Bagian pertama dan
kedua , "Evaluasi Cavium ThunderX2: Arm Server Dream Telah Menjadi Kenyataan".
Kinerja Java
SPECjbb 2015 adalah tolok ukur Java Business Benchmark yang digunakan untuk mengevaluasi kinerja server yang menjalankan aplikasi Java biasa. Ini menggunakan fitur Java 7 dan XML terbaru, messanging dengan keamanan.

Harap dicatat bahwa kami telah memperbarui versi SPECjbb 1.0 ke versi 1.01.

Kami menguji SPECjbb dengan empat kelompok injector dan backend transaksi. Alasan kami menggunakan uji Multi JVM adalah karena lebih dekat dengan kondisi nyata: beberapa mesin virtual pada server adalah praktik umum, terutama pada server dengan lebih dari 100 utas. Versi Java adalah OpenJDK 1.8.0_161.
Setiap kali kami mempublikasikan hasil SPECjbb, kami mendapat komentar bahwa kinerja kami terlalu rendah. Oleh karena itu, kami memutuskan untuk meluangkan waktu lebih sedikit dan memperhatikan berbagai pengaturan.
- Pengaturan kernel, seperti pengaturan jadwal tugas, membersihkan cache halaman
- Menonaktifkan fitur hemat energi, mengonfigurasi perilaku c-state secara manual.
- Menyetel kipas ke kecepatan maksimum (kami menghabiskan banyak energi untuk beberapa poin kinerja tambahan)
- Menonaktifkan fungsi RAS (mis. Scrub memori)
- Banyak pengaturan untuk berbagai parameter Java ... Ini tidak realistis, karena setiap kali Anda menjalankan aplikasi pada mesin yang berbeda (yang sering terjadi di cloud), spesialis mahal harus mengonfigurasi pengaturan untuk mesin tertentu, yang, di samping itu, dapat menyebabkan aplikasi berhenti pada mesin lain.
- Konfigurasikan pengaturan NUMA yang sangat spesifik untuk SKU dan pemetaan CPU. Migrasi antara dua SKU yang berbeda di cluster yang sama dapat menyebabkan masalah kinerja yang serius.
Dalam lingkungan produksi, pengaturan harus sederhana dan, lebih disukai, tidak terlalu spesifik untuk mesin. Untuk tujuan ini, kami menerapkan dua jenis pengaturan. Yang pertama adalah pengaturan yang sangat sederhana untuk mengukur kinerja di luar kotak untuk meletakkan segala sesuatu di server dengan 128 GB RAM:
"-server -Xmx24G -Xms24G -Xmn16G"Untuk pengaturan kedua, dalam mencari indikator throughput terbaik, kami bermain dengan "-XX: + AlwaysPreTouch", "-XX: -UseBiasedLocking" dan "specjbb.forkjoin.workers". "+ AlwaysPretouch" sebelum memulai mengatur ulang semua halaman memori, yang mengurangi dampak kinerja pada halaman baru. “-UseBiasedLockin” menonaktifkan baised locking, yang diaktifkan secara default. Penguncian yang bias memberi prioritas pada utas yang telah memuat data yang dipermasalahkan ke dalam cache. Sisi sebaliknya dari penguncian Biased adalah proses tambahan yang cukup kompleks (Rebias) yang dapat mengurangi kinerja dalam hal strategi yang salah dipilih.
Grafik di bawah ini menunjukkan kinerja maksimum untuk benchmark MultiJVM SPECJbb kami.

ThunderX2 mencapai kinerja 80 hingga 85% dari Xeon 8176. Angka ini cukup untuk melampaui Xeon 6148. Menariknya, sistem Intel dan Kavium mencapai hasil terbaik mereka dengan cara yang berbeda. Dalam kasus Dual ThunderX2, kami menggunakan:
'-server -Xmx24G -Xms24G -Xmn16G -XX:+AlwaysPreTouch -XX:-UseBiasedLockingSementara sistem Intel mencapai kinerja terbaik, sambil meninggalkan kunci offset (default). Kami memperhatikan bahwa sistem Intel - mungkin karena jumlah utas yang relatif "aneh" - memiliki beban prosesor rata-rata yang sedikit lebih rendah (beberapa persen) dan cache L3 yang lebih besar, yang membuat bias mengunci strategi yang baik untuk arsitektur ini.
Akhirnya, kami memiliki Critical-JOPS, yang mengukur throughput dengan batas waktu respons.

Dengan penggunaan aktif sejumlah besar utas, Anda bisa mendapatkan lebih banyak Critical-jOPS dengan meningkatkan distribusi RAM pada JVM. Anehnya, sistem Dual ThunderX2 - dengan jumlah stream yang lebih tinggi dan kecepatan clock yang lebih rendah - menunjukkan waktu terbaik, menyediakan bandwidth tinggi, sambil mempertahankan waktu respons 99 persen hingga batas tertentu.
Meningkatkan ukuran heap membantu Intel sedikit menutup celah (hingga x2), tetapi dengan mengorbankan bandwidth (dari -20% hingga -25%). Tampaknya chip Intel membutuhkan lebih banyak penyesuaian daripada ARM. Untuk menjelajahi ini lebih lanjut, kami beralih ke Transparant Huge Pages (THP).
Kinerja Java: halaman besar
Biasanya untuk CPU, seseorang jarang memutar ulang yang lain di faktor 3, tetapi kami memutuskan untuk menyelidiki masalah ini lebih dalam. Kandidat yang paling jelas adalah Huge Pages, atau seperti semua orang kecuali komunitas Linux menyebutnya “Halaman Besar.”
Setiap prosesor modern menyimpan cache pemetaan memori virtual dan fisik dalam TLB-nya. Ukuran halaman "normal" adalah 4 KB, jadi dengan 1536 elemen, inti Skylake dapat melakukan cache sekitar 6 MB per inti. Selama 15 tahun terakhir, kapasitas DRAM telah berkembang dari beberapa GB menjadi ratusan GB, dan karena itu kehilangan TLB menjadi perhatian. Kehilangan TLB cukup mahal - Anda memerlukan beberapa akses memori untuk membaca beberapa tabel dan akhirnya menemukan alamat fisik.
Semua prosesor modern mendukung halaman besar. Di x86-64 (Intel dan AMD), opsi populer adalah 2 MB, halaman 1 GB juga tersedia. Sementara itu, halaman besar di ThunderX2 setidaknya 0,5 GB. Penggunaan halaman besar mengurangi jumlah kesalahan TLB (walaupun jumlah entri dalam TLB biasanya jauh lebih rendah untuk halaman besar), mengurangi jumlah akses memori yang diperlukan saat kehilangan TLB.
Namun, sudah saatnya Linux mendukung fitur ini dengan nyaman. Fragmentasi memori, konflik dan sulit untuk mengonfigurasi pengaturan, ketidakcocokan, dan terutama nama yang sangat membingungkan menyebabkan banyak masalah. Bahkan, banyak vendor perangkat lunak masih menyarankan administrator server untuk mematikan halaman besar.
Untuk tujuan ini, mari kita lihat apa yang terjadi jika kita mengaktifkan Halaman Besar Transparan dan menyimpan pengaturan terbaik yang telah dibahas sebelumnya.
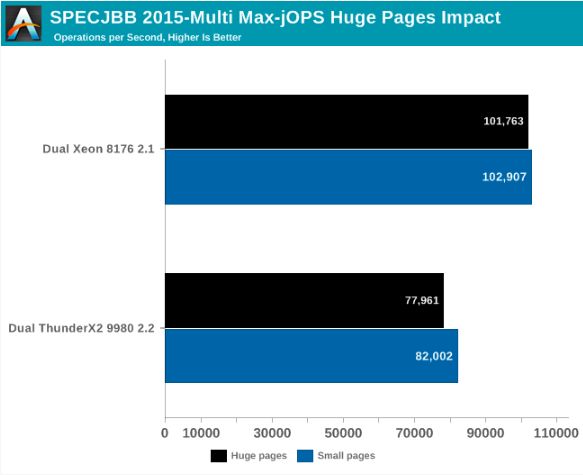
Secara keseluruhan, untuk Max-JOPs, dampak kinerja tidak spektakuler; ini sebenarnya adalah regresi kecil. Xeon kehilangan sekitar 1% dari bandwidth, ThunderX2 - sekitar 5%.
Mari kita beralih ke metrik Critical-jOPS, di mana throughput diukur sebagai persentil ke-99 dari batas waktu respons.

Perbedaan besar! Alih-alih kalah, Intel melampaui ThunderX2. Namun, harus dikatakan bahwa kinerja dengan halaman 4 KB tampaknya merupakan kelemahan serius dalam arsitektur Intel.
Apache Spark 2.x Pembandingan
Terakhir, arsenal kami memiliki tes Apache Spark. Apache Spark adalah gagasan dari pemrosesan Big Data. Mempercepat aplikasi Big Data tetap menjadi proyek prioritas di laboratorium universitas tempat saya bekerja (Sizing Servers Lab University of West-Flanders), jadi kami telah menyiapkan tolok ukur yang menggunakan banyak fitur Spark dan didasarkan pada penggunaan dunia nyata.

Tes ini dijelaskan dalam diagram di atas. Kami mulai dengan 300 GB data terkompresi yang dikumpulkan dari CommonCrawl. File-file terkompresi ini adalah sejumlah besar arsip web. Kami membuka ritsleting data dengan cepat untuk menghindari menunggu lama, yang terutama terkait dengan perangkat penyimpanan. Kemudian kami mengekstrak data teks yang bermakna dari arsip menggunakan perpustakaan Java BoilerPipe. Menggunakan Alat Pemroses Bahasa Alam Stanford CoreNLP, kami mengekstrak entitas ("kata-kata yang berarti sesuatu") dari teks dan kemudian menghitung URL mana yang paling sering terjadi pada objek-objek ini. Algoritma Alternating Lessest Square digunakan untuk merekomendasikan URL mana yang paling menarik untuk subjek tertentu.
Untuk mencapai penskalaan yang lebih baik, kami meluncurkan 4 artis. Peneliti Esley Havenert mengkonfigurasi ulang tes Spark sehingga bisa berjalan di Apache Spark 2.1.1.
Inilah hasilnya:

(*) EPYC dan Xeon E5 V4 lebih tua, bekerja pada Kernel 4.8 dan Java 1.8.0_131 sedikit lebih tua daripada 1.8.0_161. Meskipun kami berharap hasilnya sangat mirip pada kernel 4,13 dan Java 1.8.0_161, karena kami tidak melihat banyak perbedaan dalam Skylake Xeon antara kedua pengaturan ini.
Pemrosesan data sangat paralel dan sangat intensif memuat prosesor, tetapi untuk fase "pengocokan" memerlukan banyak interaksi dengan memori. Waktu yang dihabiskan untuk berkomunikasi dengan perangkat penyimpanan dapat diabaikan. Fase ALS tidak berskala pada banyak utas, tetapi kurang dari 4% dari total waktu pengujian.
ThunderX2 memberikan 87% kinerja EPYC 7601. dua kali lebih mahal dari ini. Karena indikator ini menskala dengan baik dengan jumlah core, kita dapat memperkirakan bahwa Xeon 6148 akan skor sekitar 4,8. di Apache Spark Jadi, sementara ThunderX2 tidak dapat benar-benar mengancam Xeon Platinum 8176, itu memberikan hal yang sama seperti Gold 6148 dan saudaranya dengan uang yang jauh lebih sedikit.
Dan akhirnya apa
Untuk meringkas semuanya, tes SPECInt kami menunjukkan bahwa core ThunderX2 masih memiliki beberapa kekurangan. Kesan negatif pertama kami adalah bahwa kode percabangan intensif - terutama dalam kombinasi dengan cache L3 yang biasa (penundaan DRAM tinggi) - bekerja agak lambat. Dengan demikian, akan ada kasus khusus ketika ThunderX2 bukan pilihan terbaik.
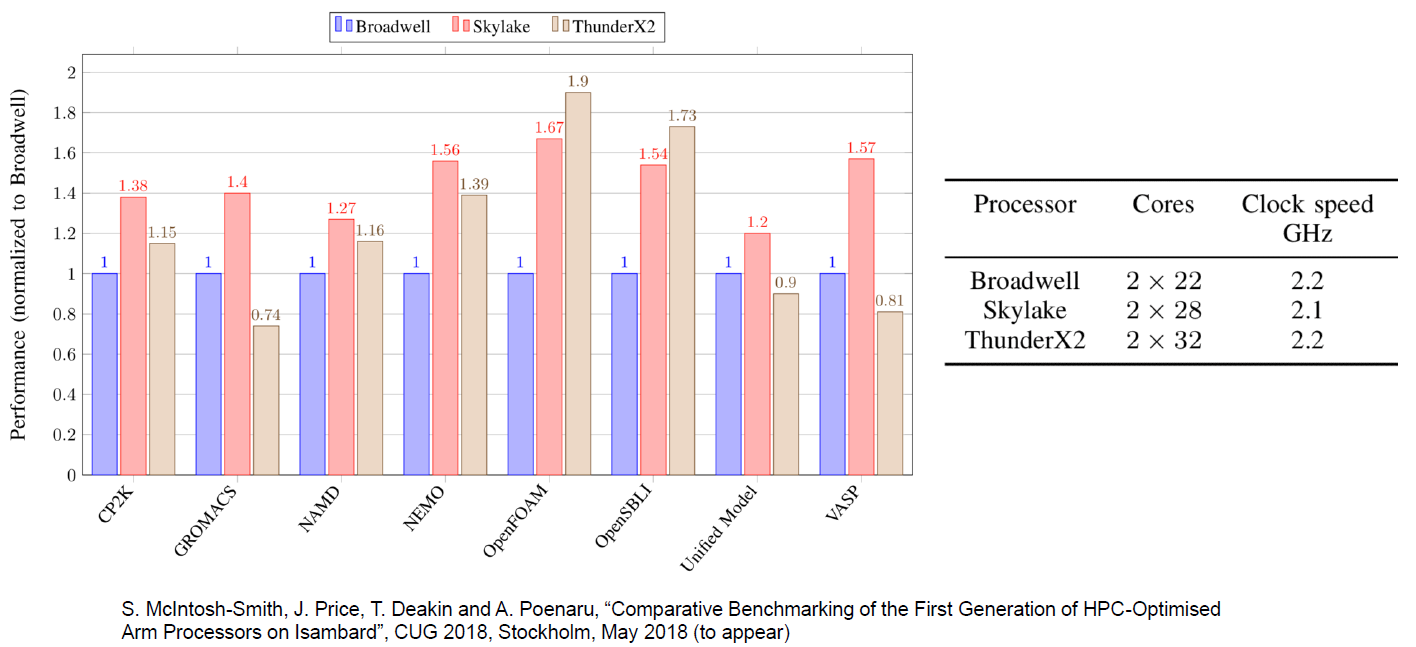
Namun, selain beberapa ceruk pasar, kami cukup yakin bahwa ThunderX2 akan menjadi pemain yang solid. Sebagai contoh, pengukuran kinerja yang dilakukan oleh rekan-rekan kami di University of Bristol mengkonfirmasi asumsi kami bahwa beban kerja HPC yang kuat seperti OpenFoam (CFD) dan NAMD.run berfungsi dengan baik di ThunderX2
Berdasarkan hasil pengujian awal perangkat lunak server yang berhasil kami lakukan, kami mungkin akan terkejut. Kinerja ThunderX2 untuk satu dolar pada Java Server (SPECJbb) dan pemrosesan data besar - sekarang - yang terbaik di pasar server. Kita harus menguji ulang prosesor AMD EPYC dan versi emas dari generasi saat ini (Skylake) Xeon, tetapi pada saat yang sama 80-90% dari kinerja prosesor 8176 untuk seperempat dari biayanya akan sangat sulit dikalahkan.
Sebagai manfaat tambahan untuk Cavium dan ThunderX2, harus disebutkan bahwa ekosistem Arm Linux sudah matang pada tahun 2018; kernel Linux khusus dan alat-alat lain tidak lagi diperlukan. Anda cukup menginstal Ubuntu, Red Hat, atau server Suse, dan Anda dapat mengotomatiskan penyebaran dan instalasi perangkat lunak dari repositori standar. Ini adalah peningkatan signifikan atas apa yang kami alami ketika ThunderX diluncurkan. Kembali pada tahun 2016, instalasi sederhana dari repositori Ubuntu biasa dapat menyebabkan masalah.
Jadi, secara keseluruhan, ThunderX2 adalah saingan yang sangat kuat. Ini bisa menjadi lebih berbahaya bagi AMD EPYC daripada untuk Intel Skylake Xeon karena fakta bahwa Cavium dan AMD bersaing untuk kelompok pelanggan yang sama, mengingat kemungkinan meninggalkan Intel. Hal ini disebabkan oleh fakta bahwa pelanggan yang berinvestasi dalam perangkat lunak perusahaan yang mahal (Oracle, SAP) kurang sensitif terhadap biaya di sisi perangkat keras, sehingga mereka jauh lebih kecil kemungkinannya untuk beralih ke platform perangkat keras baru. Dan orang-orang ini telah berinvestasi di Intel selama 5 tahun terakhir, karena itulah satu-satunya pilihan.
Ini, pada gilirannya, berarti bahwa mereka yang lebih fleksibel dan sensitif terhadap harga, seperti penyedia hosting dan cloud, sekarang akan dapat memilih server Arm alternatif dengan rasio kinerja-terhadap-dolar yang sangat baik. Dan dengan HP, Cray, Pengiun, Gigabyte, Foxconn dan Inventec yang menawarkan sistem berbasis ThunderX2, tidak ada kekurangan pemasok berkualitas.
Singkatnya, ThunderX2 adalah SoC pertama yang bersaing dengan Intel dan AMD di pasar server CPU. Dan ini kejutan yang menyenangkan: akhirnya, solusi untuk server Arm telah muncul!
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikannya kepada teman-teman Anda,
diskon 30% untuk pengguna Habr pada analog unik dari server entry-level yang kami temukan untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps dari $ 20 atau bagaimana membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
Dell R730xd 2 kali lebih murah? Hanya kami yang memiliki
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV dari $ 249 di Belanda dan Amerika Serikat! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?