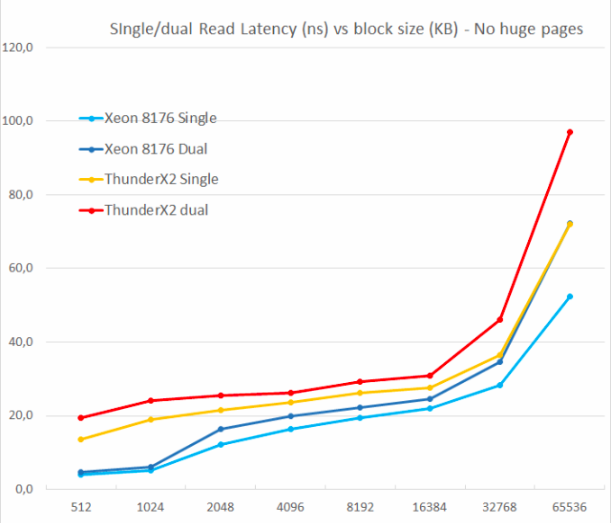
Salah satu kelemahan utama ThunderX asli adalah ketidakmampuan untuk mendukung beberapa kesalahan yang luar biasa. Konkurensi tingkat memori adalah fitur penting untuk setiap inti prosesor modern berkinerja tinggi: dengan bantuannya, ia menghindari kesalahan cache yang dapat menyebabkan "kelaparan" back-end. Dengan demikian, cache yang non-blocking adalah fitur kunci untuk core besar.
ThunderX2 tidak mengalami masalah ini sama sekali, berkat cache yang tidak menghalangi. Sama seperti inti Skylake di Xeon 8176, pembacaan kedua meningkatkan latensi total hanya 15-30%, bukan 100%. Menurut TinyMemBench, inti Skylake memiliki latensi yang jauh lebih baik. Titik referensi 512KB mudah dijelaskan: inti Skylake masih mengambil dari L2 yang cepat, dan inti ThunderX2 harus mengakses L3. Tetapi angka 1 dan 2 MB menunjukkan bahwa prefetcher Intel memberikan keuntungan yang serius, karena latensi adalah rata-rata untuk cache L2 dan L3. Tingkat latensi serupa pada kisaran 8 hingga 16 MB, tetapi segera setelah kami melampaui L3 (64 MB), Intel Skylake menawarkan memori latensi yang lebih rendah.
Performa berulir tunggal: SPEC CPU2006
Memulai dengan mengukur kinerja komputasi yang sebenarnya, kami mulai dengan paket SPEC CPU2006. Pembaca berpengetahuan akan menunjukkan bahwa SPEC CPU2006 sudah usang ketika SPEC CPU2017 muncul. Tetapi karena waktu pengujian yang terbatas dan fakta bahwa kami tidak dapat menguji ulang ThunderX, kami memutuskan untuk tetap menggunakan CPU2006.
Mengingat bahwa SPEC adalah benchmark kompiler yang sama baiknya dengan perangkat keras, kami percaya bahwa akan tepat untuk merumuskan filosofi pengujian kami. Anda perlu mengevaluasi indikator nyata, dan tidak mengembang hasil tes. Oleh karena itu, penting untuk membuat, sejauh mungkin, kondisi "seperti di dunia nyata" dengan pengaturan berikut (kritik konstruktif tentang masalah ini diterima):
- 64 bit gcc: kompiler yang paling banyak digunakan di Linux, kompiler bagus yang tidak mencoba untuk "menginterupsi" tes (libquantum ...)
- -Ofast: optimisasi kompiler yang dapat digunakan banyak pengembang
- -fno-strict-aliasing: diperlukan untuk mengkompilasi beberapa subtitle
- base run: setiap subtest mengkompilasi dengan cara yang sama
Pertama, Anda perlu mengukur kinerja dalam aplikasi yang, karena alasan tertentu, penundaan terjadi karena "lingkungan multithreaded yang bermusuhan". Kedua, Anda perlu memahami seberapa baik arsitektur ThunderX LLC bekerja dengan satu utas dibandingkan dengan arsitektur Skylake Intel. Harap dicatat bahwa dalam model Skylake tertentu Anda dapat meng-overclock frekuensi ke 3,8 GHz. Chip ini akan beroperasi pada frekuensi 2,8 GHz di hampir semua situasi (28 utas aktif) dan akan mendukung 3,4 GHz dengan 14 utas aktif.
Secara umum, Cavium memposisikan ThunderX2 CN9980 ($ 1795) sebagai "lebih baik dari 6148" ($ 3.072), prosesor yang beroperasi pada 2,6 GHz (20 utas) dan mencapai 3,3 GHz tanpa masalah (hingga 16 utas aktif) ) Di sisi lain, Intel-SKU akan memiliki keunggulan 30 persen yang signifikan dalam kecepatan clock di banyak situasi (3,3 GHz versus 2,5 GHz).
Cavium memutuskan untuk mengkompensasi defisit frekuensi dengan jumlah core, menawarkan 32 core - yang 60% lebih dari Xeon 6148 (20 core). Perlu dicatat bahwa jumlah core yang lebih besar akan menyebabkan penurunan pengembalian dalam banyak aplikasi (misalnya, Amdahl). Karena itu, jika Cavium ingin mengguncang posisi dominan Intel dengan ThunderX2, setiap inti setidaknya harus menawarkan kinerja dunia nyata yang kompetitif. Atau dalam hal ini, ThunderX2 harus menyediakan setidaknya 66% (2,5 banding 3,8) kinerja Skylake single-threaded.
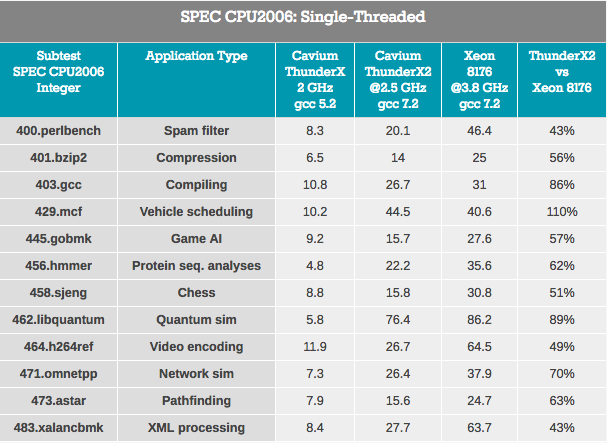
Hasilnya buram karena ThunderX2 bekerja dengan kode ARMv8 (AArch64), dan Xeon menggunakan kode x86-64.
Pointer tracking test - Pemrosesan XML (juga buffer OoO besar) dan jalur pencarian yang biasanya bergantung pada cache L3 yang besar untuk mengurangi dampak latensi akses adalah yang terburuk untuk ThunderX2. Dapat diasumsikan bahwa latensi yang lebih tinggi dari sistem DRAM menurunkan kinerja.
Beban kerja di mana pengaruh prediksi cabang lebih tinggi (setidaknya pada x86-64: persentase lebih tinggi dalam memilih cabang yang salah) - gobmk, sjeng, hmmer - bukan beban terbaik di ThunderX2.
Juga patut dicatat bahwa instruksi perlbench, gobmk, hmmer, dan h264ref diketahui mendapatkan manfaat dari cache L2 Skylake yang lebih besar (512KB). Kami menunjukkan kepada Anda beberapa potongan puzzle, tetapi bersama-sama mereka dapat membantu menyatukan gambar.
Di sisi positifnya, ThunderX2 bekerja dengan baik untuk gcc, yang bekerja sebagian besar di dalam cache L1 dan L2 (dengan demikian bergantung pada latensi L2 rendah), dan dampak kinerja prediktor cabang minimal. Secara umum, tes terbaik untuk TunderX2 adalah mcf (distribusi kendaraan di angkutan umum), yang, seperti Anda ketahui, hampir sepenuhnya melompati cache data L1, mengandalkan cache L2, dan ini adalah titik kuat ThunderX2. Mcf juga menuntut bandwidth memori. Libquantum adalah tes yang memiliki kebutuhan terbesar untuk bandwidth memori. Fakta bahwa Skylake menawarkan bandwidth single-threaded yang cukup biasa-biasa saja mungkin juga merupakan alasan ThunderX2 tampil sangat baik pada libquantum dan mcf.
SPEC CPU2006 Cont: kinerja berbasis inti dengan SMT
Melampaui kinerja single-threaded, kinerja multi-threaded dalam satu inti juga harus dipertimbangkan. Arsitektur prosesor Vulcan pada awalnya dirancang untuk menggunakan SMT4 untuk menjaga core tetap dimuat dan meningkatkan throughput keseluruhan, dan kita akan membicarakannya sekarang.
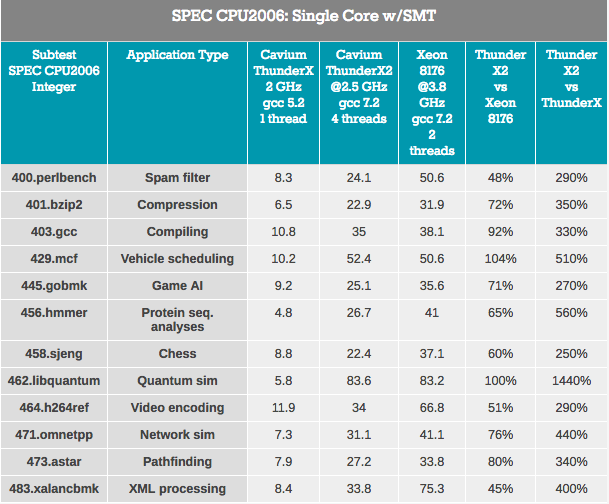
Pertama-tama, inti ThunderX2 telah “mengalami” banyak peningkatan signifikan dibandingkan inti ThunderX pertama. Bahkan dengan libquantum dalam pikiran, tes ini dapat dengan mudah berjalan 3 kali lebih cepat pada kernel ThunderX yang lebih tua setelah beberapa perbaikan dan optimasi ke kompiler. Yah, ThunderX2 baru tidak kurang dari 3,7 kali lebih cepat dari kakaknya. Keunggulan IPC ini menghilangkan kelebihan ThunderX sebelumnya.
Ketika melihat dampak SMT, rata-rata kita melihat bahwa SMT 4 arah meningkatkan kinerja ThunderX2 sebesar 32%. Ini berkisar dari 8% untuk encoding video hingga 74% untuk Pathfinding. Intel, sementara itu, mendapatkan 18% dari 2-way SMT-nya, dari 4% menjadi 37% dalam skenario yang sama.
Secara keseluruhan, peningkatan kinerja ThunderX2 adalah 32%, yang cukup bagus. Tetapi di sini muncul pertanyaan yang jelas: apa bedanya dengan arsitektur SMT4 lainnya? Sebagai contoh, IBM POWER8, yang juga mendukung SMT4, menunjukkan peningkatan 76% dalam skenario yang sama.
Namun, ini bukan perbandingan yang serupa dengan yang serupa, karena chip IBM memiliki back-end yang lebih luas: ia dapat memproses 10 instruksi, sedangkan inti ThunderX2 dibatasi hingga 6 instruksi per siklus. Inti POWER8 lebih rakus: prosesor hanya dapat menampung 10 inti "ultra-lebar" ini dengan anggaran daya 190 W pada proses 22 nm. Kemungkinan besar, peningkatan lebih lanjut dalam kinerja dari menggunakan SMT4 akan membutuhkan core yang lebih besar dan, pada gilirannya, akan secara serius mempengaruhi jumlah core yang tersedia di dalam ThunderX2. Namun demikian, menarik untuk melihat peningkatan 32% ini di masa depan.
Di bagian (3) berikutnya:
- Kinerja Java
- Kinerja Java: halaman besar
- Apache Spark 2.x Pembandingan
- Ringkasan
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikannya kepada teman-teman Anda,
diskon 30% untuk pengguna Habr pada analog unik dari server entry-level yang kami temukan untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps dari $ 20 atau bagaimana membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
Dell R730xd 2 kali lebih murah? Hanya kami yang memiliki
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV dari $ 249 di Belanda dan Amerika Serikat! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?