Replikasi aliran, yang muncul pada 2010, telah menjadi salah satu fitur terobosan PostgreSQL dan saat ini, hampir tidak ada instalasi yang dapat dilakukan tanpa menggunakan replikasi streaming. Ia dapat diandalkan, mudah dikonfigurasikan, tidak memerlukan sumber daya. Namun, untuk semua kualitas positifnya, selama operasi berbagai masalah dan situasi yang tidak menyenangkan dapat muncul.
Alexey Lesovsky (
@lesovsky ) di Highload ++ 2017 memberi tahu cara
mendiagnosis berbagai jenis masalah menggunakan alat internal dan pihak ketiga
dan cara memperbaikinya . Di bawah pemotongan, decoding laporan ini, dibangun berdasarkan prinsip spiral: pertama, kami membuat daftar semua alat diagnostik yang mungkin, kemudian beralih ke daftar masalah umum dan mendiagnosisnya, kemudian melihat tindakan darurat apa yang dapat diambil, dan akhirnya bagaimana menangani masalah secara radikal.
Tentang pembicara : Alexei Lesovsky, administrator database di Data Egret. Salah satu topik favorit Alexey di PostgreSQL adalah streaming replikasi dan bekerja dengan statistik, sehingga laporan di Highload ++ 2017 dikhususkan untuk bagaimana menemukan masalah menggunakan statistik dan metode apa yang digunakan untuk menyelesaikannya.
Rencanakan
- Sedikit teori, atau bagaimana replikasi bekerja di PostgreSQL
- Alat pemecahan masalah atau apa yang PostgreSQL dan komunitas miliki
- Kasus pemecahan masalah:
- masalah: gejala dan diagnosis mereka
- keputusan
- langkah-langkah yang harus diambil agar masalah ini tidak muncul.
Kenapa semua ini? Artikel ini akan membantu Anda lebih memahami replikasi streaming, mempelajari cara menemukan dan memperbaiki masalah dengan cepat untuk mengurangi waktu reaksi terhadap insiden yang tidak menyenangkan.
Sedikit teori
PostgreSQL memiliki entitas seperti Write-Ahead Log (XLOG), log transaksi.
Hampir semua perubahan yang terjadi dengan data dan metadata di dalam database dicatat dalam log ini. Jika ada kecelakaan yang tiba-tiba terjadi, PostgreSQL mulai, membaca log transaksi dan mengembalikan perubahan yang direkam ke data. Ini memastikan keandalan - salah satu properti terpenting dari DBMS dan PostgreSQL juga.
Log transaksi dapat diisi dengan dua cara:
- Secara default, ketika backend membuat beberapa perubahan dalam database (INSERT, UPDATE, DELETE, dll.), Semua perubahan dicatat dalam log transaksi secara serempak :
- Klien mengirim perintah COMMIT untuk mengonfirmasi data.
- Data dicatat dalam log transaksi.
- Setelah fiksasi terjadi, kontrol diberikan ke backend, dan itu dapat terus menerima perintah dari klien.
- Pilihan kedua adalah penulisan asinkron ke log transaksi, ketika proses penulis WAL khusus menulis perubahan pada log transaksi dengan interval waktu tertentu. Karena itu, peningkatan kinerja backend tercapai, karena tidak perlu menunggu sampai perintah COMMIT selesai.
Yang paling penting, replikasi streaming didasarkan pada log transaksi ini. Kami memiliki beberapa anggota replikasi streaming:
- kuasai tempat semua perubahan terjadi;
- beberapa replika yang menerima log transaksi dari master dan mereproduksi semua perubahan ini pada data lokal mereka. Ini replikasi streaming.
Patut diingat bahwa semua log transaksi ini disimpan dalam direktori pg_xlog dalam $ DATADIR - direktori dengan file data DBMS utama. Dalam versi 10 PostgreSQL, direktori ini diganti namanya menjadi pg_wal /, karena ini tidak biasa bagi pg_xlog / untuk mengambil banyak ruang, dan pengembang atau administrator yang secara tidak sadar mengacaukannya dengan log, menghapusnya dengan sembarangan, dan semuanya menjadi buruk.
PostgreSQL memiliki beberapa layanan latar belakang yang terlibat dalam replikasi streaming. Mari kita melihatnya dari sudut pandang sistem operasi.
- Dari sisi master - proses Pengirim WAL. Ini adalah proses yang mengirim log transaksi ke replika, setiap replika akan memiliki Pengirim WAL sendiri.
- Replika, pada gilirannya, menjalankan proses Penerima WAL, yang menerima log transaksi melalui koneksi jaringan dari Pengirim WAL dan meneruskannya ke proses Startup.
- Proses startup membaca log dan mereproduksi di direktori data semua perubahan yang dicatat dalam log transaksi.
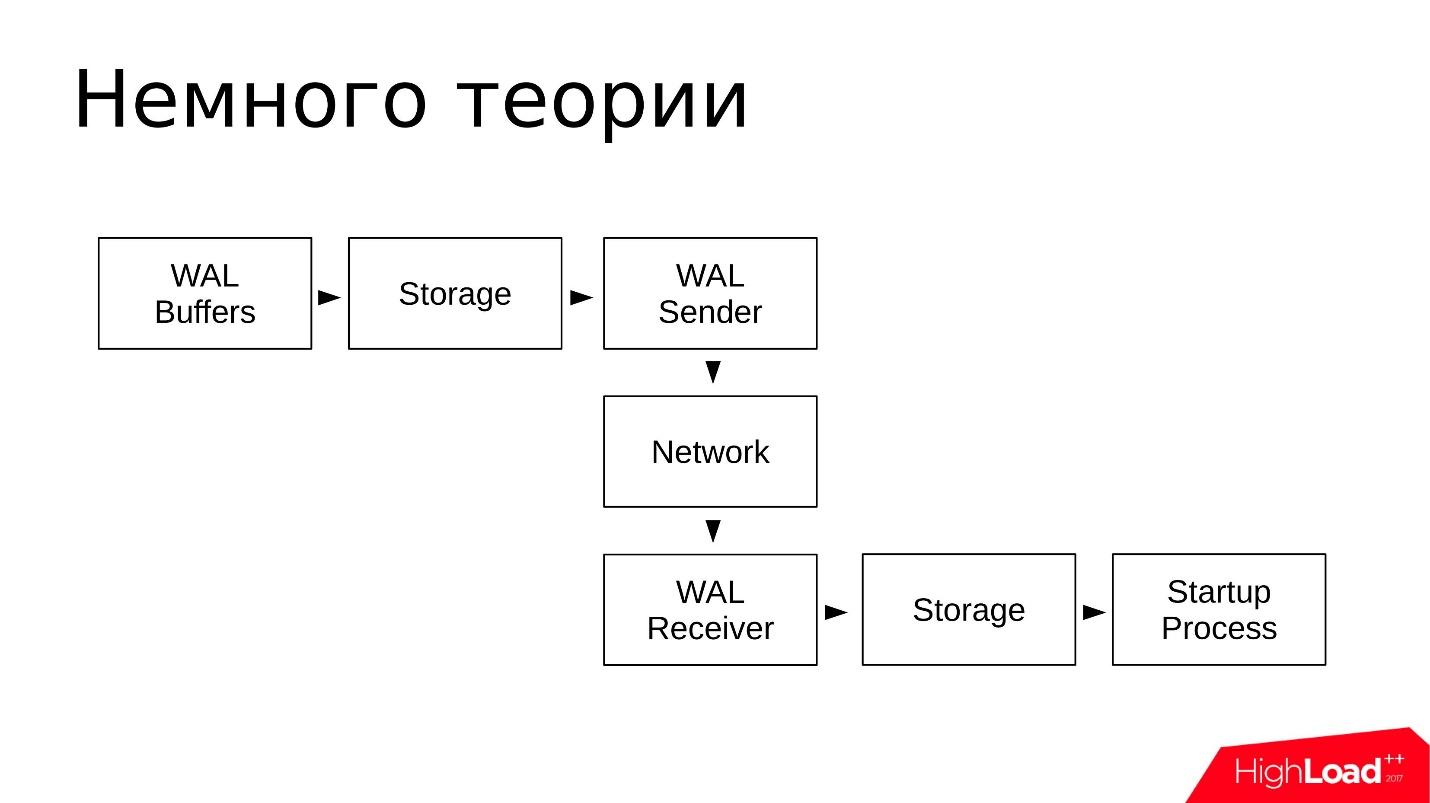
Secara skematis, tampilannya seperti ini:
- Perubahan ditulis ke WAL Buffer, yang kemudian akan ditulis ke log transaksi;
- Log disimpan dalam direktori pg_wal /;
- WAL Pengirim membaca log transaksi dari repositori dan mengirimkannya melalui jaringan;
- Penerima WAL menerima dan menyimpan dalam Penyimpanannya - di pg_wal lokal;
- Proses Startup membaca semua yang diterima dan direproduksi.
Skema ini sederhana. Replikasi aliran bekerja dengan cukup andal dan telah dieksploitasi dengan sangat baik selama bertahun-tahun.
Alat pemecahan masalah
Mari kita lihat alat dan utilitas apa yang ditawarkan komunitas dan PostgreSQL untuk menyelidiki masalah yang dihadapi dengan replikasi streaming.
Alat pihak ketiga
Mari kita mulai dengan alat pihak ketiga. Utilitas ini adalah
rencana yang agak
universal , mereka dapat digunakan tidak hanya untuk menyelidiki insiden yang terkait dengan replikasi streaming. Ini umumnya
utilitas dari administrator sistem apa pun .
- atas dari paket procps. Sebagai pengganti top, Anda dapat menggunakan utilitas seperti di atas, htop dan sejenisnya. Mereka menawarkan fungsionalitas serupa.
Dengan bantuan top kita melihat: pemanfaatan prosesor (CPU), beban rata-rata (rata-rata beban) dan penggunaan memori dan ruang swap.
- iostat dari sysstat dan iotop. Utilitas ini menunjukkan pemanfaatan perangkat disk dan I / O dibuat oleh proses dalam sistem operasi.
Dengan bantuan iostat kita melihat: pemanfaatan penyimpanan, berapa iops saat ini, apa throughput pada perangkat, apa keterlambatan saat memproses permintaan untuk I / O (latensi). Informasi yang agak terperinci ini diambil dari sistem file procfs dan diberikan kepada pengguna dalam bentuk visual.
- nicstat adalah analog dari iostat, hanya untuk antarmuka jaringan. Dalam utilitas ini Anda dapat menonton pemanfaatan antarmuka.
Menggunakan nicstat, kita melihat: sama, pemanfaatan antarmuka, beberapa kesalahan yang terjadi pada antarmuka, throughput juga merupakan utilitas yang sangat berguna.
- pgCenter adalah utilitas untuk bekerja hanya dengan PostgreSQL. Ini menunjukkan statistik PostgreSQL dalam antarmuka seperti teratas, dan Anda juga dapat melihat statistik yang terkait dengan replikasi streaming di dalamnya.
Dengan bantuan pgCenter, kami melihat: statistik tentang replikasi. Anda dapat menonton lag replikasi, entah bagaimana mengevaluasinya, dan memprediksi pekerjaan di masa depan.
- perf adalah utilitas untuk penyelidikan yang lebih dalam tentang penyebab "ketukan bawah tanah", ketika dalam operasi ada masalah aneh pada level kode PostgreSQL.
Dengan bantuan perf kami mencari: ketukan bawah tanah. Agar perf dapat bekerja sepenuhnya dengan PostgreSQL, yang terakhir harus dikompilasi dengan karakter debug, sehingga Anda dapat melihat tumpukan fungsi dalam proses dan fungsi mana yang paling memakan waktu CPU.
Semua utilitas ini diperlukan untuk
menguji hipotesis yang muncul saat pemecahan masalah - di mana dan apa yang melambat, di mana dan apa yang perlu Anda perbaiki, periksa. Utilitas ini membantu memastikan kita berada di jalur yang benar.
Alat Tertanam
Apa yang ditawarkan PostgreSQL sendiri?
Tampilan sistem
Secara umum, ada banyak alat untuk bekerja dengan PostgreSQL. Setiap perusahaan vendor yang menyediakan dukungan PostgreSQL menawarkan alatnya sendiri. Tetapi, sebagai aturan, alat-alat ini didasarkan pada statistik internal PostgreSQL. Dalam hal ini, PostgreSQL memberikan pandangan sistem di mana Anda dapat membuat berbagai pilihan dan mendapatkan informasi yang Anda butuhkan. Artinya, menggunakan klien biasa, biasanya psql, kita dapat membuat kueri dan melihat apa yang terjadi dalam statistik.
Ada beberapa pandangan sistem. Agar dapat bekerja dengan replikasi streaming dan menyelidiki masalah, kita hanya perlu: pg_stat_replication, pg_stat_wal_receiver, pg_stat_databases, pg_stat_databases_conflicts, dan pg_stat_activity dan pg_stat_archiver tambahan.
Ada beberapa dari mereka, tetapi set ini cukup untuk memeriksa apakah ada masalah.
Fungsi Pembantu
Menggunakan fungsi bantu, Anda dapat mengambil data dari representasi sistem statistik dan mengubahnya menjadi bentuk yang lebih nyaman bagi Anda. Fungsi bantu juga hanya beberapa buah.
- pg_current_wal_lsn () (analog lama pg_current_xlog_location ()) adalah fungsi yang paling penting yang memungkinkan Anda untuk melihat posisi saat ini dalam log transaksi. Log transaksi adalah urutan data yang berkelanjutan. Dengan menggunakan fungsi ini, Anda dapat melihat titik terakhir, mendapatkan posisi di mana log transaksi telah berhenti sekarang.
- pg_last_wal_receive_lsn (), pg_last_xlog_receive_location () adalah fungsi serupa di atas, hanya untuk replika. Replika menerima log transaksi, dan Anda dapat melihat posisi log transaksi yang terakhir diterima;
- pg_wal_lsn_diff (), pg_xlog_location_diff () adalah fungsi lain yang bermanfaat. Kami memberinya dua posisi dari log transaksi, dan dia menunjukkan perbedaan - jarak antara dua titik ini dalam byte. Fungsi ini selalu berguna untuk menentukan jeda antara master dan replika dalam byte.
Daftar lengkap fungsi dapat diperoleh dengan meta-command psql: \ df * (wal | xlog | lsn | location) *.
Anda dapat mengetikkannya dalam psql dan melihat semua fungsi yang berisi lokasi, xlog, Isn,. Akan ada sekitar 20-30 fungsi seperti itu, dan mereka juga menyediakan berbagai informasi pada log transaksi. Saya sarankan Anda membiasakan diri.
Utilitas Pg_waldump
Sebelum versi 10.0, itu disebut pg_xlogdump. Utilitas pg_waldump diperlukan ketika kita ingin melihat ke dalam segmen log transaksi, mencari tahu catatan sumber daya yang ada di sana, dan apa yang PostgreSQL tulis di sana, yaitu, untuk studi yang lebih rinci.
Di versi 10.0, semua tampilan sistem, fungsi, dan utilitas yang termasuk kata xlog diubah namanya. Semua kemunculan kata xlog dan lokasi masing-masing digantikan oleh kata wal dan lsn. Hal yang sama dilakukan dengan direktori pg_xlog yang menjadi direktori pg_wal.
Utilitas pg_waldump dengan mudah menerjemahkan isi segmen XLOG ke format yang dapat dibaca manusia. Anda dapat melihat apa yang disebut catatan sumber daya masuk ke dalam log segmen selama pekerjaan PostgreSQL, yang mana indeks dan file tumpukan diubah, informasi apa yang dimaksudkan untuk stand-by sampai di sana. Dengan demikian, banyak informasi dapat dilihat menggunakan pg_waldump.
Tetapi ada disclaimer yang ditulis dalam dokumentasi resmi : pg_waldump dapat menampilkan data yang sedikit salah ketika PostgreSQL berjalan (Dapat memberikan hasil yang salah ketika server berjalan - apa pun artinya)
Anda dapat menggunakan perintah:
pg_waldump -f - /wal_10 \ $(psql -qAtX - "select pg_walfile_name(pg_current_wal_lsn())")
Ini adalah analog dari perintah tail -f untuk log transaksi saja. Perintah ini menunjukkan ekor log transaksi yang sedang terjadi sekarang. Anda dapat menjalankan perintah ini, ia akan menemukan segmen terakhir dengan entri log transaksi terbaru, terhubung dengannya dan mulai menampilkan konten log transaksi. Tim yang sedikit rumit, tetapi, bagaimanapun, ini berhasil. Saya sering menggunakannya.
Mengatasi kasus
Di sini kita melihat masalah paling umum yang muncul dalam praktik konsultan, gejala apa yang mungkin terjadi dan bagaimana mendiagnosisnya:
Keterlambatan replikasi adalah masalah yang paling umum . Baru-baru ini, kami memiliki korespondensi dengan pelanggan:
- Kami telah merusak replikasi master-slave antara kedua server.
- Terdeteksi lag 2 jam, pg_dump dimulai.
- Oke saya mengerti. Apa kelambatan kami yang diizinkan?
- 16 jam di max_standby_streaming_delay.
- Apa yang akan terjadi ketika keterlambatan ini terlampaui? Sirene meraung?
- Tidak, transaksi akan dikalahkan, dan gulungan WAL akan dilanjutkan.
Kami memiliki masalah dengan keterlambatan replikasi sepanjang waktu, dan hampir setiap minggu kami menyelesaikannya.
Pembengkakan direktori pg_wal / di mana segmen log transaksi disimpan adalah masalah yang lebih jarang terjadi. Tetapi dalam hal ini perlu untuk mengambil tindakan segera sehingga masalahnya tidak berubah menjadi situasi darurat ketika replika jatuh.
Permintaan panjang yang dijalankan pada replika menyebabkan
konflik selama pemulihan . Ini adalah situasi ketika kami memulai beberapa jenis beban pada replika, Anda dapat menjalankan kueri baca pada replika, dan pada saat ini kueri ini mengganggu reproduksi log transaksi. Ada konflik, dan PostgreSQL perlu memutuskan apakah akan menunggu permintaan untuk menyelesaikan atau untuk menyelesaikannya dan terus memainkan log transaksi. Ini adalah konflik replikasi atau konflik pemulihan.
Proses pemulihan: Penggunaan CPU 100% - Proses memulihkan log transaksi pada replika membutuhkan 100% waktu prosesor. Ini juga situasi yang jarang, tetapi agak tidak menyenangkan, karena mengarah pada peningkatan keterlambatan replikasi dan umumnya sulit untuk diselidiki.
Replikasi tertinggal
Kelambatan replikasi adalah ketika permintaan yang sama, dijalankan pada master dan pada replika, mengembalikan data yang berbeda. Ini berarti bahwa data tidak konsisten antara master dan replika, dan ada beberapa kelambatan. Replika perlu mereproduksi bagian dari log transaksi untuk mengejar ketinggalan dengan wizard. Gejala utama terlihat persis seperti ini: ada kueri, dan hasilnya berbeda.
Bagaimana cara mencari masalah seperti itu?- Ada tampilan dasar pada wizard dan replika - pg_stat_replication . Ini menunjukkan informasi tentang semua Pengirim WAL, yaitu, pada proses yang mengirim log transaksi. Setiap replika akan memiliki baris terpisah yang menunjukkan statistik untuk replika khusus ini.
- Fungsi bantu pg_wal_lsn_diff () memungkinkan Anda untuk membandingkan posisi yang berbeda dalam log transaksi dan menghitung jeda yang sama. Dengan bantuannya, kita bisa mendapatkan angka tertentu dan menentukan di mana kita memiliki jeda yang besar, mana yang kecil dan entah bagaimana sudah menanggapi masalahnya.
- Fungsi pg_last_xact_replay_timestamp () hanya bekerja pada replika dan memungkinkan Anda untuk melihat waktu ketika transaksi terakhir yang hilang dilakukan. Ada fungsi now () yang terkenal yang menunjukkan waktu saat ini, kami kurangi waktu yang ditunjukkan kepada kami oleh fungsi pg_last_xact_replay_timestamp () dari fungsi now () dan mendapatkan jeda waktu.
Dalam versi 10 dari pg_stat_replication, bidang tambahan muncul yang menunjukkan jeda waktu yang sudah ada di wizard, oleh karena itu metode ini sudah usang, tetapi, bagaimanapun, itu dapat digunakan.
Ada jebakan kecil. Jika tidak ada transaksi pada wizard untuk waktu yang lama, dan itu tidak menghasilkan log transaksi, maka fungsi terakhir akan menunjukkan peningkatan jeda. Faktanya, sistem ini hanya idle, tidak ada aktivitas di dalamnya, tetapi dalam pemantauan kita dapat melihat bahwa lag semakin berkembang. Perangkap ini patut diingat.
Tampilannya adalah sebagai berikut.

Ini berisi informasi tentang setiap Pengirim WAL dan beberapa bidang yang penting bagi kami. Ini terutama
client_addr - alamat jaringan dari replika yang terhubung (biasanya alamat IP) dan seperangkat bidang
lsn (dalam versi yang lebih lama disebut lokasi), saya akan membicarakannya sedikit lebih jauh.
Dalam versi ke-10, bidang
lag muncul - ini adalah jeda yang dinyatakan dalam waktu, yaitu format yang lebih dapat dibaca oleh manusia. Kelambatan dapat dinyatakan dalam byte atau dalam waktu - Anda dapat memilih apa yang paling Anda sukai.
Sebagai aturan, saya menggunakan permintaan ini.

Ini bukan kueri paling rumit yang dicetak pg_stat_replication dalam format yang lebih mudah dimengerti. Di sini saya menggunakan fungsi-fungsi berikut:
- pg_wal_lsn_diff () untuk membaca diff. Tetapi di antara apa menurut saya perbedaan itu? Kami memiliki beberapa bidang - sent_lsn, write_lsn, flush_lsn, replay_lsn. Dengan menghitung perbedaan antara bidang saat ini dan sebelumnya, kita dapat secara akurat memahami di mana kita tertinggal, di mana tepatnya lag terjadi.
- pg_current_wal_lsn () , yang menunjukkan posisi saat ini dari log transaksi. Di sini kita melihat jarak antara posisi saat ini di log dan yang dikirim - berapa banyak log transaksi yang dihasilkan tetapi tidak dikirim.
- sent_lsn , write_lsn - ini adalah berapa banyak yang dikirim ke replika, tetapi tidak direkam. Artinya, sekarang terletak di suatu tempat di jaringan, atau diterima oleh replika, tetapi belum ditulis dari buffer jaringan ke penyimpanan disk.
- write_lsn, flush_lsn - ini ditulis, tetapi tidak dikeluarkan oleh perintah fsync - seolah-olah ditulis, tetapi dapat ditemukan di suatu tempat di RAM, dalam cache halaman sistem operasi. Segera setelah kami melakukan fsync, data disinkronkan dengan disk, sampai ke penyimpanan persisten dan semuanya tampaknya dapat diandalkan.
- replay_lsn, flush_lsn - data dicampakkan, fsync dieksekusi, tetapi tidak direplikasi.
- current_wal_lsn dan replay_lsn adalah jenis total lag yang mencakup semua posisi sebelumnya.
Beberapa contoh

Replika 10.6.6.8 disorot di atas. Dia memiliki
lag yang tertunda , dia membuat beberapa log transaksi, tetapi masih belum terkirim dan terletak pada master. Kemungkinan besar, ada beberapa jenis masalah dengan kinerja jaringan. Kami akan memverifikasi ini menggunakan utilitas nicstat.
Kami akan meluncurkan nicstat, lihat pemanfaatan antarmuka, jika ada masalah dan kesalahan di sana. Jadi kita bisa menguji hipotesis ini.
 Jeda penulisan
Jeda penulisan ditandai di atas. Sebenarnya, lag ini cukup langka, saya hampir tidak melihatnya terlalu besar. Masalahnya mungkin dengan disk, dan kami menggunakan utilitas iostat atau iotop - kami melihat pemanfaatan penyimpanan disk, yang I / O dibuat oleh proses, dan kemudian kami mencari tahu mengapa.
 Flush dan replay Lags
Flush dan replay Lags - paling sering lag terjadi di sana ketika perangkat disk pada replika tidak punya waktu untuk hanya kehilangan semua perubahan yang tiba dari master.
Juga dengan utilitas iostat dan iotop kita melihat apa yang terjadi dengan pemanfaatan disk dan mengapa rem.
Dan
total_lag terakhir adalah metrik yang berguna untuk sistem pemantauan. Jika ambang total_lag kami terlampaui, kotak centang dinaikkan dalam pemantauan, dan kami mulai menyelidiki apa yang terjadi di sana.
Tes hipotesis
Sekarang Anda perlu mencari cara untuk menyelidiki lebih lanjut masalah tertentu. Saya sudah mengatakan jika ini adalah lag jaringan, maka kita perlu memeriksa apakah semuanya sesuai dengan jaringan.
Sekarang hampir semua hosters menyediakan 1 Gb / s atau bahkan 10 Gb / s, sehingga
bandwidth yang tersumbat adalah skenario yang paling tidak mungkin . Sebagai aturan, Anda perlu melihat kesalahan. nicstat berisi informasi tentang kesalahan pada antarmuka, Anda dapat mengetahui bahwa ada masalah dengan driver, baik dengan kartu jaringan itu sendiri atau dengan kabel.
Kami menyelidiki
masalah penyimpanan menggunakan iostat dan iotop. iostat diperlukan untuk melihat gambaran umum penyimpanan disk: daur ulang perangkat, lebar pita perangkat, latensi. iotop - untuk penelitian yang lebih akurat, ketika kita perlu mengidentifikasi proses mana yang memuat subsistem disk. Jika ini adalah semacam proses pihak ketiga, itu hanya dapat dideteksi, diselesaikan, dan mungkin masalahnya akan hilang.
Pertama-tama, kita melihat
penundaan pemulihan dan konflik replikasi melalui top atau pg_stat_activity: proses mana yang sedang berjalan, permintaan mana yang sedang berjalan, waktu pelaksanaannya, berapa lama mereka berjalan. Jika ini adalah beberapa pertanyaan panjang, kami melihat mengapa mereka bekerja untuk waktu yang lama, menembak mereka, memahami dan
mengoptimalkannya - kami akan memeriksa pertanyaan itu sendiri.
Jika ini adalah sejumlah
besar log transaksi yang dihasilkan oleh wizard, kami dapat mendeteksi ini dengan
pg_stat_activity . Mungkin beberapa proses pencadangan dimulai di sana, beberapa jenis kekosongan telah dimulai (pg_stat_progress_vacuum), atau pos pemeriksaan sedang dijalankan. Artinya, jika terlalu banyak log transaksi dihasilkan, dan replika tidak punya waktu untuk memprosesnya, pada titik tertentu mungkin jatuh, dan ini akan menjadi masalah bagi kami.
Dan tentu saja
pg_wal_lsn_diff () untuk menentukan lag dan menentukan di mana kita memiliki lag secara khusus - pada jaringan, pada disk, atau pada prosesor.
Opsi solusi
Masalah Jaringan / PenyimpananSemuanya cukup sederhana di sini, tetapi dari sudut pandang konfigurasi, ini biasanya tidak terpecahkan. Anda dapat mengencangkan beberapa mur, tetapi secara umum ada 2 opsi:
Periksa permintaan apa yang sedang berjalan. Mungkin beberapa jenis migrasi diluncurkan yang menghasilkan banyak log transaksi, atau bisa juga transfer data, penghapusan atau penyisipan.
Setiap proses yang menghasilkan log transaksi dapat menyebabkan kelambatan transaksi . Semua data pada wizard dihasilkan secepat mungkin, kami membuat perubahan pada data, mengirimkannya ke replika, dan replika itu dapat mengatasi atau gagal - ini bukan masalah wizard. Kelambatan mungkin muncul di sini dan Anda perlu melakukan sesuatu dengannya.
- Tingkatkan perangkat keras
Pilihan paling bodoh - mungkin kita telah mengalami kinerja besi, dan Anda hanya perlu mengubahnya. Ini bisa berupa disk lama atau SSD berkualitas buruk, atau colokan kinerja pengontrol RAID. Di sini kita tidak lagi menjelajahi basis itu sendiri, tetapi memeriksa kinerja kelenjar kita.
Penundaan PemulihanJika kita memiliki segala jenis konflik replikasi karena permintaan panjang, yang mengakibatkan peningkatan keterlambatan ulangan,
hal pertama yang kita lakukan adalah
menembak permintaan panjang yang berjalan pada replika, karena mereka menunda pemutaran log transaksi.
Jika kueri panjang terkait dengan tidak optimalnya kueri SQL itu sendiri (kami menemukan ini menggunakan EXPLAIN ANALYZE), Anda hanya perlu mendekati kueri ini secara berbeda dan menulis ulang. Atau ada opsi untuk mengonfigurasi
replika terpisah untuk kueri pelaporan . Jika kami membuat laporan yang berfungsi untuk waktu yang lama, laporan tersebut perlu dikirim ke replika terpisah.
Masih ada opsi
menunggu saja . Jika kita memiliki beberapa kelambatan pada tingkat beberapa kilobyte atau bahkan puluhan megabita, tetapi kami pikir ini dapat diterima, kami hanya menunggu permintaan diselesaikan dan kelambatan tersebut akan menyelesaikannya sendiri. Ini juga merupakan pilihan, dan sering terjadi bahwa itu dapat diterima.
WAL volume tinggiJika kita menghasilkan volume besar log transaksi, kita perlu mengurangi
volume ini
per unit waktu , untuk membuat replika perlu mengunyah lebih sedikit log transaksi.
Ini biasanya dilakukan
melalui konfigurasi . Solusi parsial dalam pengaturan full_page_writes = parameter off. Opsi ini mengaktifkan / menonaktifkan rekaman gambar lengkap dari halaman yang berubah dalam log transaksi. Ini berarti bahwa ketika kami memiliki layanan operasi menulis pos pemeriksaan (CHECKPOINT), saat berikutnya kami mengubah beberapa blok data di area buffer bersama, gambar lengkap halaman ini akan masuk ke log transaksi, dan bukan hanya perubahan itu sendiri. Dengan semua perubahan berikutnya pada halaman yang sama, hanya perubahan yang akan dicatat dalam log transaksi. Dan seterusnya ke pos pemeriksaan berikutnya.
Setelah pos pemeriksaan, kami merekam gambar penuh halaman, dan ini memengaruhi volume log transaksi yang direkam. Jika ada cukup banyak pos pemeriksaan per unit waktu, katakanlah 4 pos pemeriksaan dilakukan per jam, dan akan ada banyak gambar halaman penuh, ini akan menjadi masalah. Anda dapat menonaktifkan perekaman gambar penuh dan ini akan mempengaruhi volume WAL. Tetapi sekali lagi, ini adalah setengah ukuran.
Catatan: Rekomendasi untuk menonaktifkan full_page_writes harus dipertimbangkan dengan hati-hati, karena penulis lupa untuk mengklarifikasi selama laporan bahwa menonaktifkan parameter dapat, dalam beberapa keadaan, terjadi dalam situasi darurat (kerusakan pada sistem file atau log, sebagian menulis ke blok, dll.) file database yang berpotensi rusak. Karena itu, berhati-hatilah, menonaktifkan parameter dapat meningkatkan risiko korupsi data dalam situasi darurat.Separuh tindakan lainnya adalah
meningkatkan interval di antara pos-pos pemeriksaan . Secara default, pos pemeriksaan dilakukan setiap 5 menit, dan ini cukup umum. Sebagai aturan, interval ini ditingkatkan menjadi 30-60 menit - ini adalah waktu yang cukup dapat diterima dimana semua halaman kotor dikelola untuk disinkronkan ke disk.
Tetapi solusi utamanya adalah, tentu saja, untuk
melihat beban kerja kita - jenis operasi berat apa yang terjadi di sana, terkait dengan mengubah data, dan, mungkin, mencoba melakukan perubahan ini dalam batch.
Misalkan kita memiliki tabel, kita ingin menghapus beberapa juta catatan dari itu. Pilihan terbaik adalah tidak menghapus jutaan ini sekaligus dengan satu permintaan, tetapi untuk memecahnya menjadi paket 100-200 ribu sehingga, pertama, volume kecil WAL dihasilkan, kedua, ruang hampa memiliki waktu untuk melewati data yang dihapus, dan karena itu lag tidak begitu besar dan kritis.
Pembengkakan pg_wal /
Sekarang, mari kita bicara tentang bagaimana Anda dapat menemukan bahwa direktori pg_wal / bengkak.
Secara teori, PostgreSQL selalu mempertahankannya dalam keadaan optimal untuk dirinya sendiri di tingkat file konfigurasi tertentu, dan, sebagai aturan, seharusnya tidak tumbuh di atas batas-batas tertentu.
Ada parameter max_wal_size, yang menentukan nilai maksimum. Plus ada parameter wal_keep_segments - jumlah tambahan segmen yang disimpan master untuk replika jika replika tiba-tiba tidak tersedia untuk waktu yang lama.
Setelah menghitung jumlah max_wal_size dan wal_keep_segments, kita dapat memperkirakan secara kasar berapa banyak ruang yang akan ditempati direktori pg_wal /. Jika itu tumbuh dengan cepat dan membutuhkan lebih banyak ruang daripada nilai yang dihitung, ini berarti ada beberapa masalah, dan Anda perlu melakukan sesuatu untuk itu.
Bagaimana cara mendeteksi masalah seperti itu?
Pada sistem operasi Linux, ada
perintah du -csh . Kami hanya dapat memantau nilai dan memantau berapa banyak log transaksi yang kami miliki di sana; simpan label yang dihitung, berapa banyak dia berutang dan berapa banyak yang sebenarnya dia ambil, dan entah bagaimana menanggapi perubahan angka.
Tempat lain yang kami lihat adalah tampilan
pg_replication_slots dan
pg_stat_archiver . Alasan paling umum mengapa pg_wal / memakan banyak ruang adalah slot replikasi yang terlupakan atau pengarsipan yang rusak. Alasan lain juga ada tempatnya, tetapi dalam praktik saya itu sangat jarang.
Dan, tentu saja, selalu ada kesalahan dalam log PostgreSQL yang terkait dengan perintah arsip. Sayangnya, tidak akan ada alasan lain yang terkait dengan pg_wal / overflow. Kami hanya dapat menangkap kesalahan arsip di sana.
Opsi untuk masalah:
CRUD Berat - operasi penyegaran data berat - INSERT, DELETE, UPDATE, terkait dengan perubahan beberapa juta baris. Jika PostgreSQL perlu melakukan operasi seperti itu, jelas bahwa sejumlah besar log transaksi akan dihasilkan. Ini akan disimpan di pg_wal /, dan ini akan menambah ruang yang ditempati. Itu, sekali lagi, seperti yang saya katakan sebelumnya, adalah praktik yang baik untuk hanya memecahnya menjadi paket, dan untuk memperbarui bukan seluruh array, tetapi masing-masing 100, 200, 300 ribu.
Slot replikasi yang terlupakan atau tidak digunakan adalah masalah umum lainnya. Orang sering menggunakan replikasi logis untuk beberapa tugas mereka: mereka mengkonfigurasi bus yang mengirim data ke Kafka, mengirim data ke aplikasi pihak ketiga yang menerjemahkan replikasi logis ke format lain dan entah bagaimana memprosesnya.
Replikasi logis biasanya bekerja melalui slot . Kebetulan kami mengatur slot replikasi, bermain dengan aplikasi, menyadari bahwa aplikasi ini tidak sesuai dengan kami, mematikan aplikasi, menghapusnya,
dan slot replikasi terus hidup .
PostgreSQL untuk setiap slot replikasi menyimpan segmen log transaksi seandainya aplikasi jarak jauh atau replika terhubung ke slot ini lagi, dan kemudian wizard dapat mengirimkan mereka log transaksi ini.
Tetapi waktu berlalu, tidak ada yang terhubung ke slot, log transaksi diakumulasikan, dan pada titik tertentu mereka menempati 90% dari ruang. Kita perlu mencari tahu apa itu, mengapa begitu banyak ruang diambil. Sebagai aturan, slot yang terlupakan dan tidak terpakai ini hanya perlu dihapus, dan masalahnya akan diselesaikan. Tetapi lebih lanjut tentang itu nanti.
Opsi lain mungkin perintah
archive_command rusak . Ketika kita memiliki semacam repositori log transaksi eksternal yang kita simpan untuk tugas pemulihan bencana, perintah arsip biasanya disiapkan, lebih jarang pg_receivexlog diatur. Perintah yang terdaftar di archive_command sangat sering berupa perintah terpisah atau beberapa skrip yang mengambil segmen log transaksi dari pg_wal / dan menyalinnya ke penyimpanan arsip.
Kebetulan kami melakukan semacam peningkatan paket sistem, misalnya, di rsync versi berubah, bendera diperbarui atau diubah, atau dalam beberapa perintah lain yang digunakan dalam perintah arsip, formatnya juga berubah - dan skrip atau program itu sendiri yang ditentukan dalam arsip_perintah istirahat. Akibatnya, arsip tidak lagi dapat disalin.
Jika perintah arsip bekerja dengan output bukan 0, maka pesan tentang ini akan ditulis ke log, dan segmen akan tetap di direktori pg_wal /.
Sampai kami menemukan bahwa tim arsip kami telah rusak, segmen akan menumpuk , dan tempat itu juga akan berakhir pada titik tertentu.
Set tindakan darurat (100% ruang yang digunakan):1.
CRUD , — pg_terminate_backend().
- , , , .. , pg_wal/, .
2.
root — reserved space ratio (ext filesystems).
ext ext 5%. , , 5% — . , , 1% , tune2fs -m 1. PostgreSQL , . 100% .
3.
(LVM, ZFS,...).
LVM ZFS, LVM ZFS, , , . , .
4. —
, , HE pg_wal/ .
, , , . ! PostgreSQL , . , , , .
, pg_xlog/ pg_wal/ — log , , , , - — !
, 100% CPU, .
workload . , ? , - , -. : , tablespace, tablespace.
. , , , , , , .
— .checkpoints_segments/max_wal_size, wal_keep_segments . , , — 10-20 wal_keep_segments, max_wal_size. , . PostgreSQL pg_wal/ .
pg_replication_slots — . ,
, — . , , . .
WAL, ,
pg_stat_archiver , . ,
, , , .
checkpoint . , , . , PostgreSQL .
, checkpoint .
, , — . - , . , .
— PostgreSQL :
- User was holding shared bufer pin for too long.
- User query might have needed to see row versions that must be removed.
- User was holding a relation lock for too long.
- User was or might have been using table space that must be dropped.
- User transaction caused bufer deadlock with recovery.
- User was connected to a database that must be dropped.
2 — , , . : , , . ( 30 ),
PostgreSQL — .
. , , . - , timeout . — ALTER, , .
. , tablespace , tablespace. , , - — .
?
pg_stat_databases, pg_stat_databases_conflicts . , . , .
,
. , . , . , , , .
?
, — :
- max_standby_streaming_delay ( ). , . .
- hot_stadby_feedback ( /). , vacuum - , . bloat . , , , hot_stadby_feedback .
- DBA — . , . , , , - , .
- , , , , DBA — , , . max_standby_streaming_delay . , . , , , . — , .
Recovery process: 100% CPU usage
, , ,
100% . , , 100%. , pg_stat_replication, , replay, , .
:
- top — — 100% CPU usage recovery process;
- pg_stat_replication — , , .
, . , :
- perf top/record/report ( debug—);
- GDB;
- pg_waldump.
, , . workload,
. , , PostgreSQL shared buffers ( ). .
Solusi
,
. - workload, - , - : « , - ».
pgsql-hackers ,
pgsql-bugs , , . , .
—
- , , .
Ringkasan
. , , , .
. , , , , , — .
,
, — . , , , .
, ,
— , , .
Tautan yang bermanfaat
, Highload++ Siberia , 25 26 . , , .
- MySQL ClickHouse.
- , Oracle.
- , , — , .
- , VK ClickHouse, , .